ジョブコンピュートの設定
LakeFlow Jobのタスクに対してサーバレスまたはクラシックコンピュートを構成し、各タスクに適切なタイプを選択します。
ジョブ用サーバレスコンピュートには、次のような制限があります。
- 継続的な スケジューリングは、
Trigger.AvailableNowなどの境界付き構造化ストリーミングトリガーでのみサポートされています。ジョブを継続的に実行するを参照してください。 - 構造化ストリーミングでは、デフォルトまたは時間ベースのインターバルトリガーはサポートされていません。
その他の制限事項については、 サーバレス コンピュートの制限事項を参照してください。
各ジョブには、1 つ以上のタスクを含めることができます。 コンピュート リソースは、タスクごとに定義します。 同じジョブに対して定義された複数のタスクは、同じコンピュート リソースを使用できます。
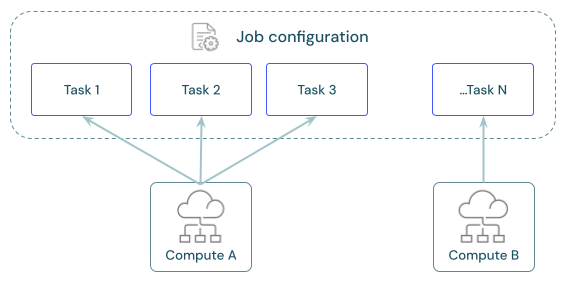
各タスクの推奨コンピュート
次の表は、各タスクの種類で推奨およびサポートされているコンピュートの種類を示しています。
サーバレス コンピュート for ジョブには制限があり、すべてのワークロードをサポートしているわけではありません。 サーバレス コンピュートの制限事項を参照してください。
タスク | 推奨コンピュート | 対応コンピュート |
|---|---|---|
ノートブック | サーバレス ジョブ | ジョブ用サーバレス、ジョブ用クラシック、汎用クラシック |
Pythonスクリプト | サーバレス ジョブ | ジョブ用サーバレス、ジョブ用クラシック、汎用クラシック |
Python Wheel | サーバレス ジョブ | ジョブ用サーバレス、ジョブ用クラシック、汎用クラシック |
SQL | サーバレス SQLウェアハウス | サーバレス SQLウェアハウス、pro SQLウェアハウス |
Lakeflowパイプライン | サーバレス パイプライン | サーバレス パイプライン、クラシックパイプライン |
dbt | サーバレス SQLウェアハウス | サーバレス SQLウェアハウス、pro SQLウェアハウス |
dbt CLI コマンド | サーバレス ジョブ | ジョブ用サーバレス、ジョブ用クラシック、汎用クラシック |
JAR | クラシックジョブ | クラシックジョブ、クラシック汎用 |
Spark Submit | クラシックジョブ | クラシックジョブ |
Lakeflowジョブの価格は、タスクの実行に使用されるコンピュートに関連付けられています。詳細については、「 Databricks の価格」を参照してください。
ジョブコンピュートの設定
クラシック ジョブ コンピュートは Lakeflow ジョブ UI から直接設定され、これらの設定はジョブ定義の一部です。 他のすべての使用可能なコンピュート タイプは、他のワークスペース アセットと共に構成を保存します。 次の表に詳細を示します。
クラスタータイプ | 詳細 |
|---|---|
クラシックジョブコンピュート | クラシックジョブのコンピュートは、汎用コンピュートと同じUIと設定を使用して設定します。 コンピュート設定リファレンスを参照してください。 |
ジョブ用サーバレスコンピュート | ジョブ用サーバレス コンピュートは、それをサポートするすべてのタスクのデフォルトです。 Databricks サーバレス コンピュートのコンピュート設定を管理します。 ワークフローのためにサーバレスコンピュートを用いたLakeflowジョブの実行 を参照してください。 |
SQLウェアハウス | サーバレスと Pro SQLウェアハウスは、ワークスペース管理者または無制限のクラスター作成権限を持つユーザーによって構成されます。 既存の SQLウェアハウスに対してタスクを実行するように構成します。 SQLウェアハウスへの接続を参照してください。 |
LakeFlow Pipelines コンピュート | パイプラインの構成中に、LakeFlow Pipelines のコンピュート設定を構成します。パイプラインのクラシック コンピュートを構成するを参照してください。Databricks は、Serverless LakeFlow Pipelines のコンピュートリソースを管理します。Serverlessパイプラインを構成するを参照してください。 |
