Author AI agents in code
This page shows how to author an AI agent in Python using Mosaic AI Agent Framework and popular agent authoring libraries like LangGraph and OpenAI.
Requirements
Databricks recommends installing the latest version of the MLflow Python client when developing agents.
To author and deploy agents using the approach on this page, install the following:
databricks-agents1.2.0 or abovemlflow3.1.3 or above- Python 3.10 or above.
- Use serverless compute or Databricks Runtime 13.3 LTS or above to meet this requirement.
%pip install -U -qqqq databricks-agents mlflow
Databricks also recommends installing Databricks AI Bridge integration packages to author agents. These integration packages provide a shared layer of APIs that interact with Databricks AI features, such as Databricks AI/BI Genie and Vector Search, across agent authoring frameworks and SDKs.
- OpenAI
- LangChain/LangGraph
- DSPy
- Pure Python agents
%pip install -U -qqqq databricks-openai
%pip install -U -qqqq databricks-langchain
%pip install -U -qqqq databricks-dspy
%pip install -U -qqqq databricks-ai-bridge
Use ResponsesAgent to author agents
Databricks recommends the MLflow interface ResponsesAgent to create production-grade agents. ResponsesAgent lets you build agents with any third-party framework, then integrate it with Databricks AI features for robust logging, tracing, evaluation, deployment, and monitoring capabilities.
The ResponsesAgent schema is compatible with the OpenAI Responses schema. To learn more about OpenAI Responses, see OpenAI: Responses vs. ChatCompletion.
The older ChatAgent interface is still supported on Databricks. However, for new agents, Databricks recommends using the latest version of MLflow and the ResponsesAgent interface.

ResponsesAgent provides the following benefits:
-
Advanced agent capabilities
- Multi-agent support
- Streaming output: Stream the output in smaller chunks.
- Comprehensive tool-calling message history: Return multiple messages, including intermediate tool-calling messages, for improved quality and conversation management.
- Tool-calling confirmation support
- Long-running tool support
-
Streamlined development, deployment, and monitoring
- Author agents using any framework: Wrap any existing agent using the
ResponsesAgentinterface to get out-of-the-box compatibility with AI Playground, Agent Evaluation, and Agent Monitoring. - Typed authoring interfaces: Write agent code using typed Python classes, benefiting from IDE and notebook autocomplete.
- Automatic signature inference: MLflow automatically infers
ResponsesAgentsignatures when logging an agent, simplifying registration and deployment. See Infer Model Signature during logging. - Automatic tracing: MLflow automatically traces your
predictandpredict_streamfunctions, aggregating streamed responses for easier evaluation and display. - AI Gateway-enhanced inference tables: AI Gateway inference tables are automatically enabled for deployed agents, providing access to detailed request log metadata.
- Author agents using any framework: Wrap any existing agent using the
To learn how to create a ResponsesAgent, see the examples in the following section and MLflow documentation - ResponsesAgent for Model Serving.
ResponsesAgent examples
The following notebooks show how to author streaming and non-streaming ResponsesAgent using popular libraries. To learn how to expand the capabilities of these agents, see AI agent tools.
- OpenAI
- LangGraph
- DSPy
OpenAI simple chat agent using Databricks-hosted models
OpenAI MCP tool-calling agent
OpenAI tool-calling agent using Databricks-hosted models
OpenAI tool-calling agent using OpenAI-hosted models
LangGraph MCP tool-calling agent
DSPy single-turn tool-calling agent
Multi-agent example
To learn how to create a multi-agent system, see Use Genie in multi-agent systems.
Stateful agent example
To learn how to create stateful agents with short-term and long-term memory using Lakebase as a memory store, see AI agent memory.
Non-conversational agent example
Unlike conversational agents that manage multi-turn dialogues, non-conversational agents focus on executing well-defined tasks efficiently. This streamlined architecture enables higher throughput for independent requests.
To learn how to create a non-conversational agent, see Non-conversational AI agents using MLflow.
What if I already have an agent?
If you already have an agent built with LangChain, LangGraph, or a similar framework, you don’t need to rewrite your agent to use it on Databricks. Instead, just wrap your existing agent with the MLflow ResponsesAgent interface:
-
Write a Python wrapper class that inherits from
mlflow.pyfunc.ResponsesAgent.Inside the wrapper class, reference the existing agent as an attribute
self.agent = your_existing_agent. -
The
ResponsesAgentclass requires implementing apredictmethod that returns aResponsesAgentResponseto handle non-streaming requests. The following is an example of theResponsesAgentResponsesschema:Pythonimport uuid
# input as a dict
{"input": [{"role": "user", "content": "What did the data scientist say when their Spark job finally completed?"}]}
# output example
ResponsesAgentResponse(
output=[
{
"type": "message",
"id": str(uuid.uuid4()),
"content": [{"type": "output_text", "text": "Well, that really sparked joy!"}],
"role": "assistant",
},
]
) -
In the
predictfunction, convert the incoming messages fromResponsesAgentRequestinto the format the agent expects. After the agent generates a response, convert its output to aResponsesAgentResponseobject.
