サーバレスエグレスコントロールのネットワークポリシーの管理
このページでは、 Databricksでサーバーレス ワークロードからの送信ネットワーク接続を制御するネットワーク ポリシーを構成および管理する方法について説明します。
イングレス制御については、 「コンテキストベースのイングレス制御」を参照してください。
必要条件
-
Databricks ワークスペースは Enterprise レベルにある必要があります。
-
ネットワークポリシーを管理するための権限は、アカウント管理者に制限されています。
ネットワークポリシーへのアクセス
アカウントでネットワークポリシーを作成、表示、更新するには:
- アカウント コンソールから、 [セキュリティ] をクリックします。
- [ネットワーク] タブをクリックします。
- [ポリシー] の下で、 [コンテキストベースのイングレスおよびエグレス制御] をクリックします。
ネットワークポリシーを作成する
-
新しいネットワーク ポリシーの作成 をクリックします。
-
ポリシー名 を入力します。
-
[出力] タブをクリックします。
イングレス ルールを設定するには、 「イングレス ルールの設定」を参照してください。
-
ネットワークアクセスモードを選択します。
- すべての宛先へのアクセスを許可する : 無制限のアウトバウンド インターネット アクセス。 [フル アクセス ] を選択した場合、送信インターネット アクセスは制限されません。
- 特定の宛先へのアクセス制限 : 送信アクセスは指定された宛先に制限されます。
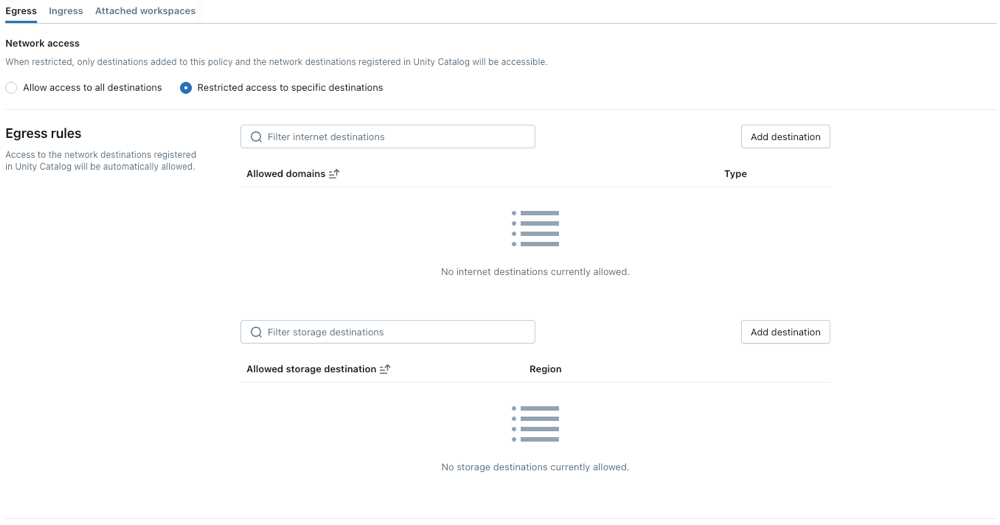
ネットワークポリシーの設定
次のステップでは、制限付きアクセス モードのオプション設定の概要を示します。
エグレス ルールを設定する
出力ルールを設定する前に、次の点に注意してください。
-
UC 外部ロケーションのメタストアバケットと S3 バケットバケットが異なるリージョンにある場合、アクセスを成功させるには、バケットをエグレス許可リストに明示的に追加する必要があります。
-
サポートされる宛先の最大数は 2500 です。
-
追加できるストレージ保存先の数 (
allowed_storage_destinations) は、ポリシーごとに100個に制限されています。 -
許可されたドメインとして追加できる FQDN の数は、ポリシーごとに 100 に制限されています。
-
ネットワーク ロード バランサーのプライベート リンク エントリとして追加されたドメインは、ネットワーク ポリシーで暗黙的に許可リストに登録されます。ドメインが削除されたり、プライベート エンドポイントが削除されたりすると、ネットワーク ポリシー制御によって変更が完全に適用されるまでに最大 24 時間かかる場合があります。VPC 内のリソースへのプライベート接続を構成するを参照してください。
-
OpenSharing バケットはネットワークポリシーで暗黙的に許可リストに登録されています。
Unity Catalog 接続の暗黙的な許可リストは非推奨です。廃止前に暗黙的な許可リストを使用していたワークスペースを含むアカウントの場合、この動作は限られた移行期間中は有効です。
-
サーバレス コンピュートに追加のドメインへのアクセス権を付与するには、 許可されたドメイン リストの上にある 宛先の追加 をクリックします。
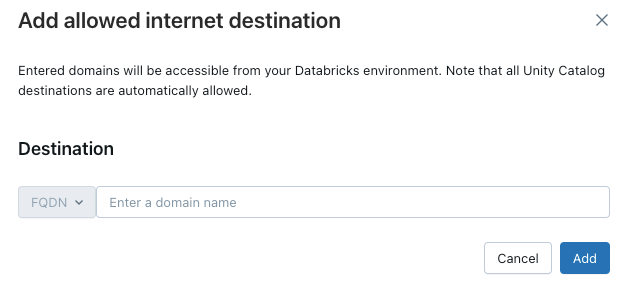
FQDNフィルタを使用すると、同じIPアドレスを共有するすべてのドメインにアクセスできます。
モデルサービング プロビジョニング スループット エンドポイントは、詳細な FQDN フィルタリングをサポートしていません。 ネットワークアクセスを制限付きに設定すると、これらのエンドポイントからのインターネットアクセスはすべてブロックされます。
-
ワークスペースが追加の S3 バケットにアクセスできるようにするには、 許可されたストレージの宛先 リストの上にある [宛先を追加 ] ボタンをクリックします。
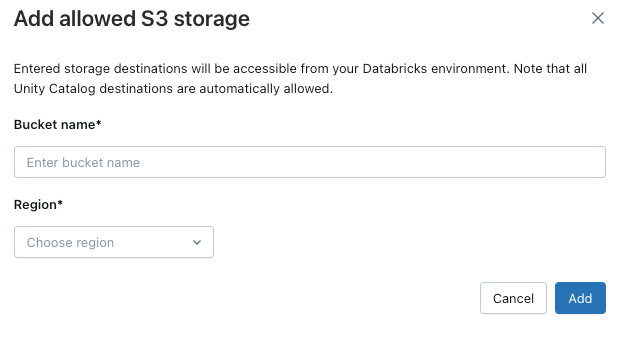
