Migrate optimized LLM serving endpoints to provisioned throughput
This documentation has been retired and might not be updated. The products, services, or technologies mentioned in this content are no longer supported.
This article describes how to migrate your existing LLM serving endpoints to the provisioned throughput experience available using Foundation Model APIs.
What's changing?
Provisioned throughput provides a simpler experience for launching optimized LLM serving endpoints. Databricks has modified their LLM model serving system so that:
- Scale-out ranges can be configured in LLM-native terms, like tokens per second instead of concurrency.
- Customers no longer need to select GPU workload types themselves.
New LLM serving endpoints are created with provisioned throughput by default. If you want to continue selecting the GPU workload type, this experience is only supported using the API.
Migrate LLM serving endpoints to provisioned throughput
The simplest way to migrate your existing endpoint to provisioned throughput is to update your endpoint with a new model version. After you select a new model version, the UI displays the experience for provisioned throughput. The UI shows tokens per second ranges based on Databricks benchmarking for typical use cases.
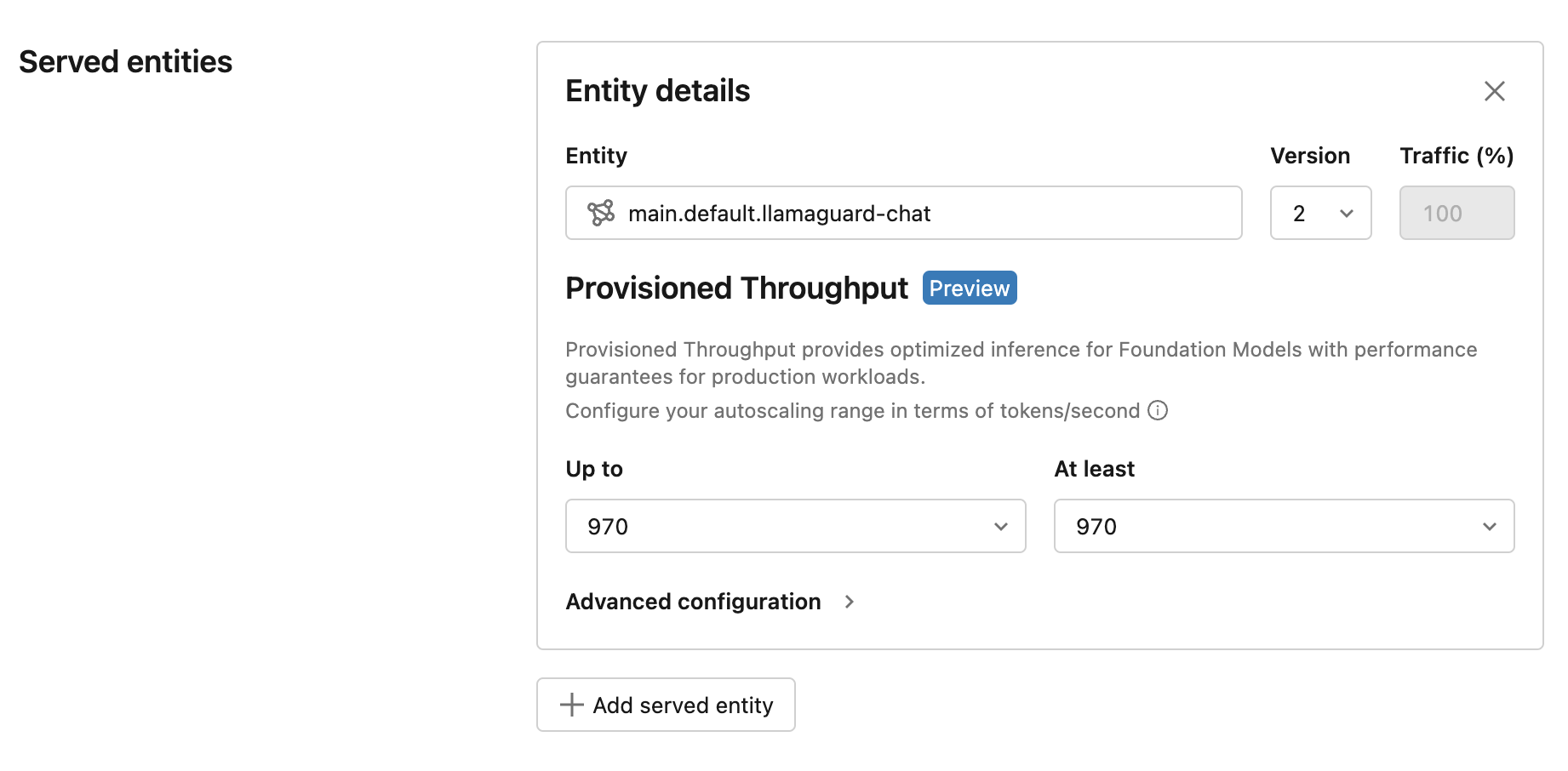
Performance with this updated offering is strictly better due to optimization improvements, and the price for your endpoint remains unchanged. Please reach out to model-serving-feedback@databricks.com for product feedback or concerns.