Debug model serving timeouts
This article describes the different timeouts you might encounter when using model serving endpoints and how to handle them. It covers model deployment timeouts, server-side timeouts, and client-side timeouts.
Model deployment timeouts
When you deploy a model or update an existing deployment using Model Serving, the process might time out for a number of reasons. The Events tab of the model serving endpoint page records timeout messages. Search on "timed out" to find them.
The deployment process times out if the container build and model deployment exceed a certain duration that is dependent on the endpoint workload configuration. Check your configuration before deploying and compare it to previous successful deployments.
The container build has no hard limit, but retries up to 3 times. The deployment after the container is built will wait up to 30 minutes for CPU workloads, 60 minutes for GPU small or medium workloads, and 120 minutes for GPU large workloads before timing out.
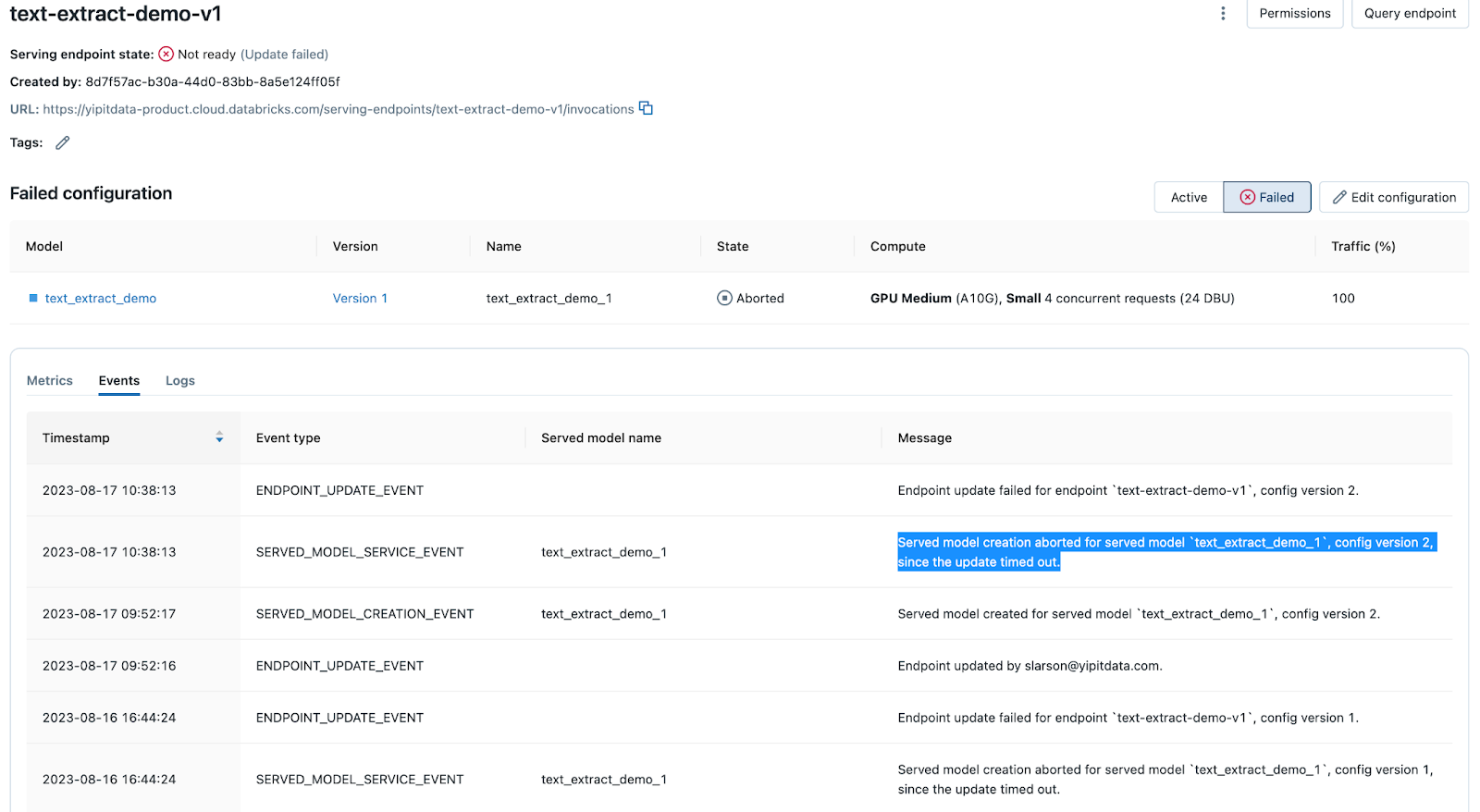
If you find a "timed out" message, navigate to the Logs tab and examine the build logs to determine the cause. Examples include library dependency issues, resource constraints, configuration issues and so on.
