コンピュート メトリクスの参照
この記事では、 Databricks UI でネイティブのコンピュート メトリクス ツールを使用して、主要なハードウェアと Spark メトリクスを収集する方法について説明します。 メトリクス UI は、汎用 とジョブ コンピュートで使用できます。
メトリクスはほぼリアルタイムで利用でき、通常の遅延は1分未満です。メトリクスは、顧客のストレージではなく、 Databricks管理ストレージに保存されます。
ノートブックとジョブにおけるサーバレスコンピュートは、メトリクス UI の代わりにクエリの知見を使用します。 サーバレス コンピュート メトリクスの詳細については、 クエリの知見の参照を参照してください。
コンピュート メトリクス UIへのアクセス
コンピュート メトリクス UI を表示するには:
- サイドバーの [ コンピュート ] をクリックします。
- メトリクスを表示するコンピュート リソースをクリックします。
- メトリクス タブをクリックします。
すべてのノードのハードウェア メトリクスが安全で表示されます。 Sparkメトリクスを表示するには、 「ハードウェア」 というラベルのドロップダウン メニューをクリックし、 Spark を選択します。 インスタンスが GPU 対応の場合は、 GPU を選択することもできます。
期間によるメトリクスのフィルタリング
過去のメトリクスを表示するには、日付ピッカーフィルターを使用して時間範囲を選択します。 メトリクスは毎分収集されるため、過去 30 日間の任意の日、時間、または分でフィルタリングできます。 カレンダーアイコンをクリックして定義済みのデータ範囲から選択するか、テキストボックス内をクリックしてカスタム値を定義します。
チャートに表示される時間間隔は、表示している時間の長さに基づいて調整されます。 ほとんどのメトリクスは、現在表示している時間間隔に基づく平均値です。
[ リフレッシュ ]ボタンをクリックして最新のメトリックを取得することもできます。
ノードレベルでのメトリクスの表示
無事、メトリクス ページには、クラスター内のすべてのノード (ドライバーを含む) の一定期間の平均メトリクスが表示されます。
[すべてのノード] ドロップダウン メニューをクリックし、メトリクスを表示するノードを選択すると、個々のノードのメトリクスを表示できます。 GPU メトリクスは、個々のノード レベルでのみ使用できます。 Spark個々のノードでは使用できません。
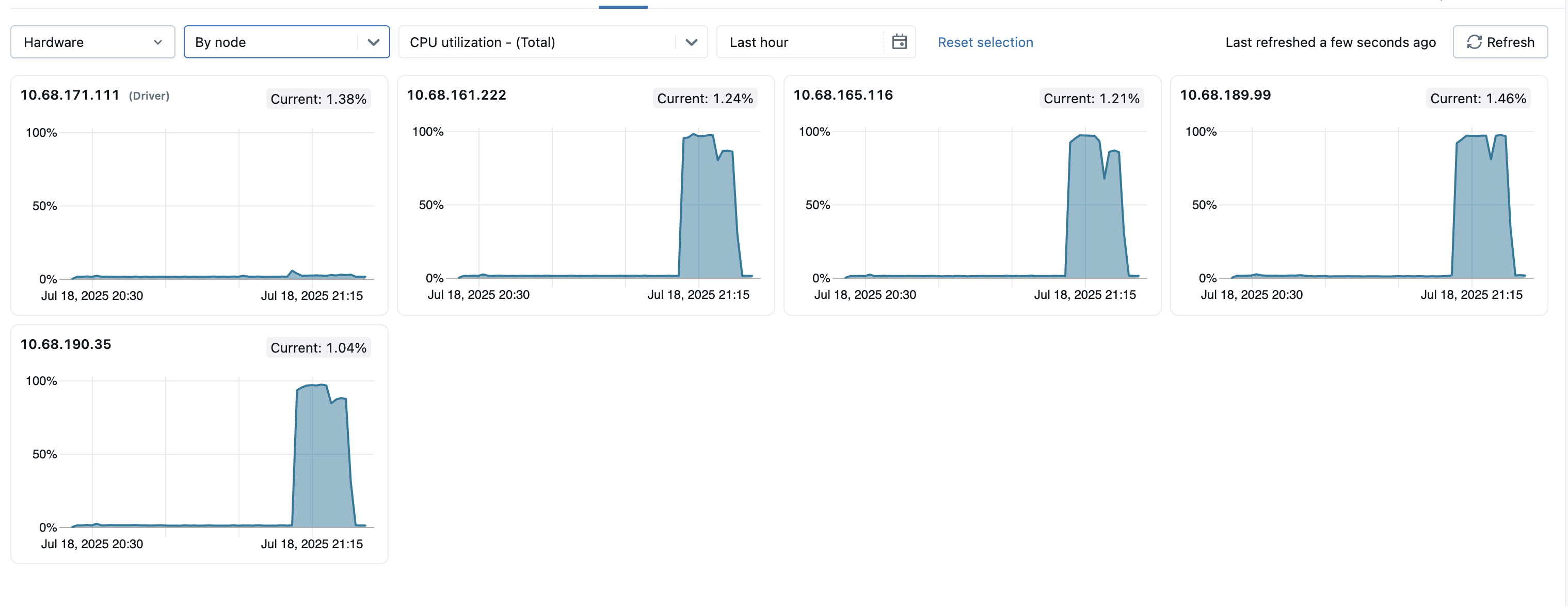
クラスター内の外れ値ノードを特定しやすくするために、すべての個々のノードのメトリクスを 1 つのページに表示することもできます。 このビューにアクセスするには、 [すべてのノード] ドロップダウン メニューをクリックし、 [ノード別] を選択してから、表示するメトリクス サブカテゴリを選択します。
