Criar um agente de AI e implantá-lo no Databricks Apps
Crie um agente de AI e implantado-o usando Databricks Apps. Databricks Apps oferece controle total sobre o código do agente, a configuração do servidor e o fluxo de trabalho de implantação. Essa abordagem é ideal quando há necessidade de comportamento personalizado do servidor, versionamento baseado em Git ou desenvolvimento de IDE local.
Se o seu agente usar apenas ferramentas hospedadas pelo Databricks e não precisar de lógica personalizada entre as chamadas de ferramentas, você poderá usar a API do Supervisor (Beta) para permitir que o Databricks gerencie o loop do agente para você.
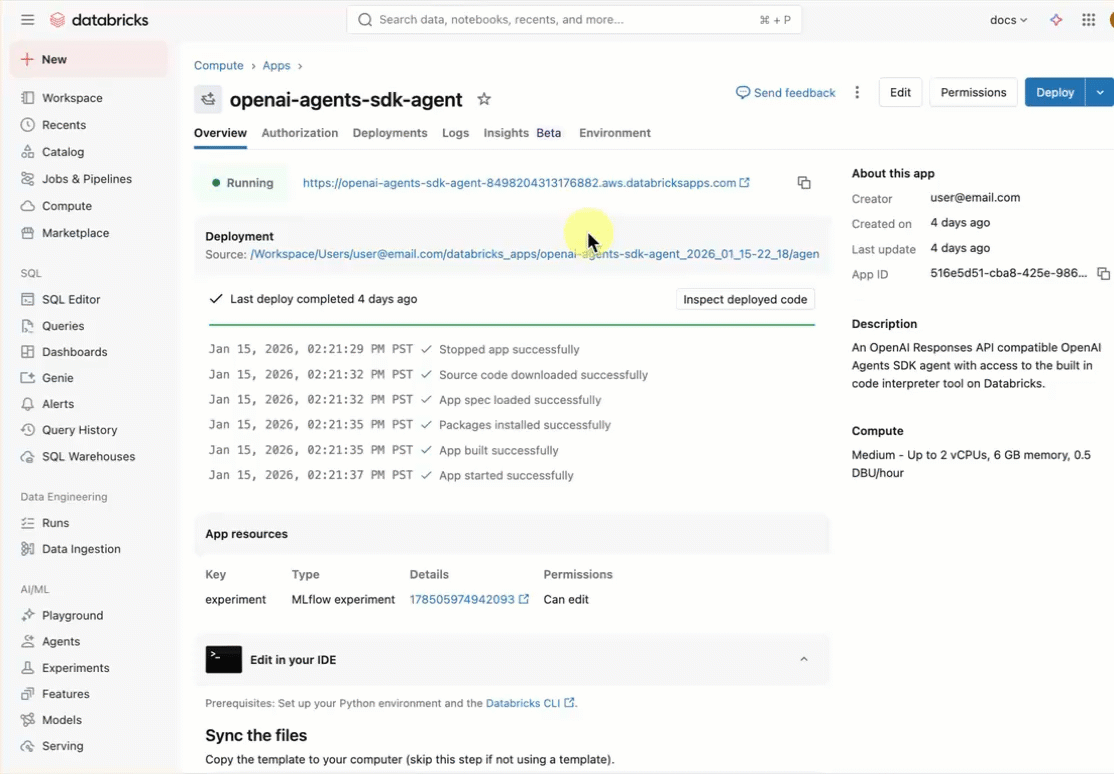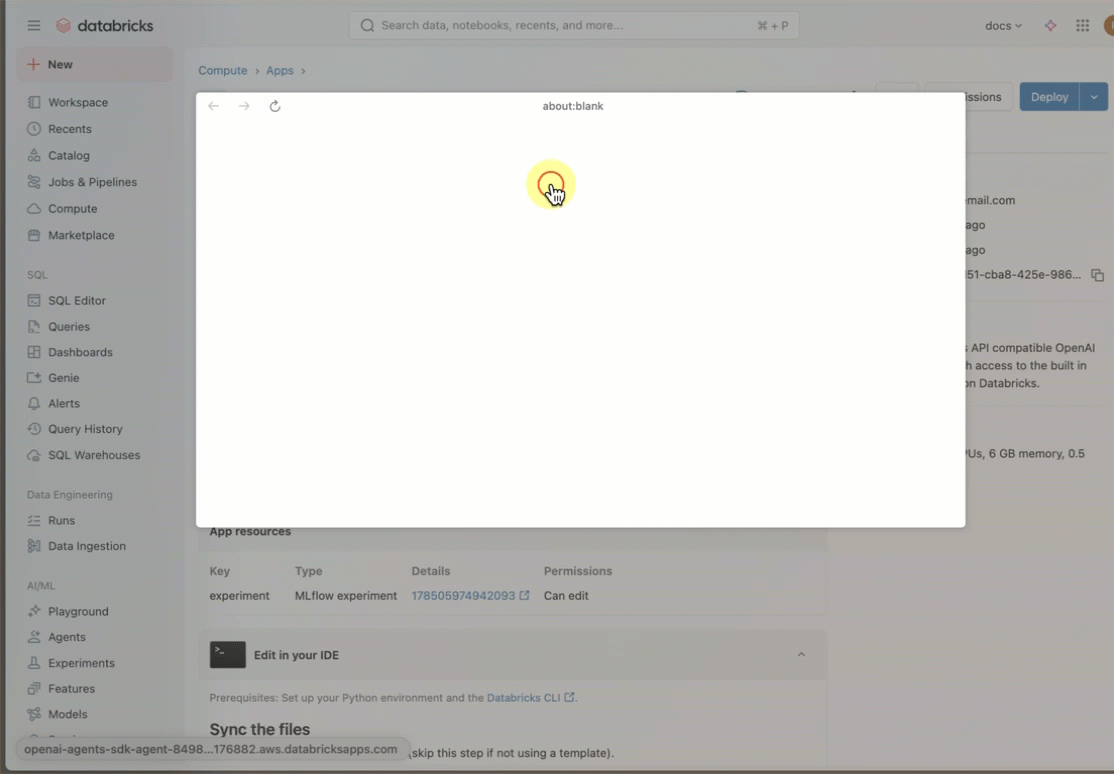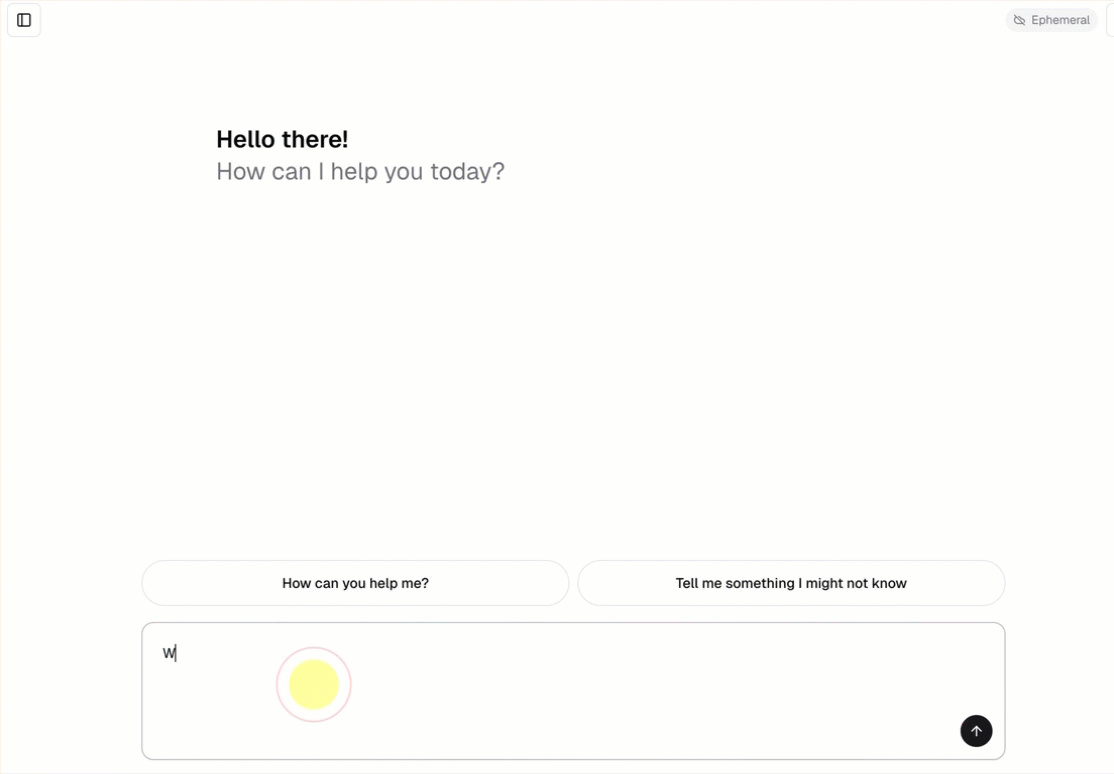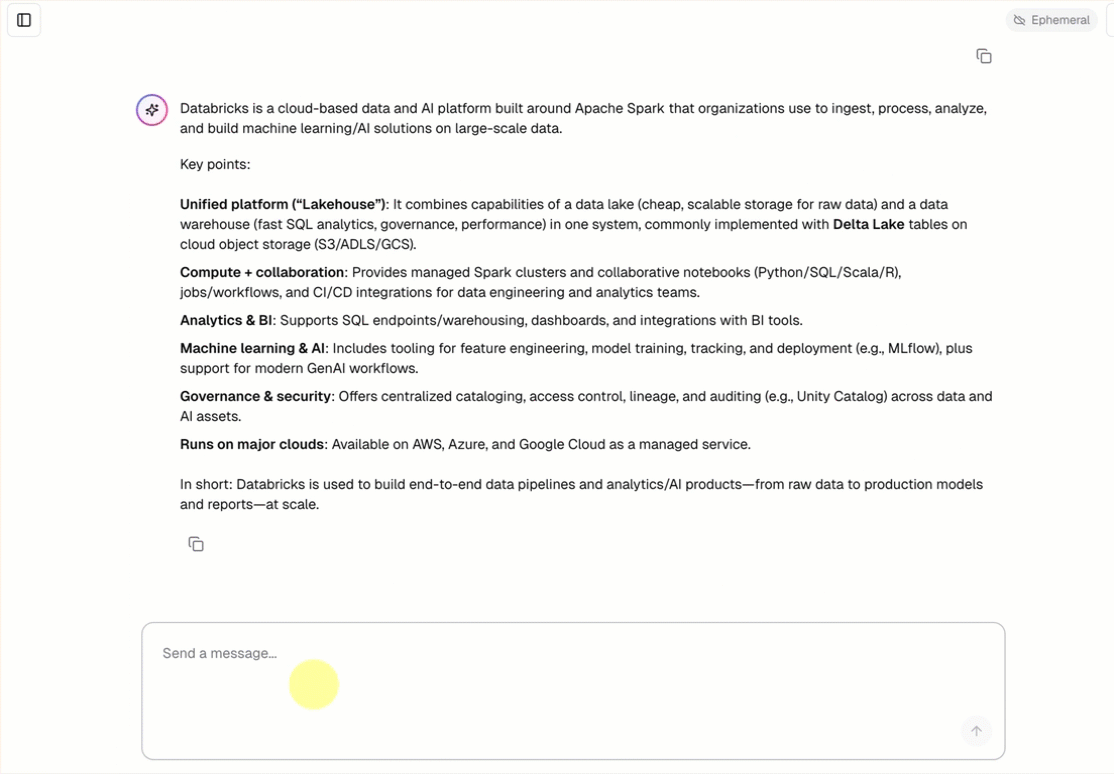
