RAG用の非構造化データパイプラインを構築
この記事では、生成AI アプリケーション用の非構造化データパイプラインを構築する方法について説明します。 非構造化パイプラインは、Retrieval-Augmented Generation (RAG) アプリケーションに特に役立ちます。
テキストファイルやPDFなどの非構造化コンテンツを、AIエージェントや他のレトリーバーがクエリできるベクトルインデックスに変換する方法を学びます。 また、エクスペリメントとチューニングを行ってパイプラインを調整し、データのチャンク化、インデックス作成、解析を最適化する方法も学習し、パイプラインのトラブルシューティングとエクスペリメントを行い、より良い結果を得ることができます。
非構造化 データパイプライン ノートブック
次のノートブックは、この記事の情報を実装して非構造化データパイプラインを作成する方法を示しています。
Databricks 非構造化 データパイプライン
データパイプラインの主要コンポーネント
非構造化データを使用するRAGアプリケーションの基盤は、データパイプラインです。このパイプラインは、RAGアプリケーションが効果的に使用できる形式で非構造化データをキュレーションおよび準備する役割を担います。

このデータパイプラインはユースケースによっては複雑になる可能性がありますが、RAGアプリケーションを最初に構築する際に考慮する必要がある主要なコンポーネントは次のとおりです。
-
コーパスの構成とインジェスト: 特定のユースケースに基づいて、適切なデータソースとコンテンツを選択します。
-
データの前処理: 生データを、埋め込みと取得に適したクリーンで一貫性のある形式に変換します。
-
チャンク化: 解析されたデータを、効率的に取得できるように、より小さく管理しやすいチャンクに分割します。
-
エンベディング:チャンク化されたテキストデータを、その意味的意味を捉える数値ベクトル表現に変換します。
-
インデックス作成と保存:効率的なベクターインデックスを作成して、検索パフォーマンスを最適化します。
コーパスの構成と摂取
RAGアプリケーションは、適切なデータコーパスがないと、ユーザークエリに応答するために必要な情報を取得できません。正しいデータは、アプリケーション固有の要件と目標に完全に依存するため、利用可能なデータのニュアンスを理解するために時間を費やすことが重要です。詳細については、「 AI app developer ワークフローの生成」を参照してください。
たとえば、顧客サポート ボットを構築する場合は、次のものを含めることを検討できます。
- ナレッジベースドキュメント
- よくある質問 (FAQ)
- 製品マニュアルと仕様
- トラブルシューティングガイド
プロジェクトの開始段階からドメインの専門家や関係者を巻き込み、データコーパスの品質とカバレッジを向上させる可能性のある関連コンテンツを特定してキュレーションします。 これにより、ユーザーが送信する可能性が高いクエリの種類を把握でき、含める最も重要な情報の優先順位付けに役立ちます。
Databricks では、スケーラブルで増分的な方法でデータを取り込むことをお勧めします。Databricks は、 SaaS アプリケーションや API 統合用のフルマネージド コネクタなど、データ取り込みのためのさまざまな方法を提供しています。 ベスト プラクティスとして、生のソース データを取り込んでターゲット テーブルに格納する必要があります。このアプローチにより、データの保存、トレーサビリティ、監査が保証されます。Lakeflowコネクトの標準コネクタを参照してください。
データの前処理
データが取り込まれた後は、生データをクリーニングして、埋め込みと取得に適した一貫した形式にフォーマットすることが不可欠です。
解析
レトリーバー・アプリケーションに適したデータソースを特定したら、次のステップは生データから必要な情報を抽出することです。 このプロセスは解析と呼ばれ、非構造化データをRAGアプリケーションが効果的に使用できる形式に変換します。
使用する特定の解析手法とツールは、操作するデータのタイプによって異なります。 例えば:
