Databricks AI関数を用いてデータにAIを適用する
プレビュー
この機能は パブリック プレビュー段階です。
この記事では、 Databricks AI 関数 とサポートされている関数について説明します。
AI 関数とは何ですか?
AI Functions 、 Databricksに保存されているデータにテキスト翻訳や感情分析などのAI適用するために使用できる組み込み関数です。 これらは、 Databricks SQL 、ノートブック、 Lakeflow Spark宣言型パイプライン、ワークフローなど、 Databricks上のどこからでも実行できます。
AI 関数は、使いやすく、高速で、スケーラブルです。アナリストはそれらを使用して独自のデータにデータインテリジェンスを適用でき、 データサイエンティストおよび機械学習エンジニアはそれらを使用して本番運用グレードのバッチパイプラインを構築できます。
AI Functions 、タスク固有の関数と汎用関数を提供します。
- タスク固有の関数は、テキストの要約や翻訳などのタスクに高レベルの AI 機能を提供します。 これらのタスク固有の機能は、 によってホストおよび管理される最先端の生成AI Databricksモデルによって強化されています。サポートされている関数とモデルについては 、タスク固有の AI 関数 を参照してください。
ai_queryは、データに任意のタイプの AI モデルを適用できる汎用関数です。汎用関数:ai_queryを参照してください。
タスク固有のAI関数
タスク固有の関数は特定のタスクを対象とするため、簡単な要約や簡単な翻訳などの日常的なアクションを自動化できます。 Databricks 、これらの関数はDatabricksによって管理されている最先端の生成AIモデルを呼び出し、カスタマイズを必要としないため、開始時に推奨されています。
例については、AI関数を使用して顧客レビューを分析するを参照してください。
次の表に、サポートされている機能とそれらが実行するタスクを示します。
関数 | 説明 |
|---|---|
最先端の生成AIモデルを使用して、入力テキストに対して感情分析を実行します。 | |
入力テキストは、最先端の生成AIモデルを使用して、提供するラベルに従って分類します。 | |
ラベルで指定されたエンティティを、最先端の生成AIモデルを使用してテキストから抽出します。 | |
最先端の生成AIモデルを使用して、テキストの文法エラーを修正します。 | |
ユーザーが提供するプロンプトに、最先端の生成AIモデルを使用して回答します。 | |
最先端の生成AIモデルを使用して、テキスト内の指定されたエンティティをマスクします。 | |
最先端の生成AIモデルを使用して、非構造化ドキュメントから構造化コンテンツを抽出します。 | |
2つの文字列とコンピュートを最先端の生成AI モデルを使用して意味的類似性スコアと比較します。 | |
SQLと最先端の生成AIモデルを使用してテキストの要約を生成します。 | |
最先端の生成AIモデルを使用して、テキストを指定されたターゲット言語に翻訳します。 | |
指定した期間までのデータを予測します。このテーブル値関数は、時系列データを将来に外挿するように設計されています。 | |
最先端の生成AI モデルを使用して、 Mosaic AI Vector Searchインデックスを検索およびクエリします。 |
汎用的な関数: ai_query
ai_query()関数を使用すると、情報の抽出、コンテンツの要約、不正の特定、収益の予測など、生成AIタスクと従来のMLタスクの両方のデータに任意のAIモデルを適用できます。構文の詳細とパラメーターについては、 ai_query 関数を参照してください。
次の表は、サポートされているモデルタイプ、関連モデル、およびそれぞれのモデルサービングエンドポイント設定要件をまとめたものです。
タイプ | 説明 | サポートされているモデル | 要件 |
|---|---|---|---|