See the following code examples to see how to convert existing agents to ResponsesAgent:
- Basic conversion
- Streaming with code re-use
- Migrate from ChatCompletions
For non-streaming agents, convert inputs and outputs in the predict function.
from uuid import uuid4
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
)
class MyWrappedAgent(ResponsesAgent):
def __init__(self, agent):
# Reference your existing agent
self.agent = agent
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
# Convert incoming messages to your agent's format
# prep_msgs_for_llm is a function you write to convert the incoming messages
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# Call your existing agent (non-streaming)
agent_response = self.agent.invoke(messages)
# Convert your agent's output to ResponsesAgent format, assuming agent_response is a str
output_item = (self.create_text_output_item(text=agent_response, id=str(uuid4())),)
# Return the response
return ResponsesAgentResponse(output=[output_item])
For streaming agents, you can be clever and reuse logic to avoid duplicating the code that converts messages:
from typing import Generator
from uuid import uuid4
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
ResponsesAgentStreamEvent,
)
class MyWrappedStreamingAgent(ResponsesAgent):
def __init__(self, agent):
# Reference your existing agent
self.agent = agent
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
"""Non-streaming predict: collects all streaming chunks into a single response."""
# Reuse the streaming logic and collect all output items
output_items = []
for stream_event in self.predict_stream(request):
if stream_event.type == "response.output_item.done":
output_items.append(stream_event.item)
# Return all collected items as a single response
return ResponsesAgentResponse(output=output_items)
def predict_stream(
self, request: ResponsesAgentRequest
) -> Generator[ResponsesAgentStreamEvent, None, None]:
"""Streaming predict: the core logic that both methods use."""
# Convert incoming messages to your agent's format
# prep_msgs_for_llm is a function you write to convert the incoming messages, included in full examples linked below
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# Stream from your existing agent
item_id = str(uuid4())
aggregated_stream = ""
for chunk in self.agent.stream(messages):
# Convert each chunk to ResponsesAgent format
yield self.create_text_delta(delta=chunk, item_id=item_id)
aggregated_stream += chunk
# Emit an aggregated output_item for all the text deltas with id=item_id
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_text_output_item(text=aggregated_stream, id=item_id),
)
If your existing agent uses the OpenAI ChatCompletions API, you can migrate it to ResponsesAgent without rewriting its core logic. Add a wrapper that:
- Converts incoming
ResponsesAgentRequestmessages to theChatCompletionsformat your agent expects. - Translates
ChatCompletionsoutputs into theResponsesAgentResponseschema. - Optionally supports streaming by mapping incremental deltas from
ChatCompletionsintoResponsesAgentStreamEventobjects.
from typing import Generator
from uuid import uuid4
from databricks.sdk import WorkspaceClient
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
ResponsesAgentStreamEvent,
)
# Legacy agent that outputs ChatCompletions objects
class LegacyAgent:
def __init__(self):
self.w = WorkspaceClient()
self.OpenAI = self.w.serving_endpoints.get_open_ai_client()
def stream(self, messages):
for chunk in self.OpenAI.chat.completions.create(
model="databricks-claude-sonnet-4-5",
messages=messages,
stream=True,
):
yield chunk.to_dict()
# Wrapper that converts the legacy agent to a ResponsesAgent
class MyWrappedStreamingAgent(ResponsesAgent):
def __init__(self, agent):
# `agent` is your existing ChatCompletions agent
self.agent = agent
def prep_msgs_for_llm(self, messages):
# dummy example of prep_msgs_for_llm
# real example of prep_msgs_for_llm included in full examples linked below
return [{"role": "user", "content": "Hello, how are you?"}]
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
"""Non-streaming predict: collects all streaming chunks into a single response."""
# Reuse the streaming logic and collect all output items
output_items = []
for stream_event in self.predict_stream(request):
if stream_event.type == "response.output_item.done":
output_items.append(stream_event.item)
# Return all collected items as a single response
return ResponsesAgentResponse(output=output_items)
def predict_stream(
self, request: ResponsesAgentRequest
) -> Generator[ResponsesAgentStreamEvent, None, None]:
"""Streaming predict: the core logic that both methods use."""
