Connect to Azure Synapse Analytics dedicated pool
The legacy query federation documentation has been retired and might not be updated. The configurations mentioned in this content are not officially endorsed or tested by Databricks. If Lakehouse Federation supports your source database, Databricks recommends using that instead.
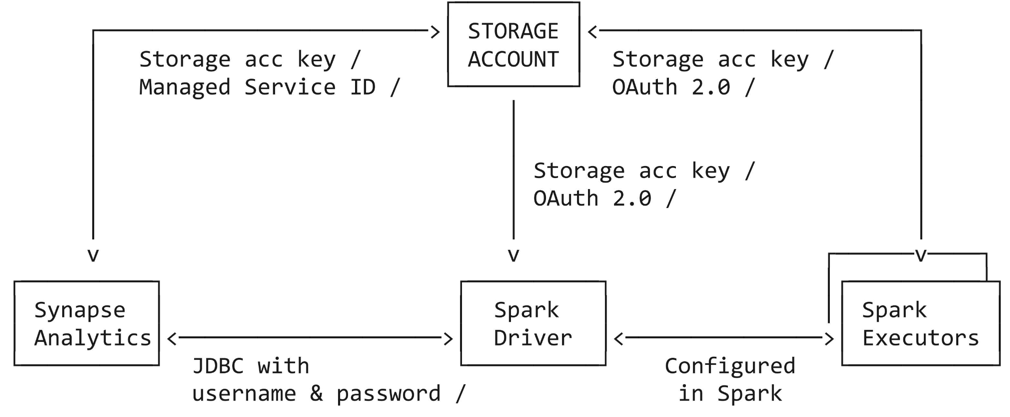
This tutorial guides you through all the steps necessary to connect from Azure Databricks to Azure Synapse Analytics dedicated pool using service principal, Azure Managed Service Identity (MSI) and SQL Authentication. The Azure Synapse connector uses three types of network connections:
- Spark driver to Azure Synapse
- Spark driver and executors to Azure storage account
- Azure Synapse to Azure storage account
Requirements
Complete these tasks before you begin the tutorial:
- Create an Azure Databricks workspace. See Create a classic workspace
- Create an Azure Synapse Analytics workspace. See Quickstart: Create a Synapse workspace
- Create a dedicated SQL pool. See Quickstart: Create a dedicated SQL pool using the Azure portal
- Create a staging Azure Data Lake Storage for the connection between Azure Databricks and Azure Synapse Analytics.
Connect to Azure Synapse Analytics using a service principal
The following steps in this tutorial show you how to connect to Azure Synapse Analytics using a service principal.
Step 1: Create a Microsoft Entra ID service principal for the Azure Data Lake Storage
To use service principals to connect to Azure Data Lake Gen2, an admin user must create a new Microsoft Entra ID (formerly known as Azure Active Directory) application. If you already have a Microsoft Entra ID service principal available, skip ahead to Step 3. To create a Microsoft Entra ID service principal, follow these instructions:
- Sign in to the Azure portal.
- If you have access to multiple tenants, subscriptions, or directories, click the Directories + subscriptions (directory with filter) icon in the top menu to switch to the directory in which you want to provision the service principal.
- Search for and select Microsoft Entra ID.
- In Manage, click App registrations > New registration.
- For Name, enter the name of the application.
- In the Supported account types section, select Accounts in this organizational directory only (Single tenant).
- Click Register.
(Optional) Step 2: Create a Microsoft Entra ID service principal for the Azure Synapse Analytics
You can optionally create a service principal dedicated to Azure Synapse Analytics by repeating the instructions in Step 1. If you do not create a separate set of service principal credentials, the connection will use the same service principal to connect to Azure Data Lake Gen2 and Azure Synapse Analytics.
Step 3: Create a client secret for your Azure Data Lake Gen2 (and Azure Synapse Analytics) service principals
- In Manage, click Certificates & secrets
- On the Client secrets tab, click New client secret.
- In the Add a client secret pane, for Description, enter a description for the client secret.