ワークスペースまたはすべてのワークスペースにバインドされた外部ストレージの場所のみが、ネットワーク ポリシーに自動的に含まれます。 場所がワークスペースにバインドされていることを確認するには、次のステップに従います。
- カタログ エクスプローラーで、[外部ロケーション] を開き、 [ワークスペース] タブをチェックして、ワークスペースが割り当てられていることを確認します。 「特定のワークスペースに外部ロケーションを割り当てる」を参照してください。
- API / CLI : ワークスペース バインディングを使用して、外部ロケーションのバインディングを取得します。
- API:ワークスペース バインディングを参照してください。
- CLI:
workspace-bindingsコマンド グループを参照してください。
追加のサービスにアクセスするには、有効な FQDN をすべて追加する必要があります。
REPL や UDF などのユーザー コード コンテナーからクラウド ストレージ サービスへの直接アクセスは、デフォルトでは許可されていません。このアクセスを有効にするには、ポリシーの [許可されたドメイン] にストレージ リソースの FQDN を追加します。ストレージ リソースのベース ドメインのみを追加すると、リージョン内のすべてのストレージ リソースへのアクセスが誤って許可されてしまう可能性があります。
ポリシーの施行
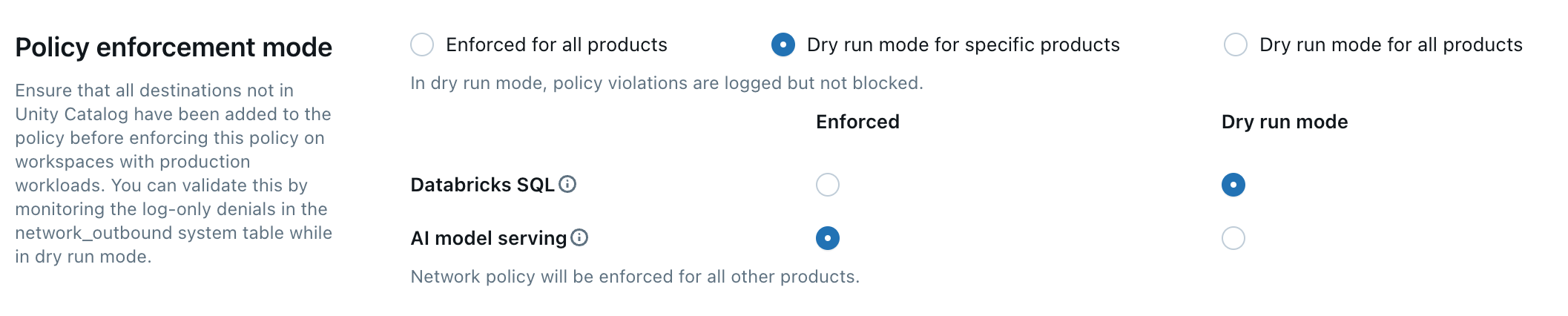
dry-run モードを使用すると、リソースへのアクセスを中断することなく、ポリシー設定をテストし、送信接続を監視できます。 dry-run モードが有効な場合、ポリシーに違反する要求はログに記録されますが、ブロックされません。 次のオプションから選択できます。
-
Databricks SQL :Databricks SQLウェアハウスはドライ実行モードで動作します。
-
AI モデルサービング : モデルサービング エンドポイントはドライ実行モードで動作します。
-
すべての製品 : すべての Databricks サービスはドライ実行モードで動作し、他のすべての選択をオーバーライドします。
インターネットの宛先をブロックする
この機能はパブリック プレビュー段階にあり、SEG対象のワークスペースで利用できます。まだSEG対象ではないEnterprise tier のワークスペースでは、ネットワークアクセスが**フルアクセス**に設定されている場合に限り、ブロックされた宛先はデフォルトのポリシーでのみサポートされます。
サーバレスワークロードからの特定のインターネットの宛先をブロックします。全体的な強制モードを切り替えることなく、既知の不正なドメインをブロックするための 制限付きアクセス モードの軽量な代替手段として、ブロックされた宛先を使用します。
ネットワークポリシーREST APIを介して、ブロックされた宛先を構成します。API にはアカウント管理者の OAuth トークンが必要です。個人用アクセストークンは、アカウントレベルのAPIsではサポートされていません。
OAuthマシン間認証を参照してください。
ブロックされた宛先は次のように動作します:
- 各エントリは、
destination(完全修飾ドメイン名、FQDN) と、DNS_NAMEのinternet_destination_typeを指定します。 - IP範囲とストレージの宛先はサポートされていません。
- ブロックされた宛先は、ポリシーのネットワークアクセスモードに関係なく常に適用されます。
- ブロックされた宛先は、許可された宛先よりも優先されます。
- 許可された宛先がブロックされた宛先のサブドメインである構成は、APIによって拒否されます。ただし、「広範囲に許可し、狭範囲にブロックする」パターンは許可されています(例:
example.comを許可し、api.example.comをブロックする)。
ネットワークアクセスが フルアクセス に設定されている場合でも、拒否ログは Unity Catalog の system.access.outbound_network テーブルに格納されます。拒否ログを確認するを参照してください。
インターネットの宛先をブロックするには:
-
