Databricks リファレンスアーキテクチャ(ダウンロード)
Databricks のリファレンスアーキテクチャは、データソース、インジェスト、変換、クエリと処理、サービング、分析、ストレージを網羅するアーキテクチャガイダンスを提供します。
各リファレンスアーキテクチャは、11 x 17(A3)フォーマットのPDFをダウンロードできます。
Databricksは大規模なパートナーツールエコシステムと統合するオープンなプラットフォームですが、リファレンスアーキテクチャはGoogle クラウドサービスとDatabricksプラットフォームにのみ焦点を当てています。示されているクラウドプロバイダーサービスは、概念を説明するために選択されており、すべてを網羅しているわけではありません。
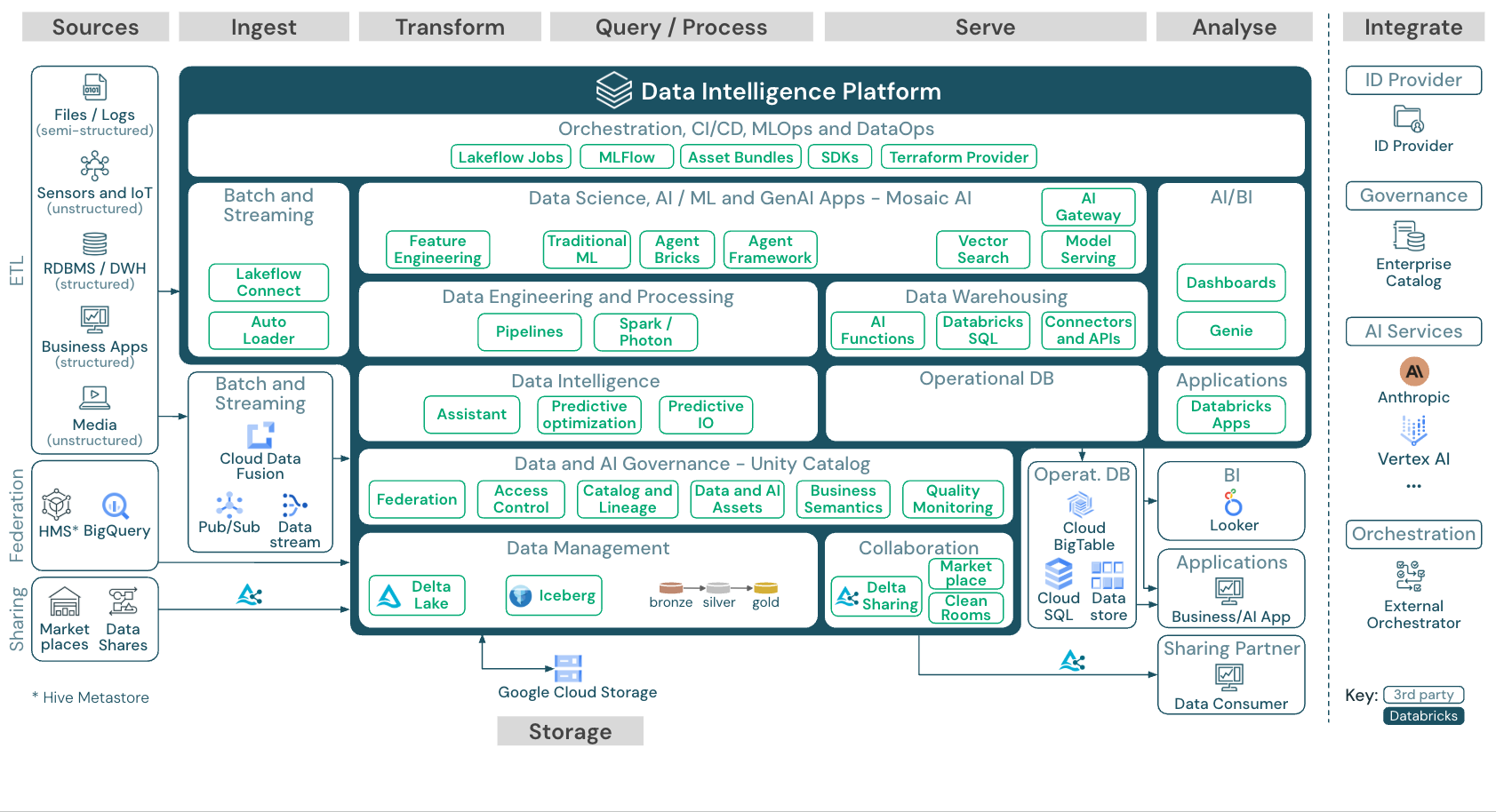
ダウンロード:Googleクラウド上のDatabricksプラットフォームのリファレンスアーキテクチャ
GCP リファレンス アーキテクチャには、取り込み、保存、配信、分析のための次の GCP 固有のサービスが示されています。
- レイクハウスフェデレーションのソースシステムとしてのBigQuery
- ストリーミング取り込み用のPub/Subとデータストリーム
- Cloud Data Fusion によるバッチ取り込み
- データおよびAIアセットのオブジェクトストレージとしてのCloud Storage
- 運用データベースとしてのCloud Big Table、Cloud SQL、Data Store
- BIツールとしてのLooker
- Vertex AI は、モデルサービングが外部LLMを呼び出すために使用できます
リファレンス・アーキテクチャの構成
参照アーキテクチャは、 ソース 、 インジェスト 、 変換 、 クエリ/プロセス 、 サーブ 、 分析 、 ストレージ のスイムレーンに沿って構成されています。
-
ソース
外部データをデータインテリジェンスプラットフォームに統合するには、次の3つの方法があります。
-
ETL:このプラットフォームは、半構造化データおよび非構造化データ(センサー、IoTデバイス、メディア、ファイル、ログなど)を提供するシステム、およびリレーショナルデータベースやビジネスアプリケーションからの構造化データとの統合を可能にします。
-
レイクハウスフェデレーション:リレーショナルデータベースなどのSQLソースは、ETLなしでDatabricksおよびUnity Catalogに統合できます。この場合、ソースシステムのデータはUnity Catalogによって管理され、クエリはソースシステムにプッシュダウンされます。