Hardware メトリクス チャート
次のハードウェア メトリクス チャートは、コンピュート メトリクス UI で表示できます。
-
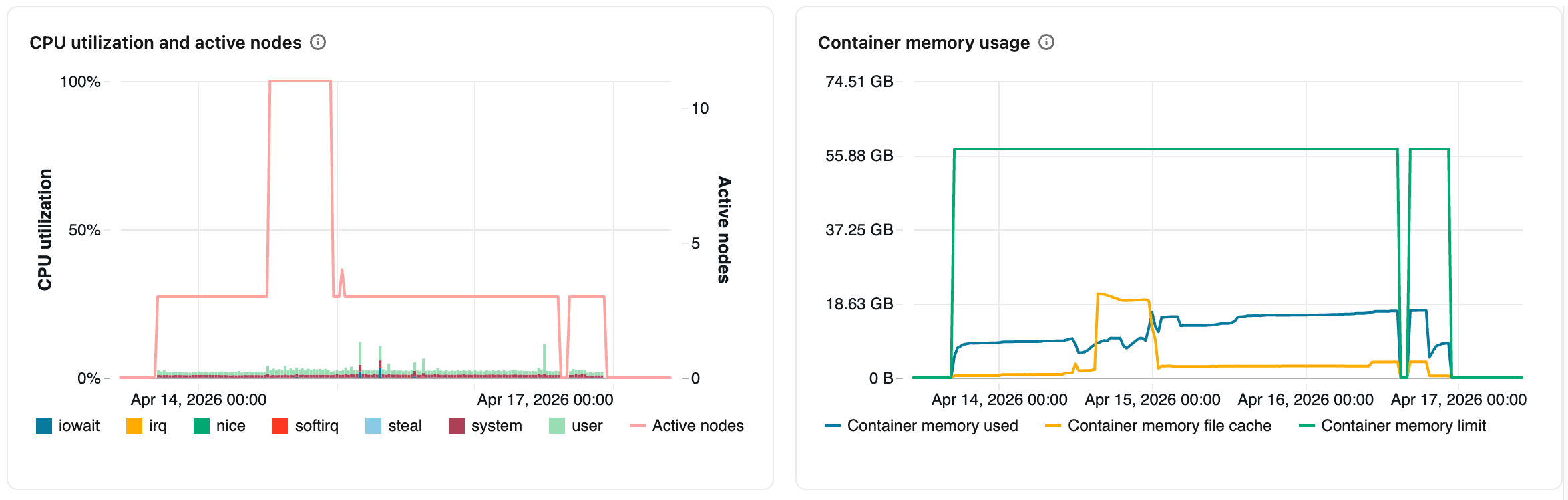
CPU使用率とアクティブノード :折れ線グラフは、指定されたコンピュートの各タイムスタンプにおけるアクティブノードの数を表示します。 棒グラフは、CPUが各モードで費やした時間の割合を、総CPU秒数に基づいて表示します。追跡対象となるモードは以下のとおりです。
guestVMを実行している場合、それらのVMが使用するCPUiowait: 入出力待ち時間idleCPUが何もすることがない時間irq割り込み要求に費やされた時間nice: ポジティブナイスネスを持つプロセスが使用する時間。つまり、他のタスクよりも優先度が低いプロセスが使用する時間。softirqソフトウェア割り込み要求に費やされた時間steal: あなたが仮想マシンである場合、他の仮想マシンがあなたのCPUから「奪った」時間system: カーネルで費やされた時間userユーザーランドで費やした時間
-
コンテナのメモリ使用量 :Sparkコンテナが消費するメモリ量を、該当するすべてのノードで平均したものです。再利用不可能なメモリ (
Container memory used)、OS ファイルページキャッシュ (Container memory file cache)、および構成済みメモリ制限 (Container memory limit) の平均値が含まれます。 -
JVMヒープ使用量 :すべての該当ノードにおけるJVMヒープメモリ使用量の平均値。実際のヒープ使用量、ヒープ容量、および設定された最大ヒープ制限の平均値が含まれます。
-
ネットワークの受信および送信 :各デバイスがネットワークを介して受信および送信したバイト数。
-
ファイルシステムの空き容量 :各マウントポイントによるファイルシステムの総使用量(バイト単位)。
ハードウェア タブの下部にある 「ノードのメモリ使用量」 をクリックすると、以下の追加グラフが表示されます。
- メモリ使用量とスワップ :折れ線グラフは、モード別のメモリ・スワップ使用量の合計をバイト単位で示しています。棒グラフは、モード別の総メモリ使用量をバイト単位で示しています。以下の利用形態が追跡されます。
used: 使用中の OS レベルの合計メモリ (コンピュートで実行されているバックグラウンド プロセスによって使用されるメモリを含む)。 ドライバーとバックグラウンドプロセスはメモリを使用するため、 Sparkが実行されていない場合でもメモリ使用量が表示されることがあります。 。other:used、buffer、または以外の目的で使用されているメモリcachedbuffer: カーネルバッファが使用するメモリcachedOSレベルでファイルシステムキャッシュが使用するメモリfree未使用メモリ。上記の表のいずれのカテゴリーにも該当しないものはすべて無料です。