事前展開モデル | これらの基盤モデルはDatabricksによってホストされており、 | これらのモデルは、バッチ推論と本番運用ワークフローを開始するためにサポートされ、最適化されています。
他のDatabricksホスト モデルはAI Functionsで使用できますが、大規模なバッチ推論本番運用ワークフローには推奨されません。 これらの他のモデルは、基盤モデルAPIsによる単位の従量課金を使用して推論に利用できるようになります。 | この機能を使用するには、Databricks Runtime 15.4 LTS 以降が必要です。エンドポイントのプロビジョニングや設定は必要ありません。これらのモデルの使用は、 適用可能なモデル開発者のライセンスと条件 、および AI Functions のリージョンの可用性の対象となります。 |
自分のモデルを持参する | 独自のモデルを持ち込み、 AI Functionsを使用してクエリを実行できます。 AI Functions は柔軟性を備えているため、リアルタイム推論またはバッチ推論のシナリオでモデルをクエリできます。 |
|
|
基盤モデルとai_queryの使用
次の例は、Databricks によってホストされる基盤モデルを使用して ai_query を使用する方法を示しています。
- 構文の詳細とパラメーターについては、
ai_query関数を参照してください。 - マルチモーダル入力クエリの例については、「マルチモーダル入力」を参照してください。
- 次のような高度なユースケースに合わせて を構成する方法については、高度なシナリオの例を参照してください。
- エラー処理には
failOnError - クエリ応答の構造化出力を指定する方法については、Databricks の構造化出力を参照してください。
- エラー処理には
SELECT text, ai_query(
"databricks-meta-llama-3-3-70b-instruct",
"Summarize the given text comprehensively, covering key points and main ideas concisely while retaining relevant details and examples. Ensure clarity and accuracy without unnecessary repetition or omissions: " || text
) AS summary
FROM uc_catalog.schema.table;
サンプルノートブック: バッチ推論と構造化データ抽出
次のサンプルノートブックは、 ai_queryを使用して基本的な構造化データ抽出を実行し、自動抽出技術によって生の非構造化データを整理された使用可能な情報に変換する方法を示しています。このノートブックでは、Mosaic AI Agent Evaluation を活用して、グラウンド トゥルース データを使用して精度を評価する方法も示します。
バッチ推論と構造化データ抽出ノートブック
従来のMLモデルでai_queryを使用する
ai_query は、従来の ML モデル (完全カスタムモデルを含む) をサポートします。これらのモデルは、モデルサービングエンドポイントにデプロイする必要があります。構文の詳細とパラメーターについては、ai_query関数を参照してください。
SELECT text, ai_query(
endpoint => "spam-classification",
request => named_struct(
"timestamp", timestamp,
"sender", from_number,
"text", text),
returnType => "BOOLEAN") AS is_spam
FROM catalog.schema.inbox_messages
LIMIT 10
サンプルノートブック: BERT を使用した名前付きエンティティ認識のバッチ推論
次のノートブックは、BERT を使用した従来の ML モデル バッチ推論の例を示しています。
BERT を使用した名前付きエンティティ認識ノートブックのバッチ推論
