エンドポイントを提供する基盤モデルの作成
この記事では、基盤モデルをデプロイして提供するモデルサービングエンドポイントを作成する方法について説明します。
モデルサービングは、以下のモデルをサポートしています。
-
外部モデル。これらは、Databricks の外部でホストされている基盤モデルです。外部モデルを提供するエンドポイントを一元管理し、顧客はレート制限とアクセス制御を確立できます。 例としては、OpenAIのGPT-4やAnthropicのClaudeなどの基盤モデルが含まれます。
-
基盤モデルAPIsによって利用可能な最先端のオープン基盤モデル。 これらのモデルは、最適化された推論をサポートするために厳選された基盤モデルアーキテクチャです。Meta-Llama-3.3-70B-Instruct のような基本モデルおよび GTE-Large は、 人権単位の従量課金 価格ですぐにご利用いただけます。 本番運用ワークロードは、ベースまたは微調整されたモデルを使用して、プロビジョニング スループット を使用してパフォーマンスを保証してデプロイできます。
モデルサービングには、モデルサービングエンドポイントの作成に次のオプションがあります。
- サービングUI
- REST API
- MLflow デプロイ SDK
従来の ML モデルまたは Python モデルを提供するエンドポイントを作成するには、「 カスタムモデルサービングエンドポイントを作成する」を参照してください。
必要条件
-
サポートされているリージョン内の Databricks ワークスペース。
-
MLflow Deployments SDK を使用してエンドポイントを作成するには、MLflow Deployments クライアントをインストールする必要があります。 インストールするには、次のコマンドを実行します。
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
基盤モデルの提供エンドポイントを作成する
プロビジョニング スループット の基盤モデルAPIを使用して利用可能になった、きめ細かいバリアントを提供するエンドポイントを作成できます。REST API を使用してプロビジョニングされたスループットエンドポイントを作成するを参照してください。
トークン 単位の従量課金 基盤モデルAPIを使用して利用可能になる基盤モデルの場合は、Databricks Databricksワークスペースでサポートされているモデルにアクセスするための特定のエンドポイントを自動的に提供します。それらにアクセスするには、ワークスペースの左側のサイドバーにある サービング タブを選択します。 基盤モデル API は、エンドポイント リスト ビューの上部にあります。
これらのエンドポイントのクエリについては、「 基盤モデルの使用」を参照してください。
外部モデルサービングエンドポイントの作成
次に、Databricks 外部モデルを使用して利用可能になった基盤モデルをクエリするエンドポイントを作成する方法について説明します。
- Serving UI
- REST API
- MLflow Deployments SDK
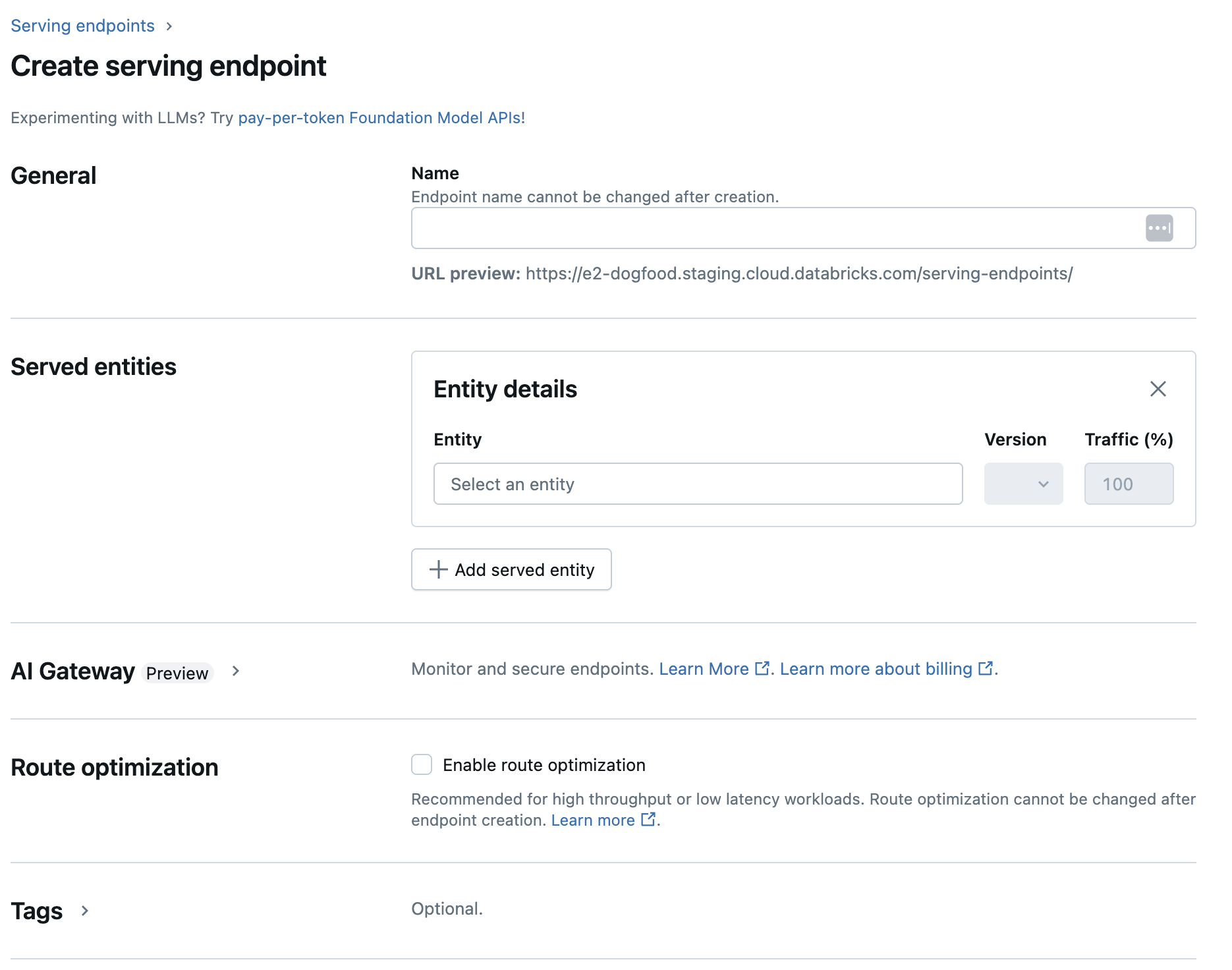
-
[ 名前 ] フィールドに、エンドポイントの名前を入力します。
-
[Served entities ] セクションで
- [エンティティ ] フィールドをクリックして、[ 提供済みエンティティの選択 ] フォームを開きます。
- [基盤モデル ] を選択します。
- [ 基盤モデルの選択 ] フィールドで、[ 外部モデル プロバイダー ] の下にリストされているものから、使用するモデル プロバイダーを選択します。 フォームは、モデル・プロバイダの選択に基づいて動的に更新されます。
- 確認 をクリックします。
- 選択したモデルプロバイダーにアクセスするための設定の詳細を指定します。これは通常、エンドポイントがこのモデルにアクセスするために使用する 個人用アクセス トークン を参照するシークレットです。
- タスクを選択します。使用可能なタスクは、チャット、完了、埋め込みです。
- 使用する外部モデルの名前を選択します。モデルのリストは、タスクの選択に基づいて動的に更新されます。使用可能な外部モデルを参照してください。
-
作成 をクリックします。[ エンドポイントの提供中 ] ページが表示され、 提供エンドポイントの状態 が [準備ができていません] と表示されます。
