tutorial: Construa um pipeline ETL usando captura de dados de alterações (CDC)
Aprenda como criar e implantar um pipeline ETL (extract, transform, and load) com captura de dados de alterações (CDC) (CDC) usando LakeFlow Spark Declarative pipeline (SDP) para orquestração de dados e Auto Loader. Um pipeline ETL implementa as etapas para ler dados de sistemas de origem, transformar esses dados com base em requisitos, como verificações de qualidade de dados e desduplicação de registros, e gravar os dados em um sistema de destino, como um data warehouse ou um data lake.
Neste tutorial, você usará dados de uma tabela customers em um banco de dados MySQL para:
- Extraia as alterações de um banco de dados transacional usando Debezium ou outra ferramenta e salve-as no armazenamento de objetos cloud (S3, ADLS ou GCS). Neste tutorial, você pulará a configuração de um sistema CDC externo e, em vez disso, gerará dados falsos para simplificar o tutorial.
- Use Auto Loader para carregar incrementalmente as mensagens do armazenamento de objetos cloud e armazenar as mensagens brutas na tabela
customers_cdc. O Auto Loader infere o esquema e manipula a evolução do esquema. - Crie a tabela
customers_cdc_cleanpara verificar a qualidade dos dados usando expectativas. Por exemplo, oidnunca deve sernullporque ele é usado para executar operações upsert. - Execute
AUTO CDC ... INTOnos dados CDC limpos para inserir alterações na tabelacustomersfinal. - Mostre como um pipeline pode criar uma tabela tipo 2 dimensões que mudam lentamente (SCD) (SCD2) para rastrear todas as alterações.
O objetivo é ingerir os dados brutos em tempo quase real e construir uma tabela para sua equipe de analistas, garantindo ao mesmo tempo a qualidade dos dados.
O tutorial usa a arquitetura medallion lakehouse, onde ele ingere dados brutos através da camada bronze, limpa e valida dados com a camada prata e aplica modelagem dimensional e agregação usando a camada ouro. Veja o que é a arquitetura do medalhão lakehouse? para mais informações.
O fluxo implementado se parece com isto:
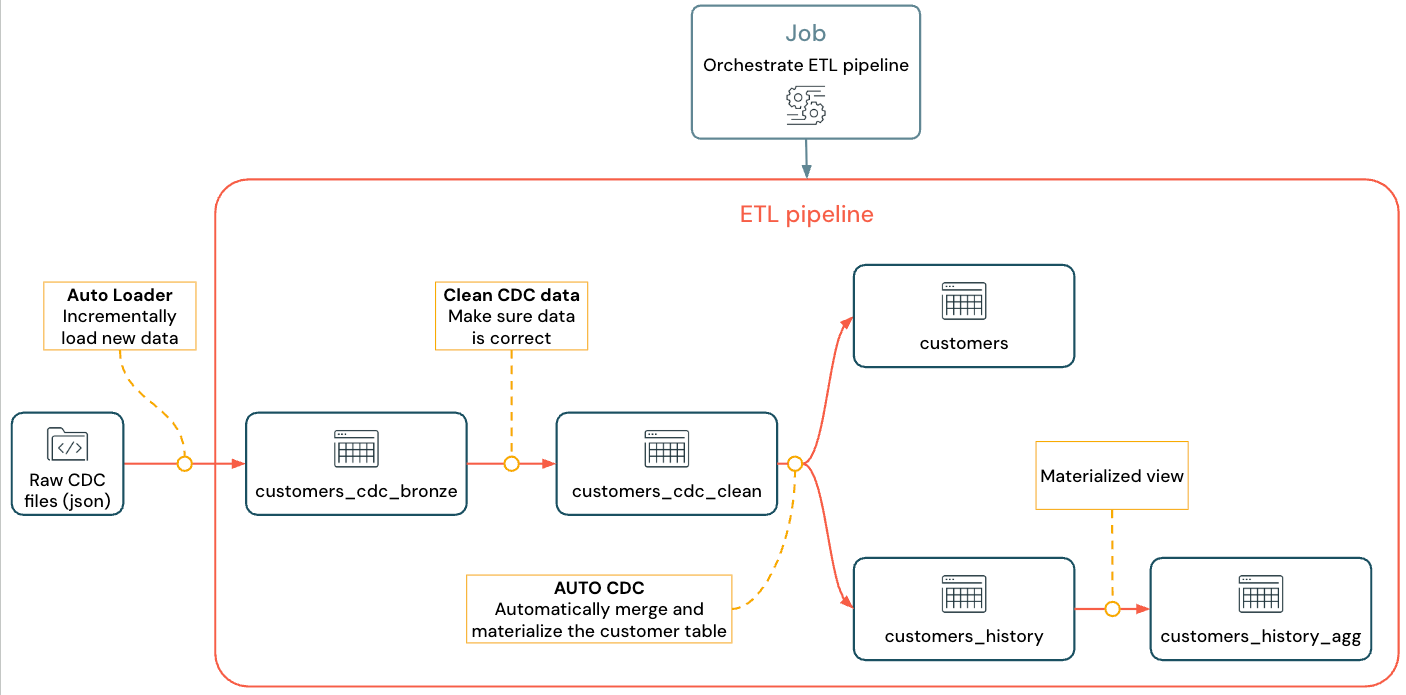
Para obter mais informações sobre pipeline, Auto Loader e CDC consulte Pipeline declarativoLakeFlow Spark, O que é Auto Loader?, e O que é captura de dados de alterações (CDC) (CDC)?
Requisitos
Para completar este tutorial, você deve atender aos seguintes requisitos:
- Faça login em um workspace Databricks .
- Tenha Unity Catalog habilitado para seu workspace.