-
カタログのフェデレーション:Hive metastore カタログはUnity Catalog 、カタログのフェデレーション を通じて に統合することもでき、Unity Catalog Hive metastoreに格納されたテーブルを制御できます。
-
-
インジェスト
バッチまたはストリーミング経由で Databricks にデータを取り込みます。
- Databricks Lakeflow Connect 、エンタープライズ アプリケーションやデータベースから取り込むための組み込みコネクタを提供します。 結果として得られる取り込みパイプラインはUnity Catalogによって管理され、サーバレス コンピュートとパイプラインによって強化されます。
- クラウドストレージに配信されたファイルは、Databricks Auto Loader を使用して直接読み込むことができます。
- エンタープライズアプリケーションからDelta Lakeへのバッチでのデータ取り込みには、Databricksプラットフォームは、これらの記録システムに特化したアダプターを備えたパートナー取り込みツールを使用します。
- ストリーミング イベントは、Databricksの構造化ストリーミングを使用して、Kafkaなどのイベント ストリーミング システムから直接取り込むことができます。ストリーミング ソースは、センサー、 IoT、または チェンジデータキャプチャ プロセスです。
-
ストレージ
- データは通常、クラウド上でストレージシステムに保存され、 ETL パイプラインは メダリオンアーキテクチャ を使用して、 Delta ファイル/テーブル または Apache Iceberg テーブルとしてキュレーションされた方法でデータを格納します。
-
変換 と クエリ/プロセス
-
Databricksプラットフォームは、すべての変換とクエリにApache SparkとPhotonのエンジンを使用します。
-
パイプラインは、信頼性が高く、保守可能で、テスト可能なデータ処理パイプラインを簡素化および最適化するための宣言型フレームワークです。
-
Apache SparkとPhotonを活用して、Databricksデータインテリジェンスプラットフォームは、 SQLウェアハウス を介したSQLクエリー、 ワークスペースのクラスターを通じた、SQL、Python、Scalaワークロードの両方をサポートします。