- For Expires, select an expiry time period for the client secret, and then click Add.
- Copy and store the client secret's Value in a secure place, as this client secret is the password for your application.
- On the application page's Overview page, in the Essentials section, copy the following values:
- Application (client) ID
- Directory (tenant) ID
If you created a set of service principal credentials for Azure Synapse Analytics, follow the steps again to create a client secret.
Step 4: Grant the service principal access to Azure Data Lake Storage
You grant access to storage resources by assigning roles to your service principal. In this tutorial, you assign the Storage Blob Data Contributor to the service principal(s) on your Azure Data Lake Storage account. You may need to assign other roles depending on specific requirements.
- In the Azure portal, go to the Storage accounts service.
- Select an Azure storage account to use.
- Click Access Control (IAM).
- Click + Add and select Add role assignment from the dropdown menu.
- Set the Select field to the Microsoft Entra ID application name that you created in step 1 and set Role to Storage Blob Data Contributor.
- Click Save.
If you created a set of service principal credentials for Azure Synapse Analytics, follow the steps again to grant access to the service principal on the Azure Data Lake Storage.
Step 5: Create a master key in Azure Synapse Analytics dedicated pool
Connect to the Azure Synapse Analytics dedicated pool and create a master key if you haven't before.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Password>'
Step 6: Grant permissions to the service principal in the Azure Synapse Analytics dedicated pool
Connect to the Azure Synapse Analytics dedicated pool and create an external user for the service principal that is going to connect to Azure Synapse Analytics:
CREATE USER <serviceprincipal> FROM EXTERNAL PROVIDER
The name of the service principal should match the one created on Step 2 (or Step 1 if you skipped creating a dedicated service principal for Azure Synapse Analytics).
Grant permissions to the service principal to be a db_owner by running the command below:
sp_addrolemember 'db_owner', '<serviceprincipal>'
Grant the required permissions to be able to insert into an existing table:
GRANT ADMINISTER DATABASE BULK OPERATIONS TO <serviceprincipal>
GRANT INSERT TO <serviceprincipal>
(Optional) Grant the required permissions to be able to insert into a new table:
GRANT CREATE TABLE TO <serviceprincipal>
GRANT ALTER ON SCHEMA ::dbo TO <serviceprincipal>
Step 7: Example syntax: query and write data in Azure Synapse Analytics
You can query Synapse in Scala, Python, SQL, and R. The following code examples use storage account keys and forward the storage credentials from Azure Databricks to Synapse.
- Scala
- Python
- SQL
- R
The following code examples show you have to:
- Set up the storage account access key in the notebook session
- Define the service principal credentials for the Azure storage account
- Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
- Get some data from an Azure Synapse table
- Load data from an Azure Synapse query
- Apply some transformations to the data, then use the Data Source API to write the data back to another table in Azure Synapse
import org.apache.spark.sql.DataFrame
// Set up the storage account access key in the notebook session
conf.spark.conf.set(
"fs.azure.account.key.<your-storage-account-name>.dfs.core.windows.net",
"<your-storage-account-access-key>")
// Define the service principal credentials for the Azure storage account
spark.conf.set("fs.azure.account.auth.type", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id", "<ApplicationId>")
spark.conf.set("fs.azure.account.oauth2.client.secret", "<SecretValue>")
spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<DirectoryId>/oauth2/token")
// Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
spark.conf.set("spark.databricks.sqldw.jdbc.service.principal.client.id", "<ApplicationId>")
spark.conf.set("spark.databricks.sqldw.jdbc.service.principal.client.secret", "<SecretValue>")
// Get some data from an Azure Synapse table
val df: DataFrame = spark.read
.format("com.databricks.spark.sqldw")
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>")
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>")
.option("enableServicePrincipalAuth", "true")
.option("dbTable", "dbo.<your-table-name>")
.load()
// Load data from an Azure Synapse query
val df1: DataFrame = spark.read
.format("com.databricks.spark.sqldw")
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>")
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>")