- Ative o recurso de computaçãoserverless compute para sua account. O pipeline declarativo Spark LakeFlow sem servidor não está disponível em todas as regiões de workspace . Consulte o recurso com disponibilidade regional limitada para obter informações sobre as regiões disponíveis. Se compute serverless não estiver habilitado para sua account, os passos do sistema operacional devem funcionar com a compute default do seu workspace.
- Tenha permissão para criar um recurso compute ou acesso a um recurso compute.
- Possuir permissões para criar um novo esquema em um catálogo. As permissões necessárias são
USE CATALOGeCREATE SCHEMA. - Possuir permissões para criar um novo volume em um esquema existente. As permissões necessárias são
USE SCHEMAeCREATE VOLUME.
captura de dados de alterações (CDC) em um pipeline ETL
captura de dados de alterações (CDC) (CDC) é o processo que captura alterações em registros feitos em um banco de dados transacional (por exemplo, MySQL ou PostgreSQL) ou em um data warehouse. CDC captura operações como exclusões, acréscimos e atualizações de dados, normalmente como uma transmissão para rematerializar tabelas em sistemas externos. O CDC permite o carregamento incremental, eliminando a necessidade de atualizações de carregamento em massa.
Para simplificar este tutorial, pule a configuração de um sistema CDC externo. Suponha que ele esteja em execução e salvando dados CDC como arquivos JSON no armazenamento de objetos cloud (S3, ADLS ou GCS). Este tutorial usa a biblioteca Faker para gerar os dados usados no tutorial.
Capturando CDC
Há uma variedade de ferramentas do CDC disponíveis. Uma das principais soluções de código aberto é o Debezium, mas existem outras implementações que simplificam a fonte de dados, como Fivetran, Qlik Replicate, StreamSets, Talend, Oracle GoldenGate e AWS DMS.
Neste tutorial, você usará dados do CDC de um sistema externo como Debezium ou DMS. Debezium captura cada linha alterada. Normalmente, ele envia o histórico de alterações de dados para tópicos Kafka ou os salva como arquivos.
Você deve ingerir as informações CDC da tabela customers (formato JSON ), verificar se estão corretas e, em seguida, materializar a tabela de clientes no lakehouse.
Contribuição do CDC sobre Debezium
Para cada alteração, você recebe uma mensagem JSON contendo todos os campos da linha que está sendo atualizada (id, firstname, lastname, email, address). A mensagem também inclui metadados adicionais:
operation: Um código de operações, normalmente (DELETE,APPEND,UPDATE).operation_date: A data e o registro de data e hora para cada ação de operações.
Ferramentas como o Debezium podem produzir resultados mais avançados, como o valor da linha antes da alteração, mas este tutorial os omite para simplificar.
o passo 1: Criar um pipeline
Crie um novo pipeline ETL para consultar sua fonte de dados CDC e gerar tabelas em seu workspace.