-
データサイエンス(ML モデリングと 生成AI)の場合、DatabricksのAI および機械学習プラットフォームは、 AutoML と ML ジョブのコーディングに特化した ML ランタイムを提供します。 すべてのデータサイエンスとMLOpsワークフローは、MLflowによって最適にサポートされます。
-
-
サービング
-
データウェアハウジング(DWH)およびBIのユースケースでは、Databricksプラットフォームは、Databricks SQL、SQLウェアハウスによって強化されたデータウェアハウス、およびサーバレスSQLウェアハウスを提供します。
-
機械学習の場合、モデルサービングは、 Databricksコントロール プレーンでホストされるスケーラブルな、無制限のエンタープライズ グレードのモデルサービング機能です。 Unity AI Gatewayは、サポートされている生成AIモデルとそれに関連するモデルサービング エンドポイントへのアクセスを管理およびモニタリングするためのDatabricksのソリューションです。
-
運用データベース: 運用データベースなどの 外部システムを使用して、最終データ製品を格納し、ユーザー アプリケーションに配信できます。
-
-
コラボレーション :
-
ビジネスパートナーは、OpenSharingを通じて必要なデータに安全にアクセスできます。
-
OpenSharingを基盤とするDatabricks Marketplaceは、データ製品を交換するためのオープンフォーラムです。
-
クリーンルーム は、複数のユーザーが互いのデータに直接アクセスすることなく、機密性の高い企業データで共同作業ができる、安全でプライバシー保護の環境です。
-
-
分析
-
最終的なビジネスアプリケーションは、このスイムレーンにあります。例としては、リアルタイム推論のためにModel Servingに接続されたAIアプリケーションや、Databricksから運用データベースにプッシュされたデータにアクセスするアプリケーションなどのカスタムクライアントがあります。
-
BI のユースケースでは、アナリストは通常、 データウェアハウスにアクセスするBI ツールを使用します。 SQL 開発者は、 Databricks SQL エディター (図には示されていません) を使用して、クエリとダッシュボードに追加で使用できます。
-
Data Intelligence Platform には、データの視覚化を構築し、知見を共有するための ダッシュボード も用意されています。