既存の Python ワークフローで AI 関数 を使用する
AI 関数 は、既存の Python ワークフローに簡単に統合できます。
次の例では、 ai_query の出力を出力テーブルに書き込みます。
df_out = df.selectExpr(
"ai_query('databricks-meta-llama-3-3-70b-instruct', CONCAT('Please provide a summary of the following text: ', text), modelParameters => named_struct('max_tokens', 100, 'temperature', 0.7)) as summary"
)
df_out.write.mode("overwrite").saveAsTable('output_table')
次の例では、要約されたテキストをテーブルに書き込みます。
df_summary = df.selectExpr("ai_summarize(text) as summary")
df_summary.write.mode('overwrite').saveAsTable('summarized_table')
本番運用 ワークフローでのAI関数
大規模なバッチ推論の場合、タスク固有のAI Functions 、または汎用関数ai_queryを、 Lakeflow Spark宣言型パイプライン、 Databricksワークフロー、構造化ストリーミングなどの本番運用ワークフローに統合できます。 これにより、本番運用レベルの大規模な処理が可能になります。 例と詳細については、 「バッチ推論パイプラインのデプロイ」を参照してください。
AI関数の進行状況を監視する
完了または失敗した推論の数を把握し、パフォーマンスのトラブルシューティングを行うには、クエリ プロファイル機能を使用してAI Functionsの進行状況を監視できます。
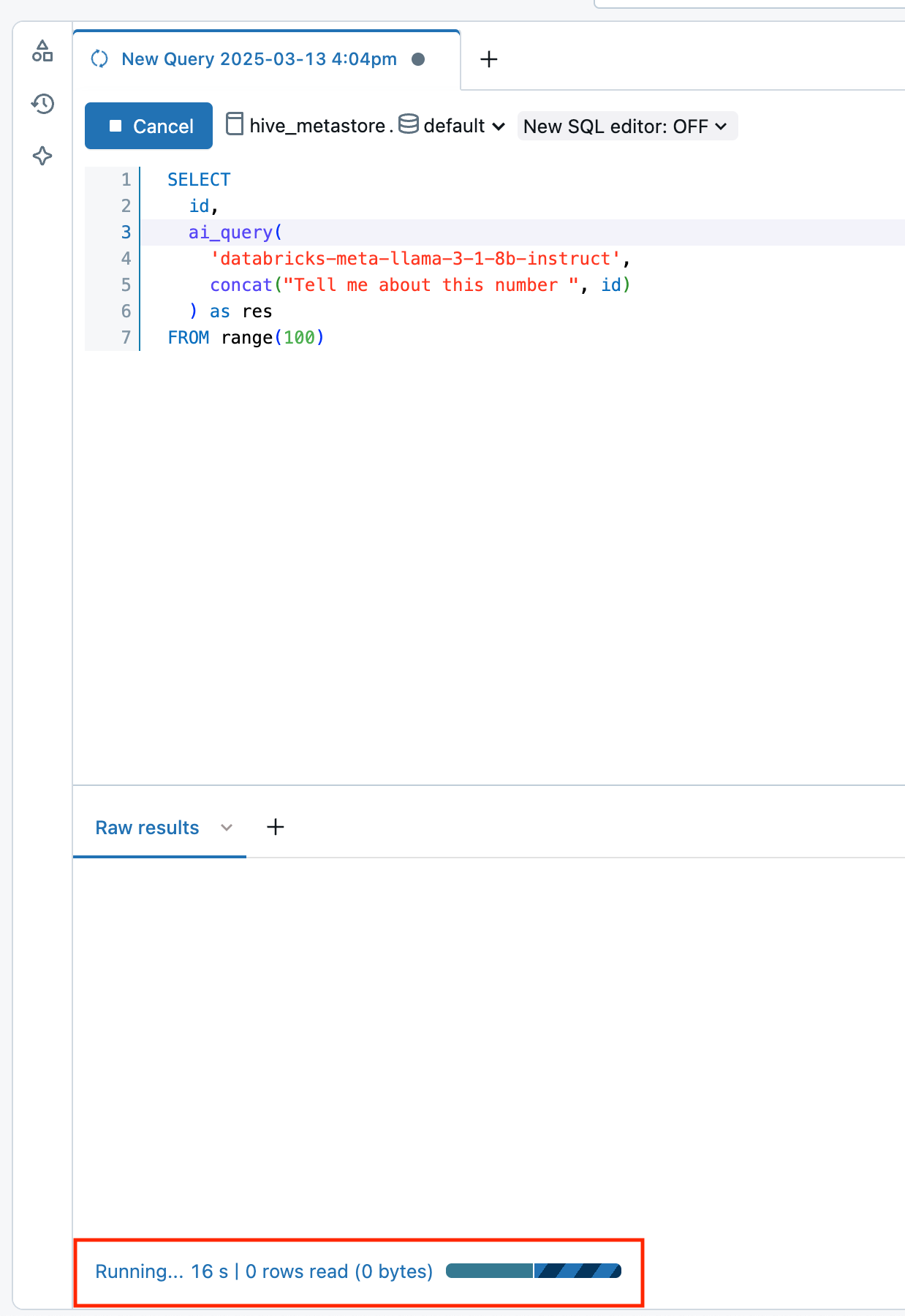
Databricks Runtime 16.1 ML 以降では、ワークスペースの SQL エディター クエリ ウィンドウから次の操作を行います。
- Raw results ウィンドウの下部にある Running--- リンクを選択します。右側に パフォーマンス ウィンドウが表示されます。
- 「 クエリ・プロファイルの表示 」をクリックして、パフォーマンスの詳細を表示します。
- AI Query をクリックすると、その特定のクエリのメトリクス (完了した推論と失敗した推論の数、リクエストの完了にかかった合計時間など) が表示されます。
AI 機能ワークロードのコストを表示する
AI 機能のコストは、 BATCH_INFERENCEオファリング タイプでMODEL_SERVING製品の一部として記録されます。クエリの例については、 「バッチ推論ワークロードのコストの表示」を参照してください。
ai_parse_documentの場合、コストはAI_FUNCTIONS製品の一部として記録されます。クエリの例については、 「 ai_parse_document実行のコストの表示」を参照してください。
バッチ推論ワークロードのコストを表示する
次の例は、ジョブ、コンピュート、 SQLウェアハウス、およびLakeflow Spark宣言型パイプラインに基づいてバッチ推論ワークロードをフィルターする方法を示しています。
AI Functionsを使用するバッチ推論ワークロードのコストを表示する方法の一般的な例については、「モデルサービング コストの監視」を参照してください。
- Jobs
- Compute
- Lakeflow Spark Declarative Pipelines
- SQL warehouse
次のクエリは、 system.workflow.jobsシステムテーブルを使用したバッチ推論にどのジョブが使用されているかを示します。 「システムテーブルを使用したジョブのコストとパフォーマンスの監視」を参照してください。