-
No seu workspace, clique em
 Novo no canto superior esquerdo.
Novo no canto superior esquerdo. -
Clique em pipelineETL .
-
Altere o título do pipeline para
Pipelines with CDC tutorialou um nome de sua preferência. -
Abaixo do título, escolha um catálogo e esquema para os quais você tenha permissões de gravação.
Este catálogo e esquema são usados por default, se você não especificar um catálogo ou esquema em seu código. Seu código pode gravar em qualquer catálogo ou esquema especificando o caminho completo. Este tutorial usa o padrão que você especificar aqui.
-
Em Opções avançadas , selecione começar com um arquivo vazio .
-
Escolha uma pasta para seu código. Você pode selecionar Procurar para navegar pela lista de pastas no workspace. Você pode escolher qualquer pasta para a qual tenha permissões de gravação.
Para usar o controle de versão, selecione uma pasta Git. Se você precisar criar uma nova pasta, selecione
botão. -
Escolha Python ou SQL para a linguagem do seu arquivo, com base na linguagem que você deseja usar para o tutorial.
-
Clique em Selecionar para criar o pipeline com essas configurações e abrir o Editor LakeFlow Pipelines .
Agora você tem um pipeline em branco com um catálogo e esquema default . Em seguida, configure os dados de amostra para importar no tutorial.
o passo 2: Crie os dados de amostra para importar neste tutorial
Este passo não é necessário se você estiver importando seus próprios dados de uma fonte existente. Para este tutorial, gere dados falsos como exemplo para o tutorial. Crie um Notebook para executar o script de geração de dados Python . Este código só precisa ser executado uma vez para gerar os dados de amostra, então crie-o dentro da pasta explorations do pipeline, que não é executada como parte de uma atualização pipeline .
Este código usa o Faker para gerar os dados de amostra do CDC. O Faker está disponível para instalação automática, então o tutorial usa %pip install faker. Você também pode definir uma dependência no faker para o Notebook. Consulte Adicionar dependências ao Notebook.
-
No Editor LakeFlow Pipelines , na barra lateral do navegador ativo à esquerda do editor, clique em
Adicione e escolha Exploração . -
Dê um nome , como
Setup data, selecione Python . Você pode deixar a pasta de destino default , que é uma nova pastaexplorations. -
Clique em Criar . Isso cria um Notebook na nova pasta.
-
Digite o seguinte código na primeira célula. Você deve alterar a definição de
<my_catalog>e<my_schema>para corresponder ao catálogo e esquema default selecionados no procedimento anterior:Python%pip install faker
# Update these to match the catalog and schema
# that you used for the pipeline in step 1.
catalog = "<my_catalog>"
schema = dbName = db = "<my_schema>"
spark.sql(f'USE CATALOG `{catalog}`')
spark.sql(f'USE SCHEMA `{schema}`')
spark.sql(f'CREATE VOLUME IF NOT EXISTS `{catalog}`.`{db}`.`raw_data`')
volume_folder = f"/Volumes/{catalog}/{db}/raw_data"
try:
dbutils.fs.ls(volume_folder+"/customers")
except:
print(f"folder doesn't exist, generating the data under {volume_folder}...")
from pyspark.sql import functions as F
from faker import Faker
from collections import OrderedDict
import uuid
fake = Faker()
import random
fake_firstname = F.udf(fake.first_name)
fake_lastname = F.udf(fake.last_name)
fake_email = F.udf(fake.ascii_company_email)
fake_date = F.udf(lambda:fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S"))
fake_address = F.udf(fake.address)
operations = OrderedDict([("APPEND", 0.5),("DELETE", 0.1),("UPDATE", 0.3),(None, 0.01)])
fake_operation = F.udf(lambda:fake.random_elements(elements=operations, length=1)[0])
fake_id = F.udf(lambda: str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None)
df = spark.range(0, 100000).repartition(100)
df = df.withColumn("id", fake_id())
df = df.withColumn("firstname", fake_firstname())
df = df.withColumn("lastname", fake_lastname())
df = df.withColumn("email", fake_email())
df = df.withColumn("address", fake_address())
df = df.withColumn("operation", fake_operation())
df_customers = df.withColumn("operation_date", fake_date())
df_customers.repartition(100).write.format("json").mode("overwrite").save(volume_folder+"/customers") -
Para gerar o dataset utilizado no tutorial, digite Shift + Enter para executar o código:
-
Opcional. Para visualizar os dados usados neste tutorial, insira o seguinte código na próxima célula e execute o código. Atualize o catálogo e o esquema para corresponder ao caminho do código anterior.