Cada padrão de agente conversacional inclui uma interface de chat integrada (mostrada acima) sem necessidade de configuração adicional. A interface de chat oferece suporte a respostas de transmissão, renderização de markdown, autenticação Databricks e história de chat persistente opcional.
Requisitos
Habilite os Databricks Apps em seu workspace. Consulte Configure seu workspace e ambiente de desenvolvimento dos Databricks Apps.
O passo 1. Clone o padrão do aplicativo do agente
Comece usando um padrão de agente pré-criado do repositório de padrões de aplicativo Databricks.
Este tutorial usa o padrão agent-openai-agents-sdk, que inclui:
- Um agente criado usando o SDK do OpenAI Agent
- Código inicial para um aplicativo de agente com uma API REST conversacional e uma IU de chat interativa
- Código para avaliar o agente usando MLflow
Escolha um dos seguintes caminhos para configurar o padrão:
- Workspace UI
- Clone from GitHub
Instale o padrão de aplicativo usando a IU do Workspace. Isso instala o aplicativo e o deixa implantado em um recurso de compute em seu workspace. Você pode sincronizar os arquivos do aplicativo com seu ambiente local para desenvolvimento posterior.
-
No seu workspace do Databricks, clique em **+ Novo** >**Aplicativo**.
-
Clique em **Agentes** > **Agente Personalizado (OpenAI SDK)**.
-
Crie um novo experimento MLflow com o nome
openai-agents-templatee conclua o restante da configuração para instalar o padrão. -
Depois de criar o aplicativo, clique no URL do aplicativo para abrir a interface do usuário do chat.
