MLOps Stacks: model development process as code
This article describes how MLOps Stacks lets you implement the development and deployment process as code in a source-controlled repository. It also describes the benefits of model development on the Databricks Data Intelligence platform, a single platform that unifies every step of the model development and deployment process.
What is MLOps Stacks?
With MLOps Stacks, the entire model development process is implemented, saved, and tracked as code in a source-controlled repository. Automating the process in this way facilitates more repeatable, predictable, and systematic deployments and makes it possible to integrate with your CI/CD process. Representing the model development process as code enables you to deploy the code instead of deploying the model. Deploying the code automates the ability to build the model, making it much easier to retrain the model when necessary.
When you create a project using MLOps Stacks, you define the components of your ML development and deployment process such as notebooks to use for feature engineering, training, testing, and deployment, pipelines for training and testing, workspaces to use for each stage, and CI/CD workflows using GitHub Actions or Azure DevOps for automated testing and deployment of your code.
The environment created by MLOps Stacks implements the MLOps workflow recommended by Databricks. You can customize the code to create stacks to match your organization's processes or requirements.
How does MLOps Stacks work?
You use the Databricks CLI to create an MLOps Stack. For step-by-step instructions, see Databricks Asset Bundles for MLOps Stacks.
When you initiate an MLOps Stacks project, the software steps you through entering the configuration details and then creates a directory containing the files that compose your project. This directory, or stack, implements the production MLOps workflow recommended by Databricks. The components shown in the diagram are created for you, and you need only edit the files to add your custom code.
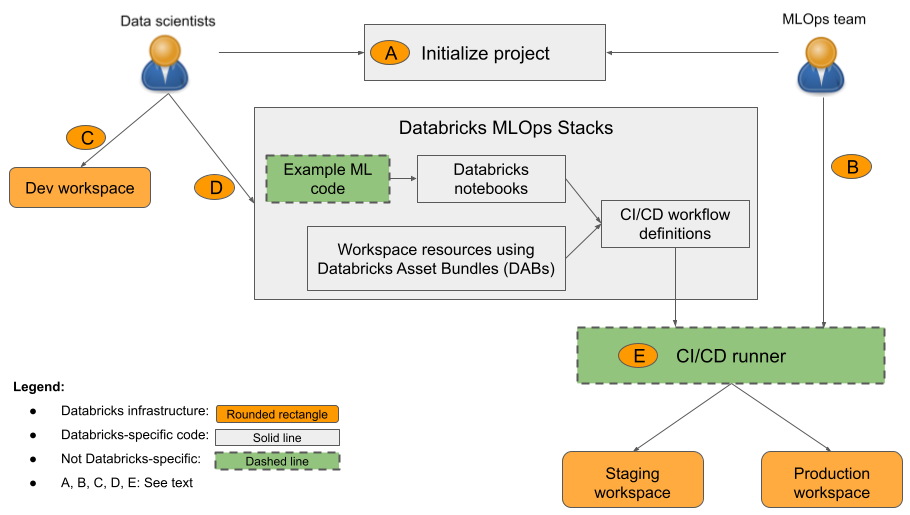
In the diagram:
- A: A data scientist or ML engineer initializes the project using
databricks bundle init mlops-stacks. When you initialize the project, you can choose to set up the ML code components (typically used by data scientists), the CI/CD components (typically used by ML engineers), or both. - B: ML engineers set up Databricks service principal secrets for CI/CD.
- C: Data scientists develop models on Databricks or on their local system.
- D: Data scientists create pull requests to update ML code.
- E: The CI/CD runner runs notebooks, creates jobs, and performs other tasks in the staging and production workspaces.
Your organization can use the default stack, or customize it as needed to add, remove, or revise components to fit your organization's practices. See the GitHub repository readme for details.
MLOps Stacks is designed with a modular structure to allow the different ML teams to work independently on a project while following software engineering best practices and maintaining production-grade CI/CD. Production engineers configure ML infrastructure that allows data scientists to develop, test, and deploy ML pipelines and models to production.
As shown in the diagram, the default MLOps Stack includes the following three components:
- ML code. MLOps Stacks creates a set of templates for an ML project including notebooks for training, batch inference, and so on. The standardized template allows data scientists to get started quickly, unifies project structure across teams, and enforces modularized code ready for testing.
- ML resources as code. MLOps Stacks defines resources such as workspaces and pipelines for tasks like training and batch inference. Resources are defined in Databricks Asset Bundles to facilitate testing, optimization, and version control for the ML environment. For example, you can try a larger instance type for automated model retraining, and the change is automatically tracked for future reference.
- CI/CD. You can use GitHub Actions or Azure DevOps to test and deploy ML code and resources, ensuring that all production changes are performed through automation and that only tested code is deployed to prod.
