Generative AI fluxo de trabalho do desenvolvedor de aplicativos
O desenvolvimento de um aplicativo gerador robusto para AI (gen AI app) requer planejamento deliberado, um ciclo rápido de desenvolvimento-feedback-avaliação e uma infraestrutura de produção dimensionável. Este fluxo de trabalho descreve uma sequência recomendada de etapas para guiá-lo desde a prova de conceito inicial (POC) até a implementação na produção.
- Reúna os requisitos para validar a adequação do gênero AI e identificar as restrições.
- Projete a arquitetura de suas soluções. Veja os padrões de design do sistema do agente
- Preparar a fonte de dados e criar as ferramentas necessárias.
- Crie e valide o protótipo inicial (POC).
- implantado no ambiente de pré-produção.
- Colete feedback do usuário e meça a qualidade
- Corrija problemas de qualidade refinando a lógica e as ferramentas do agente com base na avaliação.
- Incorpore informações de especialistas no assunto (SME) para melhorar continuamente a qualidade do sistema do agente.
- implantado o aplicativo AI no ambiente de produção.
- Monitorar o desempenho e a qualidade.
- Mantenha e melhore com base no uso no mundo real.
Esse fluxo de trabalho deve ser iterativo: após cada implantação ou ciclo de avaliação, retorne às etapas anteriores para refinar o pipeline de dados ou atualizar a lógica do agente. Por exemplo, o monitoramento da produção pode revelar novos requisitos, acionando atualizações no design do agente e outra rodada de avaliação. Seguindo essas etapas sistematicamente e aproveitando os recursos de rastreamento Databricks MLflow , Agent Framework e Agent Evaluation, é possível criar aplicativos gen AI de alta qualidade que atendam de forma confiável às necessidades do usuário, respeitem os requisitos de segurança e compliance e continuem a melhorar com o tempo.
0. Pré-requisitos
Antes de começar a desenvolver seu aplicativo gen AI, nunca é demais enfatizar a importância de reservar um tempo para fazer o seguinte corretamente: coleta de requisitos e design de soluções.
A coleta de requisitos inclui as seguintes etapas:
- Valide se o site AI é adequado ao seu caso de uso.
- Defina a experiência do usuário.
- Escopo da fonte de dados.
- Definir restrições de desempenho.
- Capture as restrições de segurança.
O projeto de soluções inclui o seguinte:
- Mapear o pipeline de dados.
- Identifique as ferramentas necessárias.
- Descreva a arquitetura geral do sistema.
Ao estabelecer essa base, você define uma direção clara para os estágios subsequentes de construção, avaliação e produção.
Reúna os requisitos
A definição de requisitos de caso de uso claros e abrangentes é a primeira etapa fundamental para o desenvolvimento de um aplicativo gen AI bem-sucedido. Esses requisitos atendem aos seguintes propósitos:
- Eles ajudam a determinar se uma abordagem gen AI é apropriada para o seu caso de uso.
- Eles orientam as decisões de projeto, implementação e avaliação de soluções.
Investir tempo desde o início para reunir requisitos detalhados pode evitar desafios significativos mais tarde no processo de desenvolvimento e garantir que as soluções resultantes atendam às necessidades dos usuários finais e das partes interessadas. Requisitos bem definidos fornecem a base para os estágios subsequentes do ciclo de vida do seu aplicativo.
O caso de uso é adequado para a geração AI?
Antes de se comprometer com uma solução gen AI, considere se os pontos fortes inerentes a ela se alinham às suas necessidades. Alguns exemplos em que a AI soluções generativas é uma boa opção incluem:
- Geração de conteúdo: A tarefa exige a geração de conteúdo novo ou criativo que não pode ser obtido com um padrão estático ou uma lógica simples baseada em regras.
- Tratamento dinâmico de consultas: as consultas dos usuários são abertas ou complexas e exigem respostas flexíveis e sensíveis ao contexto.
- síntese de informações: O caso de uso se beneficia da combinação ou do resumo de diversas fontes de informação para produzir um resultado coerente.
- Sistemas de agentes: o aplicativo exige mais do que apenas gerar texto em resposta a uma solicitação. Pode ser necessário ser capaz de:
- Planejamento e tomada de decisão: Formular uma estratégia de várias etapas para atingir uma meta específica.
- Realização de ações: Acionar processos externos ou chamar várias ferramentas para realizar a tarefa (por exemplo, recuperar dados, fazer chamadas para API, executar consultas em SQL, executar código).
- Manter o estado: Manter o controle do histórico da conversa ou do contexto da tarefa em várias interações para permitir a continuidade.
- Produção de resultados adaptativos: Geração de respostas que evoluem com base em ações anteriores, informações atualizadas ou mudanças nas condições.
Por outro lado, uma abordagem gen AI pode não ser ideal nas seguintes situações:
- A tarefa é altamente determinística e pode ser resolvida de forma eficaz com sistemas padrão ou baseados em regras predefinidos.
- Todo o conjunto de informações necessárias já é estático ou se encaixa em uma estrutura simples e fechada.
- Respostas de latência extremamente baixa (milissegundos) são necessárias, e a sobrecarga do processamento generativo não pode ser acomodada.
- Respostas simples e modeladas são suficientes para o caso de uso pretendido.
Nota sobre P0, P1 e P2 rótulo
As seções abaixo usam o rótulo P0 , P1 e P2 para indicar a prioridade relativa.
- Os itens 🟢 [P0] são críticos ou essenciais. Eles devem ser resolvidos imediatamente.
- Os itens 🟡 [P1] são importantes, mas podem seguir os requisitos do P0 .
- Os itens ⚪ [P2] são considerações ou aprimoramentos de menor prioridade que podem ser abordados conforme o tempo e o recurso permitirem.
Esses rótulos ajudam as equipes a ver rapidamente quais requisitos precisam de atenção imediata e quais podem ser adiados.
Experiência do usuário
Defina como os usuários irão interagir com o aplicativo gen AI e que tipo de respostas são esperadas.
- 🟢 [P0] Solicitação típica: Qual será a aparência de uma solicitação típica de um usuário? Reúna exemplos das partes interessadas.
- 🟢 [P0] Respostas esperadas: Que tipo de respostas o sistema deve gerar (por exemplo, respostas curtas, explicações longas, narrativas criativas)?
- 🟡 [P1] Modalidade de interação: como os usuários interagirão com o aplicativo (por exemplo, interface de bate-papo, barra de pesquisa, assistente de voz)?
- 🟡 [P1] Tom, estilo, estrutura: Que tom, estilo e estrutura os resultados gerados devem adotar (formal, conversacional, técnico, marcadores ou prosa contínua)?
- 🟡 [P1] Tratamento de erros: como o aplicativo deve lidar com consultas ambíguas, incompletas ou fora do alvo? Deve fornecer feedback ou solicitar esclarecimentos?
- ⚪ [P2] Requisitos de formatação: Há alguma formatação específica ou diretrizes de apresentação para os resultados (incluindo metadados ou informações suplementares)?
Dados
Determine a natureza, a(s) fonte(s) e a qualidade dos dados que serão usados no aplicativo gen AI.
-
🟢 [P0] fonte de dados: Quais fontes de dados estão disponíveis?
- Para cada fonte, determine:
- Os dados são estruturados ou não estruturados?
- Qual é o formato de origem (por exemplo, PDF, HTML, JSON, XML)?
- Onde os dados residem?
- Quantos dados estão disponíveis?
- Como os dados devem ser acessados?
- Para cada fonte, determine:
-
🟡 [P1] Atualizações de dados: Com que frequência os dados são atualizados? Quais mecanismos existem para lidar com as atualizações?
-
🟡 [P1] Qualidade dos dados: Existem problemas de qualidade ou inconsistências conhecidos?
- Considere se será necessário algum monitoramento de qualidade na fonte de dados.