外部モデルを提供する配信エンドポイントを作成するための REST API パラメーターは 、パブリック プレビュー段階です。
次の例では、OpenAI によって提供される text-embedding-ada-002 モデルの最初のバージョンを提供するエンドポイントを作成します。
POST /api/2.0/serving-endpoints を参照してください。エンドポイント構成パラメーターの場合。
{
"name": "openai_endpoint",
"config":
{
"served_entities":
[
{
"name": "openai_embeddings",
"external_model":{
"name": "text-embedding-ada-002",
"provider": "openai",
"task": "llm/v1/embeddings",
"openai_config":{
"openai_api_key": "{{secrets/my_scope/my_openai_api_key}}"
}
}
}
]
},
"rate_limits": [
{
"calls": 100,
"key": "user",
"renewal_period": "minute"
}
],
"tags": [
{
"key": "team",
"value": "gen-ai"
}
]
}
応答の例を次に示します。
{
"name": "openai_endpoint",
"creator": "user@email.com",
"creation_timestamp": 1699617587000,
"last_updated_timestamp": 1699617587000,
"state": {
"ready": "READY"
},
"config": {
"served_entities": [
{
"name": "openai_embeddings",
"external_model": {
"provider": "openai",
"name": "text-embedding-ada-002",
"task": "llm/v1/embeddings",
"openai_config": {
"openai_api_key": "{{secrets/my_scope/my_openai_api_key}}"
}
},
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1699617587000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "openai_embeddings",
"traffic_percentage": 100
}
]
},
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "gen-ai"
}
],
"id": "69962db6b9db47c4a8a222d2ac79d7f8",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
次の例では、OpenAI text-embedding-ada-002を使用した埋め込み用のエンドポイントを作成します。
外部モデルエンドポイントの場合は、使用するモデルプロバイダーの API キーを指定する必要があります。要求と応答のスキーマの詳細については、REST API の POST /api/2.0/serving-endpoints を参照してください。ステップ バイ ステップ ガイドについては、「 チュートリアル: OpenAI モデルに対してクエリを実行するための外部モデル エンドポイントを作成する」を参照してください。
設定ファイルのexternal_modelセクションのtaskフィールドで指定されているように、完了処理やチャットタスクのエンドポイントを作成することもできます。各タスクのサポートされているモデルとプロバイダーについては、「モデルサービング」の「外部モデル」を参照してください。
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="chat",
config={
"served_entities": [
{
"name": "completions",
"external_model": {
"name": "gpt-4",
"provider": "openai",
"task": "llm/v1/chat",
"openai_config": {
"openai_api_key": "{{secrets/scope/key}}",
