モデルサービングタイムアウトのデバッグ
この記事では、モデルサービングエンドポイントの使用時に発生する可能性のあるさまざまなタイムアウトとその処理方法について説明します。 モデル・デプロイメントのタイムアウト、サーバー・サイド・タイムアウト、およびクライアント・サイド・タイムアウトについて説明します。
モデル・デプロイメントのタイムアウト
モデルサービングを使用してモデルをデプロイしたり、既存のデプロイメントを更新したりする際に、いくつかの理由で処理がタイムアウトする場合があります。モデルサービング エンドポイント ページの [イベント] タブには、タイムアウト メッセージが記録されます。 それらを見つけるには、 「タイムアウト」 で検索してください。
コンテナのビルドとモデルのデプロイが、エンドポイントのワークロード設定に依存する特定の期間を超えると、デプロイプロセスはタイムアウトします。デプロイする前に構成を確認し、以前に成功したデプロイと比較します。
コンテナビルドにはハード制限はありませんが、最大3回再試行できます。コンテナーがビルドされた後のデプロイでは、CPU ワークロードの場合は最大 30 分、GPU 小規模または中規模のワークロードの場合は最大 60 分、GPU 大規模ワークロードの場合は 120 分待機してからタイムアウトします。
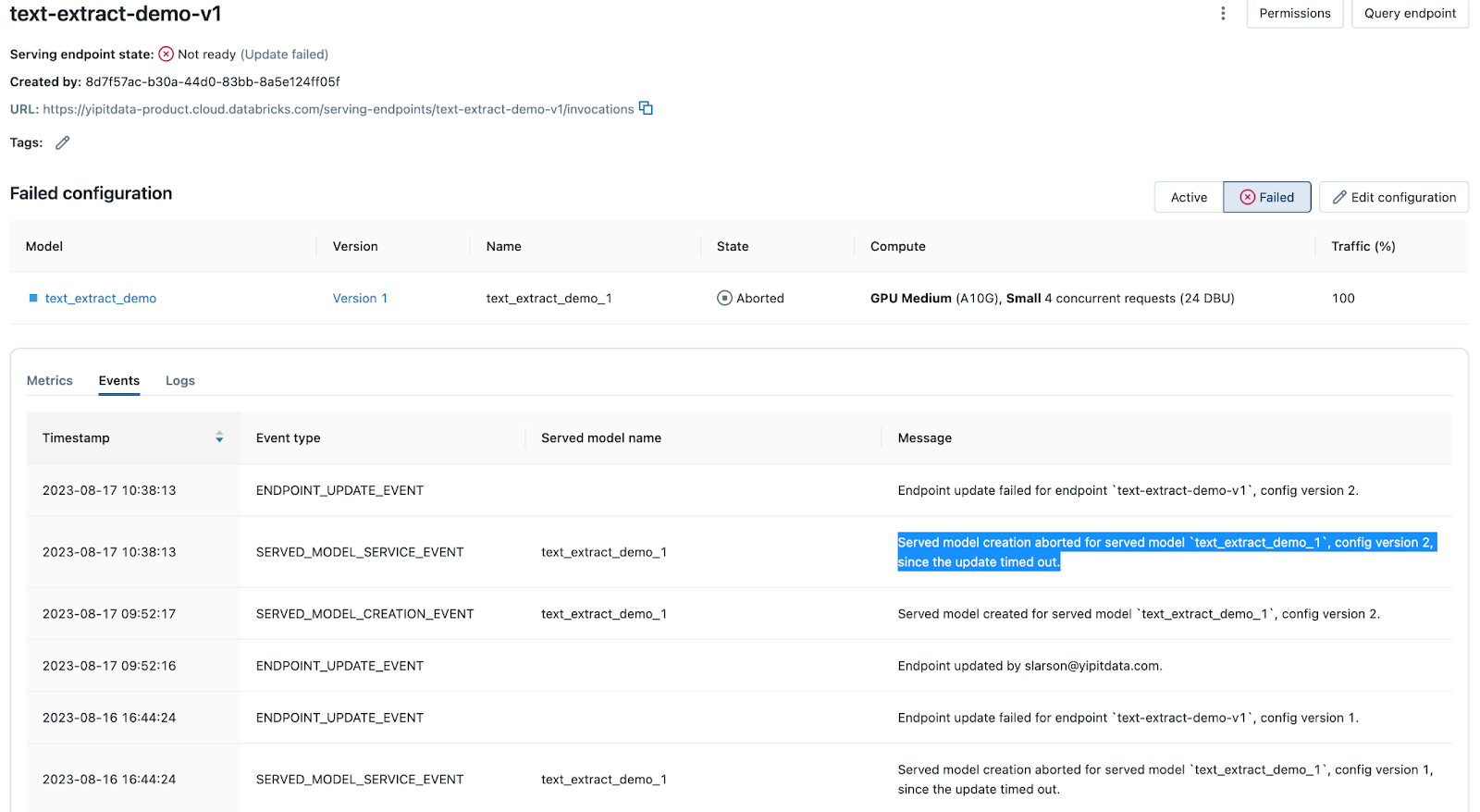
「タイムアウト」 メッセージが表示された場合は、[ ログ] タブに移動し、ビルド ログを調べて原因を特定します。例としては、ライブラリの依存関係の問題、リソースの制約、構成の問題などがあります。
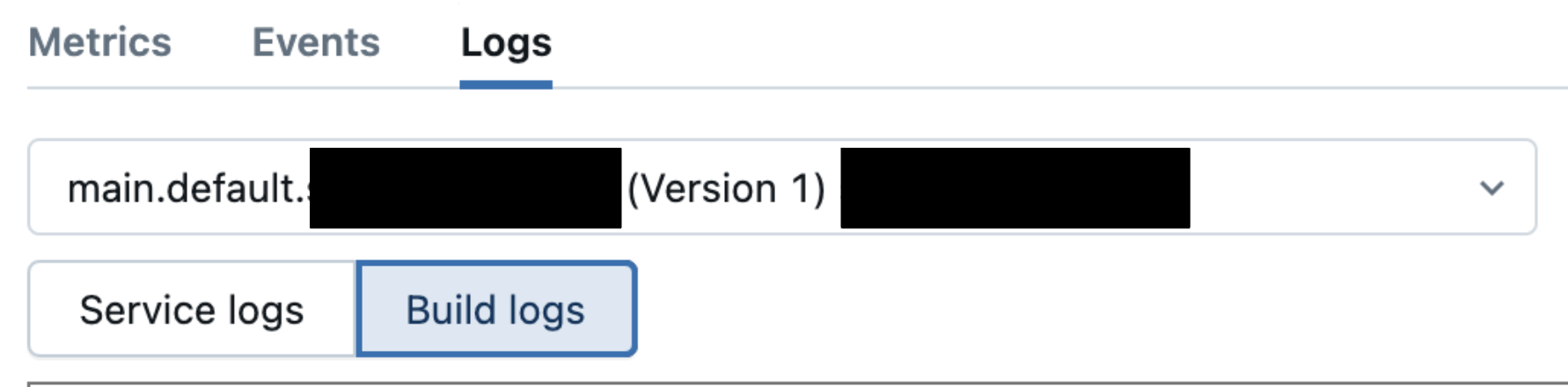
コンテナビルド失敗後のデバッグを参照してください。
サーバー側のタイムアウト
サービスエンドポイントの イベント タブと ログ タブに従ってエンドポイントが正常であるにもかかわらず、エンドポイントを呼び出すときにタイムアウトが発生する場合は、タイムアウトがサーバー側にある可能性があります。デフォルトタイムアウトは、モデルサービングエンドポイントのタイプによって異なります。 次の表は、モデルサービングエンドポイントに送信されたリクエストのデフォルトサーバー側タイムアウトを示しています。
エンドポイントの種類 | 要求タイムアウト制限 (秒) | 注 |
|---|---|---|
CPU または GPU サービング エンドポイント | デフォルト 597 | この制限を増やすことはできません。 |
エンドポイントを提供する基盤モデル | デフォルト 597 | この制限を増やすことはできません。 |
サーバー側のタイムアウトが発生したかどうかを判断するには、リクエストが上記の制限の前または後にタイムアウトしているかどうかを確認します。
- リクエストが制限で一貫して失敗する場合は、サーバー側のタイムアウトである可能性があります。
- 要求が制限より早く失敗した場合は、構成の問題が原因である可能性があります。
- サービスログを確認して、他のエラーがないかどうかを確認します。
- モデルがローカルで動作したこと (ノートブックなど) や、以前のバージョンの以前の要求で動作したことを確認できます。
