レコメンダー モデルに学習させる
この記事では、Databricks のディープラーニングベースのレコメンデーション モデルの 2 つの例を紹介します。 従来のレコメンデーション モデルと比較して、ディープラーニング モデルは、より高品質の結果を達成し、大量のデータにスケーリングできます。 これらのモデルが進化し続ける中、Databricks は、数億人のユーザーを処理できる大規模なレコメンデーションモデルを効果的にトレーニングするためのフレームワークを提供します。
一般的な推奨システムは、図に示されている段階を持つファネルと見なすことができます。
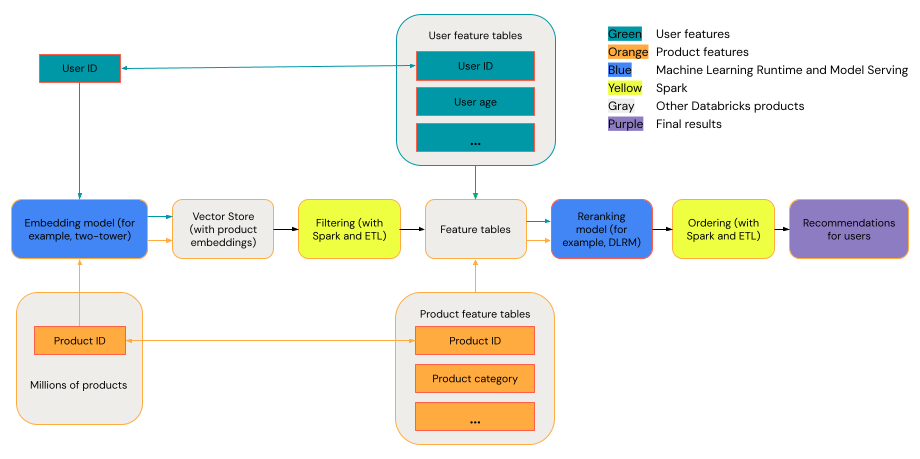
Two-Towerモデルなどの一部のモデルは、検索モデルとしてより優れたパフォーマンスを発揮します。 これらのモデルはより小さく、数百万のデータポイントを効果的に処理できます。 DLRM や DeepFM などの他のモデルは、再ランク付けモデルとしてより優れたパフォーマンスを発揮します。 これらのモデルは、より多くのデータを取り込むことができ、より大きく、きめ細かなレコメンデーションを提供できます。
必要条件
Databricks Runtime 14.3 LTS ML
ツール
この記事の例では、次のツールについて説明します。
- TorchDistributor: TorchDistributor は、Databricks で大規模な PyTorch モデル トレーニングを実行できるフレームワークです。 オーケストレーションに Spark を使用し、クラスターで使用可能な数の GPU にスケーリングできます。
- MLflow: MLflow、パラメーター、メトリクス、およびモデルチェックポイントを追跡できます。
- TorchRec:最新のレコメンダーシステムは、埋め込みルックアップテーブルを使用して、何百万人ものユーザーとアイテムを処理し、高品質のレコメンデーションを生成します。 埋め込みサイズを大きくすると、モデルのパフォーマンスは向上しますが、大量の GPU メモリとマルチ GPU セットアップが必要になります。 TorchRec は、レコメンデーションモデルとルックアップテーブルを複数の GPU にスケーリングするフレームワークを提供するため、大規模な埋め込みに最適です。
例: 2 タワー モデル アーキテクチャを使用した映画の推奨事項
2タワーモデルは、ユーザーとアイテムのデータを別々に処理してから組み合わせることで、大規模なパーソナライゼーションタスクを処理するように設計されています。 それは効率的に数百または数千のまともな品質の推奨事項を生成することができます。 モデルは通常3つの入力を想定します: user_id特徴量、product_id特徴量、および <user, product>の相互作用がポジティブ (ユーザーが製品を購入した) かネガティブ (ユーザーが製品に 1 つ星の評価を与えた) かを定義するバイナリラベルです。 モデルの出力は、ユーザーとアイテムの両方の埋め込みであり、それらは一般的に組み合わされます (多くの場合、ドット製品またはコサイン類似度を使用) ユーザーとアイテムの相互作用を予測します。
Two-Towerモデルはユーザーと製品の両方に埋め込みを提供するため、これらの埋め込みをDatabricks AI Searchのようなベクターインデックスに配置し、ユーザーとアイテムに対して類似性検索のような操作を実行できます。たとえば、すべての項目をベクター ストアに配置し、ユーザーごとに、ベクター ストアをクエリして、埋め込みがユーザーの埋め込みに類似している上位100個の項目を見つけることができます。
次のサンプルノートブックは、「アイテムセットからの学習」データセットを使用してTwo-Towerモデル トレーニングを実装し、ユーザーが特定の映画を高く評価する可能性を予測します。 分散データの読み込みには Mosaic StreamingDataset を使用し、分散モデルのトレーニングには TorchDistributor を使用し、モデルの追跡とログ記録には Mlflow を使用します。