},
},
}
],
},
)
assert endpoint == {
"name": "chat",
"creator": "alice@company.com",
"creation_timestamp": 0,
"last_updated_timestamp": 0,
"state": {...},
"config": {...},
"tags": [...],
"id": "88fd3f75a0d24b0380ddc40484d7a31b",
}
モデルサービングエンドポイントの更新
モデルの端点を有効にした後、必要に応じてコンピュート構成を設定できます。 この構成は、モデルに追加のリソースが必要な場合に特に役立ちます。 ワークロードのサイズとコンピュートの設定は、モデルを提供するためにどのリソースが割り当てられるかにおいて重要な役割を果たします。
新しい設定の準備が整うまで、古い設定は予測トラフィックを提供し続けます。更新が進行中の間は、別の更新を行うことはできません。Serving UI では、エンドポイントの詳細ページの右上にある [Cancel update] (更新のキャンセル ) を選択することで、進行中の設定更新をキャンセルできます。この機能は、サービングUIでのみ使用できます。
エンドポイント設定に external_model が存在する場合、提供されるエンティティ リストには 1 つのserved_entity オブジェクトのみを含めることができます。 external_modelを持つ既存のエンドポイントを更新して、external_modelをなくすことはできません。エンドポイントが external_modelなしで作成されている場合、エンドポイントを更新して external_modelを追加することはできません。
- REST API
- MLflow Deployments SDK
エンドポイントを更新するには、要求と応答のスキーマの詳細については、REST API 更新設定のドキュメント を参照してください。
{
"name": "openai_endpoint",
"served_entities":
[
{
"name": "openai_chat",
"external_model":{
"name": "gpt-4",
"provider": "openai",
"task": "llm/v1/chat",
"openai_config":{
"openai_api_key": "{{secrets/my_scope/my_openai_api_key}}"
}
}
}
]
}
エンドポイントを更新するには、要求と応答のスキーマの詳細については、REST API 更新設定のドキュメント を参照してください。
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.update_endpoint_config(
endpoint="chat",
config={
"served_entities": [
{
"name": "chats",
"external_model": {
"name": "gpt-4",
"provider": "openai",
"task": "llm/v1/chat",
"openai_config": {
"openai_api_key": "{{secrets/scope/key}}",
},
},
}
],
},
)
assert endpoint == {
"name": "chats",
"creator": "alice@company.com",
"creation_timestamp": 0,
"last_updated_timestamp": 0,
"state": {...},
"config": {...},
"tags": [...],
"id": "88fd3f75a0d24b0380ddc40484d7a31b",
}
rate_limits = client.update_endpoint_rate_limits(
endpoint="chat",
config={
"rate_limits": [
{
"key": "user",
"renewal_period": "minute",
"calls": 10,
}
],
},
)
assert rate_limits == {
"rate_limits": [
{
"key": "user",
"renewal_period": "minute",
"calls": 10,
}
],
}