ネットワークポリシーを取得します。次のコマンドを実行します:
<ACCOUNT_HOST>をaccounts.cloud.databricks.comに置き換えます。Bashcurl --location --request GET \
'https://<ACCOUNT_HOST>/api/2.0/accounts/<ACCOUNT_ID>/network-policies/<NETWORK_POLICY_ID>' \
--header 'Authorization: Bearer <OAUTH_TOKEN>'応答本文を
network-policy.jsonとして保存します。 -
egress.network_accessの下にblocked_internet_destinationsを追加するようにnetwork-policy.jsonを編集します。次の例は、 フルアクセス モードで単一のドメインをブロックします:JSON{
"network_policy_id": "my-policy",
"account_id": "...",
"egress": {
"network_access": {
"restriction_mode": "FULL_ACCESS",
"blocked_internet_destinations": [
{
"destination": "malicious-domain.example.com",
"internet_destination_type": "DNS_NAME"
}
]
}
}
} -
次のコマンドを使用して、更新されたポリシーを
PUTリクエストとともに同じエンドポイントに送信します。PUT本文には、完全なネットワークポリシーを含める必要があります。省略したフィールドはすべてクリアされます。Bashcurl --location --request PUT \
'https://<ACCOUNT_HOST>/api/2.0/accounts/<ACCOUNT_ID>/network-policies/<NETWORK_POLICY_ID>' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer <OAUTH_TOKEN>' \
--data @network-policy.json
Databricks CLI を使用して databricks account network-policies update-network-policy-rpc でネットワーク**ポリシー**を管理することも、**Terraform** の databricks_account_network_policy **リソース**を使用して管理することもできます。account network-policiesコマンド・グループを参照してください。
デフォルトポリシーを更新する
各 Databricks アカウントには 、デフォルト ポリシー が含まれています。 デフォルト・ポリシーは 、明示的にネットワーク・ポリシーが割り当てられていないすべてのワークスペース(新しく作成されたワークスペースを含む)に関連付けられます。このポリシーは変更できますが、削除することはできません。
デフォルト ポリシーは、少なくとも Enterprise レベルのワークスペースにのみ適用されます。
ネットワークポリシーをワークスペースに関連付ける
デフォルトのポリシーを追加の設定で更新した場合、既存のネットワークポリシーがないワークスペースにも自動的に適用されます。
ワークスペースは Enterprise レベルである必要があります。
ワークスペースを別のポリシーに関連付けるには、次の操作を行います。
- ワークスペースを選択します。
- ネットワーク ポリシー で、 ネットワーク ポリシーの更新 をクリックします。
- リストから目的のネットワークポリシーを選択します。
- [ポリシーの適用]を クリックします。
ネットワーク ポリシーの変更を適用する
ほとんどのネットワーク設定の更新は、10 分で自動的にサーバレス コンピュートに反映されます。 これには以下が含まれます。
- 新しい Unity Catalog 外部ロケーションまたは接続を追加する。