Depois que o aplicativo for criado, baixe o código-fonte para sua máquina local para personalizá-lo:
-
Copie o primeiro comando em Sincronizar os arquivos
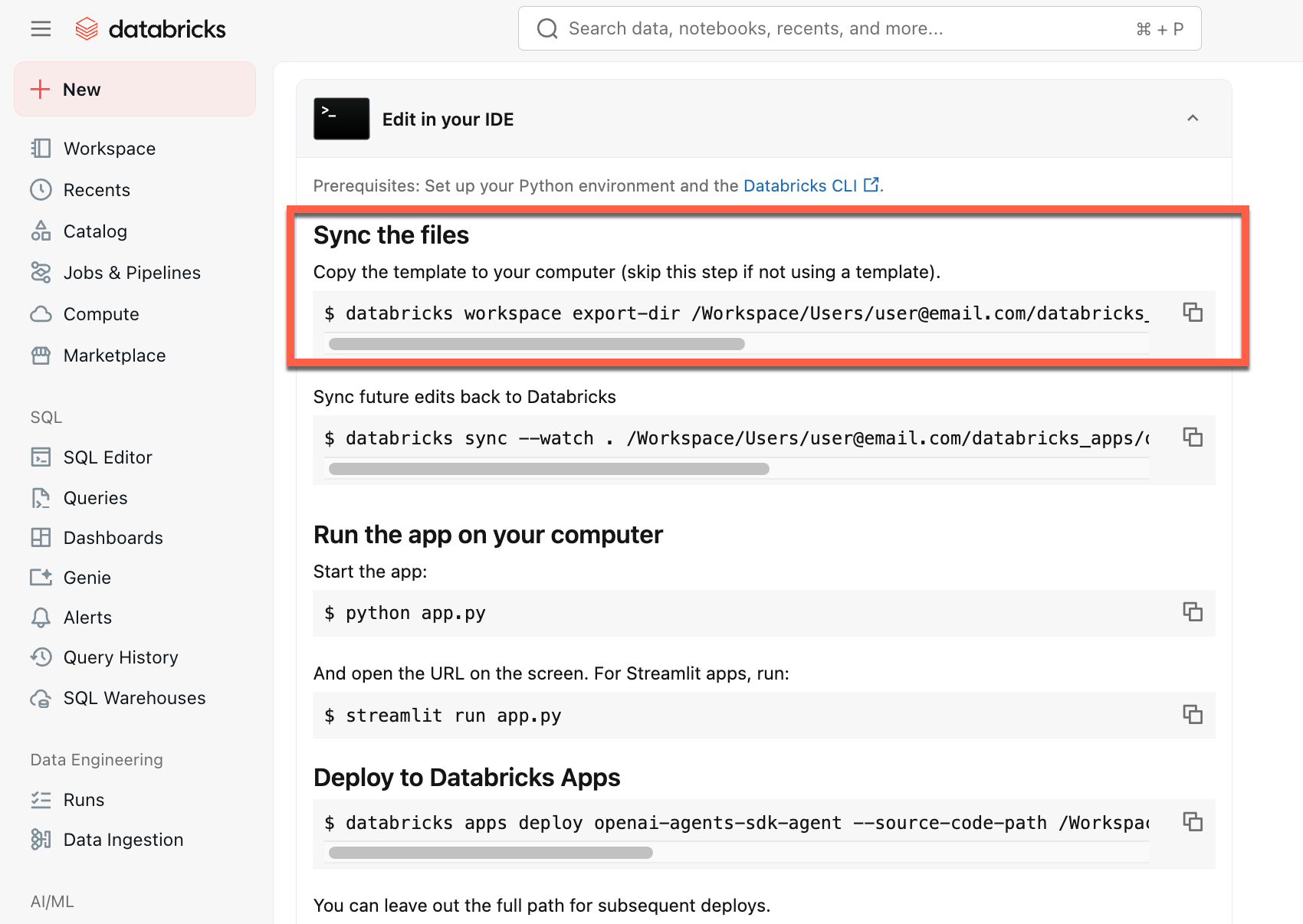
-
Em um terminal local, execute o comando copiado.
Para começar a partir de um ambiente local, clone o repositório do modelo de agente e abra o diretório agent-openai-agents-sdk:
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-agents-sdk
O passo 2. Entender a aplicação do agente
O padrão de agente demonstra uma arquitetura pronta para produção com esses componentes-key. Abra as seções a seguir para obter mais detalhes sobre cada componente:

Abra as seções a seguir para obter mais detalhes sobre cada componente:
 Interface de chat integrada
Interface de chat integrada
O padrão do agente busca e executa automaticamente o padrão de aplicativo de chat como seu frontend. Esta interface de usuário de chat é empacotada na mesma implantação do Databricks Apps e servida junto com seu agente, portanto, nenhuma configuração adicional é necessária.
Você pode personalizar a interface de chat diretamente no seu projeto. Para mais detalhes sobre o recurso do aplicativo de chat, incluindo como habilitar a história de chat persistente e a coleta de feedback do usuário, consulte Construir e Compartilhar uma Interface de Chat com Databricks Apps.