Python# Update these to match the catalog and schema
# that you used for the pipeline in step 1.
catalog = "<my_catalog>"
schema = "<my_schema>"
display(spark.read.json(f"/Volumes/{catalog}/{schema}/raw_data/customers"))
Isso gera um grande conjunto de dados (com dados falsos do CDC) que você pode usar no restante do tutorial. Na próxima etapa, ingerir o uso de dados Auto Loader.
o passo 3: Ingerir dados incrementalmente com Auto Loader
O próximo passo é ingerir os dados brutos do armazenamento cloud (falso) em uma camada de bronze.
Isso pode ser desafiador por vários motivos, pois você deve:
- Operar em escala, potencialmente ingerindo milhões de arquivos pequenos.
- Inferir esquema e tipo JSON.
- Lide com registros inválidos com esquema JSON incorreto.
- Cuide da evolução do esquema (por exemplo, uma nova coluna na tabela de clientes).
Auto Loader simplifica essa ingestão, incluindo inferência de esquema e evolução do esquema, ao mesmo tempo em que escala para milhões de arquivos de entrada. O Auto Loader está disponível em Python usando cloudFiles e em SQL usando SELECT * FROM STREAM read_files(...) e pode ser usado com uma variedade de formatos (JSON, CSV, Apache Avro, etc.):
Definir a tabela como uma tabela de transmissão garante que você consuma apenas novos dados recebidos. Se você não defini-la como uma tabela de transmissão, ela verifica e ingere todos os dados disponíveis. Consulte tabelas de transmissão para mais informações.
- Para ingerir o CDC de entrada uso de dados Auto Loader, copie e cole o seguinte código no arquivo de código que foi criado com seu pipeline (chamado
my_transformation.py). Você pode usar Python ou SQL, dependendo da linguagem escolhida ao criar o pipeline. Certifique-se de substituir<catalog>e<schema>pelos que você configurou como default para o pipeline.
- Python
- SQL
from pyspark import pipelines as dp
from pyspark.sql.functions import *
# Replace with the catalog and schema name that
# you are using:
path = "/Volumes/<catalog>/<schema>/raw_data/customers"
# Create the target bronze table
dp.create_streaming_table("customers_cdc_bronze", comment="New customer data incrementally ingested from cloud object storage landing zone")
# Create an Append Flow to ingest the raw data into the bronze table
@dp.append_flow(
target = "customers_cdc_bronze",
name = "customers_bronze_ingest_flow"
)
def customers_bronze_ingest_flow():
return (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load(f"{path}")
)
CREATE OR REFRESH STREAMING TABLE customers_cdc_bronze
COMMENT "New customer data incrementally ingested from cloud object storage landing zone";
CREATE FLOW customers_bronze_ingest_flow AS
INSERT INTO customers_cdc_bronze BY NAME
SELECT *
FROM STREAM read_files(
-- replace with the catalog/schema you are using:
"/Volumes/<catalog>/<schema>/raw_data/customers",
format => "json",
inferColumnTypes => "true"
)
- Clique
 arquivo de execução ou pipelinede execução para iniciar uma atualização para o pipeline conectado. Com apenas um arquivo de origem no seu pipeline, eles são funcionalmente equivalentes.
arquivo de execução ou pipelinede execução para iniciar uma atualização para o pipeline conectado. Com apenas um arquivo de origem no seu pipeline, eles são funcionalmente equivalentes.
Quando a atualização for concluída, o editor será atualizado com informações sobre seu pipeline.
- O gráfico de pipeline (DAG), na barra lateral à direita do seu código, mostra uma única tabela,
customers_cdc_bronze. - Um resumo da atualização é mostrado na parte superior do navegador ativo pipeline .
- Os detalhes da tabela gerada são mostrados no painel inferior, e você pode navegar pelos dados da tabela selecionando-a.