- ワークスペースを別のメタストアにアタッチする。
- 許可されたストレージまたはインターネットの宛先を変更します。
インターネットアクセスまたはドライ実行モードの設定を変更する場合は、コンピュートを再起動する必要があります。
サーバレスワークロードの再起動または再デプロイ
更新する必要があるのは、インターネットアクセスモードを切り替えるとき、またはドライ実行モードを更新するときだけです。
適切な再始動手順を決定するには、以下の製品別リストを参照してください。
- Databricks ML Serving : ML サービング エンドポイントを再デプロイします。 カスタム モデルサービング エンドポイントを作成するを参照してください。
- パイプライン : 実行中の LakeFlow Pipelines を停止してから再起動します。「パイプラインの更新を実行する」を参照してください。
- サーバレス SQLウェアハウス : SQLウェアハウスを停止して再起動します。 SQLウェアハウスの管理を参照してください。
- Lakeflow ジョブ : ネットワーク ポリシーの変更は、新しいジョブ実行がトリガーされたとき、または既存のジョブ実行が再開されたときに自動的に適用されます。
- ノートブック :
- ノートブックがSparkと対話しない場合は、ネットワーク ポリシーを更新するために、サーバレス コンピュートを終了して再アタッチできます。
- ノートブックが Sparkと対話すると、サーバレス リソースが更新され、変更が自動的に検出されます。 ほとんどの変更は 10 分で更新されますが、インターネット アクセス モードの切り替え、ドライ実行モードの更新、または適用の種類が異なるアタッチされたポリシー間の変更には、最大 24 時間かかる場合があります。 これらの特定の種類の変更の更新を迅速化するには、関連付けられているすべてのノートブックとジョブをオフにします。
宣言型自動化バンドルのUI依存関係
制限付きアクセスモードを レス 出力制御とともに使用すると、Declarative Automation Bundles UI 機能は特定の外部ドメインへのアクセスを必要とします。 アウトバウンドアクセスが完全に制限されている場合、ユーザーは宣言型自動化バンドルを操作する際に、ワークスペースインターフェイスでエラーが表示される可能性があります。
宣言的オートメーション バンドルの UI 機能が制限されたネットワーク ポリシーで動作し続けるようにするには、 ポリシーの許可されたドメイン に次のドメインを追加します。
- github.com
- objects.githubusercontent.com
- release-assets.githubusercontent.com
- checkpoint-api.hashicorp.com
- releases.hashicorp.com
- registry.terraform.io
ネットワーク ポリシーの適用を確認する
ネットワーク ポリシーが正しく適用されていることを確認するには、さまざまなサーバレス ワークロードから制限されたリソースへのアクセスを試みます。 検証プロセスは、サーバレス製品によって異なります。
- Lakeflow pipelines
- Databricks SQL
- Model serving
-
Python ノートブックを作成します。LakeFlow Pipelines Wikipedia Python チュートリアルで提供されているサンプル ノートブックを使用できます。
-
パイプラインを作成します。
-
ワークスペースで、サイドバーの
 Jobs & パイプライン をクリックします。
Jobs & パイプライン をクリックします。 -
「作成 」をクリックし、「 ETL パイプライン」 をクリックします。
-
次の設定でパイプラインを構成します。
- パイプライン Mode : サーバレス
- ソース コード : 作成したノートブックを選択します。
- ストレージオプション : Unity Catalog。 目的のカタログとスキーマを選択します。
-
作成 をクリックします。
-
-
パイプラインを実行します。
-
パイプライン ページで、 開始 をクリックします。