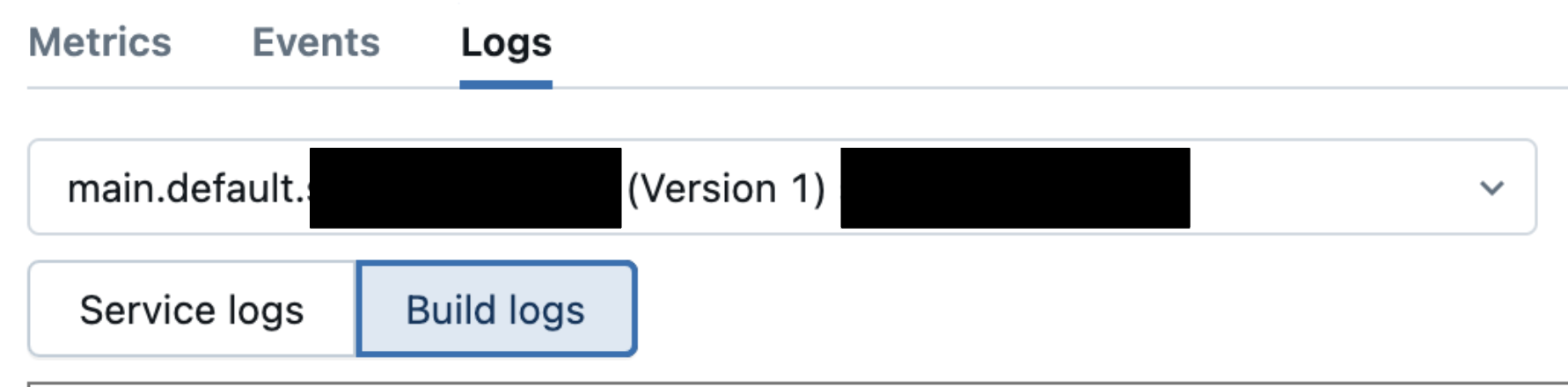
See Debug after container build failure.
Server-side timeouts
If your endpoint is healthy according to the Events and Logs tabs of your serving endpoint, but you experience timeouts when you make calls to the endpoint, the timeout might be on the server-side. The default timeout varies depending on the type of model serving endpoint. The following table shows the default server-side timeouts for requests sent to model serving endpoints.
Endpoint type | Request timeout limit (seconds) | Notes |
|---|---|---|
CPU or GPU serving endpoints | Default 597 | This limit cannot be increased. |
Foundation model serving endpoints | Default 597 | This limit cannot be increased. |
To determine if you experienced a server-side timeout, see if your requests are timing out before or after the limits listed above.
- If your request consistently fails at the limit, then it's likely a server-side timeout.
- If your request fails earlier than the limit, it might be due to configuration issues.
- Check the service logs to determine if there are any other errors.
- Confirm that the model has worked locally, like from a notebook, or on previous requests on earlier versions.
Client-side timeouts: MLflow configuration
Client-side timeouts typically return error messages that say "timed out" or 4xx Bad Request. Common causes of these timeouts are from MLflow environment variables configurations. The following are the most common MLflow environment variables for timeouts. For the full list of timeout variables, see the mlflow.environment_variables documentation.
- MLFLOW_HTTP_REQUEST_TIMEOUT: Specifies the timeout in seconds for MLflow HTTP requests. Default timeout 120 seconds.
- MLFLOW_HTTP_REQUEST_MAX_RETRIES: Specifies the maximum number of retries with exponential backoff for MLflow HTTP requests. Default is 7 seconds.
The HTTP request timeouts on the client-side are set to 120 seconds, which differs from the server-side's default timeout of 597 seconds for CPU and GPU serving endpoints. Adjust the MLflow environment variables accordingly if you expect your workload to exceed the 120-second client side timeout.
Do either of the following to determine if a timeout is caused by an MLflow environment variable configuration:
- Test the model locally using sample inputs, like in a notebook, to confirm that it works as expected before you register the model and deploy it.
- Examine the time it takes to process the requests.
- If requests take longer than the default timeouts for MLflow environment variables or you get a "timed out" message in the notebook. Example "timed out" message:
Timed out while evaluating the model. Verify that the model evaluates within the timeout.
- Examine the time it takes to process the requests.
- Test the model serving endpoint using POST requests.
- Check the Service Logs for your endpoint or the inference tables if you enabled them.