 MLflow AgentServer
MLflow AgentServer
Um servidor FastAPI assíncrono que lida com solicitações de agente com rastreamento e observabilidade integrados. O AgentServer fornece o endpoint /responses para consultar seu agente e gerencia automaticamente o roteamento de solicitações, log e tratamento de erros.
 interface
interfaceResponsesAgent
ResponsesAgentDatabricks recomenda o MLflow ResponsesAgent para construir agentes. ResponsesAgent permite que você crie agentes com qualquer framework de terceiros, e os integre aos recursos de AI da Databricks para funcionalidades robustas de registro em log, rastreamento, avaliação, implantação e monitoramento.

Para saber como criar um ResponsesAgent, consulte os exemplos na documentação do MLflow - ResponsesAgent para Model Serving.
ResponsesAgent oferece as seguintes vantagens:
-
Capacidades avançadas de agente
- Suporte multiagente
- Saída de transmissão : Transmita a saída em blocos menores.
- História abrangente de mensagens de chamada de ferramenta : retorne várias mensagens, incluindo mensagens intermediárias de chamada de ferramenta, para melhor qualidade e gerenciamento de conversas.
- Suporte à confirmação de chamada de ferramenta
- Suporte para ferramentas de longa duração
-
Desenvolvimento, implantação e monitoramento otimizados
- **Crie agentes usando qualquer estrutura**: Ajuste qualquer agente existente usando a
ResponsesAgentinterface para obter compatibilidade pronta para uso com AI Playground, Agent Evaluation e monitoramento. - Interfaces de autoria com tipagem : escreva o código do agente usando classes Python tipadas, beneficiando-se do preenchimento automático da IDE e do Notebook.
- **Rastreamento automático**: O MLflow agrega automaticamente as respostas de transmissão em rastreamentos para facilitar a avaliação e a exibição.
- **Compatível com o
Responsesesquema do OpenAI**: Consulte OpenAI: Respostas x ChatCompletion.
- **Crie agentes usando qualquer estrutura**: Ajuste qualquer agente existente usando a
 SDK do OpenAI Agentes
SDK do OpenAI Agentes
O padrão usa o SDK de Agentes OpenAI como o framework de agente para gerenciamento de conversas e orquestração de ferramentas. Você pode criar agentes usando qualquer framework. O segredo é encapsular seu agente com a interface MLflow ResponsesAgent.
 Servidores do MCP (Protocolo de Contexto de Modelo)
Servidores do MCP (Protocolo de Contexto de Modelo)
O padrão conecta aos servidores Databricks MCP para dar aos agentes acesso a ferramentas e fontes de dados. Consulte Protocolo de Contexto de Modelo (MCP) no Databricks.
Crie agentes usando assistentes de codificação de AI
A Databricks recomenda o uso de assistentes de codificação de AI, como Claude, Cursor e Copilot, para criar agentes. Use as habilidades de agente fornecidas, em /.claude/skills, e o arquivo AGENTS.md para ajudar os assistentes de AI a entender a estrutura do projeto, as ferramentas disponíveis e as melhores práticas. Os agentes podem ler esses arquivos automaticamente para desenvolver e implantado os Databricks Apps.
O passo 3. Adicione ferramentas ao seu agente
Dê ao seu agente capacidades como consultar bancos de dados, pesquisar documentos ou chamar APIs externas conectando-o a servidores MCP. O padrão do agente inclui uma conexão de servidor MCP default. Para adicionar mais ferramentas, configure servidores MCP adicionais no código do seu agente e conceda as permissões necessárias em databricks.yml.
Consulte Conectar agentes a ferramentas para tipos de ferramentas compatíveis e exemplos de código.
Defina ferramentas de função Python locais
Para operações que não exigem fontes de dados externas ou APIs, defina as ferramentas diretamente no código do seu agente. Essas ferramentas são executadas no mesmo processo que seu agente e são úteis para transformações de dados, cálculos ou operações de utilidade.
- OpenAI Agents SDK
- LangGraph
Use o decorador @function_tool do SDK do OpenAI Agents:
from agents import Agent, function_tool
@function_tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = Agent(
name="My agent",
instructions="You are a helpful assistant.",
model="databricks-claude-sonnet-4-5",
tools=[get_current_time],
)
Use o decorador @tool da LangChain:
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
from databricks_langchain import ChatDatabricks
@tool
def get_current_time() -> str:
"""Get the current date and time."""
from datetime import datetime
return datetime.now().isoformat()
agent = create_react_agent(
ChatDatabricks(endpoint="databricks-claude-sonnet-4-5"),
tools=[get_current_time],
)
Ferramentas de função local não exigem concessões de recursos em databricks.yml, pois são executadas dentro do processo do agente.