- テキストドキュメント(PDF、Wordドキュメント): 非構造化ライブラリや PyPDF2 などの既製のライブラリは、さまざまなファイル形式を処理でき、解析プロセスをカスタマイズするためのオプションを提供します。
- HTML ドキュメント: BeautifulSoupやlxmlなどのHTML解析ライブラリを使用して、Webページから関連コンテンツを抽出できます。これらのライブラリは、HTML 構造をナビゲートし、特定の要素を選択し、目的のテキストまたは属性を抽出するのに役立ちます。
- 画像とスキャンしたドキュメント: 光学式文字認識(OCR)技術は、通常、画像からテキストを抽出するために必要です。 人気のある OCR ライブラリには、Tesseract などのオープンソース ライブラリや、SaaS AmazonTextract 、AzureAI Vision OCR 、Google Cloud VisionAPI などの バージョンがあります。
データ解析のベストプラクティス
解析により、データがクリーンで構造化され、埋め込み生成とベクトル検索の準備ができていることが保証されます。 データを解析するときは、次のベスト プラクティスを考慮してください。
- データクリーニング: 抽出したテキストを前処理して、ヘッダー、フッター、特殊文字など、無関係な情報やノイズの多い情報を削除します。 RAGチェーンが処理する必要がある不要な情報や不正な形式の情報の量を減らします。
- エラーと例外の処理: エラー処理とログ記録のメカニズムを実装して、解析プロセス中に発生した問題を特定して解決します。 これにより、問題を迅速に特定して修正できます。 多くの場合、これはソース データの品質に関するアップストリームの問題を示しています。
- 解析ロジックのカスタマイズ: データの構造と形式によっては、最も関連性の高い情報を抽出するために解析ロジックをカスタマイズする必要がある場合があります。 事前に追加の作業が必要になる場合もありますが、多くの場合、多くの下流の品質問題を防ぐため、必要に応じてこれを行うために時間を投資してください。
- 解析品質の評価: 出力のサンプルを手動でレビューすることにより、解析されたデータの品質を定期的に評価します。 これにより、解析プロセスの問題や改善すべき領域を特定できます。
エンリッチメント
エンリッチデータ 追加のメタデータとノイズの除去。 エンリッチメントはオプションですが、アプリケーションの全体的なパフォーマンスを大幅に向上させることができます。
メタデータの抽出
ドキュメントのコンテンツ、コンテキスト、構造に関する重要な情報をキャプチャするメタデータを生成および抽出することで、RAGアプリケーションの取得品質とパフォーマンスを大幅に向上させることができます。メタデータは、関連性を向上させ、高度なフィルタリングを可能にし、ドメイン固有の検索要件をサポートする追加のシグナルを提供します。
LangChain や LlamaIndex などのライブラリには、関連する標準メタデータを自動的に抽出できる組み込みパーサーが用意されていますが、特定のユースケースに合わせたカスタムメタデータでこれを補完すると便利な場合がよくあります。 このアプローチにより、ドメイン固有の重要な情報が確実にキャプチャされ、ダウンストリームの取得と生成が向上します。 また、大規模言語モデル (LLM) を使用して、メタデータの拡張を自動化することもできます。
メタデータの種類は次のとおりです。
- ドキュメントレベルのメタデータ: ファイル名、URL、作成者情報、作成と変更のタイムスタンプ、GPS座標、およびドキュメントのバージョン管理。
- コンテンツベースのメタデータ: 抽出されたキーワード、サマリー、トピック、名前付きエンティティ、ドメイン固有のタグ(製品名とPIIやHIPPAなどのカテゴリ)。
- 構造メタデータ: セクション ヘッダー、目次、ページ番号、およびセマンティック コンテンツの境界 (章またはサブセクション)。
- コンテキストメタデータ: ソースシステム、取り込み日、データ感度レベル、元の言語、または国境を越えた命令。