-
-
統合
-
Databricks プラットフォームは、 ユーザー管理 と シングルサインオン (SSO) のための標準 ID プロバイダーと統合されています。
-
OpenAI 、 LangGraph 、 HuggingFaceなどの外部AIサービスは、 Databricks Intelligence Platform内から直接利用できます。
-
外部オーケストレーターは、包括的な REST API を使用するか、 Apache Airflow などの外部オーケストレーション ツールへの専用コネクタを使用できます。
-
Unity Catalogは、Databricks Intelligence PlatformのすべてのデータおよびAIのガバナンスに使用され、レイクハウスフェデレーション を通じて他のデータベースをガバナンスに統合できます。
さらに、Unity Catalog は他のエンタープライズ カタログに統合できます。 詳細については、エンタープライズ カタログ ベンダーにお問い合わせください。
-
すべてのワークロードに共通の機能
さらに、Databricks プラットフォームには、すべてのワークロードをサポートする管理機能が備わっています:
-
データとAIのガバナンス
Databricks Data Intelligence Platform の中心的なデータおよび AI ガバナンスシステムは、Unity Catalog です。Unity Catalog は、すべてのワークスペースに適用されるデータアクセス ポリシーを管理する単一の場所を提供し、テーブル、ボリューム、フィーチャー (Feature Store)、モデル (モデルレジストリ) など、Databricks で作成または使用されるすべてのアセットをサポートします。Unity Catalog は、Databricks で実行されるクエリ全体で ランタイム データリネージをキャプチャするためにも使用できます。
Databricks データ品質モニタリングを使用すると、アカウント内のすべてのテーブルのデータ品質を監視できます。すべてのテーブルの異常を検出し、各テーブルの完全なデータプロファイリングを提供します。
可観測性のために、 システムテーブル は、アカウントの運用データの Databricksホスト型分析ストアです。 システムテーブルは、アカウント全体の履歴オブザーバビリティに使用できます。
-
データインテリジェンスエンジン