Considere a possibilidade de criar uma tabela de inventário para consolidar essas informações, por exemplo:
Origem de dados | Origem | Tipo (s) de arquivo | Tamanho | Frequência de atualização |
|---|---|---|---|---|
fonte de dados 1 | Unity Catalog volume | JSON | 10 GB | Diariamente |
fonte de dados 2 | API pública | XML | NA (API) | Em tempo real |
fonte de dados 3 | SharePoint | PDF, .docx | 500 MB | Mensal |
Restrições de desempenho
Capturar os requisitos de desempenho e recurso para o aplicativo gen AI.
Latência
-
🟢 [P0] Tempo até os primeiros tokens: Qual é o atraso máximo aceitável antes de entregar os primeiros tokens de saída?
- Observação: normalmente, a latência é medida usando p50 (mediana) e p95 (percentil 95) para capturar o desempenho médio e o pior caso.
-
🟢 [P0] Tempo de conclusão: Qual é o tempo de resposta aceitável (tempo de conclusão) para os usuários?
-
🟢 Latência de transmissão [P0]: Se as respostas forem transmitidas, é aceitável uma latência geral mais alta?
Escalabilidade
-
🟡 [P1] usuários concorrente & solicitações: Quantos usuários ou solicitações simultâneas o sistema deve suportar?
- Observação: a escalabilidade geralmente é medida em termos de QPS (consultas por segundo) ou QPM (consultas por minuto).
-
🟡 [P1] Padrões de uso: Quais são os padrões de tráfego esperados, picos de carga ou picos de uso baseados no tempo?
Restrições de custo
- 🟢 [P0] Limitações de custo de inferência: Quais são as restrições de custo ou limitações orçamentárias para a inferência compute recurso?
Avaliação
Estabeleça como o aplicativo gen AI será avaliado e aprimorado ao longo do tempo.
-
🟢 [P0] KPIs de negócios : qual meta de negócios ou KPI o aplicativo deve impactar? Defina seus valores básicos e metas.
-
🟢 [ P0] Feedback das partes interessadas : Quem fornecerá feedback inicial e contínuo sobre o desempenho e os resultados do aplicativo? Identifique grupos de usuários específicos ou especialistas em domínios.
-
🟢 [ P0] Medição da qualidade : Quais métricas (por exemplo, precisão, relevância, segurança, pontuações humanas) serão usadas para avaliar a qualidade dos resultados gerados?
- Como essas métricas serão computadas durante o desenvolvimento (por exemplo, em relação a dados sintéticos, conjunto de dados selecionados manualmente)?
- Como a qualidade será medida na produção (por exemplo, registrando e analisando respostas a consultas reais de usuários)?
- Qual é a sua tolerância geral a erros? (por exemplo, aceite uma certa porcentagem de pequenas imprecisões factuais ou exija quase 100% de exatidão para casos de uso críticos.)
- O objetivo é criar um conjunto de avaliação a partir de consultas reais de usuários, dados sintéticos ou uma combinação de ambos. Esse conjunto oferece uma maneira consistente de avaliar o desempenho à medida que o sistema evolui.
-
🟡 [P1] Ciclos de feedback: como o feedback do usuário deve ser coletado (por exemplo, polegar para cima/para baixo, formulários de pesquisa) e usado para promover melhorias iterativas ?
- Planeje com que frequência o feedback será analisado e incorporado.
Segurança
Identifique quaisquer considerações de segurança e privacidade.
- 🟢 [P0] Sensibilidade de dados: Existem elementos de dados sensíveis ou confidenciais que requerem tratamento especial?
- 🟡 [P1] Controles de acesso: Você precisa implementar controles de acesso para restringir determinados dados ou funcionalidades?
- 🟡 [P1] Avaliação e atenuação de ameaças: O seu aplicativo precisará ser protegido contra ameaças comuns do gênero AI, como injeção de prompt ou entradas de usuário mal-intencionadas?
Implantação
Entenda como as soluções gen AI serão integradas, implantadas, monitoradas e mantidas.
-
🟡 [P1] Integração: Como as soluções do gen AI devem se integrar aos sistemas existentes e ao fluxo de trabalho?
- Identifique os pontos de integração (por exemplo, Slack, CRM, ferramentas de BI) e os conectores de dados necessários.
- Determine como as solicitações e respostas fluirão entre o aplicativo gen AI e os sistemas downstream (por exemplo, APIs REST, webhooks).
-
🟡 [P1] Implantação: Quais são os requisitos para implantação, dimensionamento e controle de versão do aplicativo? Este artigo aborda como o ciclo de vida de ponta a ponta pode ser tratado em Databricks usando MLflow, Unity Catalog, Agent Framework, Agent Evaluation e servindo modelo.
-
🟡 [ P1] Monitoramento da produção & observabilidade: Como o senhor monitorará o aplicativo quando ele estiver em produção?
- Registrando rastreamentos &: capture traços de execução completos.
- Qualidade das métricas: Avalie continuamente key métricas (como correção, latência, relevância) no tráfego ao vivo.
- alerta & dashboards: Configure alertas para problemas críticos.
- Ciclo de feedback: incorpore o feedback do usuário na produção (positivo ou negativo) para detectar problemas com antecedência e impulsionar melhorias iterativas.
Exemplo
Como exemplo, veja como essas considerações e requisitos se aplicam a um aplicativo RAG autêntico hipotético usado por uma equipe de suporte ao cliente da Databricks:
Área | Considerações | Requisitos |
|---|---|---|
Experiência do usuário |
|
|
Lógica do agente |
|
|
Dados |
|
|
Desempenho |
|
|
Avaliação |
|
|
Segurança |
|
|
Implantação |
|
|
soluções design
Para considerações adicionais de design, consulte Padrões de design do sistema do agente.
fonte de dados & tools
Ao projetar um aplicativo gen AI, é importante identificar e mapear as várias fontes de dados e ferramentas necessárias para impulsionar suas soluções. Isso pode envolver um conjunto de dados estruturados, um pipeline de processamento de dados não estruturados ou uma consulta externa em APIs. Abaixo estão as abordagens recomendadas para incorporar diferentes fontes de dados ou ferramentas em seu aplicativo gen AI:
Dados estruturados
Os dados estruturados normalmente residem em formatos tabulares bem definidos (por exemplo, uma tabela Delta ou um arquivo CSV ) e são ideais para tarefas em que as consultas são predeterminadas ou precisam ser geradas dinamicamente com base na entrada do usuário. Consulte Conectar agentes a dados estruturados para obter recomendações sobre como adicionar dados estruturados ao seu aplicativo AI gen.
Dados não estruturados
Dados não estruturados incluem documentos brutos, PDFs, e-mails, imagens e outros formatos que não se enquadram em um esquema fixo. Esses dados exigem processamento adicional, normalmente por meio de uma combinação de análise sintática, segmentação e incorporação, para serem consultados e usados de forma eficaz em um aplicativo AI de última geração. Consulte Conectar agentes a dados não estruturados para obter recomendações sobre como adicionar dados estruturados ao seu aplicativo AI de geração.
APIs externas & actions
Em alguns cenários, seu aplicativo gen AI pode precisar interagir com sistemas externos para recuperar dados ou executar ações. Nos casos em que seu aplicativo requer a invocação de ferramentas ou a interação com APIs externas, recomendamos o seguinte:
- Gerenciar credenciais API com uma conexãoUnity Catalog: Use uma conexão Unity Catalog para gerenciar com segurança as credenciais API. Esse método garante que tokens e os segredos sejam gerenciados de forma centralizada e com controle de acesso.
- Invocar por meio do SDK da Databricks :
Enviar solicitações HTTP para o serviço externo usando a funçãohttp_requestda bibliotecadatabricks-sdk. Essa função aproveita uma conexão do Unity Catalog para autenticação e oferece suporte a métodos HTTP padrão. - Aproveite as funções do Unity Catalog :
Envolva conexões externas em uma função do Unity Catalog para adicionar lógica personalizada de pré ou pós-processamento. - Ferramenta do executor Python :
Para executar dinamicamente o código para transformações de dados ou interações API usando funções Python, use a ferramenta integrada Python executor .