クライアント側のタイムアウト: MLflow の構成
クライアント側のタイムアウトは、通常 、 timed out または 4xx Bad Request というエラーメッセージを返します。これらのタイムアウトの一般的な原因は、MLflow 環境変数の構成によるものです。タイムアウトの最も一般的な MLflow 環境変数を次に示します。タイムアウト変数の完全なリストについては、 mlflow.environment_variables のドキュメントを参照してください。
- MLFLOW_HTTP_REQUEST_TIMEOUT : MLflow HTTP 要求のタイムアウトを秒単位で指定します。デフォルトのタイムアウトは 120 秒です。
- MLFLOW_HTTP_REQUEST_MAX_RETRIES : MLflow HTTP 要求のエクスポネンシャル バックオフを使用した再試行の最大数を指定します。デフォルトは 7 秒です。
クライアント側のHTTPリクエストのタイムアウトは120秒に設定されていますが、これはCPUおよびGPUサービスエンドポイントにおけるサーバー側のデフォルトタイムアウトである597秒とは異なります。ワークロードが120秒のクライアント側タイムアウトを超えることが予想される場合は、MLflowの環境変数を適切に調整してください。
次のいずれかの操作を行って、タイムアウトが MLflow 環境変数の構成によって引き起こされているかどうかを判断します。
-
ノートブックなどのサンプル入力を使用してモデルをローカルでテストし、モデルが期待どおりに動作することを確認してから、モデルを登録してデプロイします。
- 要求の処理にかかる時間を調べます。
- リクエストが MLflow 環境変数のデフォルト タイムアウトよりも長い場合、またはノートブックに "timed out" メッセージが表示される場合。 timed out メッセージの例:
Timed out while evaluating the model. Verify that the model evaluates within the timeout.
- 要求の処理にかかる時間を調べます。
-
POST 要求を使用してモデルサービング エンドポイントをテストします。
- エンドポイントの サービス ログ または推論テーブルを有効にしている場合は、それらを確認します。
- 推論テーブルスキーマの詳細については、 「Unity AI Gateway 対応の推論テーブルスキーマ」を参照してください。
- エンドポイントの サービス ログ または推論テーブルを有効にしている場合は、それらを確認します。
MLflow 環境変数を構成する
MLflow 環境変数は、Serving UI を使用するか、Python を使用してプログラムで構成します。
- Serving UI
- Python
モデル・デプロイメントの環境変数を構成できます
- 環境変数を設定するエンドポイントを選択します。
- エンドポイントのページで、右上の [編集 ] を選択します。
- [エンティティの詳細] で、[ 詳細設定 ] を展開して、関連する MLflow タイムアウト環境変数を追加します。
プレーンテキスト環境変数の追加を参照してください。