Databricks Data Intelligence Platformは、組織全体でデータとAIを活用することを可能にし、生成AIとDatabricksの統合の利点を組み合わせることで、データの独自のセマンティクスを理解します。Databricks AIアシスト機能を参照してください。
Genie Code は、ユーザー向けのコンテキスト認識 AI アシスタントとして、Databricks ノートブック、SQL エディター、ファイル エディターなどで利用できます。
-
オートメーション&オーケストレーション
Lakeflow Jobs は、Databricks Data Intelligence Platform 上でデータ処理、Machine Learning、アナリティクス パイプラインを調整します。Lakeflow pipelinesを使用すると、宣言型構文で信頼性と保守性に優れた ETL パイプラインを構築できます。このプラットフォームは、CI/CD と MLOps もサポートしています。
Google Cloud 上の Data Intelligence Platform のユースケースの概要
を使用した アプリやデータベースからの組み込みSaaSLakeflowコネクト
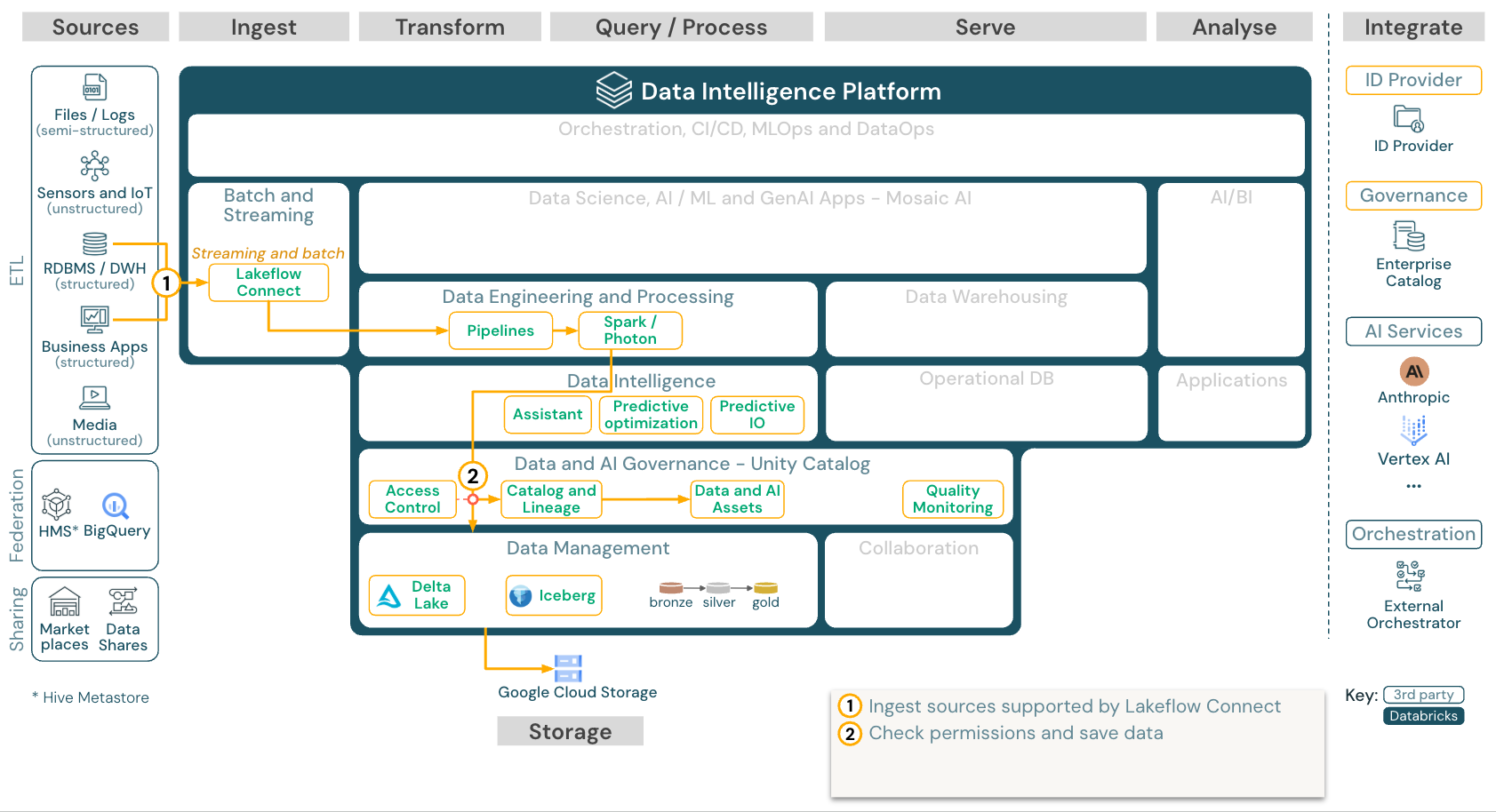
ダウンロード:Lakeflowコネクト DatabricksonGCP の リファレンス アーキテクチャ。
Databricks Lakeflow Connectは、エンタープライズアプリケーションおよびデータベースからの取り込み用の組み込みコネクタを提供します。結果として得られる取り込みパイプラインはUnity Catalogによって管理され、Serverless コンピュートおよびLakeflow Pipelinesによって強化されます。
Lakeflowコネクト は、効率的な増分読み取りと書き込みを活用して、データ取り込みをより速く、スケーラブルで、コスト効率を高めながら、データを最新のままダウンストリームで消費できるようにします。
バッチ取り込みとETL
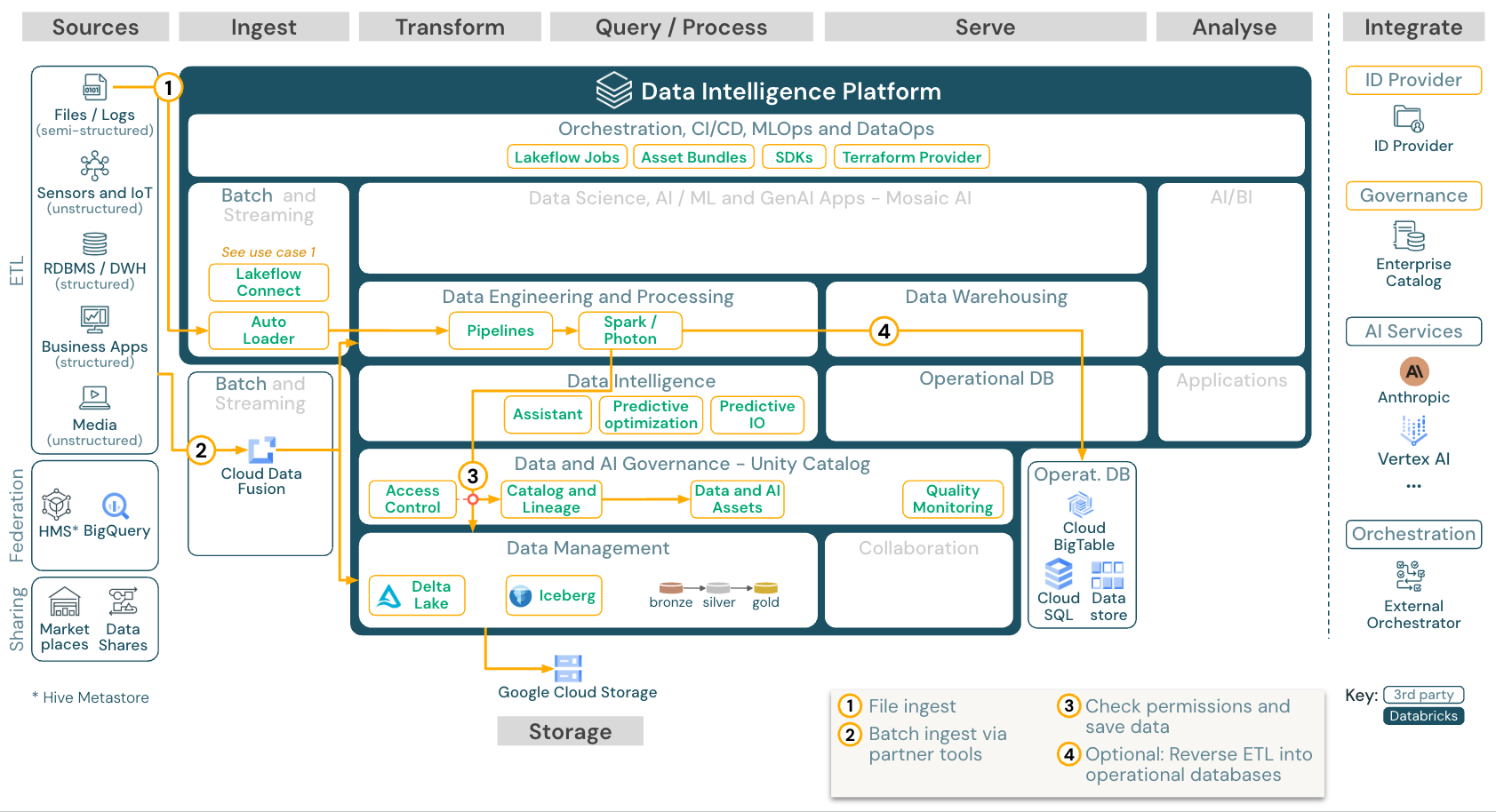
ダウンロード:Databricks on Google CloudのバッチETLリファレンスアーキテクチャ
