チュートリアル: チェンジデータキャプチャを使用してETLパイプラインを構築する
データオーケストレーションとAuto Loaderのため、チェンジデータキャプチャ (CDC) を使用したETL (抽出、変換、ロード) パイプラインをLakeFlow Pipelinesで作成およびデプロイします。ETLパイプラインは、ソースシステムからデータを読み取り、データ品質チェックやレコードの重複排除などの要件に基づいてそのデータを変換し、データウェアハウスやデータレイクなどのターゲットシステムにデータを書き込む手順を実装します。
このチュートリアルでは、MySQL データベースのcustomersテーブルのデータを使用して次の操作を行います。
- Debezium または別のツールを使用してトランザクション データベースから変更を抽出し、クラウド オブジェクト ストレージ (S3、ADLS、または GCS) に保存します。このチュートリアルでは、外部 CDC システムの設定を省略し、代わりに偽のデータを生成することでチュートリアルを簡素化します。
- Auto Loaderを使用して、クラウド オブジェクト ストレージからメッセージを段階的に読み込み、生のメッセージを
customers_cdcテーブルに保存します。 Auto Loaderスキーマを推測し、スキーマ進化を処理します。 - 期待値を使用してデータ品質を確認するには、
customers_cdc_cleanテーブルを作成します。たとえば、id、upsert 操作を実行するために使用されるため、nullにすることはできません。 - クリーンアップされた CDC データに対して
AUTO CDC ... INTO実行し、最終的なcustomersテーブルに変更をアップサートします。 - パイプラインがタイプ 2 のゆっくりと変化する寸法 (SCD2) テーブルを作成して、すべての変更を追跡する方法を示します。
目標は、生データをほぼリアルタイムで取り込み、データの品質を確保しながらアナリスト チーム向けのテーブルを構築することです。
このチュートリアルでは、メダリオン レイクハウス アーキテクチャを使用して、ブロンズレイヤーを介して生データを取り込み、シルバーレイヤーでデータのクリーニングと検証を行い、ゴールドレイヤーを使用してディメンション モデリングと集計を適用します。 詳細は、メダリオンレイクハウスアーキテクチャとは何ですか?をご覧ください。
実装されたフローは次のようになります。
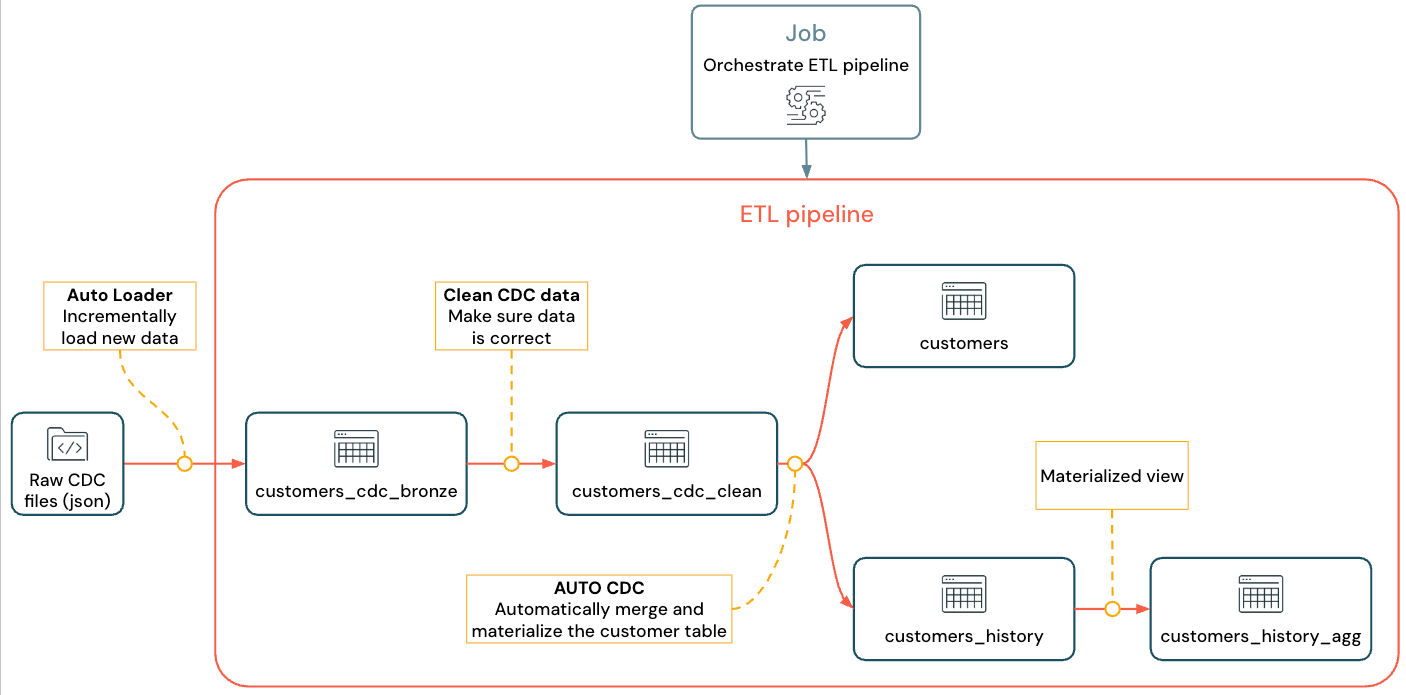
パイプライン、Auto Loader、およびCDCの詳細については、Spark宣言型パイプライン、Auto Loaderとは、およびチェンジデータキャプチャとスナップショットを参照してください。
要件
このチュートリアルを完了するには、以下の条件を満たす必要があります。
- Unity Catalogはワークスペースで有効になっています。
- Serverless コンピュートはワークスペースで利用可能です (Unity Catalogを持つワークスペースではdefaultで有効になっています)。Serverless Lakeflow pipelinesは、すべてのワークスペース地域で利用できるわけではありません。利用可能な地域については、地域限定で利用できる機能を参照してください。Serverlessコンピュートが利用できない場合、ステップはワークスペースのdefaultコンピュートで動作するはずです。
- コンピュート リソースを作成する、またはコンピュート リソースにアクセスする権限。
- カタログに新しいスキーマを作成するためのアクセス許可。必要なアクセス許可は
USE CATALOGとCREATE SCHEMAです。 - 既存のスキーマに新しいボリュームを作成する権限。必要な権限は
USE SCHEMAおよびCREATE VOLUMEです。 - パイプラインとその出力を作成、実行、更新、および表示するために必要な特権の全セットについては、パイプラインの ID、アクセス許可、および特権の管理を参照してください。
ETLパイプラインにおけるチェンジデータキャプチャ
変更データキャプチャ ( CDC ) は、トランザクション データベース ( MySQLやPostgreSQLなど) またはデータウェアハウスに対して行われたレコードの変更をキャプチャするプロセスです。 CDC は、データの削除、追加、更新などの操作を、通常は外部システムのテーブルを再マテリアライズするためのストリームとしてキャプチャします。CDC を使用すると、一括ロード更新の必要性を排除しながら増分ロードが可能になります。