Estes são os dados brutos da camada de bronze importados do armazenamento cloud . No próximo passo, limpe os dados para criar uma tabela de camada prateada.
o passo 4: Limpeza e expectativas para rastrear a qualidade dos dados
Depois que a camada bronze for definida, crie a camada prata adicionando expectativas para controlar a qualidade dos dados. Verifique as seguintes condições:
- O ID nunca deve ser
null. - O tipo de operações CDC deve ser válido.
- O JSON deve ser lido corretamente pelo Auto Loader.
As linhas que não atendem a essas condições são descartadas.
Consulte gerenciamento da qualidade dos dados com expectativas pipeline para obter mais informações.
-
Na barra lateral do navegador ativo pipeline , clique em
Adicione , então transforma . -
Digite um Nome e escolha uma linguagem (Python ou SQL) para o arquivo de código-fonte. Você pode misturar e combinar idiomas dentro de um pipeline, para que você possa escolher qualquer um para este ou aquele passo.
-
Para criar uma camada prateada com uma tabela limpa e impor restrições, copie e cole o seguinte código no novo arquivo (escolha Python ou SQL com base na linguagem do arquivo).
- Python
- SQL
from pyspark import pipelines as dp
from pyspark.sql.functions import *
dp.create_streaming_table(
name = "customers_cdc_clean",
expect_all_or_drop = {"no_rescued_data": "_rescued_data IS NULL","valid_id": "id IS NOT NULL","valid_operation": "operation IN ('APPEND', 'DELETE', 'UPDATE')"}
)
@dp.append_flow(
target = "customers_cdc_clean",
name = "customers_cdc_clean_flow"
)
def customers_cdc_clean_flow():
return (
spark.readStream.table("customers_cdc_bronze")
.select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data")
)
CREATE OR REFRESH STREAMING TABLE customers_cdc_clean (
CONSTRAINT no_rescued_data EXPECT (_rescued_data IS NULL) ON VIOLATION DROP ROW,
CONSTRAINT valid_id EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW,
CONSTRAINT valid_operation EXPECT (operation IN ('APPEND', 'DELETE', 'UPDATE')) ON VIOLATION DROP ROW
)
COMMENT "New customer data incrementally ingested from cloud object storage landing zone";
CREATE FLOW customers_cdc_clean_flow AS
INSERT INTO customers_cdc_clean BY NAME
SELECT * FROM STREAM customers_cdc_bronze;
-
Clique
arquivo de execução ou pipelinede execução para iniciar uma atualização para o pipeline conectado.Como agora há dois arquivos de origem, eles não fazem a mesma coisa, mas, neste caso, a saída é a mesma.
- execução pipeline execução de todo o seu pipeline, incluindo o código da etapa 3. Se seus dados de entrada estivessem sendo atualizados, isso puxaria todas as alterações dessa fonte para sua camada de bronze. Isso não executa o código da configuração de dados ou passo, porque ele está na pasta explorations e não faz parte do código-fonte do seu pipeline.
- arquivo de execução execução apenas do arquivo fonte atual. Nesse caso, sem que seus dados de entrada sejam atualizados, isso gera os dados de prata da tabela de bronze armazenada em cache. Seria útil executar apenas este arquivo para uma iteração mais rápida ao criar ou editar seu código pipeline .
Quando a atualização for concluída, você poderá ver que o gráfico do pipeline agora mostra duas tabelas (com a camada prateada dependendo da camada bronze) e o painel inferior mostra detalhes de ambas as tabelas. A parte superior do navegador ativo pipeline agora mostra vários tempos de execução, mas apenas detalhes da execução mais recente.
Em seguida, crie sua versão final da camada ouro da tabela customers .
o passo 5: Materializar a tabela de clientes com um fluxo AUTO CDC
Até este ponto, as tabelas apenas passaram os dados CDC em cada passo. Agora, crie a tabela customers para conter a view mais atualizada e ser uma réplica da tabela original, não a lista de operações CDC que a criou.
Não é fácil implementar isso manualmente. Você deve considerar coisas como desduplicação de dados para manter a linha mais recente.
No entanto, o pipeline LakeFlow Spark Declarative resolve esses desafios com as operações AUTO CDC .