# Convert incoming messages to your agent's format
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# process the ChatCompletion output stream
agent_content = ""
tool_calls = []
msg_id = None
for chunk in self.agent.stream(messages): # call the underlying agent's stream method
delta = chunk["choices"][0]["delta"]
msg_id = chunk.get("id", None)
content = delta.get("content", None)
if tc := delta.get("tool_calls"):
if not tool_calls: # only accommodate for single tool call right now
tool_calls = tc
else:
tool_calls[0]["function"]["arguments"] += tc[0]["function"]["arguments"]
elif content is not None:
agent_content += content
yield ResponsesAgentStreamEvent(**self.create_text_delta(content, item_id=msg_id))
# aggregate the streamed text content
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_text_output_item(agent_content, msg_id),
)
for tool_call in tool_calls:
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_function_call_item(
str(uuid4()),
tool_call["id"],
tool_call["function"]["name"],
tool_call["function"]["arguments"],
),
)
agent = MyWrappedStreamingAgent(LegacyAgent())
for chunk in agent.predict_stream(
ResponsesAgentRequest(input=[{"role": "user", "content": "Hello, how are you?"}])
):
print(chunk)
For complete examples, see ResponsesAgent examples.
Streaming responses
Streaming allows agents to send responses in real-time chunks instead of waiting for the complete response. To implement streaming with ResponsesAgent, emit a series of delta events followed by a final completion event:
- Emit delta events: Send multiple
output_text.deltaevents with the sameitem_idto stream text chunks in real-time. - Finish with done event: Send a final
response.output_item.doneevent with the sameitem_idas the delta events containing the complete final output text.
Each delta event streams a chunk of text to the client. The final done event contains the complete response text and signals Databricks to do the following:
- Trace your agent's output with MLflow tracing
- Aggregate streamed responses in AI Gateway inference tables
- Show the complete output in the AI Playground UI
Streaming error propagation
Mosaic AI propagates any errors encountered while streaming with the last token under databricks_output.error. It is up to the calling client to properly handle and surface this error.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
Advanced features
Custom inputs and outputs
Some scenarios might require additional agent inputs, such as client_type and session_id, or outputs like retrieval source links that should not be included in the chat history for future interactions.
For these scenarios, MLflow ResponsesAgent natively supports the fields custom_inputs and custom_outputs. You can access the custom inputs via request.custom_inputs in all examples linked above in ResponsesAgent Examples.
The Agent Evaluation review app does not support rendering traces for agents with additional input fields.
See the following notebooks to learn how to set custom inputs and outputs.
Provide custom_inputs in the AI Playground and review app
If your agent accepts additional inputs using the custom_inputs field, you can manually provide these inputs in both the AI Playground and the review app.
-
In either the AI Playground or the Agent Review App, select the gear icon
 .
. -
Enable custom_inputs.
-
Provide a JSON object that matches your agent's defined input schema.
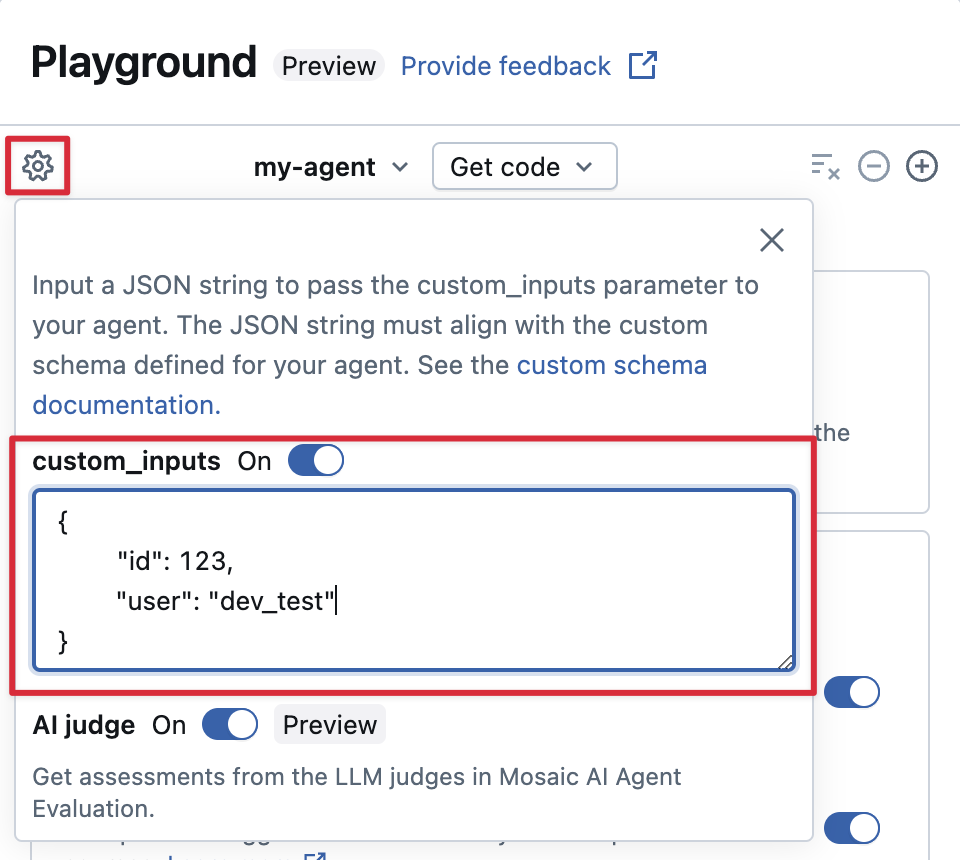
Specify custom retriever schemas
AI agents commonly use retrievers to find and query unstructured data from vector search indices. For example retriever tools, see Connect agents to unstructured data.