汎用コンピューティング | オプションで、従来の汎用コンピュートを使用してタスクを設定できます。Databricks では、この構成を本番運用ジョブにはお勧めしません。コンピュート設定リファレンスおよび限定的な例外を参照してください。 |
タスクにおけるコンピュートの共有
同じジョブ コンピュート リソースを使用するようにタスクを構成して、複数のタスクを調整するジョブでリソースの使用を最適化します。 タスク間でコンピュートを共有すると、起動時間に関連するレイテンシーを短縮できます。
1 つのジョブ コンピュート リソースを使用して、ジョブの一部であるすべてのタスクを実行したり、特定のワークロード用に最適化された複数のジョブ リソースを実行したりできます。 ジョブの一部として設定されたジョブコンピュートは、ジョブ内の他のすべてのタスクで使用できます。
次の表は、1 つのタスク用に構成されたジョブ コンピュートと、タスク間で共有されるジョブ コンピュートの違いを示しています。
1 つのタスク | タスク間で共有 | |
|---|---|---|
起動 | タスクの実行が開始されたとき。 | コンピュート リソースを使用するように構成された最初のタスク実行が開始されると、そのタスク実行が開始されます。 |
終了 | タスクの実行後。 | 最後のタスクの後、コンピュート リソースを使用するように構成しました。 |
アイドルコンピュート | 該当なし。 | コンピュートはオンでアイドル状態のままで、タスクはコンピュート リソースを使用していません。 |
共有ジョブ クラスターは、スコープが 1 つのジョブ実行に限定され、他のジョブや同じジョブの実行では使用できません。
ライブラリは、共有ジョブ クラスター構成で宣言することはできません。 タスク設定で依存ライブラリを追加する必要があります。
タスク間で共有されるドライバの状態
複数のタスクがジョブ コンピュート リソースを共有する場合、タスクは同じドライバーJVM上で実行されます。 クラスの状態とシングルトンは、ジョブ実行期間中、タスク間で保持されます。ほとんどのワークロードではこれは透過的ですが、以下の点に注意してください。
- Scalaのシングルトンとコンパニオンオブジェクトは、タスク間で共有されます。 Scalaコンパニオン オブジェクトの変更可能な状態は、同じ共有クラスター上で実行されるタスク間で持続します。 並列タスクが同じコンパニオン オブジェクト変数に対して読み取りまたは書き込みを行う場合、あるタスクの値が別のタスクの値を上書きする可能性があります。 実際の例については、ナレッジベースの記事「不正な値を使用したマルチタスク ワークフロー」を参照してください。
- 1 つのタスクによってロードされたライブラリは、ジョブの実行期間中、後続のタスクで利用可能なままになります 。
コードでタスクレベルの分離が必要な場合は、以下のいずれかの方法を使用してください。
- 個別のジョブ コンピュート リソースを使用するように各タスクを構成します。
- 明示的なタスクの依存関係を追加して、タスクが並列ではなく順次に実行されるようにします。
- シングルトンや共有可変状態に依存しないようにコードをリファクタリングしてください。たとえば、コンパニオン オブジェクトから読み取るのではなく、各関数に明示的に問題を渡します。
ジョブコンピュートのレビュー、構成、スワップ
「 ジョブの詳細 」ペインの「 コンピュート 」セクションには、現在のジョブのタスク用に構成されているすべてのコンピュートが一覧表示されます。
コンピュート リソースを使用するように構成されたタスクは、コンピュート仕様にカーソルを合わせると、タスク グラフで強調表示されます。
スワップ ボタンを使用して、コンピュート リソースに関連付けられているすべてのタスクのコンピュートを変更します。
クラシック ジョブ コンピュート リソースには [構成] オプションがあります。 その他のコンピュート リソースには、コンピュート構成の詳細を表示および変更するオプションがあります。
その他のリソース
Databricks クラシック ジョブの設定の詳細については、Lakeflow ジョブのクラシック コンピュートの設定を参照してください。