-
パイプラインが完了するまで待ちます。
-
結果を確認する
- 信頼できる宛先 : パイプラインは正常に実行され、宛先にデータを書き込みます。
- 信頼できない宛先 : パイプラインはエラーで失敗し、ネットワーク アクセスがブロックされていることを示します。
Databricks SQL による検証
-
SQLウェアハウスを作成します。
-
SQL エディタでテストクエリを実行し、ネットワークポリシーによって制御されるリソースへのアクセスを試みます。
-
結果を確認します。
- 信頼できる宛先 : クエリは成功します。
- 信頼できない宛先 : クエリはネットワーク アクセス エラーで失敗します。
-
標準の Python ライブラリを使用して UDF からネットワークに接続するには、次の UDF 定義を実行します。
SQLCREATE OR REPLACE TEMPORARY FUNCTION ping_google(value DOUBLE)
RETURNS STRING
LANGUAGE python
AS $$
import requests
url = "https://www.google.com"
response = requests.get(url, timeout=5)
if response.status_code == 200:
return "UDF has network!"
else:
return "UDF has no network!"
$$;
モデルサービングで検証
始める前に
モデルサービング エンドポイントが作成されると、モデルを提供するコンテナ イメージが構築されます。 ネットワーク ポリシーは、このビルド ステージ中に適用されます。ネットワークポリシーでモデルサービングを使用する場合は、次の点を考慮してください。
-
依存関係アクセス: PyPI や conda-forge の Python パッケージ、ベース コンテナ イメージ、モデルの環境やモデルの環境で必要な Docker コンテキストで指定された外部 URL のファイルなど、外部ビルドの依存関係は、ネットワーク ポリシーで許可する必要があります。
- たとえば、モデルでビルド中にダウンロードする必要がある特定のバージョンの scikit-learn が必要な場合、ネットワーク ポリシーでパッケージをホストしているリポジトリへのアクセスを許可する必要があります。
-
ビルドの失敗: ネットワークポリシーが必要な依存関係へのアクセスをブロックしている場合、モデルサービングコンテナのビルドは失敗します。これにより、サービングエンドポイントのデプロイが正常に行われなくなり、正しく保存または機能しなくなる可能性があります。拒否ログの確認を参照してください。
-
拒否のトラブルシューティング: ビルド フェーズ中のネットワーク アクセス拒否はログに記録されます。これらのログには、値
ML Buildのnetwork_source_typeフィールドがあります。この情報は、ビルドを正常に完了するためにネットワーク ポリシーに追加する必要がある特定のブロックされたリソースを特定するために重要です。
ランタイム・ネットワーク・アクセスの検証
次の手順では、デプロイされたモデルのネットワーク ポリシー をランタイムで検証する方法、特に推論中に外部リソースにアクセスしようとする試みについて検証する方法を示します。 これは、モデルサービングコンテナが正常にビルドされた、つまり、ビルド時の依存関係がネットワークポリシーで許可されていることを前提としています。
-
テストモデルの作成
-
Python ノートブックで、推論時にパブリック インターネット リソースへのアクセスを試みるモデル (ファイルのダウンロードや API 要求の作成など) を作成します。
-
このノートブックを実行して、テスト ワークスペースにモデルを生成します。 例えば:
Pythonimport mlflow
import mlflow.pyfunc
import mlflow.sklearn
import requests
class DummyModel(mlflow.pyfunc.PythonModel):
def load_context(self, context):