.option("enableServicePrincipalAuth", "true")
.option("query", "select * from dbo.<your-table-name>")
.load()
// Apply some transformations to the data, then use the
// Data Source API to write the data back to another table in Azure Synapse
df1.write
.format("com.databricks.spark.sqldw")
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>")
.option("tempDir", "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>")
.option("enableServicePrincipalAuth", "true")
.option("dbTable", "dbo.<new-table-name>")
.save()
The following code examples show you have to:
- Set up the storage account access key in the notebook session
- Define the service principal credentials for the Azure storage account
- Define a separate set of service principal credentials for Azure Synapse Analytics
- Get some data from an Azure Synapse table
- Load data from an Azure Synapse query
- Apply some transformations to the data, then use the Data Source API to write the data back to another table in Azure Synapse
The following code examples show you have to:
- Define the service principal credentials for the Azure storage account
- Define a separate set of service principal credentials for Azure Synapse Analytics
- Set up the storage account access key in the notebook session
- Read data using SQL
- Write data using SQL
# Define the Service Principal credentials for the Azure storage account
fs.azure.account.auth.type OAuth
fs.azure.account.oauth.provider.type org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider
fs.azure.account.oauth2.client.id <application-id>
fs.azure.account.oauth2.client.secret <service-credential>
fs.azure.account.oauth2.client.endpoint https://login.microsoftonline.com/<directory-id>/oauth2/token
## Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
spark.databricks.sqldw.jdbc.service.principal.client.id <application-id>
spark.databricks.sqldw.jdbc.service.principal.client.secret <service-credential>
# Set up the storage account access key in the notebook session
conf.SET fs.azure.account.key.<your-storage-account-name>.dfs.core.windows.net=<your-storage-account-access-key>
-- Read data using SQL
CREATE TABLE df
USING com.databricks.spark.sqldw
OPTIONS (
url 'jdbc:sqlserver://<the-rest-of-the-connection-string>',
'enableServicePrincipalAuth' 'true',
dbtable 'dbo.<your-table-name>',
tempDir 'abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>'
);
-- Write data using SQL
-- Create a new table, throwing an error if a table with the same name already exists:
CREATE TABLE df1
USING com.databricks.spark.sqldw
OPTIONS (
url 'jdbc:sqlserver://<the-rest-of-the-connection-string>',
'enableServicePrincipalAuth' 'true',
dbTable 'dbo.<new-table-name>',
tempDir 'abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>'
)
AS SELECT * FROM df1
The following code examples show you have to:
- Set up the storage account access key in the notebook session conf
- Define the service principal credentials for the Azure storage account
- Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
- Get some data from an Azure Synapse table
- Apply some transformations to the data, then use the Data Source API to write the data back to another table in Azure Synapse
# Load SparkR
library(SparkR)
# Set up the storage account access key in the notebook session conf
conf <- sparkR.callJMethod(sparkR.session(), "conf")
sparkR.callJMethod(conf, "set", "fs.azure.account.key.<your-storage-account-name>.dfs.core.windows.net", "<your-storage-account-access-key>")
# Load SparkR
library(SparkR)
conf <- sparkR.callJMethod(sparkR.session(), "conf")
# Define the service principal credentials for the Azure storage account
sparkR.callJMethod(conf, "set", "fs.azure.account.auth.type", "OAuth")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth2.client.id", "<ApplicationId>")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth2.client.secret", "<SecretValue>")
sparkR.callJMethod(conf, "set", "fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<DirectoryId>/oauth2/token")
# Define a separate set of service principal credentials for Azure Synapse Analytics (If not defined, the connector will use the Azure storage account credentials)
sparkR.callJMethod(conf, "set", "spark.databricks.sqldw.jdbc.service.principal.client.id", "<ApplicationId>")
sparkR.callJMethod(conf, "set", "spark.databricks.sqldw.jdbc.service.principal.client.secret", "SecretValue>")
# Get some data from an Azure Synapse table
df <- read.df(
source = "com.databricks.spark.sqldw",
url = "jdbc:sqlserver://<the-rest-of-the-connection-string>",
tempDir = "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>",
enableServicePrincipalAuth = "true",
dbTable = "dbo.<your-table-name>")