インジェストツールは、ソース固有のアダプターを使用してソースからデータを読み取り、その後、Auto Loaderが読み取れるクラウド上で保存するか、Databricksを直接呼び出します(例えば、Databricksプラットフォームに統合されたパートナーインジェストツールを使用する場合などです)。データをロードするには、DatabricksのETLおよび処理エンジンがパイプライン経由でクエリを実行します。Lakeflowジョブを使用して単一またはマルチタスクのジョブを調整し、Unity Catalog(アクセス制御、監査、リネージなど)を使用してそれらを管理します。低レイテンシの運用システム向けに特定のゴールデンテーブルへのアクセスを提供するには、ETLパイプラインの最後にRDBMSやキーバリューストアなどの運用データベースにテーブルをエクスポートします。
ストリーミング and チェンジデータキャプチャ (CDC)
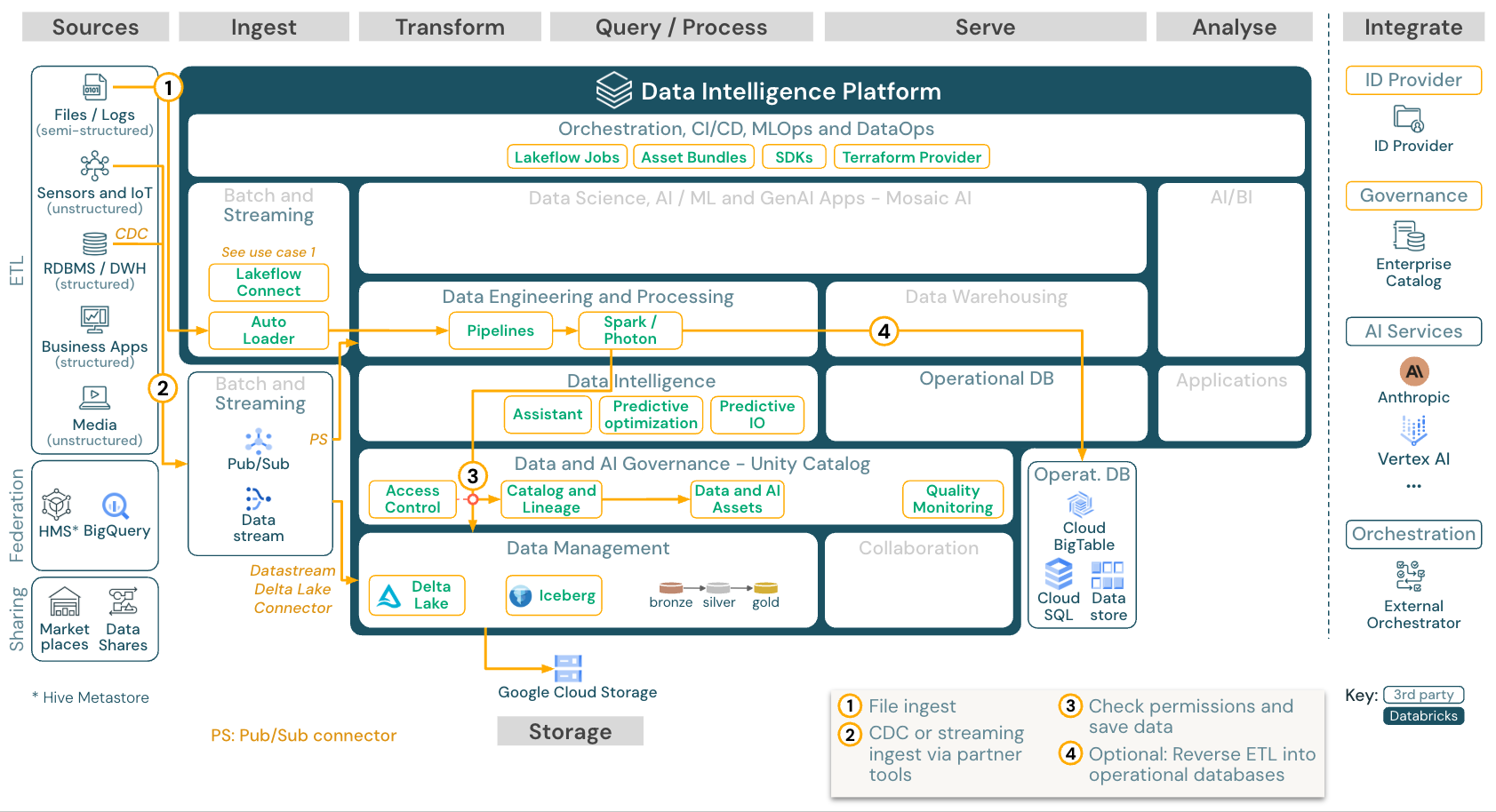
ダウンロード:Databricks on Google CloudのSpark構造化ストリーミングアーキテクチャ
Databricks ETL エンジンは、 Spark 構造化ストリーミング を使用して、Apache Kafka や Pub/Sub などのイベント キューから読み取ります。ダウンストリームの手順は、上記のバッチのユースケースのアプローチに従います。
通常、変化データキャプチャ( CDC ) は、抽出されたイベントをイベント キューに保存します。 そこから、ユースケースはストリーミングのユースケースに従います。
CDCバッチで実行され、抽出されたレコードが最初にクラウド ストレージに保存されている場合、 Databricks Auto Loaderそれらを読み取ることができ、ユース ケースは バッチETLに従います。
機械学習と AI (従来型)
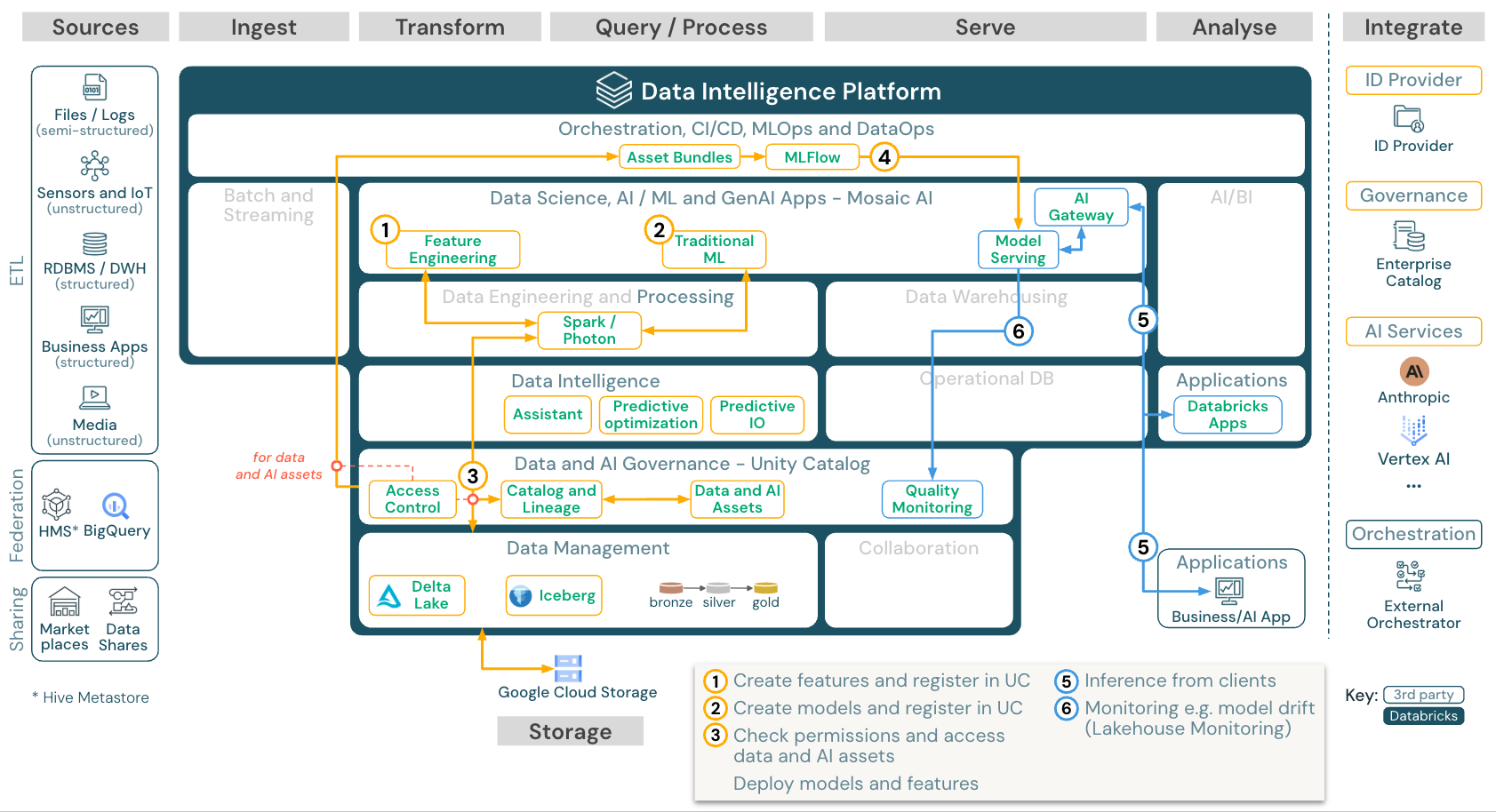
ダウンロード:Databricks on Google Cloudの機械学習およびAIリファレンスアーキテクチャ
機械学習のために、 Databricks Data Intelligence Platform は最先端のマシンとディープラーニング ライブラリを提供します。 これは、 Feature StoreやModel Registry (両方ともUnity Catalogに統合)、 AutoMLによるローコード機能、データサイエンス ライフサイクルへのMLflow統合などの機能を提供します。
Unity Catalogすべてのデータサイエンス関連の資産 (テーブル、機能、モデル) を管理し、 data scientists Lakeflowジョブを使用してジョブを調整できます。