-
Na barra lateral do navegador ativo pipeline , clique em
Adicione e transforme . -
Digite um Nome e escolha uma linguagem (Python ou SQL) para o novo arquivo de código-fonte. Você pode escolher qualquer idioma para este passo, mas use o código correto, abaixo.
-
Para processar o uso de dados CDC
AUTO CDCno pipeline declarativo LakeFlow Spark , copie e cole o seguinte código no novo arquivo.
- Python
- SQL
from pyspark import pipelines as dp
from pyspark.sql.functions import *
dp.create_streaming_table(name="customers", comment="Clean, materialized customers")
dp.create_auto_cdc_flow(
target="customers", # The customer table being materialized
source="customers_cdc_clean", # the incoming CDC
keys=["id"], # what we'll be using to match the rows to upsert
sequence_by=col("operation_date"), # de-duplicate by operation date, getting the most recent value
ignore_null_updates=False,
apply_as_deletes=expr("operation = 'DELETE'"), # DELETE condition
except_column_list=["operation", "operation_date", "_rescued_data"],
)
CREATE OR REFRESH STREAMING TABLE customers;
CREATE FLOW customers_cdc_flow
AS AUTO CDC INTO customers
FROM stream(customers_cdc_clean)
KEYS (id)
APPLY AS DELETE WHEN
operation = "DELETE"
SEQUENCE BY operation_date
COLUMNS * EXCEPT (operation, operation_date, _rescued_data)
STORED AS SCD TYPE 1;
- Clique arquivo de execução para iniciar uma atualização para o pipeline conectado.
Quando a atualização estiver concluída, você poderá ver que seu gráfico de pipeline mostra 3 tabelas, progredindo de bronze para prata e para ouro.
o passo 6: Track update história com dimensões que mudam lentamente (SCD) type 2 (SCD2)
Muitas vezes é necessário criar uma tabela acompanhando todas as alterações resultantes de APPEND, UPDATE e DELETE:
- história: Você quer manter um histórico de todas as alterações na sua tabela.
- Rastreabilidade: Você quer ver quais operações ocorreram.
SCD2 com LakeFlow SDP
O Delta oferece suporte ao fluxo de dados de alteração (CDF) e table_change pode consultar modificações de tabelas em SQL e Python. No entanto, o principal caso de uso do CDF é capturar alterações em um pipeline, não criar uma view completa das alterações da tabela desde o início.
As coisas ficam especialmente complexas de implementar se você tiver eventos fora de ordem. Se você precisar sequenciar suas alterações por um registro de data e hora e receber uma modificação que ocorreu no passado, deverá anexar uma nova entrada na sua tabela SCD e atualizar as entradas anteriores.
LakeFlow SDP elimina essa complexidade e permite criar uma tabela separada que contém todas as modificações desde o início dos tempos. Essa tabela pode então ser usada em grande escala, com partições específicas ou colunas ZORDER, se necessário. Os campos fora de ordem são tratados automaticamente com base no _sequence_by.
Para criar uma tabela SCD2, use a opção STORED AS SCD TYPE 2 em SQL ou stored_as_scd_type="2" em Python.
Você também pode limitar quais colunas o recurso rastreia usando a opção: TRACK HISTORY ON {columnList | EXCEPT(exceptColumnList)}
-
Na barra lateral do navegador ativo pipeline , clique em
Adicione e transforme . -
Digite um Nome e escolha uma linguagem (Python ou SQL) para o novo arquivo de código-fonte.
-
Copie e cole o seguinte código no novo arquivo.
- Python
- SQL
from pyspark import pipelines as dp
from pyspark.sql.functions import *
# create the table
dp.create_streaming_table(
name="customers_history", comment="Slowly Changing Dimension Type 2 for customers"
)
# store all changes as SCD2
dp.create_auto_cdc_flow(
target="customers_history",
source="customers_cdc_clean",
keys=["id"],
sequence_by=col("operation_date"),
ignore_null_updates=False,
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list=["operation", "operation_date", "_rescued_data"],
stored_as_scd_type="2",
) # Enable SCD2 and store individual updates
CREATE OR REFRESH STREAMING TABLE customers_history;
CREATE FLOW customers_history_cdc
AS AUTO CDC INTO
customers_history
FROM stream(customers_cdc_clean)
KEYS (id)
APPLY AS DELETE WHEN
operation = "DELETE"
SEQUENCE BY operation_date
COLUMNS * EXCEPT (operation, operation_date, _rescued_data)
STORED AS SCD TYPE 2;
- Clique arquivo de execução para iniciar uma atualização para o pipeline conectado.
