Unity Catalog ボリュームとは
ボリュームは、表形式以外のデータセットに対するガバナンスを可能にする Unity Catalog オブジェクトです。 ボリュームは、クラウド・オブジェクト・ストレージ・ロケーション内のストレージの論理ボリュームを表します。 ボリュームは、ファイルへのアクセス、保存、管理、および整理の機能を提供します。
テーブルは表形式データを管理しますが、ボリュームは構造化、半構造化、非構造化など、あらゆる形式の非表形式データを管理します。
Databricks では、ボリュームを使用して、すべての非表形式データへのアクセスを管理することをお勧めします。ボリュームには、次の 2 つのタイプがあります。
- 管理対象ボリューム: シンプルな Databricks マネージド ストレージ用。
- 外部ボリューム: 既存のクラウド・オブジェクト・ストレージの場所にガバナンスを追加します。
個人的な作業や探索的な作業のためにファイルを保存する場合、カタログ、スキーマ、およびボリュームを最初に作成することなく、ユーザーごとのボリュームである「マイファイル」をご利用いただけます。マイファイルはベータ版です。「マイファイルにファイルを保存する」を参照してください。
ビデオウォークスルー
このビデオではUnity Catalogボリュームの操作方法を説明します (3 分)。
ボリュームの使用例
ボリュームの使用例は次のとおりです。
- ETLパイプラインやその他のデータ エンジニアリング アクティビティの初期段階での処理をサポートするために、外部システムによって生成された生データのランディング エリアを登録します。
- 登録する インジェストのステージング場所。 たとえば、Auto Loader、
COPY INTO、または CTAS (CREATE TABLE AS) ステートメントを使用します。 - data scientists 、データ アナリスト、機械学習エンジニアが探索的データ分析やその他のデータサイエンス タスクの一部として使用できるファイルの保存場所を提供します。
- Databricks ユーザーに、他のシステムによって生成およびクラウド ストレージに格納された任意のファイルへのアクセスを許可します。たとえば、監視システムやIoTデバイスによってキャプチャされた非構造化データ(画像、オーディオ、ビデオ、PDFファイルなど)の大規模なコレクションや、ローカルの依存関係管理システムやCI/CDパイプラインからエクスポートされたライブラリファイル(JARファイルやPython wheelファイル)などです。
- ログ記録ファイルやチェックポイント設定ファイルなどの運用データを格納します。
ボリュームの操作のデモについては、「 Unity Catalog ボリュームを使用したファイル、イメージ、およびデータの取得の簡略化」を参照してください。
ボリューム内のファイルを Unity Catalog のテーブルとして登録することはできません。ボリュームは、パスベースのデータ・アクセスのみを目的としています。テーブルは、Unity Catalog で表形式データを操作する場合は使用します。
管理ボリュームと外部ボリューム
マネージドボリュームと外部ボリュームは、 Databricks ツール、UI、および APIsを使用する場合に、ほぼ同じエクスペリエンスを提供します。 主な違いは、保管場所、ライフサイクル、および制御に関連しています。
機能 | 管理対象ボリューム | 外部ボリューム |
|---|---|---|
ストレージロケーション | スキーマの UC 管理ストレージ内に作成されます。 | 既存のクラウド・オブジェクト・ストレージ・パスに対して登録されている |
データライフサイクル | UC はレイアウトと削除を管理します (削除時に 7 日間保持) | ボリュームを削除しても、データはクラウドストレージに残ります |
アクセス制御 | すべてのアクセスはUCを経由します | UC はアクセスを管理しますが、外部ツールは直接 URI を使用できます |
移行が必要ですか? | No | いいえ:既存のストレージ・パスをそのまま使用します |
一般的な使用例 | Databricks のみのワークロードの最も簡単なオプション | Databricks と外部システム アクセスの混在 |
管理対象ボリュームを使用する理由
管理対象ボリュームには、次の利点があります。
- Databricksワークロードのデフォルト選択。
- クラウド認証情報やストレージパスを手動で管理する必要はありません。
- 管理されたストレージの場所を迅速に作成するための最も簡単なオプション。
外部ボリュームを使用する理由とは?