モデルサービング エンドポイントをプログラムで設定し、 を使用して調整されたMLflow 環境変数を含めることができます。Python次の例では、最大タイムアウトを 300 秒に、最大再試行回数を 3 回に調整します。
これを設定するためのペイロードの詳細については、 Databricks API ページを参照してください。
import mlflow.deployments
# Get the deployment client
client = mlflow.deployments.get_deploy_client("databricks")
# Define the configuration with environment variables
config = {
"served_entities": [
{
"name": "sklearn_example-1",
"entity_name": "catalog.schema.model_name",
"entity_version": "1",
"workload_size": "Small",
"workload_type": "CPU",
"scale_to_zero_enabled": True,
"environment_vars": {
"MLFLOW_HTTP_REQUEST_MAX_RETRIES": 3,
"MLFLOW_HTTP_REQUEST_TIMEOUT": 300
}
},
],
"traffic_config": {
"routes": [
{
"served_model_name": "model_name-1",
"traffic_percentage": 100
}
]
}
}
# Create the endpoint with the specified configuration
endpoint = client.create_endpoint(
name="model_name-1",
config=config
)
クライアント側のタイムアウト: サード パーティのクライアントAPI
クライアント側のタイムアウトは、通常、 timed out または 4xx Bad Request というエラーメッセージを返します。MLflow 構成と同様に、サード パーティのクライアント APIは、構成によってはクライアント側のタイムアウトを引き起こす可能性があります。これらは、これらのサードパーティ クライアントAPIを使用するパイプラインで構成されるモデル サービング エンドポイントに影響を与える可能性があります。 カスタム PyFunc モデルと PyFunc カスタムスキーマエージェントを参照してください。
MLflow 構成のデバッグ手順と同様に、次の操作を実行して、タイムアウトの原因がモデル パイプラインで使用されている 3rd-party クライアント APIであるかどうかを判断します。
-
ノートブックのサンプル入力を使用してモデルをローカルでテストします。
- ノートブックに "timed out" メッセージが表示された場合は、サードパーティ クライアントのタイムアウト ウィンドウに関連するパラメーターを調整します。
- timed out メッセージの例:
APITimeoutError: Request timed out.