チャンクされたドキュメントまたはそれに対応する埋め込みと一緒にメタデータを保存することは、最適なパフォーマンスを得るために不可欠です。 また、取得した情報を絞り込み、アプリケーションの精度とスケーラビリティを向上させるのにも役立ちます。 さらに、メタデータをハイブリッド検索パイプラインに統合する、つまりベクトル類似性検索とキーワードベースのフィルタリングを組み合わせると、特に大規模なデータセットや特定の検索条件のシナリオで関連性を高めることができます。
重複 排除
ソースによっては、ドキュメントが重複したり、重複しそうになったりする可能性があります。 たとえば、1 つ以上の共有ドライブから取り込む場合、同じドキュメントの複数のコピーが複数の場所に存在する可能性があります。 これらのコピーの中には、微妙な変更が加えられているものもあります。 同様に、ナレッジベースには、製品ドキュメントのコピーやブログ記事のドラフトコピーがある場合があります。 これらの重複がコーパスに残っていると、最終的なインデックスに冗長性の高いチャンクができ、アプリケーションのパフォーマンスが低下する可能性があります。
メタデータのみを使用して、一部の重複を削除できます。 たとえば、アイテムのタイトルと作成日が同じで、ソースや場所からの複数のエントリが異なる場合、メタデータに基づいてそれらをフィルタリングできます。
ただし、これだけでは不十分な場合があります。 ドキュメントの内容に基づいて重複を特定して排除するために、ローカリティセンシティ ハッシュと呼ばれる手法を使用できます。 具体的には、ここでは MinHash と呼ばれる手法がうまく機能し、 Spark ML では Spark の実装が既に利用可能です。 これは、ドキュメントに含まれる単語に基づいてドキュメントのハッシュを作成することで機能し、それらのハッシュを結合することで重複または重複の近くを効率的に識別できます。 大まかに言うと、これは4つのステップからなるプロセスです。
- ドキュメントごとに特徴ベクトルを作成します。 必要に応じて、ストップワードの削除、ステミング、レンマ化などの手法を適用して結果を改善し、n-gram にトークン化することを検討してください。
- MinHash モデルを近似し、 Jaccard 距離の MinHash を使用してベクトルをハッシュします。
- これらのハッシュを使用して類似性結合を実行し、重複するドキュメントまたは重複に近いドキュメントごとに結果セットを生成します。
- 保持したくない重複を除外します。
ベースライン重複排除ステップでは、保持するドキュメントを任意に選択できます (各重複の結果の最初のドキュメントや、重複の中からランダムに選択するドキュメントなど)。改善策として考えられるのは、他のロジック (最近更新されたもの、発行状態、最も信頼できるソースなど) を使用して、複製の "最適な" バージョンを選択することです。また、マッチング結果を改善するために、特徴付けステップと MinHash モデルで使用されるハッシュ テーブルの数を使用してエクスペリメントが必要な場合があることに注意してください。
詳細については、 locality-sensitive ハッシュ に関するSparkドキュメントを参照してください。
フィルタリング
コーパスに取り込むドキュメントの中には、目的に無関係であったり、古すぎたり信頼性が低かったり、有害な言葉などの問題のあるコンテンツが含まれているなど、エージェントにとって役に立たないものもあります。 それでも、他のドキュメントには、エージェントを通じて公開したくない機密情報が含まれている場合があります。
そのため、任意のメタデータを使用してこれらのドキュメントを除外するステップをパイプラインに含めることを検討してください (ドキュメントに毒性分類子を適用してフィルターとして使用できる予測を生成するなど)。 別の例としては、個人を特定できる情報(PII)検出アルゴリズムをドキュメントに適用して、ドキュメントをフィルタリングします。
最後に、エージェントにフィードするドキュメントソースは、悪意のあるアクターがデータポイズニング攻撃を仕掛ける潜在的な攻撃ベクトルとなります。 また、検出メカニズムとフィルタリングメカニズムを追加して、それらを特定して排除することも検討できます。
チャンキング