スケーラブルでエンタープライズ グレードの方法でモデルをデプロイするには、 MLOps 機能を使用してモデルをモデル サービングにパブリッシュします。
AIエージェントアプリケーション(生成AI)
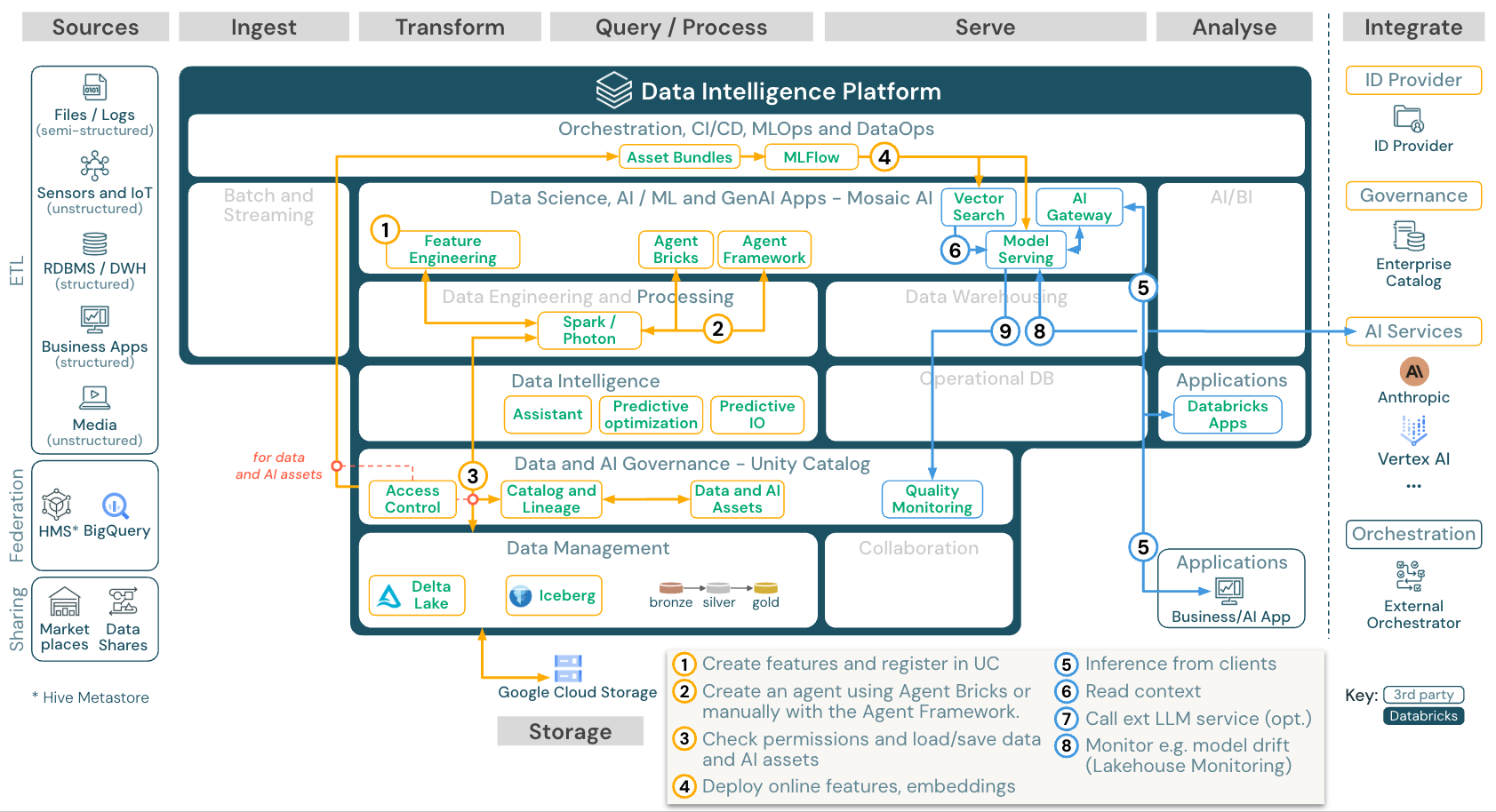
ダウンロード: Gen AI application reference architecture for Databricks on Google Cloud
生成AIのユースケース向けに、Databricksは最先端のライブラリと、プロンプトエンジニアリングからAIエージェントの構築、既存モデルのファインチューニングまで、特定の生成AI機能を備えています。上記のアーキテクチャは、AI検索 を 生成AI エージェントに統合する方法の例を示しています。
スケーラブルでエンタープライズグレードの方法でモデルをデプロイするには、MLOps機能を使用してモデルサービングでモデルを公開します。
BI and SQL アナリティクス
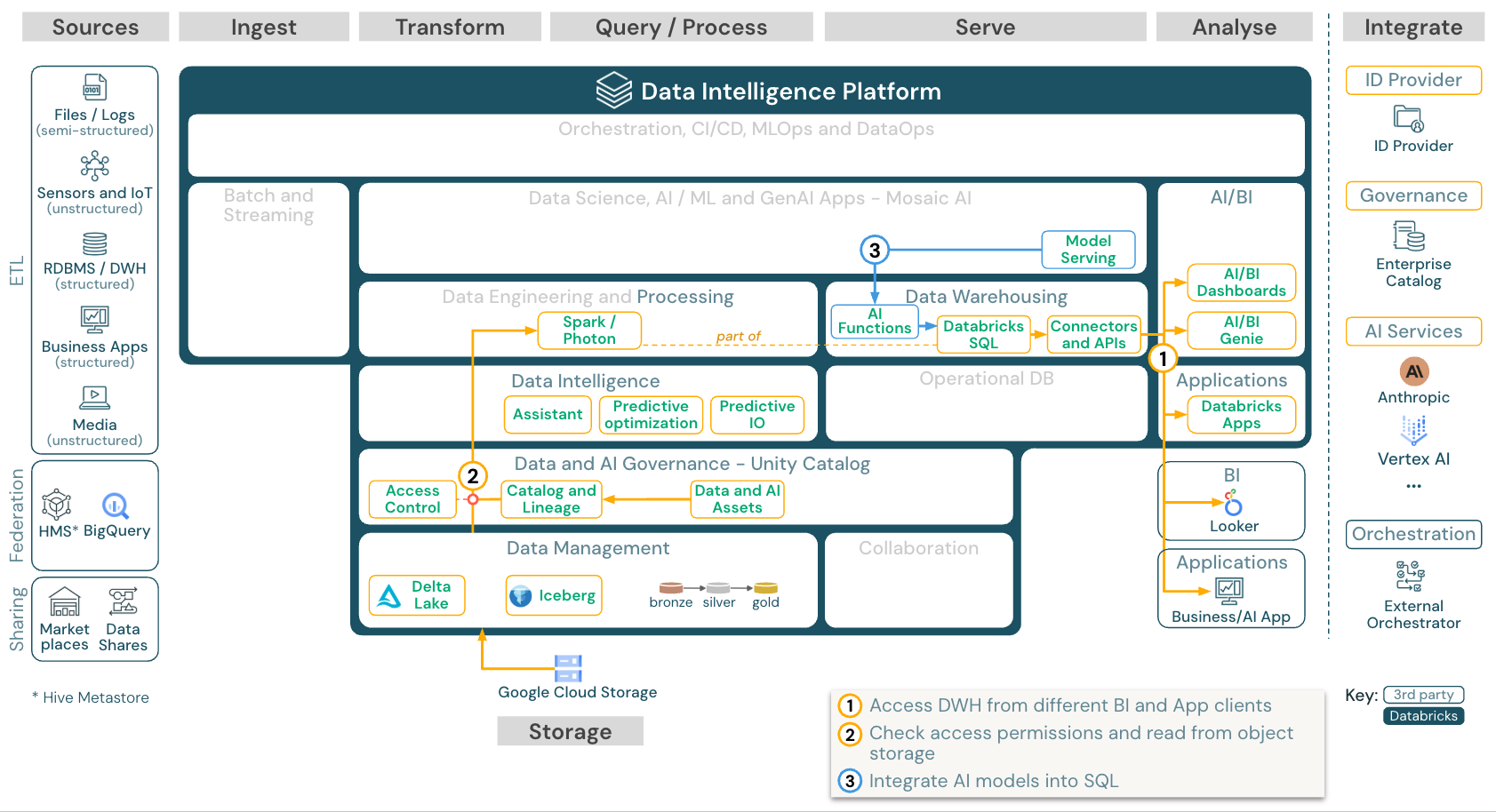
ダウンロード:Databricks on Google CloudのBIおよびSQLアナリティクスのリファレンスアーキテクチャ
BI のユースケースでは、ビジネスアナリストは ダッシュボード、 Databricks SQL エディター 、または Tableau や Looker などの BI ツール を使用できます。いずれの場合も、エンジンは Databricks SQL (サーバレスまたは非サーバレス) であり、 Unity Catalog がデータディスカバリー、探索、およびアクセス制御を提供します。
ビジネスアプリ
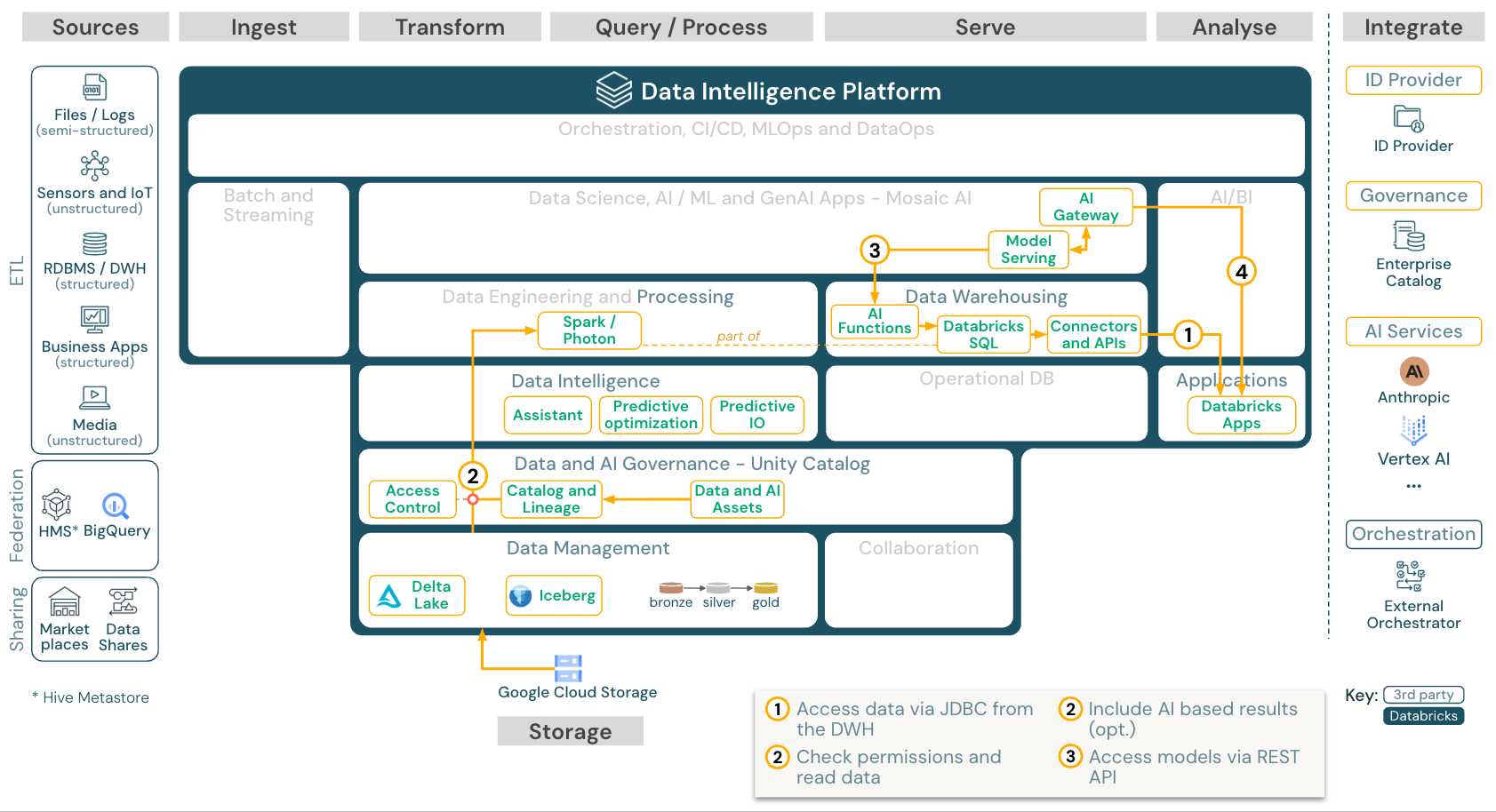
ダウンロード: Databricks on Google Cloud Databricks Business Apps
Databricks Apps を使用すると、開発者は安全なデータアプリケーションや AI アプリケーションを Databricks プラットフォーム上で直接構築してデプロイできるため、個別のインフラストラクチャが不要になります。アプリは Databricks サーバレス プラットフォームでホストされ、主要なプラットフォーム サービスと統合されます。
レイクハウス連合
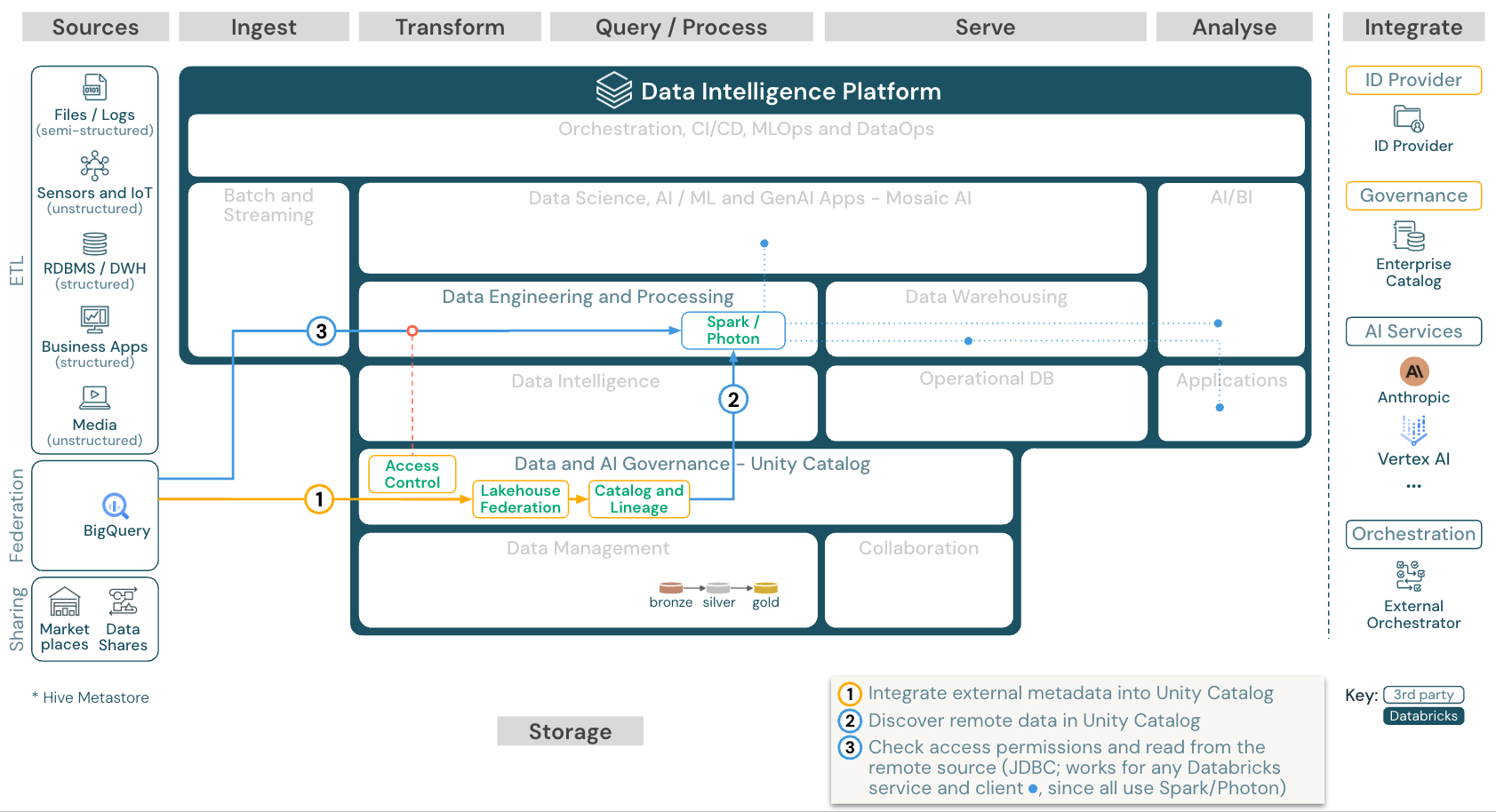
ダウンロード: Databricks on Google Cloudのレイクハウスフェデレーションリファレンスアーキテクチャ