O passo 4. Governe o uso de LLM de seus agentes em Databricks Apps com o Unity AI Gateway
Encaminhe as chamadas de LLM do seu agente pelo Unity AI Gateway (Beta) para que cada solicitação seja governada pelos mesmos controles, independentemente de qual provedor a responda. Com o gateway no caminho da solicitação, o senhor pode centralizar permissões, atribuir custos por aplicativo, fazer swap de modelos e inspecionar ou reproduzir o tráfego sem modificar o código do agente ou rotacionar as credenciais do provedor.
Beta
Este recurso está em Beta. Os administradores de workspace podem controlar o acesso a este recurso na página **Pré-visualizações**. Consulte Gerenciar prévias do Databricks.
-
Habilite o Unity AI Gateway no seu workspace. Unity AI Gateway é opcional durante a fase Beta. Um administrador da account deve ativá-lo no console da account, na página **Prévias**, antes que você possa criar ou consultar endpoints de gateway. Consulte Gerenciar prévias do Databricks.
-
Direcione seu agente para um endpoint do Unity AI Gateway. No código do seu agente, passe o nome do endpoint do Unity AI Gateway como argumento
modele definause_ai_gateway=Trueno cliente LLM do Databricks. O cliente roteia o tráfego através do gateway e lida com a autenticação automaticamente.
- OpenAI
- LangGraph
from agents import Agent, set_default_openai_api, set_default_openai_client
from databricks_openai import AsyncDatabricksOpenAI
set_default_openai_client(AsyncDatabricksOpenAI(use_ai_gateway=True))
set_default_openai_api("chat_completions")
agent = Agent(
name="Agent",
instructions="You are a helpful assistant.",
model="<ai-gateway-endpoint>",
)
from databricks_langchain import ChatDatabricks
llm = ChatDatabricks(
model="<ai-gateway-endpoint>",
use_ai_gateway=True,
)
Para superfícies de API adicionais (API de Respostas OpenAI, API de Mensagens Anthropic, Google Gemini) e exemplos de REST, consulte Consultar serviços de modelo.
Tópicos avançados de autoria
Respostas de transmissão
Respostas de transmissão
A transmissão permite que os agentes enviem respostas em partes em tempo real em vez de esperar pela resposta completa. Para implementar a transmissão com ResponsesAgent, emita uma série de eventos delta seguidos por um evento de conclusão final:
- Emitir eventos delta : Enviar vários eventos
output_text.deltacom o mesmoitem_idpara transmitir blocos de texto em tempo real. - Finalizar com evento de conclusão : Envie um evento
response.output_item.donefinal com o mesmoitem_idque os eventos delta contendo o texto de saída final completo.
Cada evento delta faz uma transmissão de um fragmento de texto para o cliente. O evento de conclusão final contém o texto completo da resposta e sinaliza à Databricks para fazer o seguinte:
- Rastreie a saída do seu agente com o rastreamento do MLflow
- Agregue as respostas de transmissão em tabelas de inferência do Unity AI Gateway
- Mostrar a saída completa na UI do AI Playground
Propagação de erros de transmissão
Databricks propaga quaisquer erros encontrados durante a transmissão com o último token em databricks_output.error. Cabe ao cliente chamador lidar e expor esse erro adequadamente.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
Entradas e saídas personalizadas
Entradas e saídas personalizadas
Alguns cenários podem exigir entradas de agente adicionais, como client_type e session_id, ou saídas como links de origem de recuperação que não devem ser incluídos na história do chat para futuras interações.
Para esses cenários, o MLflow ResponsesAgent suporta nativamente os campos custom_inputs e custom_outputs. Você pode acessar as entradas personalizadas por meio de request.custom_inputs nos exemplos de framework acima.
O aplicativo de revisão de Agent Evaluation não oferece suporte à renderização de rastreamentos para agentes com campos de entrada adicionais.