MLOps project flow
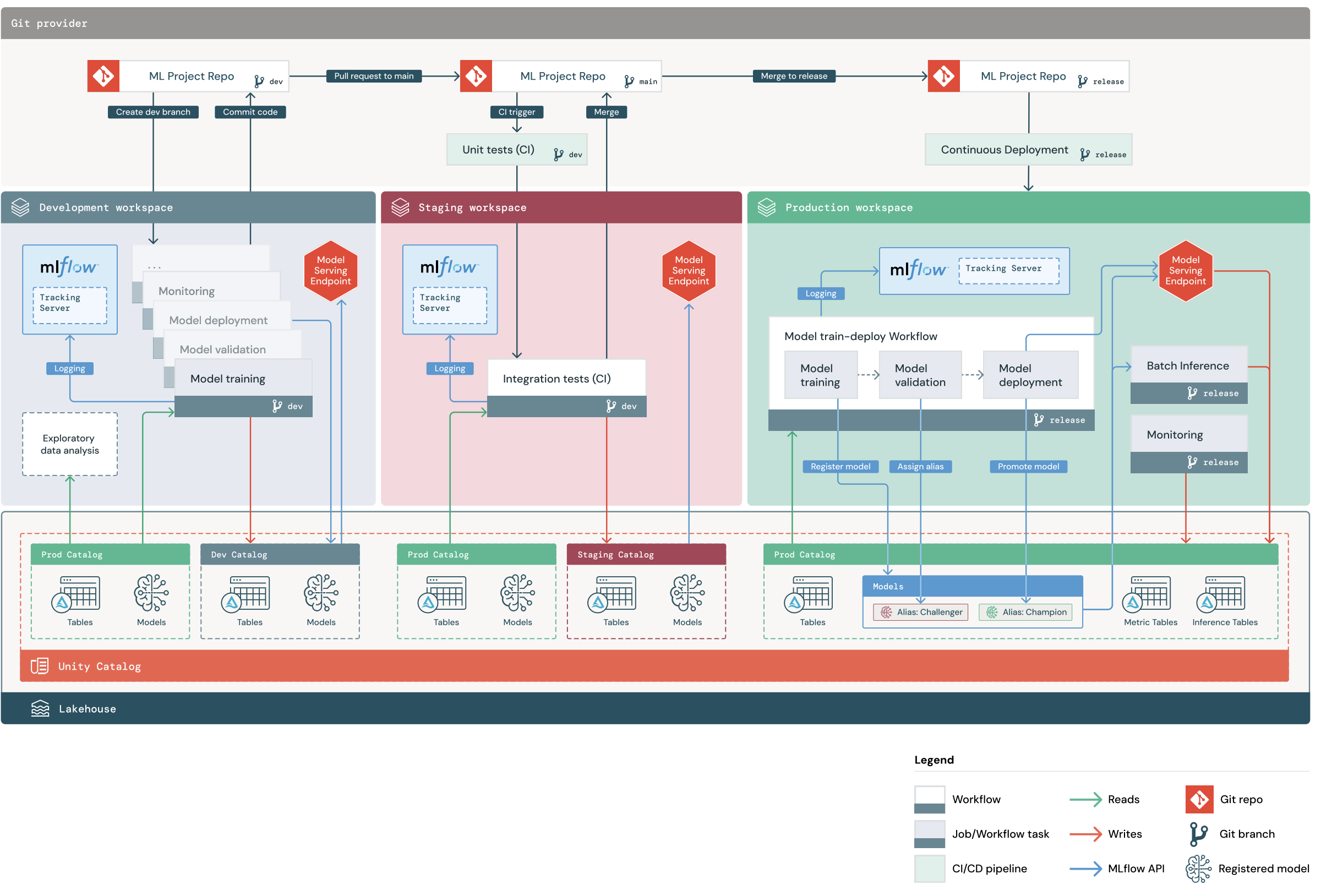
A default MLOps Stacks project includes an ML pipeline with CI/CD workflows to test and deploy automated model training and batch inference jobs across development, staging, and production Databricks workspaces. MLOps Stacks is configurable, so you can modify the project structure to meet your organization's processes.
The diagram shows the process that is implemented by the default MLOps Stack. In the development workspace, data scientists iterate on ML code and file pull requests (PRs). PRs trigger unit tests and integration tests in an isolated staging Databricks workspace. When a PR is merged to main, model training and batch inference jobs that run in staging immediately update to run the latest code. After you merge a PR into main, you can cut a new release branch as part of your scheduled release process and deploy the code changes to production.
MLOps Stacks project structure
An MLOps Stack uses Databricks Asset Bundles – a collection of source files that serves as the end-to-end definition of a project. These source files include information about how they are to be tested and deployed. Collecting the files as a bundle makes it easy to co-version changes and use software engineering best practices such as source control, code review, testing, and CI/CD.
The diagram shows the files created for the default MLOps Stack. For details about the files included in the stack, see the documentation on the GitHub repository or Databricks Asset Bundles for MLOps Stacks.

MLOps Stacks components
A “stack” refers to the set of tools used in a development process. The default MLOps Stack takes advantage of the unified Databricks platform and uses the following tools:
Component | Tool in Databricks |
|---|---|
ML model development code | |
Feature development and management | |
ML model repository | |
ML model serving | |
Infrastructure-as-code | |
Orchestrator | |
CI/CD | |
Data and model performance monitoring |
Next steps
To get started, see Databricks Asset Bundles for MLOps Stacks or the Databricks MLOps Stacks repository on GitHub.