# Load data from an Azure Synapse query.
df <- read.df(
source = "com.databricks.spark.sqldw",
url = "jdbc:sqlserver://<the-rest-of-the-connection-string>",
tempDir = "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>",
enableServicePrincipalAuth = "true",
query = "Select * from dbo.<your-table-name>")
# Apply some transformations to the data, then use the
# Data Source API to write the data back to another table in Azure Synapse
write.df(
df,
source = "com.databricks.spark.sqldw",
url = "jdbc:sqlserver://<the-rest-of-the-connection-string>",
tempDir = "abfss://<your-container-name>@<your-storage-account-name>.dfs.core.windows.net/<your-directory-name>",
enableServicePrincipalAuth = "true",
dbTable = "dbo.<new-table-name>")
Troubleshooting
The following sections discuss error messages that you may encounter and their possible meanings.
Service principal credential does not exist as an user
com.microsoft.sqlserver.jdbc.SQLServerException: Login failed for user '<token-identified principal>'
The preceding error probably means the service principal credential does not exist as an user in the Synapse Analytics workspace.
Run the following command in the Azure Synapse Analytics dedicated pool to create an external user:
CREATE USER <serviceprincipal> FROM EXTERNAL PROVIDER
Service principal credential has insufficient SELECT permissions
com.microsoft.sqlserver.jdbc.SQLServerException: The SELECT permission was denied on the object 'TableName', database 'PoolName', schema 'SchemaName'. [ErrorCode = 229] [SQLState = S0005]
The preceding error probably means that the service principal credential does not have enough SELECT permissions in the Azure Synapse Analytics dedicated pool.
Run the following command in the Azure Synapse Analytics dedicated pool to grant SELECT permissions:
GRANT SELECT TO <serviceprincipal>
Service principal credential does not have permissions to use COPY
com.microsoft.sqlserver.jdbc.SQLServerException: User does not have permission to perform this action. [ErrorCode = 15247] [SQLState = S0001]
The preceding error probably means that the service principal credential does not have enough permissions in the Azure Synapse Analytics dedicated pool to use COPY. The service principal requires different permissions depending on the operation (insert into an existing table or insert into a new table). Make sure the service principal has the required Azure Synapse permissions.
The service principal is not a db_owner of the Azure Synapse Analytics dedicated pool.
Run the following command in the Azure Synapse Analytics dedicated pool to grant db_owner permissions:
sp_addrolemember 'db_owner', 'serviceprincipal'
No master key in the dedicated pool
com.microsoft.sqlserver.jdbc.SQLServerException: Please create a master key in the database or open the master key in the session before performing this operation. [ErrorCode = 15581] [SQLState = S0006]
The preceding error probably means that there is no master key in the Azure Synapse Analytics dedicated pool.
Create a master key in Azure Synapse Analytics to fix this issue.
Service principal credential has insufficient write permissions
com.microsoft.sqlserver.jdbc.SQLServerException: CREATE EXTERNAL TABLE AS SELECT statement failed as the path name '' could not be used for export. Please ensure that the specified path is a directory which exists or can be created, and that files can be created in that directory. [ErrorCode = 105005] [SQLState = S0001]
The preceding error probably means that:
-
The service principal credential does not have enough permissions for PolyBase write operations
Make sure the service principal has the required Azure Synapse permissions for PolyBase with the external data source option.
-
The staging storage account does not have Azure Data Lake Storage capabilities.
You can upgrade Azure Blob Storage with Azure Data Lake Storage capabilities.
-
The service principal/managed service identity does not have “Storage Blob Data Contributor” role on the Azure Data Lake Storage.
-
Refer to Error 105005 when you do CETAS operation to Azure blob storage for additional troubleshooting.