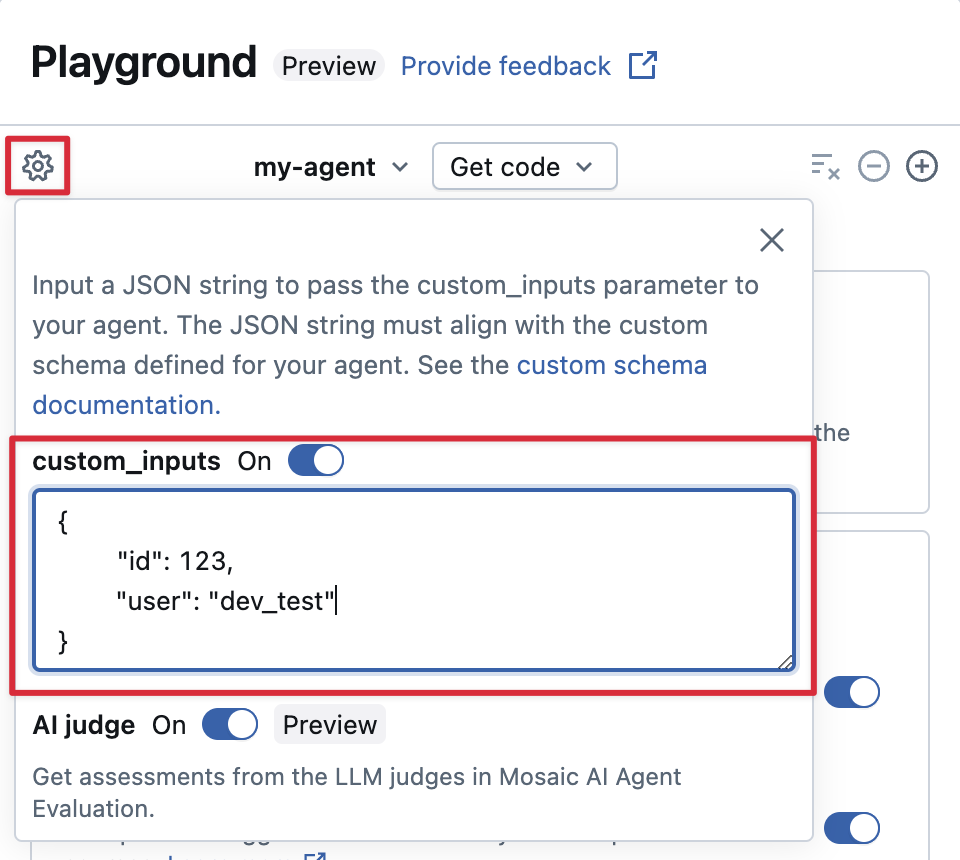
Forneça custom_inputs no AI Playground e no aplicativo de revisão
Se o agente aceitar entradas adicionais usando o campo custom_inputs, é possível fornecer essas entradas manualmente no AI Playground e no aplicativo de avaliação.
-
No AI Playground ou no Aplicativo de Revisão de Agente, selecione o ícone de engrenagem
 .
. -
Habilitar custom_inputs .
-
Forneça um objeto JSON que corresponda ao esquema de entrada definido do seu agente.
O passo 5. Realize a execução do aplicativo do agente localmente
Configure seu ambiente local:
-
Instalar
uv(gerenciador de pacotes Python),nvm(gerenciador de versões Node) e a CLI do Databricks:-
Execute o seguinte para usar o Node 20 LTS:
Bashnvm use 20
-
Mude o diretório para a pasta
agent-openai-agents-sdk. -
Realize a execução dos scripts de início rápido fornecidos para instalar dependências, configurar seu ambiente e começar o aplicativo.
Bashuv run quickstart
uv run start-app
Em um navegador, vá para http://localhost:8000 para abrir a interface de chat integrada e começar a conversar com o agent.
o passo 6. Configurar autenticação
Seu agente precisa de autenticação para acessar os recursos do Databricks. O Databricks Apps fornece dois métodos de autenticação: autorização de aplicativo (entidade de serviço) e autorização de usuário (em nome do usuário). Você pode configurar qualquer um dos dois através da UI do workspace ou declarativamente em databricks.yml com os Declarative Automation Bundles. Os modelos de agente padrão vêm com um databricks.yml, então esse caminho é o default quando você começa a partir de um padrão.
Para a referência completa, incluindo todos os tipos de recurso suportados, valores de permissão e um passo a passo completo databricks.yml, consulte Autenticação para agentes de AI.
- App authorization (default)
- User authorization
A autorização do aplicativo usa uma entidade de serviço que o Databricks cria automaticamente para o seu aplicativo. Todos os usuários compartilham as mesmas permissões.
Declare todos os recursos que o agente usa em resources.apps.<app>.resources em databricks.yml. Implante o pacote para conceder à entidade de serviço as permissões declaradas:
resources:
apps:
agent_openai_agents_sdk:
name: 'agent-openai-agents-sdk'
source_code_path: ./
config:
command: ['uv', 'run', 'start-app']
env:
- name: MLFLOW_TRACKING_URI
value: 'databricks'
- name: MLFLOW_REGISTRY_URI
value: 'databricks-uc'
- name: MLFLOW_EXPERIMENT_ID
value_from: 'experiment'
resources:
- name: 'experiment'
experiment:
experiment_id: '<experiment-id>'
permission: 'CAN_EDIT'
- name: 'llm'
serving_endpoint:
name: 'databricks-claude-sonnet-4-5'
permission: 'CAN_QUERY'
databricks bundle deploy
databricks bundle run agent_openai_agents_sdk
Para a lista completa de tipos de recursos, consulte Autorização de aplicativo.