Exemplo:
Um aplicativo analítico interno recupera dados de mercado ao vivo de um site financeiro externo API. O aplicativo usa:
- Conexão externa do Unity Catalog para armazenar com segurança as credenciais da API.
- Uma função personalizada do Unity Catalog envolve a chamada de API para adicionar pré-processamento (como normalização de dados) e pós-processamento (como tratamento de erros).
- Além disso, o aplicativo pode chamar diretamente a API por meio do SDK da Databricks.
Abordagem de implementação
Ao desenvolver um aplicativo gen AI, o senhor tem duas opções principais para implementar a lógica do seu agente: aproveitar uma estrutura de código aberto ou criar uma solução personalizada usando o código Python. Abaixo está uma análise dos prós e contras de cada abordagem.
Usar uma estrutura (como LangChain, LlamaIndex, CrewAI ou AutoGen)
Prós:
- Componentes prontos para uso: As estruturas vêm com ferramentas prontas para o gerenciamento de solicitações, encadeamento de chamadas e integração com várias fontes de dados, o que pode acelerar o desenvolvimento.
- comunidade e documentação: Beneficie-se do suporte da comunidade, do tutorial e das atualizações regulares.
- Padrões de design comuns: Normalmente, as estruturas oferecem uma estrutura clara e modular para orquestrar tarefas comuns, o que pode simplificar o projeto geral do agente.
Contras:
- Abstração adicional: As estruturas de código aberto geralmente introduzem camadas de abstração que podem ser desnecessárias para seu caso de uso específico.
- Dependência de atualizações: O senhor pode depender dos mantenedores da estrutura para correções de bugs e atualizações de recursos, o que pode diminuir sua capacidade de se adaptar rapidamente a novos requisitos.
- Possível sobrecarga: a abstração extra pode levar a desafios de personalização se seu aplicativo precisar de um controle mais refinado.
Usando Python puro
Prós:
- Flexibilidade: O desenvolvimento em Python puro permite que o senhor adapte sua implementação exatamente às suas necessidades, sem ser limitado pelas decisões de design de uma estrutura.
- Adaptação rápida: você pode ajustar rapidamente seu código e incorporar as alterações conforme necessário, sem esperar por atualizações de uma estrutura externa.
- Simplicidade: Evitar camadas desnecessárias de abstração, o que pode resultar em soluções mais enxutas e de melhor desempenho.
Contras:
- Maior esforço de desenvolvimento: Construir do zero pode exigir mais tempo e conhecimento para implementar recursos que uma estrutura dedicada poderia fornecer.
- Reinventando a roda: talvez você precise desenvolver funcionalidades comuns (como o encadeamento de ferramentas ou o gerenciamento imediato) por conta própria.
- Responsabilidade pela manutenção: Todas as atualizações e correções de erros se tornam de sua responsabilidade, o que pode ser um desafio para sistemas complexos.
Em última análise, a sua decisão deve ser orientada pela complexidade do seu projeto, pelas necessidades de desempenho e pelo nível de controle que o senhor precisa. Nenhuma abordagem é inerentemente superior; cada uma oferece vantagens distintas, dependendo de suas preferências de desenvolvimento e prioridades estratégicas.
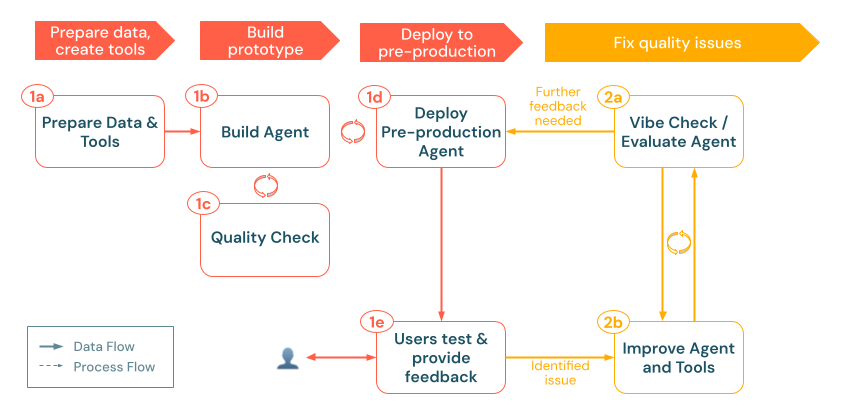
1. Construir
Nesta etapa, o senhor transforma o design de suas soluções em um aplicativo gen AI funcional. Em vez de aperfeiçoar tudo de antemão, comece pequeno com uma prova de conceito (POC) mínima que possa ser testada rapidamente. Isso permite que o senhor implante em um ambiente de pré-produção o mais rápido possível, reúna consultas representativas de usuários reais ou PMEs e refine com base no feedback do mundo real.

O processo de construção segue estas etapas key:
a. Prepare as ferramentas de & de dados: certifique-se de que os dados necessários estejam acessíveis, analisados e prontos para recuperação. Implemente ou registre as funções e conexões do Unity Catalog (por exemplo, recuperação APIs ou chamadas externas API ) de que seu agente precisará. b. Agente de criação: orquestre a lógica central, começando com uma abordagem simples de POC. c. Verificação de qualidade: valide a funcionalidade essencial antes de expor o aplicativo a mais usuários. d. implantar o agente de pré-produção: Disponibilize o POC para usuários de teste e especialistas no assunto para obter feedback inicial. e. Colete feedback do usuário: use o uso no mundo real para identificar áreas de melhoria, dados ou ferramentas adicionais necessários e possíveis refinamentos para a próxima iteração.
a. Prepare as ferramentas de dados &
A partir da fase de design de soluções, o senhor terá uma ideia inicial da fonte de dados e das ferramentas necessárias para o seu aplicativo. Nesse estágio, mantenha o mínimo: concentre-se em dados suficientes para validar seu POC. Isso garante uma iteração rápida sem grandes investimentos iniciais em pipelines complexos.
Dados
-
Identifique um subconjunto representativo de dados
- Para dados estruturados , selecione as tabelas ou colunas do site key mais relevantes para seu cenário inicial.
- Para dados não estruturados , priorize a indexação de apenas um subconjunto de documentos representativos. Use um pipeline básico de fragmentação/incorporação com o Mosaic AI Vector Search para que seu agente possa recuperar partes de texto relevantes, se necessário.
-
Configurar o acesso aos dados
- Se precisar que seu aplicativo faça chamadas de API externas, armazene as credenciais de forma segura usando uma conexão do Unity Catalog.
-
Valide a cobertura básica
- Confirme se os subconjuntos de dados escolhidos atendem adequadamente às consultas do usuário que você planeja testar.
- Salve qualquer fonte de dados adicional ou transformações complexas para iterações futuras. Seu objetivo atual deve ser provar a viabilidade básica e coletar feedback.
Ferramentas
Com sua fonte de dados configurada, a próxima etapa é implementar e registrar as ferramentas que seu agente chamará em tempo de execução para Unity Catalog. Uma ferramenta é uma função de interação única , como uma consulta SQL ou uma chamada externa API, que o agente pode invocar para recuperação, transformações ou ações.
Ferramentas de recuperação de dados
- Consultas de dados estruturados e restritos: Se as consultas forem fixas, envolva-as em uma função SQL do Unity Catalog ou em um UDF do Python. Isso mantém a lógica centralizada e detectável.
- Consultas de dados abertos e estruturados: Se as consultas forem mais abertas, considere a possibilidade de configurar um espaço Genie para lidar com consultas de texto para SQL.
- Funções auxiliares de dados não estruturados: Para dados não estruturados armazenados no Mosaic AI Vector Search, crie uma ferramenta de recuperação de dados não estruturados que o agente possa chamar para buscar pedaços de texto relevantes.