Quando a atualização estiver concluída, o gráfico do pipeline incluirá a nova tabela customers_history , também dependente da tabela da camada prateada, e o painel inferior mostrará os detalhes de todas as 4 tabelas.
o passo 7: Crie uma view materializada que rastreie quem mais alterou suas informações
A tabela customers_history contém todas as alterações históricas que um usuário fez em suas informações. Crie uma view materializada simples na camada ouro que monitore quem mais alterou suas informações. Isso pode ser usado para análise de detecção de fraudes ou recomendações de usuários em um cenário do mundo real. Além disso, a aplicação de alterações com o SCD2 já removeu duplicatas, então você pode contar diretamente as linhas por ID de usuário.
-
Na barra lateral do navegador ativo pipeline , clique em
Adicione e transforme . -
Digite um Nome e escolha uma linguagem (Python ou SQL) para o novo arquivo de código-fonte.
-
Copie e cole o seguinte código no novo arquivo de origem.
- Python
- SQL
from pyspark import pipelines as dp
from pyspark.sql.functions import *
@dp.table(
name = "customers_history_agg",
comment = "Aggregated customer history"
)
def customers_history_agg():
return (
spark.read.table("customers_history")
.groupBy("id")
.agg(
count("address").alias("address_count"),
count("email").alias("email_count"),
count("firstname").alias("firstname_count"),
count("lastname").alias("lastname_count")
)
)
CREATE OR REPLACE MATERIALIZED VIEW customers_history_agg AS
SELECT
id,
count("address") as address_count,
count("email") AS email_count,
count("firstname") AS firstname_count,
count("lastname") AS lastname_count
FROM customers_history
GROUP BY id
- Clique arquivo de execução para iniciar uma atualização para o pipeline conectado.
Após a conclusão da atualização, há uma nova tabela no gráfico pipeline que depende da tabela customers_history , e você pode view la no painel inferior. Seu pipeline agora está completo. Você pode testá-lo executando um pipelinede execução completo. Os únicos passos que faltam são programar o pipeline para atualizar regularmente.
o passo 8: Crie um Job para executar o pipeline ETL
Em seguida, crie um fluxo de trabalho para automatizar a ingestão de dados, o processamento e a análise dos passos em seu pipeline usando um trabalho Databricks .
- Na parte superior do editor, escolha o botão programar .
- Se a caixa de diálogo do programa aparecer, escolha Adicionar programa .
- Isso abre a caixa de diálogo Novo programa , onde você pode criar um Job para executar seu pipeline em um programa.
- Opcionalmente, dê um nome ao trabalho.
- Por default, o programador é configurado para executar uma vez por dia. Você pode aceitar esse default ou definir seu próprio programa. Escolher Avançado lhe dá a opção de definir um horário específico para a execução do trabalho. Selecionar Mais opções permite que você crie notificações quando o trabalho for executado.
- Selecione Criar para aplicar as alterações e criar o trabalho.
Agora o Job será executado diariamente para manter seu pipeline atualizado. Você pode escolher programar novamente para view a lista de programas. Você pode gerenciar programas para seu pipeline a partir dessa caixa de diálogo, incluindo adicionar, editar ou remover programas.
Clicar no nome do programa (ou Job) leva você para a página do Job na lista Jobs & pipeline . A partir daí você pode view detalhes sobre a execução do Job, incluindo a história de execução, ou executar o Job imediatamente com o botão executar agora .
Consulte monitoramento e observabilidade para trabalhos LakeFlow para obter mais informações sobre execução de trabalhos.
Recurso adicional
- Pipeline declarativo LakeFlow Spark
- Tutorial: Crie um pipeline ETL com LakeFlow Spark Declarative pipeline
- O que é captura de dados de alterações (CDC) (CDC)?
- APIs AUTO CDC : Simplifique a captura de dados de alterações (CDC) com pipeline
- Converter um pipeline em um projeto Databricks ativo Bundle
- O que é o Auto Loader?