Como a Databricks oferece suporte a CI/CD para aprendizado de máquina?
CI/CD (integração contínua (CI) e entrega contínua (CD)) refere-se a um processo automatizado de desenvolvimento, implantação, monitoramento e manutenção de seus aplicativos. Ao automatizar a criação, o teste e a implantação do código, as equipes de desenvolvimento podem entregar versões com mais frequência e confiabilidade do que os processos manuais ainda predominantes em muitas equipes de engenharia de dados e ciência de dados. A CI/CD para aprendizado de máquina reúne técnicas de MLOps, DataOps, ModelOps e DevOps.
Este artigo descreve como o site Databricks oferece suporte ao CI/CD para soluções de aprendizado de máquina. Nos aplicativos de aprendizado de máquina, o CI/CD é importante não apenas para o código ativo, mas também é aplicado ao pipeline de dados, incluindo os dados de entrada e os resultados gerados pelo modelo.
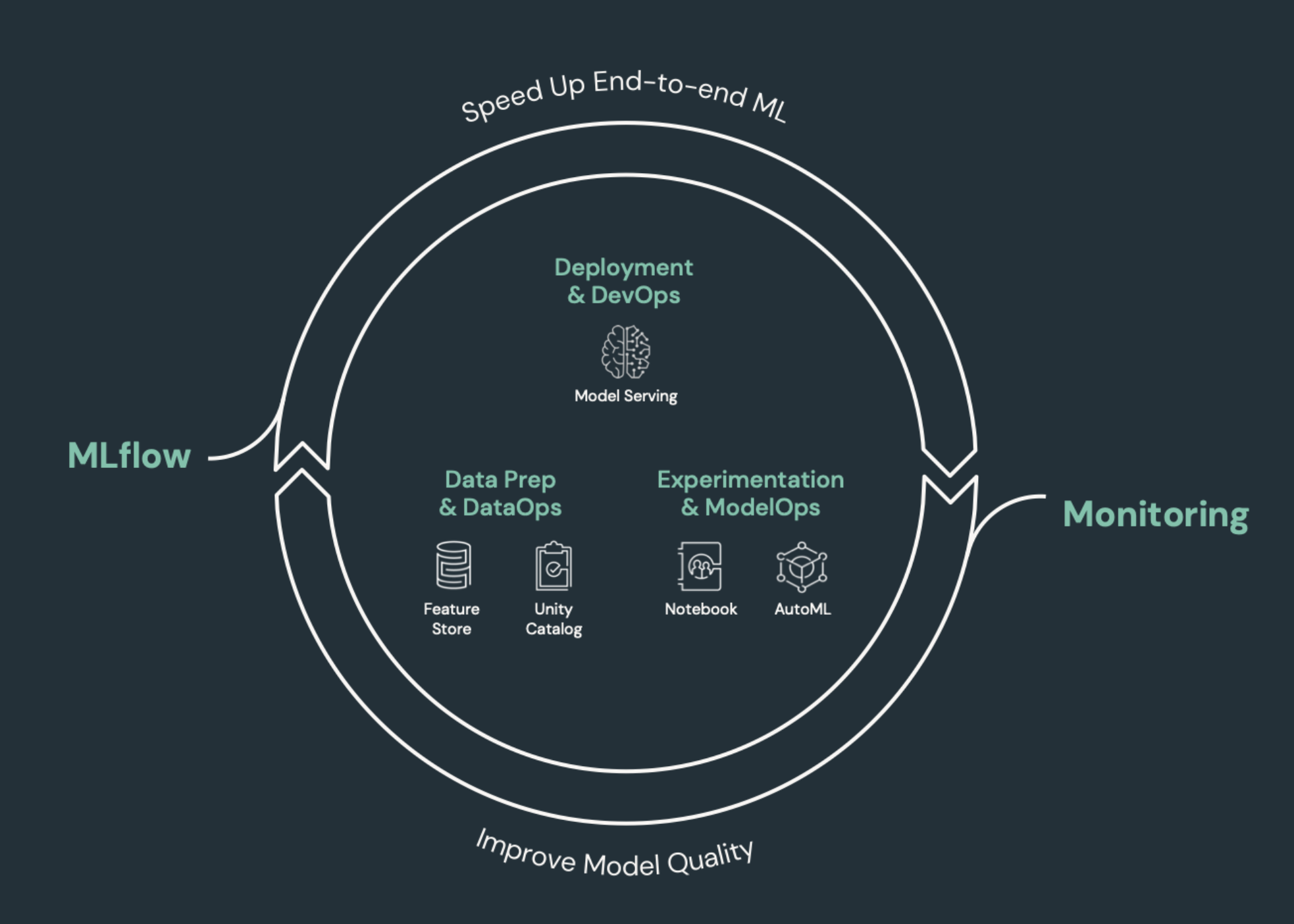
Elementos de aprendizado de máquina que precisam de CI/CD
Um dos desafios do desenvolvimento de ML é que diferentes equipes possuem diferentes partes do processo. As equipes podem confiar em diferentes ferramentas e ter diferentes programas de lançamento. Databricks fornece uma plataforma única e unificada de dados e ML com ferramentas integradas para melhorar a eficiência das equipes e garantir a consistência e a repetibilidade dos dados e do pipeline ML.