# This method is called when the model is loaded by the serving environment.
# No network access here in this example, but could be a place for it.
pass
def predict(self, _, model_input):
# This method is called at inference time.
first_row = model_input.iloc[0]
try:
# Attempting network access during prediction
response = requests.get(first_row['host'])
except requests.exceptions.RequestException as e:
# Return the error details as text
return f"Error: An error occurred - {e}"
return [response.status_code]
with mlflow.start_run(run_name='internet-access-model'):
wrappedModel = DummyModel()
# When this model is deployed to a serving endpoint,
# the environment will be built. If this environment
# itself (e.g., specified conda_env or python_env)
# requires packages from the internet, the build-time serverless network policy applies.
mlflow.pyfunc.log_model(
artifact_path="internet_access_ml_model",
python_model=wrappedModel,
registered_model_name="internet-http-access"
)
-
-
配信エンドポイントを作成する
-
ワークスペースのナビゲーションで、 [AI/ML] を選択します。
-
サービング タブをクリックします。
-
サービングエンドポイントの作成 をクリックします。
-
次の設定でエンドポイントを構成します。
- サービングエンドポイント名 : わかりやすい名前を指定します。
- エンティティの詳細 : モデル レジストリ モデル を選択します。
- モデル : 前の手順で作成したモデルを選択します (
internet-http-access)。
-
[確認] をクリックします。この段階で、モデルサービングコンテナのビルドプロセスが開始されます。
ML Buildのネットワークポリシーが適用されます。依存関係のネットワーク アクセスがブロックされたためにビルドが失敗した場合、エンドポイントは準備完了になりません。 -
サービス エンドポイントが [準備完了 ] 状態に達するまで待ちます。準備完了にならない場合は、拒否ログで
network_source_type: ML Buildエントリを確認します。「拒否ログを確認する」を参照してください。
-
-
エンドポイントをクエリします。
-
[サービス エンドポイント] ページの [クエリ エンドポイント ] オプションを使用して、テスト要求を送信します。
JSON{ "dataframe_records": [{ "host": "[https://www.google.com](https://www.google.com)" }] }
-
-
実行時アクセスの結果を確認します。
- ランタイムでインターネットアクセスが有効 : クエリは成功し、
200のようなステータスコードを返します。 - ランタイムでのインターネット アクセス制限 : クエリは、モデル コード内の
try-exceptブロックからのエラー メッセージなど、接続タイムアウトまたはホスト解決エラーを示すネットワーク アクセス エラーで失敗します。
- ランタイムでインターネットアクセスが有効 : クエリは成功し、
ネットワークポリシーを更新する
ネットワーク ポリシーは、作成後いつでも更新できます。 ネットワークポリシーを更新するには:
-
アカウントコンソールのネットワークポリシーの詳細ページで、ポリシーを変更します。
- ネットワークアクセスモードを変更します。
- 特定のサービスのドライ実行モードを有効または無効にします。
- FQDN またはストレージの宛先を追加または削除します。
-
更新 をクリックします。
-
ネットワーク ポリシーの変更を適用する を参照して、更新プログラムが既存のワークロードに適用されることを確認します。
拒否ログを確認する
拒否ログは Unity Catalog のsystem.access.outbound_networkテーブルに保存されます。これらのログは、送信ネットワーク要求が拒否されたタイミングを追跡します。拒否ログにアクセスするには、Unity Catalog メタストアでアクセス スキーマが有効になっていることを確認します。「システムテーブルを有効にする」を参照してください。