外部ボリュームを使用すると、Unity Catalog データガバナンスを既存のクラウドオブジェクトストレージディレクトリに追加できます。 外部ボリュームの使用例には、次のようなものがあります。
- データのコピーを必要とせずに、データがすでに存在する場所にガバナンスを追加します。
- Databricks によって取り込まれるかアクセスする必要がある他のシステムによって生成されたファイルを管理します。
- 他のシステムからクラウドオブジェクトストレージから直接アクセスする必要がある Databricks によって生成されたデータを管理します。
Databricks では、Databricks に加えて外部システムによって読み取りまたは書き込みされるテーブル形式以外のデータ ファイルを保存するには、外部ボリュームを使用することをお勧めします。Unity Catalog は、外部システムからのクラウドオブジェクトストレージに対して直接実行される読み取りと書き込みを管理しません。そのため、Databricks の外部で以下のいずれかの方法を使用して追加のガバナンスを適用する必要があります:
- Unity Catalog から有効期間の短い資格情報を付与する :外部エンジンを構成して、Unity Catalog から有効期間の短い資格情報を要求するようにします。付与された資格情報は、要求元のプリンシパルの Unity Catalog の特権を継承し、これにより、承認の信頼できる唯一のソースとして Unity Catalog が維持されます。Unity Catalog 外部システムアクセス用の Unity Catalog クレデンシャルベンディングをご覧ください。
- クラウドネイティブのアクセス制御を構成する:クラウドプロバイダーのIAMポリシー、バケットポリシー、または基になるストレージの場所にあるアクセス制御リストを使用して、直接アクセスを制限します。外部システムからのアクセスが Unity Catalog のアクセスと一致するように、これらのコントロールをボリュームに付与した Unity Catalog の権限と整合させる必要があります。Unity Catalog がクラウドストレージに接続する方法の背景については、「Unity Catalog を使用したクラウドオブジェクトストレージへの接続」を参照してください。
ボリューム内のファイルにアクセスするためのパス
ボリュームは、Unity Catalog の 3 レベル名前空間 (catalog.schema.volumeの 3 番目のレベルにあります。
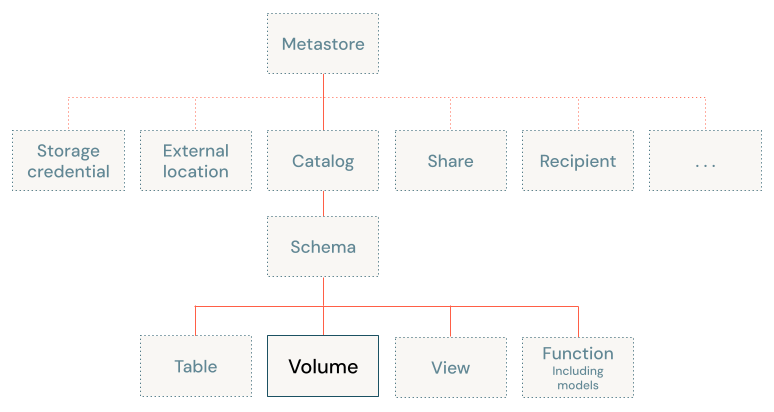
ボリュームへのアクセスパスは、Apache Spark、SQL、Python、またはその他の言語やライブラリのいずれを使用する場合でも同じです。 これは、Databricks ワークスペースにバインドされたオブジェクト ストレージ内のファイルに対する従来のアクセス パターンとは異なります。
ボリューム内のファイルにアクセスするためのパスは、次の形式を使用します。
/Volumes/<catalog>/<schema>/<volume>/<path>/<file-name>
Databricks では、Apache Spark を使用する場合、オプションの dbfs:/ スキームもサポートされているため、次のパスも機能します。
dbfs:/Volumes/<catalog>/<schema>/<volume>/<path>/<file-name>
パスの /<catalog>/<schema>/<volume> 部分は、ファイルの 3 つの Unity Catalog オブジェクト名にマップされます。これらのディレクトリは読み取り専用であり、Unity Catalog によって自動的に管理されます。ファイルシステムコマンドで作成または削除することはできません。
また、クラウドストレージのURIを使用して、外部ボリューム内のデータにアクセスすることもできます。
ボリューム用のリザーブドパス
ボリュームでは、ボリュームへのアクセスに使用される次の予約済みパスが導入されています。
dbfs:/Volumes/Volumes
パスは、/volumes、/Volume、/volumeなど、Apache Spark APIs と dbutilsのこれらのパスの潜在的なタイプミスのために予約されており、前に dbfs:/が付くかどうかに関係なく、 。パス /dbfs/Volumes も予約されていますが、ボリュームへのアクセスには使用できません。
ボリュームは、Databricks Runtime 13.3 LTS 以降でのみサポートされます。 Databricks Runtime 12.2 LTS 以前では、/Volumes パスに対する操作は成功する可能性がありますが、コンピュート クラスターにアタッチされたエフェメラル ストレージ ディスクにのみデータを書き込むことができます。これは、期待どおりにデータを Unity Catalog ボリュームに永続化するのではなく、コンピュート クラスターにアタッチされています。
DBFSルートの予約済みパスに既存のデータが保存されている場合は、サポート チケットを提出して、このデータに一時的にアクセスして別の場所に移動します。
コンピュートの要件
ボリュームを操作する場合は、カタログエクスプローラーなどのDatabricks UI を使用していない限り、SQLウェアハウスまたは 13.3 LTS 以降Databricks Runtime実行されているクラスターを使用する必要があります。
ボリューム内のDataFrameチェックポイントの保存について詳しくは、 「ボリューム内のDataFrameチェックポイント」を参照してください。
制限
Unity CatalogUnity Catalogボリュームを操作するには、対応コンピュートを使用する必要があります。
次の表は、Databricks Runtime のバージョンに基づく Unity Catalog のボリューム制限の概要を示しています。
Databricks Runtimeのバージョン | 制限事項 |
|---|---|
サポートされているすべての Databricks Runtime バージョン |
|
14.3 LTS以上 |
|
14.2 以下 |
|
その他のリソース
次の記事では、ボリュームの操作に関する詳細情報を提供します。