- For inference table schema details, see Unity AI Gateway-enabled inference table schema.
- Check the Service Logs for your endpoint or the inference tables if you enabled them.
Configure MLflow environment variables
Configure MLflow environment variables using the Serving UI or programmatically using Python.
- Serving UI
- Python
You can configure environment variables for a model deployment
- Select the endpoint that you want to configure an environment variable for.
- On the endpoint's page, select Edit on the top right.
- In "Entity Details", expand Advanced configuration to add the relevant MLflow timeout environment variable.
You can programmatically set up a model serving endpoint and include adjusted MLflow environment variables using Python. The following example adjusts the maximum timeout to 300 seconds and the maximum number of retries to three.
For further details about the payload to set this up, see the Databricks API page.
import mlflow.deployments
# Get the deployment client
client = mlflow.deployments.get_deploy_client("databricks")
# Define the configuration with environment variables
config = {
"served_entities": [
{
"name": "sklearn_example-1",
"entity_name": "catalog.schema.model_name",
"entity_version": "1",
"workload_size": "Small",
"workload_type": "CPU",
"scale_to_zero_enabled": True,
"environment_vars": {
"MLFLOW_HTTP_REQUEST_MAX_RETRIES": 3,
"MLFLOW_HTTP_REQUEST_TIMEOUT": 300
}
},
],
"traffic_config": {
"routes": [
{
"served_model_name": "model_name-1",
"traffic_percentage": 100
}
]
}
}
# Create the endpoint with the specified configuration
endpoint = client.create_endpoint(
name="model_name-1",
config=config
)
Client-side timeouts: Third party client APIs
Client-side timeouts typically return error messages that say "timed out" or 4xx Bad Request. Similar to MLflow configurations, third party client APIs can cause client-side timeouts depending on their configuration. These can impact model serving endpoints that consist of pipelines that use these third party client APIs. See custom PyFunc models and PyFunc custom schema agents.
Similar to the MLflow configuration debugging instructions, do the following to determine if a timeout is caused by 3rd-party client APIs used in your model pipeline:
- Test the model locally with sample inputs in a notebook.
- If you see a "timed out" message in the notebook, adjust any relevant parameters for the third party client's timeout window.
- Example "timed out" message:
APITimeoutError: Request timed out.
- Test the model serving endpoint using POST requests.
- Check the Service Logs for your endpoint or the inference tables if you enabled them.
- For inference table schema details, see Unity AI Gateway-enabled inference table schema.
- Check the Service Logs for your endpoint or the inference tables if you enabled them.
OpenAI client example
When you establish an OpenAI client, you can configure the timeout parameter to change the maximum time before a request times out on the client-side. The default and maximum timeout for an OpenAI client is 10 minutes.
The following example highlights how to configure a 3rd-party client APIs timeout.
%pip install openai==1.54.0
dbutils.library.restartPython()
from openai import OpenAI
import os
# How to get your Databricks token: https://docs.databricks.com/en/dev-tools/auth/pat.html
DATABRICKS_TOKEN = os.environ.get('DATABRICKS_TOKEN')
client = OpenAI(
timeout=10, # Number of seconds before client times out
api_key=DATABRICKS_TOKEN,
base_url="<WORKSPACE_URL>/serving-endpoints"
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are an AI assistant"
},
{
"role": "user",
"content": "Tell me about Large Language Models."
}
],
model="model_name",
max_tokens=256
)
For the OpenAI client, you can get around the maximum timeout window by enabling streaming.
Other timeouts
Idle endpoints warming up
If an endpoint is scaled to 0 and it receives a request that warms it up, it could potentially lead to a client-side timeout if it takes too long to warm up. This can be a cause of timeouts in pipelines that leverage steps like calls to provisioned throughput endpoints or AI Search indices, as mentioned above.
Connection timeout
Connection timeouts are related to the time a client waits to establish a connection with the server. If the connection is not established within this time, the client cancels the attempt. It's important to be aware of the clients used in your model pipeline and check the service logs and inference tables of the Model Serving endpoint for any connection timeouts. The messaging varies by service.
- For example, a SocketTimeout (for a service reading/writing to a SQL endpoint over a JDBC connection) may look like the following:
jdbc:spark://<server-hostname>:443;HttpPath=<http-path>;TransportMode=http;SSL=1[;property=value[;property=value]];SocketTimeout=300
- To find these, look for error messages containing the term "timed out" or "timeout".
Rate limits
Multiple requests made over the rate limit of an endpoint might lead to failure for additional requests. See Resource and payload limits for rate limits based on endpoint types. For third party clients, Databricks recommends that you review the documentation of the third party client you are using.