Ferramentas de chamada de API
- Chamadas de API externas: As chamadas de API podem ser invocadas diretamente usando o método
http_requestdo SDK da Databricks. - Envoltórios opcionais: Se o senhor precisar implementar lógica de pré ou pós-processamento (como normalização de dados ou tratamento de erros), envolva a chamada de API em uma função do Unity Catalog.
Mantenha o mínimo
- começar apenas com as ferramentas essenciais: Concentre-se em um único caminho de recuperação ou em um conjunto limitado de API calls. Você pode adicionar mais à medida que itera.
- Validar interativamente: Teste cada ferramenta de forma independente (por exemplo, em um Notebook) antes de incorporá-la ao sistema de agentes.
Depois que suas ferramentas de protótipo estiverem prontas, continue criando o agente. O agente orquestra essas ferramentas para responder a consultas, buscar dados e realizar ações conforme necessário.
b. Agente de construção
Depois que seus dados e ferramentas estiverem prontos, você poderá criar o agente que responda às solicitações recebidas, como consultas de usuários. Para criar um protótipo inicial de agente, use o Python ou o AI playground. Siga estas etapas:
-
começar simples
-
Escolha um padrão básico de design: Para um POC, comece com uma cadeia básica (como uma sequência fixa de etapas) ou um único agente de chamada de ferramenta (em que o LLM pode chamar dinamicamente uma ou duas ferramentas essenciais).
- Se o seu cenário estiver alinhado com um dos exemplos de Notebook fornecidos na documentação da Databricks, adapte esse código como um esqueleto.
-
Solicitação mínima: resista à tentação de exagerar na engenharia das solicitações neste momento. Mantenha as instruções sucintas e diretamente relevantes para sua tarefa inicial.
-
-
Incorpore ferramentas
-
Integração de ferramentas: se estiver usando um padrão de design de cadeia, as etapas que chamam cada ferramenta serão codificadas. Em um agente de chamada de ferramenta, o senhor fornece um esquema para que o LLM saiba como invocar a função.
- Verifique se as ferramentas isoladas estão funcionando conforme o esperado, antes de incorporá-las ao sistema do agente e testar de ponta a ponta.
-
Barreiras de proteção: Se o seu agente puder modificar sistemas externos ou código de execução, certifique-se de ter verificações de segurança básicas e proteções (como limitar o número de chamadas ou restringir determinadas ações). Implemente-os em uma função do Unity Catalog.
-
-
Rastreie e log o agente com MLflow
- Rastreie cada etapa: Use o MLflow Tracing para capturar entradas e saídas por etapa e o tempo decorrido, para depurar problemas e medir o desempenho.
- registrar o agente: Use MLflow acompanhamento para log o código e a configuração do agente.
Nesse estágio, a perfeição não é o objetivo . O senhor deseja um agente simples e funcional que possa ser implantado para receber feedback antecipado de usuários de teste e PMEs. A próxima etapa é executar uma rápida verificação de qualidade antes de disponibilizá-la em um ambiente de pré-produção.
c. Verificação de qualidade
Antes de expor o agente a um público mais amplo de pré-produção, execute uma verificação de qualidade off-line "suficientemente boa" para detectar quaisquer problemas importantes antes de implantá-lo em um site endpoint. Nesse estágio, o senhor normalmente não terá uma avaliação grande e robusta dataset, mas ainda pode fazer uma passagem rápida para garantir que o agente se comporte como pretendido em algumas consultas de amostra.
-
Teste interativamente em um Notebook
- inspeção manual: ligue manualmente para seu agente com solicitações representativas. Preste atenção se ele recupera os dados corretos, chama as ferramentas corretamente e segue o formato desejado.
- Inspecione os rastros do MLflow: Se o senhor tiver ativado o MLflow Tracing, examine a telemetria passo a passo. Confirme se o agente escolhe a (s) ferramenta (s) apropriada (s), trata os erros normalmente e não gera solicitações ou resultados intermediários inesperados.
- Verifique a latência: Observe quanto tempo cada solicitação leva para ser executada. Se os tempos de resposta ou o uso de tokens forem muito altos, talvez o senhor precise reduzir as etapas ou simplificar a lógica antes de prosseguir.
-
Verificação de vibração
- Isso pode ser feito em um Notebook ou no AI Playground.
- Correção da coerência &: a saída do agente faz sentido para as consultas que você testou? Há imprecisões gritantes ou detalhes ausentes?
- Casos extremos: se você tentou algumas consultas inusitadas, o agente ainda respondeu logicamente ou, pelo menos, falhou normalmente (por exemplo, recusando-se educadamente a responder em vez de produzir resultados sem sentido)?
- Adesão imediata: se você forneceu instruções de alto nível, como tom ou formatação desejados, o agente as está seguindo?
-
Avalie a qualidade " suficientemente boa do "
- Se você estiver limitado em consultas de teste neste momento, considere gerar dados sintéticos. Consulte Criar um conjunto de avaliação.
- Resolva os principais problemas: se você descobrir falhas graves (por exemplo, o agente chama repetidamente ferramentas inválidas ou gera bobagens), corrija esses problemas antes de expô-los a um público maior. Consulte Problemas comuns de qualidade e como corrigi-los.
- Decida sobre a viabilidade: se o agente atender a um padrão básico de usabilidade e exatidão para um pequeno conjunto de consultas, você poderá prosseguir. Caso contrário, refine as solicitações, corrija problemas com ferramentas ou dados e teste novamente.
-
Planeje as próximas etapas
- Acompanhe as melhorias: documente todas as deficiências que você decidir adiar. Depois de coletar feedback do mundo real na pré-produção, você pode revisitá-los.
Se tudo parecer viável para uma implementação limitada, o senhor estará pronto para implantar o agente na pré-produção. Um processo de avaliação completo acontecerá em fases posteriores, especialmente depois de você ter mais dados reais, feedback das PME e um conjunto de avaliação estruturado. Por enquanto, concentre-se em garantir que seu agente demonstre de forma confiável sua funcionalidade principal.
d. agente de pré-produção implantado
Depois que seu agente atender a um limite de qualidade de linha de base, a próxima etapa é hospedá-lo em um ambiente de pré-produção para que você possa entender como os usuários consultam o aplicativo e coletar seu feedback para orientar o desenvolvimento. Esse ambiente pode ser seu ambiente de desenvolvimento durante a fase de POC. O principal requisito é que o ambiente seja acessível para selecionar testadores internos ou especialistas do domínio.
-
implantado o agente
- registrar e registrar o agente: Primeiro, log o agente como um modelo MLflow e registre-o em Unity Catalog.
- implantado usando o Agent Framework: Use o Agent Framework para pegar o agente registrado e implantá-lo como um modelo de serviço endpoint.
-
Tabelas de inferência
- O Agent Framework armazena automaticamente solicitações, respostas e rastreamentos, juntamente com metadados, no servidor de rastreamento do Unity Catalog para cada endpoint de serviço.
-
Proteja e configure
- Controle de acesso: Restrinja o acesso ao endpoint ao seu grupo de teste (PMEs, usuários avançados). Isso garante o uso controlado e evita a exposição inesperada dos dados.
- Autenticação : Confirme se os segredos, tokens de API ou conexões de banco de dados necessários estão configurados corretamente.
Agora você tem um ambiente controlado para coletar feedback sobre consultas reais. Uma das maneiras pelas quais o senhor pode interagir rapidamente com o agente é em AI Playgroundonde o senhor pode selecionar o modelo de serviço recém-criado endpoint e consultar o agente.
e. Coletar feedback do usuário
Depois de implantar o agente em um ambiente de pré-produção, a próxima etapa é coletar feedback de usuários reais e PMEs para descobrir lacunas, identificar imprecisões e refinar ainda mais o agente.
-
Use o aplicativo Review
- Quando o senhor implanta seu agente com o Agent Framework, é criado um aplicativo de revisão simples no estilo de bate-papo. Ele fornece uma interface fácil de usar, na qual os testadores podem fazer perguntas e avaliar imediatamente as respostas do agente.