レイクハウスフェデレーション を使用すると、外部データのSQLデータベース(MySQLやPostgresなど)をDatabricksと統合できます。
最初にデータをオブジェクトストレージにETLする必要がなく、すべてのワークロード (AI、DWH、BI) がこのメリットを享受できます。外部ソースカタログはUnity Catalogにマッピングされ、Databricksプラットフォーム経由のアクセスにきめ細かいアクセス制御を適用できます。
カタログのフェデレーション
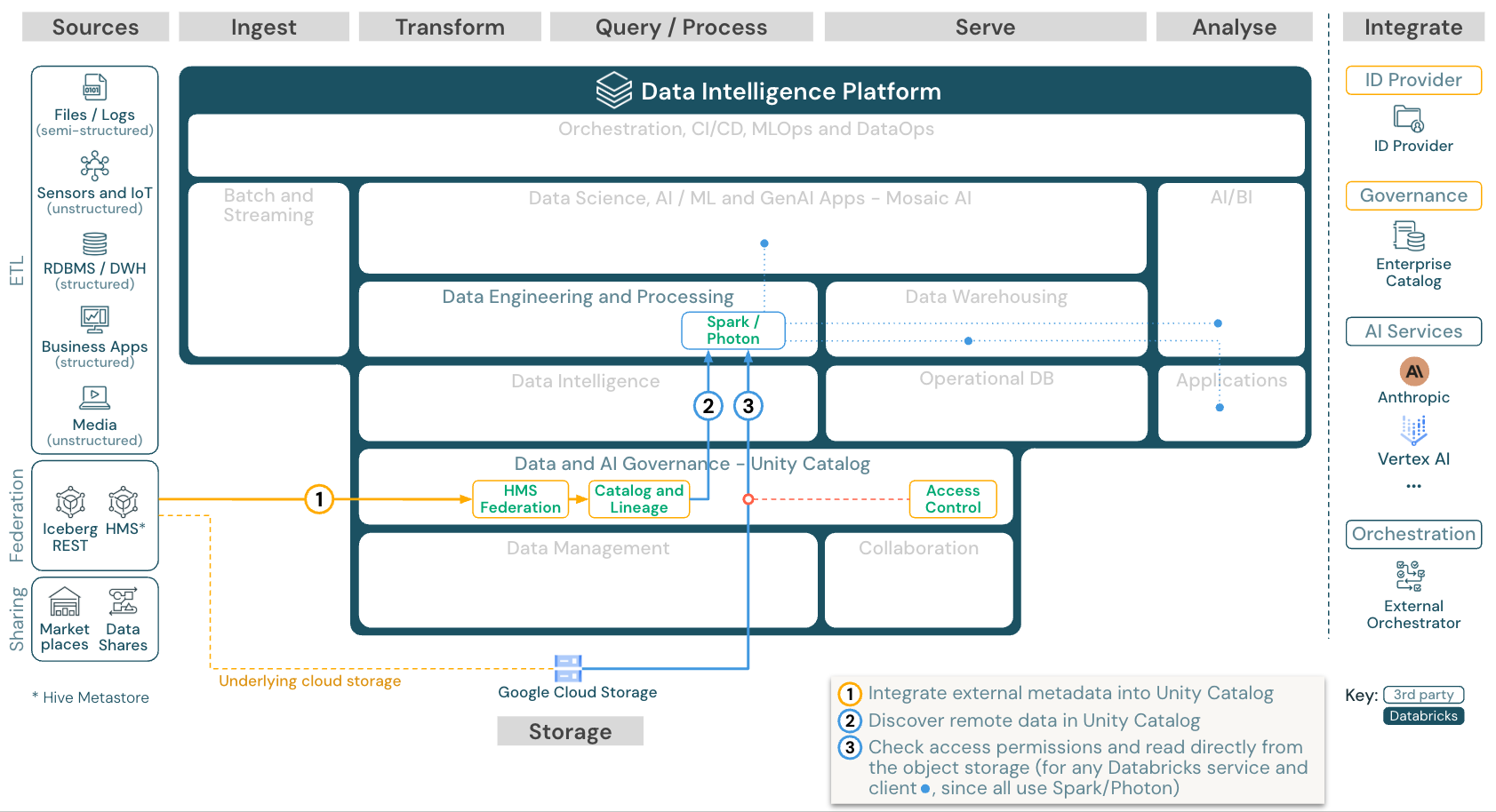
ダウンロード: Databricks on Google Cloud のカタログ統合参照アーキテクチャ
カタログ フェデレーション を使用すると、外部の Hive メタストア (MySQL や Postgres など) を Databricks と統合できます。
すべてのワークロード(AI、DWH、BI)は、最初にデータをオブジェクトストレージにETLしなくても、このメリットを享受できます。外部ソース カタログは、Unity Catalog プラットフォームを介してきめ細かなアクセス制御が適用されるDatabricks に追加されます。
サードパーティのツールとデータを共有する
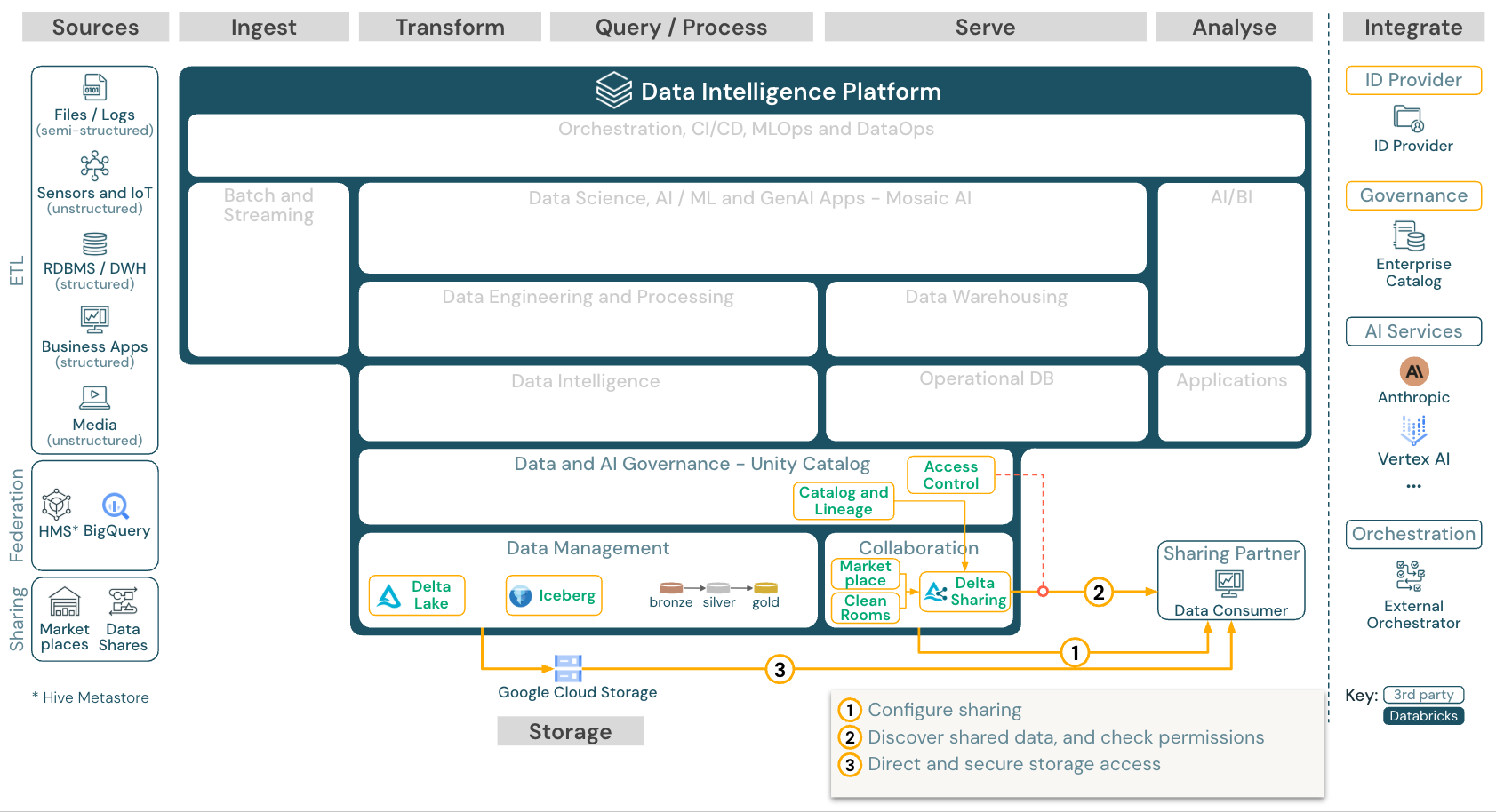
ダウンロード: 3rd パーティ ツールとのデータ共有: Databricks on Google Cloud のリファレンス アーキテクチャ
サードパーティとのエンタープライズグレードのデータ共有は、OpenSharingによって提供されます。Unity Catalogで保護されたオブジェクトストア内のデータに直接アクセスできます。この機能は、データ製品を交換するためのオープンフォーラムであるDatabricks Marketplaceでも使用されています。
Databricks から共有データを使用する
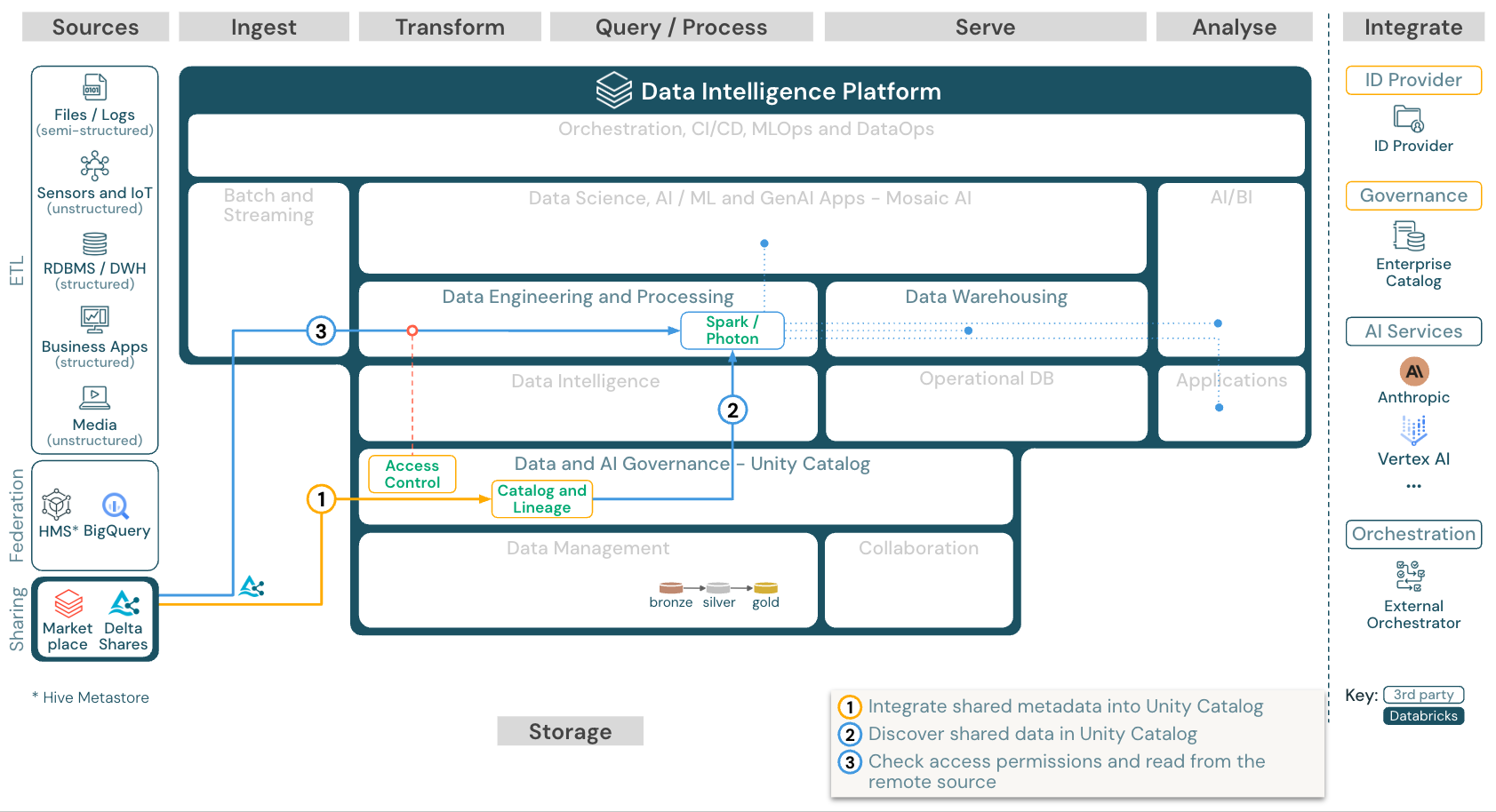
ダウンロード: の参照アーキテクチャから共有データを使用するDatabricksDatabricks on Google Cloud
OpenSharing Databricks-to-Databricks プロトコルを使用すると、アカウントやクラウドホストに関係なく、Unity Catalogが有効になっているワークスペースにアクセスできるDatabricksユーザーであれば、任意のユーザーとデータを安全に共有できます。