このチュートリアルを簡略化するために、外部 CDC システムの設定をスキップします。実行されていて、CDC データが JSON ファイルとしてクラウド オブジェクト ストレージ (S3、ADLS、または GCS) に保存されていると想定します。このチュートリアルでは、 Fakerライブラリを使用して、チュートリアルで使用するデータを生成します。
CDCをキャプチャする
さまざまな CDC ツールが利用可能です。主要なオープンソース ソリューションの 1 つは Debezium ですが、 Fivetran 、 Qlik Replicate 、 StreamSets 、Talend、Oracle GoldenGate、 AWS DMS など、データソースを簡素化する他の実装も存在します。
このチュートリアルでは、Debezium や DMS などの外部システムからの CDC データを使用します。Debezium は変更されたすべての行をキャプチャします。通常、データの変更履歴は Kafka トピックに送信され、ファイルとして保存されます。
customersテーブル ( JSON形式) からCDC情報を取り込み、それが正しいことを確認してから、レイクハウスで顧客テーブルをマテリアライズする必要があります。
DebeziumからのCDCの入力
変更ごとに、更新される行のすべてのフィールド ( id 、 firstname 、 lastname 、 email 、 address ) を含む JSON メッセージを受け取ります。メッセージには追加のメタデータも含まれます:
operation: 操作コード。通常は (DELETE、APPEND、UPDATE)。operation_date: 各操作アクションの記録の日付とタイムスタンプ。
Debezium などのツールは、変更前の行の値など、より高度な出力を生成できますが、このチュートリアルでは簡潔にするために省略しています。
ステップ 1: パイプラインを作成する
新しいETLパイプラインを作成して、 CDCデータ ソースをクエリし、ワークスペースにテーブルを生成します。
-
ワークスペースで、 をクリックします。
 サイドバーで 「新規」 をクリックし、 ETLパイプライン」 を選択します。 これにより、
サイドバーで 「新規」 をクリックし、 ETLパイプライン」 を選択します。 これにより、 New Pipeline <date> <time>ようなデフォルトのパイプライン名でパイプラインエディタが開きます。 -
名前を選択し、
Pipelines with CDC tutorialのような説明的な名前を入力してください。 -
名前の右側にあるカタログとスキーマをクリックして、書き込み権限のあるデフォルト値を選択します。
コード内でカタログまたはスキーマを指定しない場合は、このカタログとスキーマがデフォルトで使用されます。完全なパスを指定することで、コードは任意のカタログまたはスキーマに書き込むことができます。このチュートリアルでは、ここで指定したデフォルトを使用します。
-
(オプション)作成された
my_transformationソースファイルで、言語ドロップダウンリストから Python または SQL を選択して、ファイルの言語を設定します。 -
クリック
 サンプルコードを使用してください 。
サンプルコードを使用してください 。
LakeFlow Pipelines Editor が開き、パイプライン内のサンプル ファイルが表示されます。 後のステップで独自の変換ファイルを追加します。 次に、チュートリアルで使用するサンプルデータをインポートするための設定を行います。
ステップ 2: このチュートリアルにインポートするサンプルデータを作成します
既存のソースから独自のデータをインポートする場合、このステップは必要ありません。 このチュートリアルでは、チュートリアルの例として偽のデータを生成します。Python データ生成スクリプトを実行するためのノートブックを作成します。このコードはサンプル データを生成するために 1 回だけ実行する必要があるため、パイプラインの更新の一部として実行されないパイプラインのexplorationsフォルダー内に作成します。
このコードはFakerを使用してサンプル CDC データを生成します。Faker は自動的にインストールできるため、チュートリアルでは%pip install fakerを使用します。ノートブックに faker への依存関係を設定することもできます。「ノートブックに依存関係を追加する」を参照してください。
-
Lakeflowパイプラインエディター内のエディターの左側にあるアセットブラウザサイドバーで、