A autorização do usuário permite que seu agente atue com as permissões individuais de cada usuário. Use isto quando precisar de controle de acesso por usuário ou trilhas de auditoria.
Adicione este código ao seu agente:
from agent_server.utils import get_user_workspace_client
# In your agent code (inside @invoke or @stream)
user_workspace = get_user_workspace_client()
# Access resources with the user's permissions
response = user_workspace.serving_endpoints.query(name="my-endpoint", inputs=inputs)
Inicialize get_user_workspace_client() dentro de suas funções @invoke ou @stream, não durante o startup do aplicativo. As credenciais de usuário existem apenas ao processar uma solicitação.
Configure quais APIs do Databricks o agente pode chamar em nome do usuário adicionando escopos em user_api_scopes no aplicativo em databricks.yml:
resources:
apps:
agent_openai_agents_sdk:
name: 'agent-openai-agents-sdk'
source_code_path: ./
user_api_scopes:
- sql
- genie
- model-serving
databricks bundle deploy
databricks bundle run agent_openai_agents_sdk
Para a lista de escopos disponíveis e instruções completas de configuração, consulte Autorização do usuário.
O passo 7. Avalie o agente
O modelo padrão inclui código de avaliação de agente. Consulte agent_server/evaluate_agent.py para obter mais informações. Avalie a relevância e a segurança das respostas do seu agente, executando o seguinte em um terminal:
uv run agent-evaluate
Etapa 8. Implante o agente no Databricks Apps
Após configurar a autenticação, o seu agente estará implantado no Databricks. Os padrões de agente usam Databricks Asset Bundles (DABs) para implantação. O arquivo databricks.yml no padrão define a configuração do aplicativo e as permissões de recurso. Certifique-se de ter a CLI do Databricks instalada e configurada.
Se você criou seu aplicativo pela IU do Workspace na Etapa 1, execute databricks bundle deployment bind agent_openai_agents_sdk <app-name> --auto-approve antes de implantar para vincular o aplicativo existente ao seu pacote. Caso contrário, databricks bundle deploy falha com "Um aplicativo com o mesmo nome já existe".
-
Valide a configuração do pacote para detectar erros antes de implantar:
Bashdatabricks bundle validate -
Implante o pacote. Isso faz upload do seu código e configura o recurso (experimento MLflow, endpoint de serviço e assim por diante) definidos em
databricks.yml:Bashdatabricks bundle deploy -
Começar ou reiniciar o aplicativo:
Bashdatabricks bundle run agent_openai_agents_sdk
bundle deploy apenas faz upload de arquivos e configura recursos. bundle run é necessário para começar ou reiniciar o aplicativo com o novo código.
Para futuras atualizações, execute databricks bundle deploy e, em seguida, databricks bundle run agent_openai_agents_sdk para reimplantar.
O passo 9. Consultar o agente implantado
O exemplo a seguir usa uma requisição curl rápida com tokens OAuth. Tokens de acesso pessoal (PATs) não são compatíveis com o Databricks Apps.
Para obter a lista completa de métodos de consulta, incluindo o Cliente OpenAI e a API REST do Databricks, consulte Consultar um agente implantado no Databricks.
Gerar tokens OAuth usando a CLI do Databricks:
databricks auth login --host <https://host.databricks.com>
databricks auth token
Use o token para consultar o agente:
curl -X POST <app-url.databricksapps.com>/responses \
-H "Authorization: Bearer <oauth token>" \
-H "Content-Type: application/json" \
-d '{ "input": [{ "role": "user", "content": "hi" }], "stream": true }'
Compreender as assinaturas de modelo para garantir a compatibilidade com os recursos do Databricks
A Databricks usa Assinaturas de Modelo do MLflow para definir o esquema de entrada e saída dos agentes. Recursos do produto como o AI Playground assumem que seu agente tem uma das assinaturas de modelo suportadas.
Se você seguir a abordagem recomendada para a criação de agents usando a interface ResponsesAgent, o MLflow inferirá automaticamente uma assinatura para seu agent que é compatível com os recursos do produto Databricks.
Limitações
- Somente tamanhos de compute médios e grandes têm suporte. Consulte Configurar recursos de compute para um aplicativo Databricks.
- A IU de chat do aplicativo de avaliação do MLflow atualmente não oferece suporte a agentes implantados em Databricks Apps. Para avaliar rastreamentos existentes, utilize sessões de rótulo, que funcionam independentemente do método de implantação. A Databricks está integrando o suporte a revisão e feedback diretamente no padrão de chatbot.
Próximos os passos
Depois que seu agente funcionar em desenvolvimento, leve-o para produção. Consulte Coloque o seu agente do Databricks Apps em produção para a sequência recomendada: CI/CD, teste de carga e, em seguida, Unity AI Gateway.