Spark メトリクスチャート
次の Spark メトリクスチャートは、コンピュート メトリクス UI で表示できます。
- サーバー負荷分散 : これらのタイルには、コンピュート リソース内の各ノードの過去 1 分間の CPU 使用率が表示されます。 各タイルは、個々のノードのメトリクス ページへのクリック可能なリンクです。
- アクティブなタスク :任意の時点で実行されているタスクの総数。
- Total failed task : エグゼキューターで失敗したタスクの総数。
- 完了タスク総数 : エグゼキューター内で完了したタスクの総数。
- タスク総数 : エグゼキューター内の全タスク(実行中、失敗、完了)の総数です。
- 合計シャッフル読み取り :シャッフル読み取りデータの合計サイズ(バイト単位)。
Shuffle read、ステージの開始時にすべてのエグゼキューターでシリアル化された読み取りデータの合計を意味します。 - 合計シャッフル書き込み: シャッフル書き込みデータの合計サイズ(バイト単位)。
Shuffle Writeは、送信前(通常はステージの終わり)にすべてのエグゼキューターに書き込まれたすべてのシリアル化データの合計です。 - 合計タスク期間 : JVMエグゼキューター上でタスクの実行に費やした合計経過時間 (秒単位で測定)。
GPU メトリクス チャート
GPU メトリクスは、 Databricks Runtime ML 13.3 以降でのみ使用できます。
次の GPU メトリクス チャートは、コンピュート メトリクス UI で表示できます。
- サーバーの負荷分散 : このグラフには、各ノードの過去 1 分間の CPU 使用率が表示されます。
- GPUごとのデコーダー使用率:GPUデコーダーの使用率(パーセント )。
- GPUエンコーダー使用率:GPUエンコーダーの使用率(パーセント )。
- GPUごとのフレームバッファメモリ使用率(バイト) :フレームバッファメモリの使用率(バイト単位)。
- GPUごとのメモリ使用率:GPUメモリの使用率(パーセント )。
- GPUごとの利用率:GPUの利用率(パーセント )。
トラブルシューティング
ある期間に不完全または欠落しているメトリクスが表示される場合は、次のいずれかの問題である可能性があります。
- メトリクスのクエリと保存を担当する Databricks サービスの停止。
- 顧客側のネットワークの問題。
- コンピュートが異常な状態にあるか、または健康に問題があった。