- Todas as solicitações, respostas e feedback do usuário (curtidas/descurtidas, comentários escritos) são registrados automaticamente no servidor de rastreamento MLflow Databricks , facilitando a análise posterior.
-
Use a UI de monitoramento para inspecionar logs
- Acompanhe os votos positivos/negativos ou o feedback textual na UI de monitoramento para ver quais respostas os testadores consideraram particularmente úteis (ou inúteis).
-
Envolva especialistas em domínios
- Incentivar as PMEs a executar cenários típicos e incomuns. O conhecimento do domínio ajuda a revelar erros sutis, como interpretações errôneas de políticas ou dados ausentes.
- Mantenha uma lista de pendências de problemas, desde pequenos ajustes no prompt até refatorações maiores no pipeline de dados. Decida quais correções priorizar antes de prosseguir.
-
Organize novos dados de avaliação
- Converta interações notáveis ou problemáticas em casos de teste. Com o tempo, eles formam a base de uma avaliação mais robusta dataset.
- Se possível, adicione respostas corretas ou esperadas a esses casos. Isso ajuda a medir a qualidade em ciclos de avaliação subsequentes.
-
Itere com base no feedback
- Aplique soluções rápidas, como pequenas mudanças imediatas ou novas barreiras de proteção, para resolver os pontos problemáticos imediatos.
- Para questões mais complexas, como a necessidade de uma lógica avançada de várias etapas ou de uma nova fonte de dados, reúna evidências suficientes antes de investir em grandes mudanças na arquitetura.
Ao aproveitar o feedback do aplicativo Review, da tabela de inferência logs e das percepções do SME, essa fase de pré-produção ajuda a revelar as lacunas do key e a refinar seu agente de forma iterativa. As interações do mundo real reunidas nesta etapa criam a base para a construção de um conjunto de avaliação estruturado, permitindo a transição de melhorias ad hoc para uma abordagem mais sistemática de medição de qualidade. Depois que os problemas recorrentes forem resolvidos e o desempenho se estabilizar, o senhor estará bem preparado para uma implementação de produção com uma avaliação robusta em vigor.
2. Avalie & iterate
Depois que seu aplicativo gen AI tiver sido testado em um ambiente de pré-produção, a próxima etapa é medir, diagnosticar e refinar sistematicamente sua qualidade. Essa fase de "avaliação e iteração" transforma o feedback bruto e o logs em um conjunto de avaliação estruturado, permitindo que o senhor teste repetidamente as melhorias e garanta que o aplicativo atenda aos padrões exigidos de precisão, relevância e segurança.
Essa fase inclui as seguintes etapas:
- Reúna consultas reais de logs: Converta interações problemáticas ou de alto valor de suas tabelas de inferência em casos de teste.
- Adicionar rótulo de especialista: Sempre que possível, anexe verdades básicas ou diretrizes de estilo e política a esses casos para que o senhor possa medir a correção, a fundamentação e outras dimensões de qualidade de forma mais objetiva.
- Aproveite a avaliação do agente: Use os juízes integrados do LLM ou verificações personalizadas para quantificar a qualidade do aplicativo.
- Iterar: Melhore a qualidade refinando a lógica, o pipeline de dados ou os prompts do seu agente. Execute novamente a avaliação para confirmar se o senhor resolveu os problemas do key.
Observe que esses recursos funcionam mesmo que o seu gen AI app execute fora do Databricks . Ao instrumentar seu código com o MLflow Tracing, o senhor pode capturar traços de qualquer ambiente e unificá-los na Databricks Data Intelligence Platform para avaliação e monitoramento consistentes. À medida que o senhor continua a incorporar novas consultas, feedbacks e percepções das PMEs, sua avaliação dataset se torna um recurso vivo que sustenta um ciclo de melhoria contínua, garantindo que seu aplicativo AI permaneça robusto, confiável e alinhado com as metas de negócios.
a. Avalie o agente
Depois que o agente estiver em execução em um ambiente de pré-produção, a próxima etapa é medir sistematicamente seu desempenho, além das verificações de vibração ad-hoc. Mosaic AI O Agent Evaluation permite que o senhor crie conjuntos de avaliação, execute verificações de qualidade com juízes integrados ou personalizados LLM no site e itere rapidamente nas áreas problemáticas.
Avaliação offline e online
Ao avaliar os aplicativos do site AI, há duas abordagens principais: avaliação off-line e avaliação on-line. Essa fase do ciclo de desenvolvimento se concentra na avaliação off-line, que se refere à avaliação sistemática fora das interações ao vivo do usuário. A avaliação on-line será abordada mais adiante, quando discutirmos o monitoramento do agente na produção.
As equipes costumam confiar demais no teste de vibração "" por muito tempo no fluxo de trabalho do desenvolvedor, tentando informalmente algumas consultas e julgando subjetivamente se as respostas parecem razoáveis. Embora isso forneça um ponto de partida, ele carece do rigor e da cobertura necessários para criar aplicativos com qualidade de produção.
Por outro lado, um processo de avaliação off-line adequado faz o seguinte:
- Estabelece uma linha de base de qualidade antes de uma implantação mais ampla, criando métricas claras para o aprimoramento.
- Identifica pontos fracos específicos que exigem atenção, indo além da limitação de testar apenas os casos de uso esperados.
- Detecta regressões de qualidade à medida que o senhor aperfeiçoa o aplicativo, comparando automaticamente o desempenho entre as versões.
- Fornece métricas quantitativas para demonstrar melhorias às partes interessadas.
- Ajuda a descobrir casos extremos e possíveis modos de falha antes que os usuários o façam.
- Reduz o risco de implantar um agente de baixo desempenho na produção.
Investir tempo na avaliação off-line rende dividendos significativos a longo prazo, ajudando o senhor a fornecer respostas de alta qualidade de forma consistente.
Crie um conjunto de avaliação
Um conjunto de avaliação serve como base para medir o desempenho do seu aplicativo gen AI. Semelhante a um conjunto de testes no desenvolvimento tradicional do software, essa coleção de consultas representativas e respostas esperadas se torna sua referência de qualidade e teste de regressão dataset.

Você pode criar um conjunto de avaliação por meio de várias abordagens complementares:
-
Transformar a tabela de inferência logs em exemplos de avaliação
Os dados de avaliação mais valiosos vêm diretamente do uso real. Sua implantação de pré-produção gerou logs de tabelas de inferência contendo solicitações, respostas de agentes, chamadas de ferramentas e contexto recuperado.
A conversão desses logs em um conjunto de avaliação oferece várias vantagens:
- Cobertura do mundo real: comportamentos imprevisíveis do usuário que você talvez não tenha previsto estão incluídos.
- Focado no problema: você pode filtrar especificamente por feedback negativo ou respostas lentas.
- Distribuição representativa: a frequência real dos diferentes tipos de consulta é capturada.
-
Gere dados de avaliação sintéticos
Se o senhor não tiver um conjunto selecionado de consultas de usuários, poderá gerar automaticamente uma avaliação sintética dataset. Esse conjunto inicial " " de consultas ajuda você a avaliar rapidamente se o agente:
- Retorna respostas coerentes e precisas.
- Responde no formato correto.
- Respeita a estrutura, a tonalidade e as diretrizes políticas.
- Recupera corretamente o contexto (para RAG).
Os dados sintéticos normalmente não são perfeitos. Pense nisso como um trampolim temporário. Você também vai querer:
- Faça com que as PMEs ou especialistas do domínio analisem e eliminem quaisquer consultas irrelevantes ou repetitivas.
- Substitua-o ou aumente-o posteriormente com o uso no mundo real logs.
-
Organize consultas manualmente
Se preferir não depender de dados sintéticos ou ainda não tiver logs de inferência, identifique de 10 a 15 consultas reais ou representativas e crie um conjunto de avaliação a partir delas. As consultas representativas podem vir de entrevistas com usuários ou de um brainstorming com desenvolvedores. Até mesmo uma lista curta e organizada pode expor falhas gritantes nas respostas do seu agente.