追加 を選択し、 探索 を選択します。 -
Setup dataなどの 名前 を付け、 Python を選択します。デフォルトの宛先フォルダ(新しいexplorationsフォルダ)をそのまま使用できます。 -
[作成] をクリックします。これにより、新しいフォルダーにノートブックが作成されます。
-
最初のセルに次のコードを入力します。前の手順で選択したデフォルトのカタログとスキーマと一致するように、
<my_catalog>と<my_schema>の定義を変更する必要があります。Python%pip install faker
# Update these to match the catalog and schema
# that you used for the pipeline in step 1.
catalog = "<my_catalog>"
schema = dbName = db = "<my_schema>"
spark.sql(f'USE CATALOG `{catalog}`')
spark.sql(f'USE SCHEMA `{schema}`')
spark.sql(f'CREATE VOLUME IF NOT EXISTS `{catalog}`.`{db}`.`raw_data`')
volume_folder = f"/Volumes/{catalog}/{db}/raw_data"
try:
dbutils.fs.ls(volume_folder+"/customers")
except:
print(f"folder doesn't exist, generating the data under {volume_folder}...")
from pyspark.sql import functions as F
from faker import Faker
from collections import OrderedDict
import uuid
fake = Faker()
import random
fake_firstname = F.udf(fake.first_name)
fake_lastname = F.udf(fake.last_name)
fake_email = F.udf(fake.ascii_company_email)
fake_date = F.udf(lambda:fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S"))
fake_address = F.udf(fake.address)
operations = OrderedDict([("APPEND", 0.5),("DELETE", 0.1),("UPDATE", 0.3),(None, 0.01)])
fake_operation = F.udf(lambda:fake.random_elements(elements=operations, length=1)[0])
fake_id = F.udf(lambda: str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None)
df = spark.range(0, 100000).repartition(100)
df = df.withColumn("id", fake_id())
df = df.withColumn("firstname", fake_firstname())
df = df.withColumn("lastname", fake_lastname())
df = df.withColumn("email", fake_email())
df = df.withColumn("address", fake_address())
df = df.withColumn("operation", fake_operation())
df_customers = df.withColumn("operation_date", fake_date())
df_customers.repartition(100).write.format("json").mode("overwrite").save(volume_folder+"/customers") -
チュートリアルで使用するデータセットを生成するには、 Shift + Enter キー を押してコードを実行します。
-
オプション。このチュートリアルで使用されるデータをプレビューするには、次のセルに次のコードを入力してコードを実行します。前のコードからのパスと一致するようにカタログとスキーマを更新します。