Em geral, para a tarefa de aprendizado de máquina, os seguintes itens devem ser monitorados em um CI/CD fluxo de trabalho automatizado:
- Dados de treinamento, incluindo qualidade de dados, alterações de esquema e alterações de distribuição.
- Pipeline de entrada de dados.
- Código para treinamento, validação e utilização do modelo.
- Previsões e desempenho do modelo.
Integrar a Databricks em seus processos de CI/CD
MLOps, DataOps, ModelOps e DevOps referem-se à integração dos processos de desenvolvimento com as "operações", tornando os processos e a infraestrutura previsíveis e confiáveis. Este conjunto de artigos descreve como integrar os princípios de operações ("ops") em seu fluxo de trabalho ML na plataforma Databricks.
Databricks incorpora todos os componentes necessários para o ciclo de vida do ML, incluindo ferramentas para criar "configuração como código" para garantir a reprodutibilidade e "infraestrutura como código" para automatizar o provisionamento do serviço de nuvem. Ele também inclui serviços de registro e alerta para ajudá-lo a detectar e solucionar problemas quando eles ocorrerem.
DataOps: dados confiáveis e seguros
Os bons modelos do site ML dependem de um pipeline de dados e de uma infraestrutura confiáveis. Com a Databricks Data Intelligence Platform, todo o pipeline de dados, desde a ingestão de dados até as saídas do modelo servido, está em uma única plataforma e usa o mesmo conjunto de ferramentas, o que facilita a produtividade, a reprodutibilidade, o compartilhamento e a solução de problemas.

Tarefa e ferramentas de DataOps em Databricks
A tabela lista as tarefas e ferramentas comuns do DataOps em Databricks:
Tarefa de DataOps | Ferramenta na Databricks |
|---|---|
Ingestão e transformação de dados | Auto Loader e Apache Spark |
Acompanhe as alterações nos dados, incluindo controle de versão e linhagem | |
Criar, gerenciar e monitorar o pipeline de processamento de dados | |
Garanta a segurança e a governança dos dados | |
Análise exploratória de dados e dashboards | |
Codificação geral | |
programar pipeline de dados | |
Automatizar o fluxo geral de trabalho | |
Criar, armazenar, gerenciar e descobrir recursos para o treinamento de modelos | |
Monitoramento de dados |
ModelOps: desenvolvimento de modelos e ciclo de vida
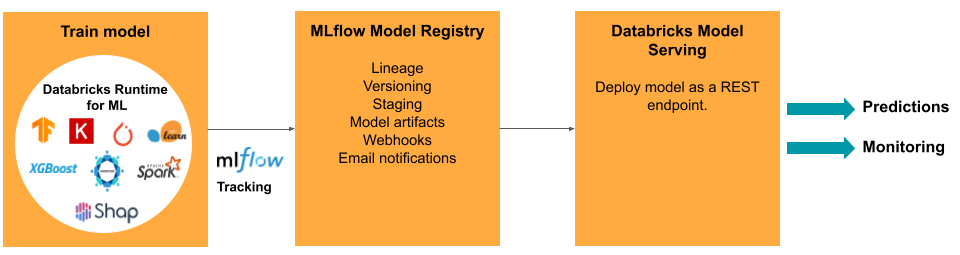
O desenvolvimento de um modelo requer uma série de experimentos e uma forma de rastrear e comparar as condições e os resultados desses experimentos. O Databricks Data Intelligence Platform inclui o MLflow para acompanhamento do desenvolvimento do modelo e o MLflow Model Registry para gerenciar o ciclo de vida do modelo, incluindo a preparação, o fornecimento e o armazenamento de artefatos do modelo.