次のような SQL クエリを使用して、拒否イベントを表示します。 dry-run logs が有効になっている場合、クエリは拒否ログと dry-run ログの両方を返します。これらは access_type 列を使用して区別できます。 拒否ログには DROP 値がありますが、dry-run ログには DRY_RUN_DENIAL が表示されます。
次の例では、過去 2 時間のログを取得します。
SELECT *
FROM system.access.outbound_network
WHERE event_time >= CURRENT_TIMESTAMP() - INTERVAL 2 HOUR
ORDER BY event_time DESC;
dry-run モードと external 生成AI モデルの場合、次のようになります。
- ネットワーク ポリシーが必要な依存関係へのアクセスをブロックしている場合は、まず
system.access.outbound_networkの拒否ログを確認します。さらに、モデルサービングコンテナのビルドログは、ブロックされたドメインに関する有用な情報を提供する場合があります。 - モデルサービングコンテナのビルドが失敗した場合は、
system.access.outbound_networkの拒否ログを確認して、ブロックされたドメインを特定します。 - モデルサービングによる外部モデルへのアクセスの強制は、ドライ実行モードでも継続されます。
アクセス時から拒否ログが表示されるまでの間に、知覚可能な遅延が発生する可能性があります。
制限
-
アーティファクトのアップロードサイズ : MLflowの内部 Databricks Filesystem を
dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<artifactPath>形式で使用する場合、アーティファクトのアップロードはlog_artifact、log_artifacts、およびlog_modelAPIで5GBに制限されます。 -
短時間のみ有効なガベージコレクション (GC) ワークロードのログ配信拒否 : 存続時間が 120 秒未満の短時間 GC ワークロードからのログ拒否ログは、ログの遅延によりノードが終了する前に配信されない場合があります。アクセスは引き続き適用されますが、対応するログ エントリが欠落している可能性があります。
-
Databricks SQL ユーザー定義関数 (UDF) のネットワーク接続 : Databricks SQL でネットワーク アクセスを有効にするには、Databricks アカウント チームにお問い合わせください。
-
パイプラインイベントフックのログ記録 :別のワークスペースを対象とするLakeFlow Pipelinesイベントフックはログに記録されません。これは、クロスリージョンワークスペースと、同じリージョン内のワークスペースの両方に構成されたEventhooksに適用されます。
-
Unity Catalogワークスペース バインディングの変更 : Unity Catalogワークスペース バインディングへの変更が有効になるまでに最大 24 時間かかる場合があります。 このプロセスを迅速化するには、ストレージバケットをネットワークポリシーに追加してください。ワークスペースカタログのバインディングを参照してください。
-
リージョンをまたいだUnity Catalog S3ロケーションヘのネットワークアクセス AWS メタストアとは異なる リージョンにある 外部ロケーションに使用される バケットは、サーバレス ネットワーク ポリシーによって自動的に許可されません。これらのクロスリージョン S3 ロケーションは、サーバレスワークロードからのアクセスを有効にするために、ネットワークポリシーの許可された宛先に明示的に追加する必要があります。
次のステップ
- コンテキストベースのイングレス制御を構成する : ID、リクエストの種類、ネットワーク ソースに基づいて受信アクセス ポリシーを定義し、ワークスペース アクセスを保護します。コンテキストベースのイングレス制御を参照してください。
- プライベートエンドポイントルールの管理 : セキュリティ強化のために接続を許可または拒否する特定のルールを定義することで、プライベートエンドポイントとの間のネットワークトラフィックを制御します。「プライベートエンドポイントルールの管理」を参照してください。
- サーバレス コンピュート アクセス用のファイアウォールを構成する :お客様のサーバレス コンピュート環境に対する送受信ネットワーク接続を制限および保護するために、ファイアウォールを実装します。サーバレス コンピュート ファイアウォールの設定を参照してください。
- データ転送と接続コストを理解する :ネットワークセキュリティ制御とプライベート接続を実装する際のコストへの影響について学びます。 レスワークロード。 Databricksのネットワークコストについて理解するを参照してください。