Python# Update these to match the catalog and schema
# that you used for the pipeline in step 1.
catalog = "<my_catalog>"
schema = "<my_schema>"
display(spark.read.json(f"/Volumes/{catalog}/{schema}/raw_data/customers"))
これにより、チュートリアルの残りの部分で使用できる大規模なデータ セット (フェイクの CDC データを含む) が生成されます。次のステップでは、Auto Loader を使用してデータを取り込みます。
ステップ 3: Auto Loaderを使用してデータを増分的に取り込む
次のステップは、(フェイクの) クラウド ストレージから生データをブロンズ レイヤーに取り込むことです。
これは、次のような複数の理由から難しい場合があります。
- 大規模に運用し、数百万の小さなファイルを取り込む可能性があります。
- スキーマと JSON 型を推測します。
- 不正な JSON スキーマを持つ不良レコードを処理します。
- スキーマ進化 (顧客テーブルの新しい列など) に注意してください。
Auto Loader は、スキーマ推論やスキーマ進化などのこの取り込みを簡素化し、数百万の受信ファイルに拡張します。Auto Loader は、Python ではcloudFiles 、SQL ではSELECT * FROM STREAM read_files(...)を使用して使用でき、さまざまな形式 (JSON、CSV、Apache Avro など) で使用できます。
テーブルをストリーミング テーブルとして定義すると、新しい受信データのみを使用することが保証されます。 ストリーミング テーブルとして定義しない場合、利用可能なすべてのデータがスキャンされ、取り込まれます。 詳細については、ストリーミング テーブルを参照してください。
- Auto Loader を使用して受信した CDC データをインジェストするには、パイプラインで作成されたコード ファイル (
my_transformation.pyまたはmy_transformation.sqlという名前) に次のコードをコピーして貼り付けます。パイプライン作成時に選択した言語に応じて、PythonまたはSQLを使用できます。<catalog>と<schema>は、パイプラインのデフォルト設定で指定した値に置き換えてください。
- Python
- SQL
from pyspark import pipelines as dp
from pyspark.sql.functions import *
# Replace with the catalog and schema name that
# you are using:
path = "/Volumes/<catalog>/<schema>/raw_data/customers"
# Create the target bronze table
dp.create_streaming_table("customers_cdc_bronze", comment="New customer data incrementally ingested from cloud object storage landing zone")
# Create an Append Flow to ingest the raw data into the bronze table
@dp.append_flow(
target = "customers_cdc_bronze",
name = "customers_bronze_ingest_flow"
)
def customers_bronze_ingest_flow():
return (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load(f"{path}")
)
CREATE OR REFRESH STREAMING TABLE customers_cdc_bronze
COMMENT "New customer data incrementally ingested from cloud object storage landing zone";
CREATE FLOW customers_bronze_ingest_flow AS
INSERT INTO customers_cdc_bronze BY NAME
SELECT *
FROM STREAM read_files(
-- replace with the catalog/schema you are using:
"/Volumes/<catalog>/<schema>/raw_data/customers",
format => "json",
inferColumnTypes => "true"
)
- クリック
 ファイルを実行する か、 パイプラインを実行 して、接続されたパイプラインの更新を開始します。パイプラインにソース ファイルが 1 つしかない場合、これらは機能的に同等です。
ファイルを実行する か、 パイプラインを実行 して、接続されたパイプラインの更新を開始します。パイプラインにソース ファイルが 1 つしかない場合、これらは機能的に同等です。
更新が完了すると、エディターはパイプラインに関する情報で更新されます。
- パイプライングラフ(有向非巡回グラフ(DAG)とも呼ばれる)は、コードの右側のサイドバーに単一のテーブル
customers_cdc_bronzeを表示します。 - 更新内容の概要は、パイプライン資産ブラウザの上部に表示されます。
- 生成されたテーブルの詳細は下部のペインに表示され、テーブルを選択してデータを参照できます。
これは、クラウド ストレージからインポートされた生のブロンズ レイヤー データです。 次のステップでは、データをクリーンアップしてシルバーレイヤー テーブルを作成します。