Trace these retrievers within your agent with MLflow RETRIEVER spans to enable Databricks product features, including:
- Automatically displaying links to retrieved source documents in the AI Playground UI
- Automatically running retrieval groundedness and relevance judges in Agent Evaluation
Databricks recommends using retriever tools provided by Databricks AI Bridge packages like databricks_langchain.VectorSearchRetrieverTool and databricks_openai.VectorSearchRetrieverTool because they already conform to the MLflow retriever schema. See Locally develop Vector Search retriever tools with AI Bridge.
If your agent includes retriever spans with a custom schema, call mlflow.models.set_retriever_schema when you define your agent in code. This maps your retriever's output columns to MLflow's expected fields (primary_key, text_column, doc_uri).
import mlflow
# Define the retriever's schema by providing your column names
# For example, the following call specifies the schema of a retriever that returns a list of objects like
# [
# {
# 'document_id': '9a8292da3a9d4005a988bf0bfdd0024c',
# 'chunk_text': 'MLflow is an open-source platform, purpose-built to assist machine learning practitioners...',
# 'doc_uri': 'https://mlflow.org/docs/latest/index.html',
# 'title': 'MLflow: A Tool for Managing the Machine Learning Lifecycle'
# },
# {
# 'document_id': '7537fe93c97f4fdb9867412e9c1f9e5b',
# 'chunk_text': 'A great way to get started with MLflow is to use the autologging feature. Autologging automatically logs your model...',
# 'doc_uri': 'https://mlflow.org/docs/latest/getting-started/',
# 'title': 'Getting Started with MLflow'
# },
# ...
# ]
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="mlflow_docs_vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="document_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="chunk_text",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
# Specify any other columns returned by the retriever
other_columns=["title"],
)
The doc_uri column is especially important when evaluating the retriever's performance. doc_uri is the main identifier for documents returned by the retriever, allowing you to compare them against ground truth evaluation sets. See Evaluation sets (MLflow 2).
Deployment considerations
Prepare for Databricks Model Serving
Databricks deploys ResponsesAgents in a distributed environment on Databricks Model Serving. This means that during a multi-turn conversation, the same serving replica might not handle all requests. Pay attention to the following implications for managing agent state:
-
Avoid local caching: When deploying a
ResponsesAgent, don't assume the same replica handles all requests in a multi-turn conversation. Reconstruct internal state using a dictionaryResponsesAgentRequestschema for each turn. -
Thread-safe state: Design agent state to be thread-safe, preventing conflicts in multi-threaded environments.
-
Initialize state in the
predictfunction: Initialize state each time thepredictfunction is called, not duringResponsesAgentinitialization. Storing state at theResponsesAgentlevel could leak information between conversations and cause conflicts because a singleResponsesAgentreplica could handle requests from multiple conversations.
Parametrize code for deployment across environments
Parametrize agent code to reuse the same agent code across different environments.
Parameters are key-value pairs that you define in a Python dictionary or a .yaml file.
To configure the code, create a ModelConfig using either a Python dictionary or a .yaml file. ModelConfig is a set of key-value parameters that allows for flexible configuration management. For example, you can use a dictionary during development and then convert it to a .yaml file for production deployment and CI/CD.
An example ModelConfig is shown below:
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-meta-llama-3-3-70b-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
In your agent code, you can reference a default (development) configuration from the .yaml file or dictionary:
import mlflow
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-meta-llama-3-3-70b-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
# You can also use model_config.to_dict() to convert the loaded config object
# into a dictionary
value = model_config.get('sample_param')
Then, when logging your agent, specify the model_config parameter to log_model to
specify a custom set of parameters to use when loading the logged agent. See
MLflow documentation - ModelConfig.
Use synchronous code or call-back patterns
To ensure stability and compatibility, use synchronous code or callback-based patterns in your agent implementation.
Databricks automatically manages asynchronous communication to provide optimal concurrency and performance when you deploy an agent. Introducing custom event loops or async frameworks might lead to errors like RuntimeError: This event loop is already running and caused unpredictable behavior.
Databricks recommends avoiding asynchronous programming, such as using asyncio or creating custom event loops, when developing agents.