Essas abordagens não são mutuamente exclusivas, mas complementares. Um conjunto de avaliação eficaz evolui com o tempo e normalmente combina exemplos de várias fontes, incluindo as seguintes:
- começar com exemplos selecionados manualmente para testar a funcionalidade principal.
- Opcionalmente, adicione dados sintéticos para ampliar a cobertura antes de ter dados reais do usuário.
- Gradualmente, incorpore o mundo real logs à medida que ele se tornar disponível.
- refresh continuamente com novos exemplos que refletem as mudanças nos padrões de uso.
Melhores práticas para consultas de avaliação
Ao criar seu conjunto de avaliação, inclua deliberadamente diversos tipos de consulta, como os seguintes:
- Padrões de uso esperados e inesperados (como solicitações muito longas ou curtas).
- Possíveis tentativas de uso indevido ou ataques imediatos de injeção (como tentativas de revelar o aviso do sistema).
- Consultas complexas que exigem várias etapas de raciocínio ou chamadas de ferramentas.
- Casos de borda com informações mínimas ou ambíguas (como erros de ortografia ou consultas vagas).
- Exemplos que representam diferentes níveis de habilidades e experiências do usuário.
- Consultas que testam possíveis vieses nas respostas (como ", comparam a Empresa A com a Empresa B ").
Lembre-se de que seu conjunto de avaliação deve crescer e evoluir junto com sua inscrição. Ao descobrir novos modos de falha ou comportamentos do usuário, adicione exemplos representativos para garantir que seu agente continue melhorando nessas áreas.
Adicionar critérios de avaliação
Cada exemplo de avaliação deve ter critérios para avaliar a qualidade. Esses critérios servem como padrões pelos quais as respostas do agente são medidas, permitindo uma avaliação objetiva em várias dimensões de qualidade.
Fatos verídicos básicos ou respostas de referência
Ao avaliar a precisão factual, existem duas abordagens principais: fatos esperados ou respostas de referência. Cada um tem um propósito diferente em sua estratégia de avaliação.
Use os fatos esperados (recomendado)
A abordagem expected_facts envolve a listagem dos key fatos que devem aparecer em uma resposta correta. Para ver um exemplo, consulte Exemplo de avaliação definido com request, response, guidelines e expected_facts.
Essa abordagem oferece vantagens significativas:
- Permite flexibilidade na forma como os fatos são expressos na resposta.
- Facilita que as PMEs forneçam informações concretas.
- Acomoda diferentes estilos de resposta, garantindo que as informações essenciais estejam presentes.
- Permite uma avaliação mais confiável em todas as versões do modelo ou configurações de parâmetros.
O juiz de correção integrada verifica se a resposta do agente incorpora esses fatos essenciais, independentemente da fraseologia, da ordem ou do conteúdo adicional.
Use a resposta esperada (alternativa)
Como alternativa, você pode fornecer uma resposta de referência completa. Essa abordagem funciona melhor nas seguintes situações:
- O senhor tem respostas padrão-ouro criadas por especialistas.
- O texto ou a estrutura exata da resposta são importantes.
- Você está avaliando respostas em contextos altamente regulamentados.
Em geral, a Databricks recomenda o uso de expected_facts em vez de expected_response porque oferece mais flexibilidade e, ao mesmo tempo, garante a precisão.
Diretrizes de estilo, tom ou política compliance
Além da precisão factual, talvez seja necessário avaliar se as respostas cumprem requisitos específicos de estilo, tom ou política.
Somente diretrizes
Se sua principal preocupação é impor requisitos de estilo ou política em vez de precisão factual, você pode fornecer diretrizes sem os fatos esperados:
# Per-query guidelines
eval_row = {
"request": "How do I delete my account?",
"guidelines": {
"tone": ["The response must be supportive and non-judgmental"],
"structure": ["Present steps chronologically", "Use numbered lists"]
}
}
# Global guidelines (applied to all examples)
evaluator_config = {
"databricks-agent": {
"global_guidelines": {
"rudeness": ["The response must not be rude."],
"no_pii": ["The response must not include any PII information (personally identifiable information)."]
}
}
}
O juiz de diretrizes do LLM interpreta essas instruções de linguagem natural e avalia se a resposta está de acordo com elas. Isso funciona particularmente bem para dimensões subjetivas de qualidade, como tom, formatação e adesão às políticas organizacionais.

Combinando verdades básicas e diretrizes
Para uma avaliação abrangente, você pode combinar verificações de precisão factual com diretrizes de estilo. Consulte Exemplo de conjunto de avaliação com request, response, guidelines e expected_facts. Essa abordagem garante que as respostas sejam factualmente precisas e estejam de acordo com os padrões de comunicação da sua organização.
Use respostas pré-capturadas
Se você já capturou pares de solicitação-resposta do desenvolvimento ou do teste, pode avaliá-los diretamente sem chamar novamente seu agente. Isso é útil para:
- Analisando os padrões existentes no comportamento do seu agente.
- Benchmarking de desempenho em relação a versões anteriores.
- Economizando tempo e custos ao não regenerar as respostas.
- Avaliação de um agente atendido fora do Databricks.
Para obter detalhes sobre como fornecer as colunas relevantes em seu DataFrame de avaliação, consulte Exemplo: Como passar saídas geradas anteriormente para a Avaliação de agentes. O Mosaic AI Agent Evaluation usa esses valores pré-capturados em vez de ligar novamente para o seu agente, aplicando ainda as mesmas verificações de qualidade e métricas.
Melhores práticas para critérios de avaliação
Ao definir seus critérios de avaliação:
-
Seja específico e objetivo: defina critérios claros e mensuráveis que diferentes avaliadores interpretariam de forma semelhante.
- Considere adicionar métricas personalizadas para medir os critérios de qualidade com os quais o senhor se preocupa.
-
Concentre-se no valor do usuário: priorize os critérios que se alinham com o que é mais importante para seus usuários.
-
começar simples: Comece com um conjunto básico de critérios e amplie-o à medida que sua compreensão das necessidades de qualidade aumentar.
-
Cobertura do equilíbrio: inclua critérios que abordem diferentes aspectos da qualidade (por exemplo, precisão factual, estilo e segurança).
-
Itere com base no feedback: refine seus critérios com base no feedback do usuário e nos requisitos em evolução.
Consulte Práticas recomendadas para desenvolver um conjunto de avaliação para obter mais informações sobre como criar um conjunto de dados de avaliação de alta qualidade.
avaliações de execução
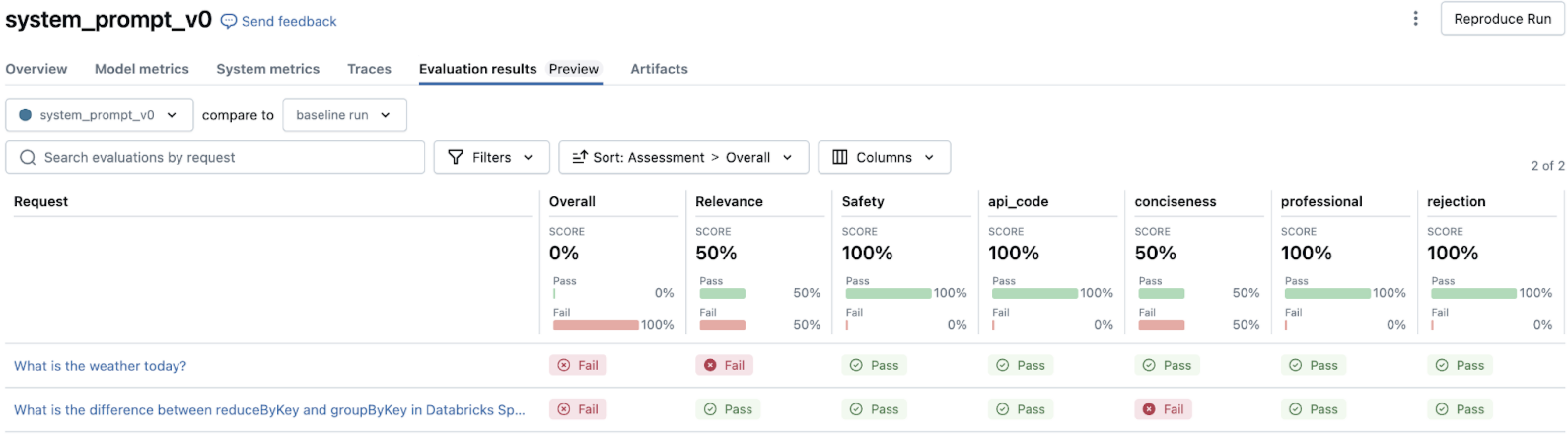
Agora que o senhor preparou um conjunto de avaliação com consultas e critérios, pode executar uma avaliação usando mlflow.evaluate(). Essa função lida com todo o processo de avaliação, desde a invocação do agente até a análise dos resultados.