ステップ 4: クリーンアップとデータ品質を追跡するためのエクスペクテーション
ブロンズ レイヤーを定義した後、データ品質を制御するための期待値を追加してシルバー レイヤーを作成します。 次の条件を確認してください。
- ID は
nullであってはなりません。 - CDC 操作タイプは有効である必要があります。
- JSON は Auto Loader によって正しく読み取られる必要があります。
これらの条件を満たさない行は削除されます。
詳細については、「 パイプラインのエクスペクテーションを使用してデータ品質を管理する 」を参照してください。
-
パイプラインアセットブラウザーのサイドバーから、クリックします
追加 、次に 変換 。 -
ソースコードファイルの 名前 (例:
customers_silver)を入力し、言語(PythonまたはSQL)を選択してください。言語の選択に応じて、.pyまたは.sql拡張子が追加されます。パイプライン内では複数の言語を混在させることができるため、このステップではどちらの言語でも選択できます。 -
クレンジングされたテーブルを含むシルバーレイヤーを作成し、制約を課すには、次のコードをコピーして新しいファイルに貼り付けます (ファイルの言語に基づいてPythonまたはSQLを選択します)。
- Python
- SQL
from pyspark import pipelines as dp
from pyspark.sql.functions import *
dp.create_streaming_table(
name = "customers_cdc_clean",
expect_all_or_drop = {"no_rescued_data": "_rescued_data IS NULL","valid_id": "id IS NOT NULL","valid_operation": "operation IN ('APPEND', 'DELETE', 'UPDATE')"}
)
@dp.append_flow(
target = "customers_cdc_clean",
name = "customers_cdc_clean_flow"
)
def customers_cdc_clean_flow():
return (
spark.readStream.table("customers_cdc_bronze")
.select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data")
)
CREATE OR REFRESH STREAMING TABLE customers_cdc_clean (
CONSTRAINT no_rescued_data EXPECT (_rescued_data IS NULL) ON VIOLATION DROP ROW,
CONSTRAINT valid_id EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW,
CONSTRAINT valid_operation EXPECT (operation IN ('APPEND', 'DELETE', 'UPDATE')) ON VIOLATION DROP ROW
)
COMMENT "New customer data incrementally ingested from cloud object storage landing zone";
CREATE FLOW customers_cdc_clean_flow AS
INSERT INTO customers_cdc_clean BY NAME
SELECT * FROM STREAM customers_cdc_bronze;
-
クリック
ファイルを実行する か、 パイプラインを実行 して、接続されたパイプラインの更新を開始します。ソース ファイルが 2 つあるため、同じことを行うわけではありませんが、この場合、出力は同じになります。
- パイプライン実行 ステップ 3 のコードを含むパイプライン全体を実行します。 入力データが更新されている場合、そのソースからの変更がブロンズレイヤーに取り込まれます。 これは、データ設定ステップのコードは実行しません。これは、データ設定ステップのコードが探索フォルダ内にあり、パイプラインのソースの一部ではないためです。
- ファイルの実行 現在のソース ファイルのみを実行します。 この場合、入力データは更新されずに、キャッシュされたブロンズ テーブルからシルバー データが生成されます。パイプライン コードを作成または編集するときに、このファイルだけを実行すると反復処理が高速化されます。
更新が完了すると、パイプライン グラフに 2 つのテーブル (ブロンズ レイヤーに応じてシルバー レイヤー) が表示され、下部パネルに両方のテーブルの詳細が表示されることがわかります。 パイプライン アセット ブラウザーの上部に複数の実行時間が表示されるようになりましたが、最新の実行の詳細のみが表示されます。
次に、 customersテーブルの最終的なゴールドレイヤー バージョンを作成します。
ステップ 5: AUTO CDCフローを使用して顧客テーブルをマテリアライズする
ここまで、テーブルは各ステップで CDC データを渡してきました。ここで、 customersテーブルを作成して、最新のビューを含み、元のテーブルを作成した CDC 操作のリストではなく、元のテーブルのレプリカとなるようにします。
これを手動で実装するのは簡単ではありません。最新の行を保持するには、データの重複排除などを考慮する必要があります。
ただし、パイプラインはAUTO CDC操作でこれらの課題を解決します。
-
パイプラインアセットブラウザーのサイドバーから、クリックします
追加 と 変換 。 -