2タワーレコメンダーモデルノートブック
このノートブックは、Databricks Marketplaceでも入手可能です: Two-Towerモデルノートブック
- Two-Towerモデルの入力は、ほとんどの場合、カテゴリ特徴の user_id と製品です。 モデルは、ユーザーと製品の両方に対して複数の特徴ベクトルをサポートするように変更できます。
- Two-Towerモデルの出力は通常、ユーザーが製品に対して肯定的なやり取りをするか否定的なやり取りをするかを示すバイナリ値です。 このモデルは、回帰、多クラス分類、複数のユーザー操作 (却下や購入など) の確率など、他のアプリケーション用に変更できます。 複雑な出力は、競合する目的によってモデルによって生成される埋め込みの品質が低下する可能性があるため、慎重に実装する必要があります。
例: 合成データセットを使用して DLRM アーキテクチャをトレーニングする
DLRMは、パーソナライゼーションおよびレコメンデーションシステム専用に設計された最先端のニューラルネットワークアーキテクチャです。 カテゴリ入力と数値入力を組み合わせて、ユーザーとアイテムの相互作用を効果的にモデル化し、ユーザーの好みを予測します。 DLRM は、通常、疎な特徴量 (ユーザー ID、アイテム ID、地理的位置、製品カテゴリなど) と密な特徴量 (ユーザーの年齢やアイテム価格など) の両方を含む入力を想定しています。 DLRMの出力は、通常、クリックスルー率や購入の可能性など、ユーザーエンゲージメントの予測です。
DLRM は、大規模なデータを処理できる高度にカスタマイズ可能なフレームワークを提供するため、さまざまなドメインにわたる複雑なレコメンデーション タスクに適しています。 2タワーアーキテクチャよりも大型モデルであるため、リランキングの段階でこのモデルがよく使われます。
次のノートブックの例では、密な (数値) 特徴とスパース (カテゴリ) 特徴を使用してバイナリ ラベルを予測する DLRM モデルを構築します。合成データセットを使用してモデルをトレーニングし、分散データ読み込みには Mosaic StreamingDataset、分散モデル トレーニングには TorchDistributor 、モデルの追跡とロギングには MLflow を使用します。
DLRM ノートブック
このノートブックは、Databricks Marketplace: DLRM ノートブックでも入手できます。
ツータワーモデルとDLRMモデルの比較
この表は、使用するレコメンダー モデルを選択するためのガイドラインを示しています。
モデルのタイプ | トレーニングに必要なデータセットのサイズ | モデルサイズ | サポートされている入力タイプ | サポートされている出力タイプ | ユースケース |
|---|---|---|---|---|---|
Two-Tower | 小さい | 小さい | 通常2つの機能(user_id、製品) | 主に二項分類と埋め込み生成 | 数百または数千の可能な推奨事項を生成する |
DLRM (英語) | 大きい | 大きい | さまざまなカテゴリカルおよび高密度の特徴(user_id、gender、geographic_location、product_id、product_category、...) | マルチクラス分類、回帰、その他 | きめ細かな検索(関連性の高い数十のアイテムを推奨) |
要約すると、Two-Towerモデルは、何千もの高品質のレコメンデーションを非常に効率的に生成するのに最適です。 例としては、ケーブル プロバイダーからの映画の推奨事項があります。 DLRM モデルは、より多くのデータに基づいて非常に具体的な推奨事項を生成する場合に最適です。 一例としては、顧客が購入する可能性が高い少数の商品を提示したい小売業者が挙げられます。