Avaliação básica fluxo de trabalho
Executar uma avaliação básica requer apenas algumas linhas de código. Para obter detalhes, consulte execução e avaliação.
Quando a avaliação é acionada:
-
Para cada linha em seu conjunto de avaliação,
mlflow.evaluate()faz o seguinte:- Liga para seu agente com a consulta (se você ainda não tiver fornecido uma resposta).
- Aplica a integração LLM de juízes para avaliar as dimensões de qualidade.
- Calcula métricas operacionais, como uso de tokens e latência.
- Registra os fundamentos detalhados de cada avaliação.
-
Os resultados são registrados automaticamente em MLflow, criando:
- Avaliações de qualidade por linha.
- Métricas agregadas em todos os exemplos.
- Detalhado logs para depuração e análise.
Personalize a avaliação
Você pode adaptar a avaliação às suas necessidades específicas usando parâmetros adicionais. O parâmetro evaluator_config permite que você faça o seguinte:
- Selecione os juízes integrados para execução.
- Defina diretrizes globais que se apliquem a todos os exemplos.
- Configurar limite para juízes.
- Forneça alguns exemplos para orientar as avaliações dos juízes.
Para obter detalhes e exemplos, consulte Exemplos.
Avaliar agentes fora do Databricks
Um recurso poderoso da Avaliação de agentes é sua capacidade de avaliar os aplicativos gen AI implantados em qualquer lugar, não apenas em Databricks.
Quais juízes são aplicados
defaultEm, o Agent Evaluation seleciona automaticamente os juízes apropriados LLM com base nos dados disponíveis em seu conjunto de avaliação. Para obter detalhes sobre como a qualidade é avaliada, consulte Como a qualidade é avaliada pelos juízes do LLM.
Analise os resultados da avaliação
Depois de executar uma avaliação, a interface do usuário MLflow fornece visualizações e percepções para entender o desempenho do seu aplicativo. Essa análise ajuda o senhor a identificar padrões, diagnosticar problemas e priorizar melhorias.
Navegue pelos resultados da avaliação
Ao abrir a interface do usuário MLflow depois de executar mlflow.evaluate(),, o senhor encontrará várias visualizações interconectadas. Para obter informações sobre como navegar por esses resultados na UI MLflow, consulte Revisar a saída usando a UI MLflow.
Para obter orientação sobre como interpretar os padrões de falha, consulte b. Melhorar o agente e as ferramentas.
Personalizado AI judges & métricas
Embora os juízes integrados cubram muitas verificações comuns (como correção, estilo, política e segurança), talvez o senhor precise avaliar aspectos específicos do domínio do desempenho do seu aplicativo. Juízes e métricas personalizados permitem que o senhor amplie os recursos de avaliação para atender aos seus requisitos exclusivos de qualidade.
Para obter detalhes sobre como criar um juiz LLM personalizado a partir de um prompt, consulte Criar juízes AI a partir de um prompt.
Os juízes personalizados se destacam na avaliação de dimensões de qualidade subjetivas ou diferenciadas que se beneficiam de um julgamento semelhante ao humano, como:
- Domínio específico compliance (jurídico, médico, financeiro).
- Voz da marca e estilo de comunicação.
- Sensibilidade cultural e adequação.
- Qualidade de raciocínio complexo.
- Convenções de redação especializadas.
O resultado do juiz aparece na interface do usuário MLflow junto com os juízes integrados, com as mesmas justificativas detalhadas que explicam as avaliações.
Para avaliações mais programáticas e determinísticas, o senhor pode criar métricas personalizadas usando o decorador @metric. Veja o decorador @metric.
As métricas personalizadas são ideais para:
- Verificação de requisitos técnicos, como validação de formato e esquema compliance.
- Verificar a presença ou ausência de conteúdo específico.
- Realizar medições quantitativas, como pontuações de comprimento de resposta ou complexidade.
- Implementação de regras de validação específicas da empresa.
- Integração com sistemas de validação externos.
b. Melhore o agente e as ferramentas
Depois de executar a avaliação e identificar os problemas de qualidade, a próxima etapa é abordar sistematicamente esses problemas para melhorar o desempenho. Os resultados da avaliação fornecem percepções valiosas sobre onde e como seu agente está falhando, permitindo que o senhor faça melhorias direcionadas em vez de ajustes aleatórios.
Problemas comuns de qualidade e como corrigi-los
As avaliações dos juízes do LLM a partir dos resultados de sua avaliação apontam para tipos específicos de falhas em seu sistema de agentes. Esta seção explora esses padrões de falha comuns e suas soluções. Para obter informações sobre como interpretar os resultados do juiz LLM, consulte AI judge outputs.
Melhores práticas de iteração de qualidade
À medida que você itera nas melhorias, mantenha uma documentação rigorosa. Por exemplo:
-
Versione suas alterações
- Registre cada iteração significativa usando MLflow acompanhamento.
- Salve prompts, configurações e parâmetros do key em um arquivo de configuração central. Certifique-se de que isso seja registrado com o agente.
- Para cada novo agente implantado, mantenha um registro de alterações em seu repositório detalhando o que mudou e por quê.
-
Documente o que funcionou e o que não funcionou
- Documente as abordagens bem-sucedidas e malsucedidas.
- Observe o impacto específico de cada alteração nas métricas. Link de volta para a execução do MLflow de avaliação do agente.
-
Alinhe-se com as partes interessadas
-
Use o aplicativo Review para validar melhorias com PMEs.
- Comunique as alterações aos revisores usando as instruções do revisor.
-
Para uma comparação lado a lado de diferentes versões de um agente, considere a possibilidade de criar um endpoint de vários agentes e usar o modelo em AI Playground. Isso permite que os usuários enviem a mesma solicitação para um endpoint separado e examinem a resposta e os rastreamentos lado a lado.
-
3. Produção
Depois de avaliar e aprimorar seu aplicativo de forma iterativa, você atingiu um nível de qualidade que atende aos seus requisitos e está pronto para um uso mais amplo. A fase de produção envolve a implantação do agente refinado no ambiente de produção e a implementação do monitoramento contínuo para manter a qualidade ao longo do tempo.
A fase de produção inclui:
- Implantar o agente na produção: Configure um site endpoint pronto para produção com as configurações adequadas de segurança, dimensionamento e autenticação.
- Monitore o agente em produção: Estabeleça a avaliação contínua da qualidade, o acompanhamento do desempenho e a emissão de alertas para garantir que o agente mantenha alta qualidade e confiabilidade no uso real.
Isso cria um ciclo de feedback contínuo em que as percepções de monitoramento geram melhorias adicionais, que o senhor pode testar, implantar e continuar a monitorar. Essa abordagem garante que seu aplicativo permaneça de alta qualidade, compatível e alinhado às necessidades comerciais em evolução durante todo o ciclo de vida.