SELECT *
FROM system.billing.usage u
JOIN system.workflow.jobs x
ON u.workspace_id = x.workspace_id
AND u.usage_metadata.job_id = x.job_id
WHERE u.usage_metadata.workspace_id = <workspace_id>
AND u.billing_origin_product = "MODEL_SERVING"
AND u.product_features.model_serving.offering_type = "BATCH_INFERENCE";
次に、 system.compute.clusters システムテーブルを使用したバッチ推論に使用されているクラスターを示します。
SELECT *
FROM system.billing.usage u
JOIN system.compute.clusters x
ON u.workspace_id = x.workspace_id
AND u.usage_metadata.cluster_id = x.cluster_id
WHERE u.usage_metadata.workspace_id = <workspace_id>
AND u.billing_origin_product = "MODEL_SERVING"
AND u.product_features.model_serving.offering_type = "BATCH_INFERENCE";
以下は、 system.lakeflow.pipelinesシステムテーブルを使用したバッチ推論にどのLakeflow Spark宣言型パイプラインが使用されているかを示しています。
SELECT *
FROM system.billing.usage u
JOIN system.lakeflow.pipelines x
ON u.workspace_id = x.workspace_id
AND u.usage_metadata.dlt_pipeline_id = x.pipeline_id
WHERE u.usage_metadata.workspace_id = <workspace_id>
AND u.billing_origin_product = "MODEL_SERVING"
AND u.product_features.model_serving.offering_type = "BATCH_INFERENCE";
以下は、 system.compute.warehousesシステムテーブルを使用したバッチ推論にどのSQLウェアハウスが使用されているかを示しています。
SELECT *
FROM system.billing.usage u
JOIN system.compute.clusters x
ON u.workspace_id = x.workspace_id
AND u.usage_metadata.cluster_id = x.cluster_id
WHERE u.workspace_id = <workspace_id>
AND u.billing_origin_product = "MODEL_SERVING"
AND u.product_features.model_serving.offering_type = "BATCH_INFERENCE";
ai_parse_document回の実行のコストを表示
次の例は、課金システム テーブルをクエリして、 ai_parse_document実行のコストを表示する方法を示しています。
SELECT *
FROM system.billing.usage u
WHERE u.workspace_id = <workspace_id>
AND u.billing_origin_product = "AI_FUNCTIONS"
AND u.product_features.ai_functions.ai_function = "AI_PARSE_DOCUMENT";