名前 を入力し、新しいソース コード ファイルの言語 (Python または SQL) を選択します。このステップではどちらの言語も選択できますが、以下の正しいコードを使用してください。
-
AUTO CDCを使用してCDCデータを処理するには、次のコードをコピーして新しいファイルに貼り付けます。
- Python
- SQL
from pyspark import pipelines as dp
from pyspark.sql.functions import *
dp.create_streaming_table(name="customers", comment="Clean, materialized customers")
dp.create_auto_cdc_flow(
target="customers", # The customer table being materialized
source="customers_cdc_clean", # the incoming CDC
keys=["id"], # what we'll be using to match the rows to upsert
sequence_by=col("operation_date"), # de-duplicate by operation date, getting the most recent value
ignore_null_updates=False,
apply_as_deletes=expr("operation = 'DELETE'"), # DELETE condition
except_column_list=["operation", "operation_date", "_rescued_data"],
)
CREATE OR REFRESH STREAMING TABLE customers;
CREATE FLOW customers_cdc_flow
AS AUTO CDC INTO customers
FROM stream(customers_cdc_clean)
KEYS (id)
APPLY AS DELETE WHEN
operation = "DELETE"
SEQUENCE BY operation_date
COLUMNS * EXCEPT (operation, operation_date, _rescued_data)
STORED AS SCD TYPE 1;
- ファイルを実行 をクリックして、接続されたパイプラインの更新を開始します。
更新が完了すると、パイプライン グラフに、ブロンズ、シルバー、ゴールドの順に 3 つのテーブルが表示されることがわかります。
ステップ 6: 緩やかに変化するディメンション タイプ 2 (SCD2) による更新履歴の追跡
多くの場合、 APPEND 、 UPDATE 、 DELETEから生じるすべての変更を追跡するテーブルを作成する必要があります。
- 履歴: テーブルに対するすべての変更の履歴を保持します。
- トレーサビリティ: どの操作が発生したかを確認します。
SCD2とLakeFlow Pipelines
Delta は変更データフロー (CDF) をサポートしており、 table_change SQL および Python でテーブルの変更をクエリできます。ただし、CDF の主な使用例は、パイプライン内の変更をキャプチャすることであり、最初からテーブルの変更の完全なビューを作成することではありません。
順序どおりに実行されないイベントがある場合、実装は特に複雑になります。変更をタイムスタンプ順に並べ、過去に発生した変更を受け取る必要がある場合は、SCD テーブルに新しいエントリを追加し、以前のエントリを更新する必要があります。
LakeFlow Pipelines はこの複雑さを取り除きます。最初からのすべての変更を含む個別のテーブルを作成できます。これはパイプラインが自動的に維持します。このテーブルは、リキッドクラスタリングなどのデータLayoutの最適化をサポートし、_sequence_byに基づいて順不同のレコードを自動的に処理します。テーブルにリキッドクラスタリングを使用するを参照してください。
SCD2 テーブルを作成するには、SQL ではオプションSTORED AS SCD TYPE 2 、Python ではオプションstored_as_scd_type="2"を使用します。
このオプションを使用して、機能が追跡する列を制限することもできます。 TRACK HISTORY ON {columnList | EXCEPT(exceptColumnList)}
-
パイプラインアセットブラウザーのサイドバーから、クリックします
追加 と 変換 。 -
名前 を入力し、新しいソース コード ファイルの言語 (Python または SQL) を選択します。
-
次のコードをコピーして新しいファイルに貼り付けます。
- Python
- SQL
from pyspark import pipelines as dp
from pyspark.sql.functions import *
# create the table
dp.create_streaming_table(
name="customers_history", comment="Slowly Changing Dimension Type 2 for customers"
)
# store all changes as SCD2
dp.create_auto_cdc_flow(
target="customers_history",
source="customers_cdc_clean",
keys=["id"],
sequence_by=col("operation_date"),
ignore_null_updates=False,
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list=["operation", "operation_date", "_rescued_data"],