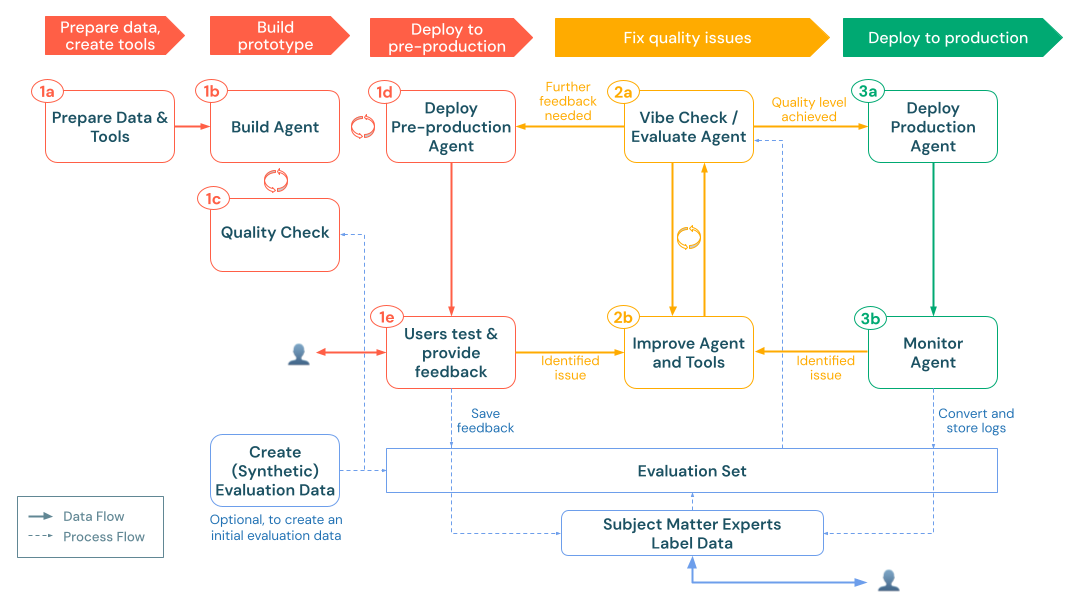
a. agente implantado para produção
Depois de concluir a avaliação completa e o aprimoramento iterativo, o senhor estará pronto para implantar o agente em um ambiente de produção. [Mosaic AI Agent Framework](/generative-AI/agent-framework/build-gen AI-apps.md#agent-framework) simplifica esse processo ao lidar automaticamente com muitas questões de implantação.
Processo de implantação
A implantação do agente na produção envolve as seguintes etapas:
- Faça o logon e registre seu agente como um modelo MLflow em Unity Catalog.
- Implantar o agente usando o Agent Framework.
- Configure a autenticação para qualquer recurso dependente que seu agente precise acessar.
- Teste a implantação para verificar a funcionalidade no ambiente de produção.
- Depois que o modelo de atendimento endpoint estiver pronto, o senhor poderá interagir com o agente no site AI Playground, onde poderá testar e verificar a funcionalidade.
Para obter etapas detalhadas de implementação, consulte Implantação de um agente para aplicativos AI generativos.
Considerações sobre a implantação da produção
Ao passar para a produção, tenha em mente as seguintes considerações key:
desempenho e escalonamento
- Equilibre o custo e o desempenho com base em seus padrões de uso esperados.
- Considere habilitar a escala até zero para agentes usados de forma intermitente para reduzir os custos.
- Entenda os requisitos de latência com base nas necessidades de experiência do usuário do seu aplicativo.
Segurança e governança
- Garanta controles de acesso adequados no nível do Unity Catalog para todos os componentes do agente.
- Use a passagem de autenticação integrada para Databricks recurso sempre que possível.
- Configure o gerenciamento de credenciais apropriado para APIs externo ou fonte de dados.
Abordagem de integração
-
Determine como seu aplicativo interagirá com o agente (por exemplo, usando uma API ou uma interface incorporada).
-
Considere como lidar e exibir as respostas dos agentes em seu aplicativo.
- Se seu aplicativo cliente precisar de contexto adicional (como referências de documentos de origem ou pontuações de confiança), crie seu agente para incluir esses metadados em suas respostas (por exemplo, usando saídas personalizadas).
-
Planeje o tratamento de erros e os mecanismos de fallback para quando o agente não estiver disponível.
Coleta de feedback
- Utilize o aplicativo Review para coletar feedback das partes interessadas durante a implementação inicial.
- Crie mecanismos para coletar feedback do usuário diretamente na interface do seu aplicativo.
- Garanta que os dados de feedback fluam para seu processo de avaliação e melhoria.
b. Agente de monitoramento em produção
Depois que o agente é implantado na produção, é essencial monitorar continuamente o desempenho, a qualidade e os padrões de uso. Ao contrário do software tradicional, em que a funcionalidade é determinística, os aplicativos da geração AI podem apresentar desvios de qualidade ou comportamentos inesperados à medida que encontram entradas do mundo real. O monitoramento eficaz permite que o senhor detecte problemas antecipadamente, entenda os padrões de uso e melhore continuamente a qualidade do seu aplicativo.
Configurar o monitoramento de agentes
Mosaic AI fornece recursos integrados de monitoramento que permitem que o senhor acompanhe o desempenho de seus agentes sem criar uma infraestrutura de monitoramento personalizada:
- Crie um monitor para seu agente implantado.
- Configure a taxa e a frequência de amostragem com base no volume de tráfego e nas necessidades de monitoramento.
- Selecione métricas de qualidade para avaliar automaticamente as solicitações amostradas.
Principais dimensões do monitoramento
Em geral, o monitoramento eficaz deve abranger três dimensões críticas:
-
Métricas operacionais
- Volume e padrões de solicitação.
- Latência de resposta.
- Taxas e tipos de erros.
- uso e custos de tokens.
-
Qualidade métricas
- Relevância para as consultas dos usuários.
- Fundamentação no contexto recuperado.
- Segurança e cumprimento das diretrizes.
- Taxa geral de aprovação de qualidade.
-
Feedback do usuário
- Feedback explícito (polegar para cima/para baixo).
- Sinais implícitos (perguntas de acompanhamento, conversas abandonadas).
- Problemas relatados ao canal de suporte.
Use a UI de monitoramento
A UI de monitoramento fornece percepções visualizadas nessas dimensões por meio de duas guias.
- Gráficos tab : veja as tendências em volume de solicitações, qualidade métrica, latência e erros ao longo do tempo.
- logs tab : Examine as solicitações e respostas individuais, incluindo os resultados da avaliação.
Os recursos de filtragem permitem que os usuários pesquisem consultas específicas ou filtrem por resultado da avaliação.
Criar painéis de controle e alertas
Para um monitoramento abrangente:
- Crie dashboards personalizados usando os dados de monitoramento armazenados na tabela de traces avaliados.
- Configure um alerta para qualidade crítica ou limite operacional.
- Programar revisões regulares de qualidade com key stakeholders.
Ciclo de melhoria contínua
O monitoramento é mais valioso quando alimenta o seu processo de aprimoramento:
- Identificar problemas por meio do monitoramento de métricas e do feedback dos usuários.
- Exporte exemplos problemáticos para seu conjunto de avaliação.
- Diagnosticar as causas principais usando a análise de rastreamento do MLflow e os resultados do LLM judge (conforme discutido em Problemas comuns de qualidade e como corrigi-los).
- Desenvolva e teste melhorias em relação ao seu conjunto de avaliação expandido.
- implantar atualizações e monitorar o impacto.
Essa abordagem iterativa de ciclo fechado ajuda a garantir que seu agente continue melhorando com base nos padrões de uso do mundo real, mantendo a alta qualidade e se adaptando às mudanças nos requisitos e nos comportamentos dos usuários. Com o Agent Monitor, o senhor obtém visibilidade do desempenho do seu agente na produção, o que lhe permite solucionar problemas de forma proativa e otimizar a qualidade e o desempenho.