Depois que um modelo é liberado para produção, muitas coisas podem mudar e afetar seu desempenho. Além de monitorar o desempenho da previsão do modelo, o senhor também deve monitorar os dados de entrada quanto a alterações na qualidade ou nas características estatísticas que possam exigir o retreinamento do modelo.
Tarefa e ferramentas do ModelOps em Databricks
A tabela lista as tarefas e ferramentas comuns do ModelOps fornecidas pelo site Databricks:
Tarefa de ModelOps | Ferramenta na Databricks |
|---|---|
Acompanhar o desenvolvimento do modelo | |
gerenciar o ciclo de vida do modelo | |
Controle e compartilhamento da versão do código do modelo | |
Desenvolvimento de modelo sem código | |
Monitoramento de modelos |
DevOps: produção e automação
A plataforma Databricks oferece suporte a modelos de ML em produção com o seguinte:
- Linhagem de dados e modelos de ponta a ponta: Desde os modelos em produção até a fonte de dados bruta, na mesma plataforma.
- Modelo de serviço em nível de produção: Aumente ou diminua automaticamente com base em suas necessidades comerciais.
- Empregos: Automatiza o trabalho e cria um fluxo de trabalho programado de aprendizado de máquina.
- Git pastas: O controle de versão do código e o compartilhamento do workspace também ajudam as equipes a seguir as práticas recomendadas de engenharia do software.
- Databricks ativo Bundles: Automatiza a criação e a implementação do recurso Databricks, como Job, modelos registrados e endpoint de serviço.
- Databricks Terraform provedor: Automatiza a infraestrutura de implementação entre nuvens para o trabalho de inferência ML, atendendo ao endpoint e ao trabalho de caracterização.
servindo modelo
Para modelos implantados em produção, o MLflow simplifica significativamente o processo, oferecendo uma implantação com um único clique como um trabalho em lote para grandes quantidades de dados ou como um REST endpoint em um clustering de escala automática. A integração do Databricks recurso Store com o MLflow também garante a consistência do recurso para treinamento e veiculação; além disso, os modelos do MLflow podem procurar automaticamente o recurso no recurso Store, mesmo para veiculação on-line de baixa latência.
A plataforma Databricks oferece suporte a muitas opções de implantação de modelos:
- Código e contêineres.
- lotes servindo.
- Serviço on-line de baixa latência.
- Servindo no dispositivo ou na borda.
- O Multi-cloud, por exemplo, treina o modelo em uma nuvem e o implanta em outra.
Para obter mais informações, consulte Mosaic AI Model Serving.
Empregos
LakeFlow Os trabalhos permitem que o senhor automatize e programe qualquer tipo de carga de trabalho,ETL de ML a. Databricks também oferece suporte a integrações com orquestradores populares de Airflow terceiros, como.
Pastas do Git
A plataforma Databricks inclui suporte Git no workspace para ajudar as equipes a seguir as práticas recomendadas de engenharia software realizando Git operações por meio da interface do usuário. Os administradores e engenheiros de DevOps podem usar APIs para configurar a automação com suas ferramentas de CI/CD favoritas. A Databricks é compatível com qualquer tipo de implementação de Git, inclusive redes privadas.
Para obter mais informações sobre as práticas recomendadas para o desenvolvimento de código usando as pastas Databricks Git , consulte CI/CD fluxo de trabalho com a integração Git e as pastas Databricks Git e Use CI/CD. Essas técnicas, juntamente com o Databricks REST API, permitem que o senhor crie processos de implantação automatizados com GitHub Actions, Azure DevOps pipeline ou Jenkins Job.
Unity Catalog para governança e segurança
A plataforma Databricks inclui Unity Catalogque permite que os administradores configurem controle de acesso refinado, políticas de segurança e governança para todos os dados e AI ativo em Databricks.