stored_as_scd_type="2",
) # Enable SCD2 and store individual updates
CREATE OR REFRESH STREAMING TABLE customers_history;
CREATE FLOW customers_history_cdc
AS AUTO CDC INTO
customers_history
FROM stream(customers_cdc_clean)
KEYS (id)
APPLY AS DELETE WHEN
operation = "DELETE"
SEQUENCE BY operation_date
COLUMNS * EXCEPT (operation, operation_date, _rescued_data)
STORED AS SCD TYPE 2;
- ファイルを実行 をクリックして、接続されたパイプラインの更新を開始します。
更新が完了すると、パイプライン グラフには、これもシルバーレイヤー テーブルに依存する新しいcustomers_historyテーブルが含まれ、下部パネルには 4 つのテーブルすべての詳細が表示されます。
ステップ 7: 誰の情報を最も多く変更したかを追跡するマテリアライズドビューを作成する
テーブルcustomers_historyには、ユーザーが自分の情報に対して行ったすべての変更履歴が含まれます。ゴールドレイヤーで簡単なマテリアライズドビューを作成し、誰の情報を最も多く変更したかを追跡します。 これは、実際のシナリオにおける不正行為検出分析やユーザー推奨に使用できます。さらに、SCD2 を使用して変更を適用すると重複がすでに削除されているため、ユーザー ID ごとに行を直接カウントできます。
-
パイプラインアセットブラウザーのサイドバーから、クリックします
追加 と 変換 。 -
名前 を入力し、新しいソース コード ファイルの言語 (Python または SQL) を選択します。
-
次のコードをコピーして新しいソース ファイルに貼り付けます。
- Python
- SQL
from pyspark import pipelines as dp
from pyspark.sql.functions import *
@dp.table(
name = "customers_history_agg",
comment = "Aggregated customer history"
)
def customers_history_agg():
return (
spark.read.table("customers_history")
.groupBy("id")
.agg(
count_distinct("address").alias("address_count"),
count_distinct("email").alias("email_count"),
count_distinct("firstname").alias("firstname_count"),
count_distinct("lastname").alias("lastname_count")
)
)
CREATE OR REPLACE MATERIALIZED VIEW customers_history_agg AS
SELECT
id,
count(distinct address) as address_count,
count(distinct email) AS email_count,
count(distinct firstname) AS firstname_count,
count(distinct lastname) AS lastname_count
FROM customers_history
GROUP BY id
- ファイルを実行 をクリックして、接続されたパイプラインの更新を開始します。
更新が完了すると、パイプライン グラフにcustomers_historyテーブルに依存する新しいテーブルが追加され、下部のパネルで確認できます。パイプラインが完成しました。完全な パイプラインの実行 を実行してテストできます。残っているステップは、パイプラインを定期的に更新するようにスケジュールすることだけです。
ステップ 8: ETLパイプラインを実行するジョブを作成する
次に、 Databricksジョブを使用してパイプラインのデータ取り込み、処理、分析ステップを自動化するワークフローを作成します。
- エディターの上部にある [スケジュール] ボタンを選択します。
- [スケジュール] ダイアログが表示されたら、 [スケジュールの追加] を 選択します。
- これにより、 新しいスケジュール ダイアログが開き、スケジュールに従ってパイプラインを実行するジョブを作成できます。
- 必要に応じて、ジョブに名前を付けます。
- デフォルトでは、スケジュールは 1 日に 1 回実行されるように設定されています。このデフォルトを受け入れることも、独自のスケジュールを設定することもできます。 「詳細」 を選択すると、ジョブを実行する特定の時間を設定するオプションが提供されます。 その他のオプション を選択すると、ジョブの実行時に通知を作成できます。
- 変更を適用してジョブを作成するには、 [作成] を選択します。
これで、ジョブは毎日実行され、パイプラインが最新の状態に保たれます。スケジュールのリストを表示するには、もう一度 「スケジュール」 を選択します。このダイアログから、スケジュールの追加、編集、削除など、パイプラインのスケジュールを管理できます。
スケジュール (またはジョブ) の名前をクリックすると、 [ジョブとパイプライン] リストのジョブのページに移動します。そこから、実行の履歴を含むジョブ実行に関する詳細を表示したり、 今すぐ実行 ボタンを使用してジョブをすぐに実行したりできます。
ジョブ実行の詳細については、Lakeflow ジョブの監視を参照してください。