-
POST 要求を使用してモデルサービング エンドポイントをテストします。
- エンドポイントの サービス ログ または推論テーブルを有効にしている場合は、それらを確認します。
- 推論テーブルスキーマの詳細については、 「Unity AI Gateway 対応の推論テーブルスキーマ」を参照してください。
- エンドポイントの サービス ログ または推論テーブルを有効にしている場合は、それらを確認します。
OpenAI クライアントの例
OpenAI クライアントを確立するときに、timeout パラメーターを構成して、クライアント側で要求がタイムアウトするまでの最大時間を変更できます。OpenAI クライアントのデフォルトのタイムアウトと最大タイムアウトは 10 分です。
次の例では、サードパーティ クライアント APIs タイムアウトを設定する方法を強調しています。
%pip install openai==1.54.0
dbutils.library.restartPython()
from openai import OpenAI
import os
# How to get your Databricks token: https://docs.databricks.com/en/dev-tools/auth/pat.html
DATABRICKS_TOKEN = os.environ.get('DATABRICKS_TOKEN')
client = OpenAI(
timeout=10, # Number of seconds before client times out
api_key=DATABRICKS_TOKEN,
base_url="<WORKSPACE_URL>/serving-endpoints"
)
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "You are an AI assistant"
},
{
"role": "user",
"content": "Tell me about Large Language Models."
}
],
model="model_name",
max_tokens=256
)
OpenAIクライアントの場合、 ストリーミングを有効にすることで最大タイムアウトウィンドウを回避できます。
その他のタイムアウト
アイドル状態のエンドポイントのウォーミングアップ
エンドポイントが0にスケールダウンされており、ウォームアップを必要とするリクエストを受信した場合、ウォームアップに時間がかかりすぎると、クライアント側のタイムアウトが発生する可能性があります。上記のとおり、プロビジョニング済みスループットエンドポイントやAI検索インデックスへの呼び出しのようなステップを活用するパイプラインでは、これがタイムアウトの原因となる可能性があります。
接続タイムアウト
接続タイムアウトは、クライアントがサーバーとの接続を確立するのを待機する時間に関連しています。この時間内に接続が確立されない場合、クライアントは試行をキャンセルします。モデル パイプラインで使用されるクライアントを認識し、モデル サービング エンドポイントのサービス ログと推論テーブルで接続タイムアウトを確認することが重要です。 メッセージングはサービスによって異なります。
-
たとえば、SocketTimeout (SQL 接続を介して エンドポイントに対して読み取り/書き込みを行うサービスの場合)JDBC は、次のようになります。
jdbc:spark://<server-hostname>:443;HttpPath=<http-path>;TransportMode=http;SSL=1[;property=value[;property=value]];SocketTimeout=300
-
これらを見つけるには、 timed out またはtimeoutという用語を含むエラーメッセージを探します。
レート制限
エンドポイントのレート制限を超えて複数のリクエストが行われると、追加のリクエストが失敗する可能性があります。エンドポイントタイプに基づくレート制限については 、リソースとペイロードの制限 を参照してください。サードパーティ クライアントの場合、Databricks では、使用しているサードパーティ クライアントのドキュメントを確認することをお勧めします。