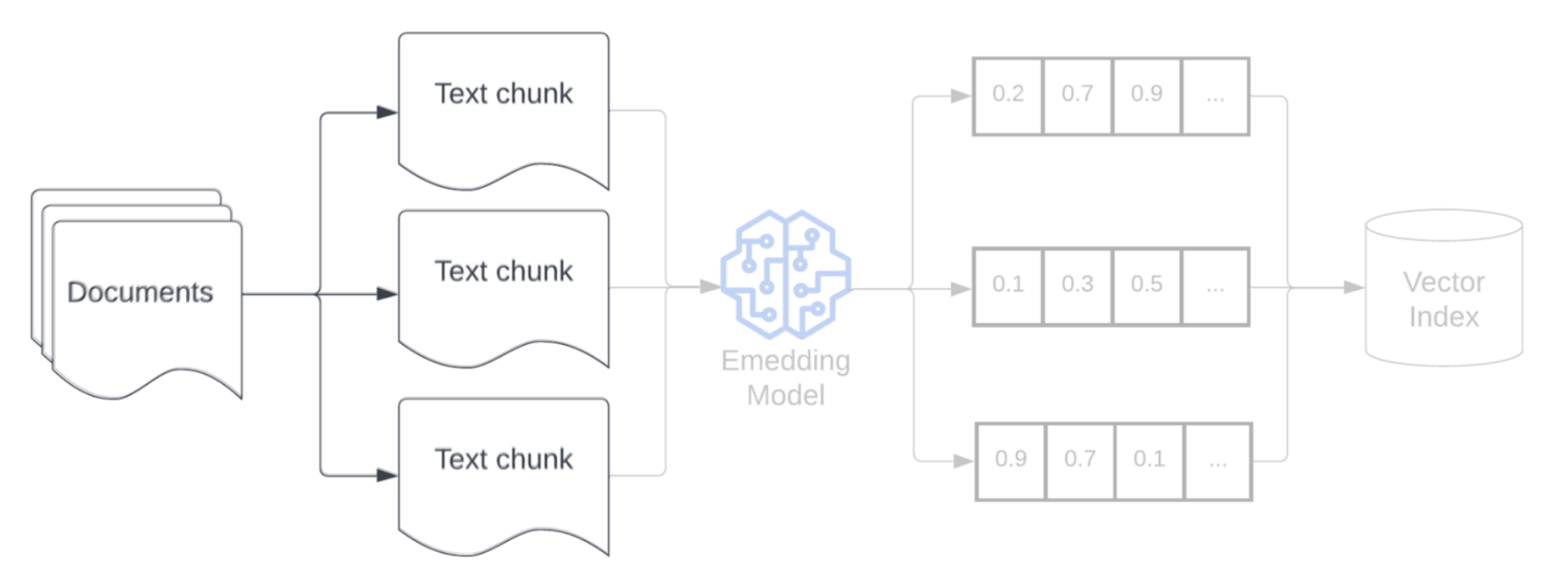
生データをより構造化された形式に解析し、重複を削除し、不要な情報をフィルタリングした後、次のステップは、生データをチャンクと呼ばれる管理しやすい小さな単位に分割することです。大きなドキュメントをより小さく、意味的に集中したチャンクに分割することで、取得したデータがLLMのコンテキストに収まるようにすると同時に、気を散らす情報や無関係な情報を含めることを最小限に抑えます。チャンキングでの選択は、LLMが提供する取得データに直接影響するため、LLMはRAGアプリケーションにおける最適化の最初のレイヤーの1つになります。
データをチャンク化するときは、次の要素を考慮してください。
- チャンク戦略: 元のテキストをチャンクに分割するために使用する方法。 これには、文、段落、特定の文字/トークン数、より高度なドキュメント固有の分割戦略による分割などの基本的な手法が含まれる場合があります。
- チャンク サイズ: 小さなチャンクは特定の詳細に焦点を当てているかもしれませんが、周囲のコンテキスト情報の一部が失われます。 チャンクが大きいほど、より多くのコンテキストをキャプチャできますが、無関係な情報が含まれたり、計算コストが高かったりする可能性があります。
- チャンク間のオーバーラップ: データをチャンクに分割するときに重要な情報が失われないように、隣接するチャンク間に重複を含めることを検討してください。 オーバーラップにより、チャンク間の連続性とコンテキストの保持を確保し、取得結果を改善できます。
- セマンティックの一貫性: 可能であれば、関連する情報を含みながらも、意味のあるテキスト単位として独立できる、意味的に一貫性のあるチャンクを作成することを目指します。 これは、段落、セクション、トピックの境界など、元のデータの構造を考慮することで実現できます。
- メタデータ: ソース ドキュメント名、セクション見出し、製品名などの 関連するメタデータを使用すると、取得を向上させることができます。 この追加情報は、取得クエリをチャンクに一致させるのに役立ちます。
データ チャンク化戦略
適切なチャンク方法を見つけることは、反復的であると同時にコンテキストに依存します。 万能のアプローチはありません。 最適なチャンク サイズと方法は、特定のユース ケースと処理されるデータの性質によって異なります。 チャンク戦略は、大まかに次のように見なすことができます。
- 固定サイズのチャンク: テキストを所定のサイズのチャンク (固定数の文字やトークンなど) に分割します (例: LangChain CharacterTextSplitter)。 任意の数の文字/トークンで分割するのはすばやく簡単に設定できますが、通常は意味的に一貫性のあるチャンクにはなりません。 このアプローチは、本番運用グレードのアプリケーションではほとんど機能しません。
- 段落ベースのチャンク化: テキスト内の自然な段落境界を使用して、チャンクを定義します。この方法は、段落に関連情報 ( LangChain RecursiveCharacterTextSplitter など) が含まれていることが多いため、チャンクのセマンティック一貫性を維持するのに役立ちます。
- 形式固有のチャンク化: Markdown や HTML などの形式には、チャンク境界 (markdown ヘッダーなど) を定義できる固有の構造があります。この目的のために、LangChainの MarkdownHeaderTextSplitter やHTML ヘッダー/セクションベースのスプリッターなどのツールを使用できます。
- セマンティック チャンク: トピックモデリングなどの手法を適用して、テキスト内の意味的に一貫性のあるセクションを特定できます。 これらのアプローチでは、各ドキュメントの内容または構造を分析し、トピックの変化に基づいて最適なチャンク境界を決定します。 セマンティック チャンクは、基本的なアプローチよりも複雑ですが、テキスト内の自然なセマンティック分割により一致するチャンクを作成するのに役立ちます (たとえば、 LangChain SemanticChunker を参照)。
例: 固定サイズのチャンク
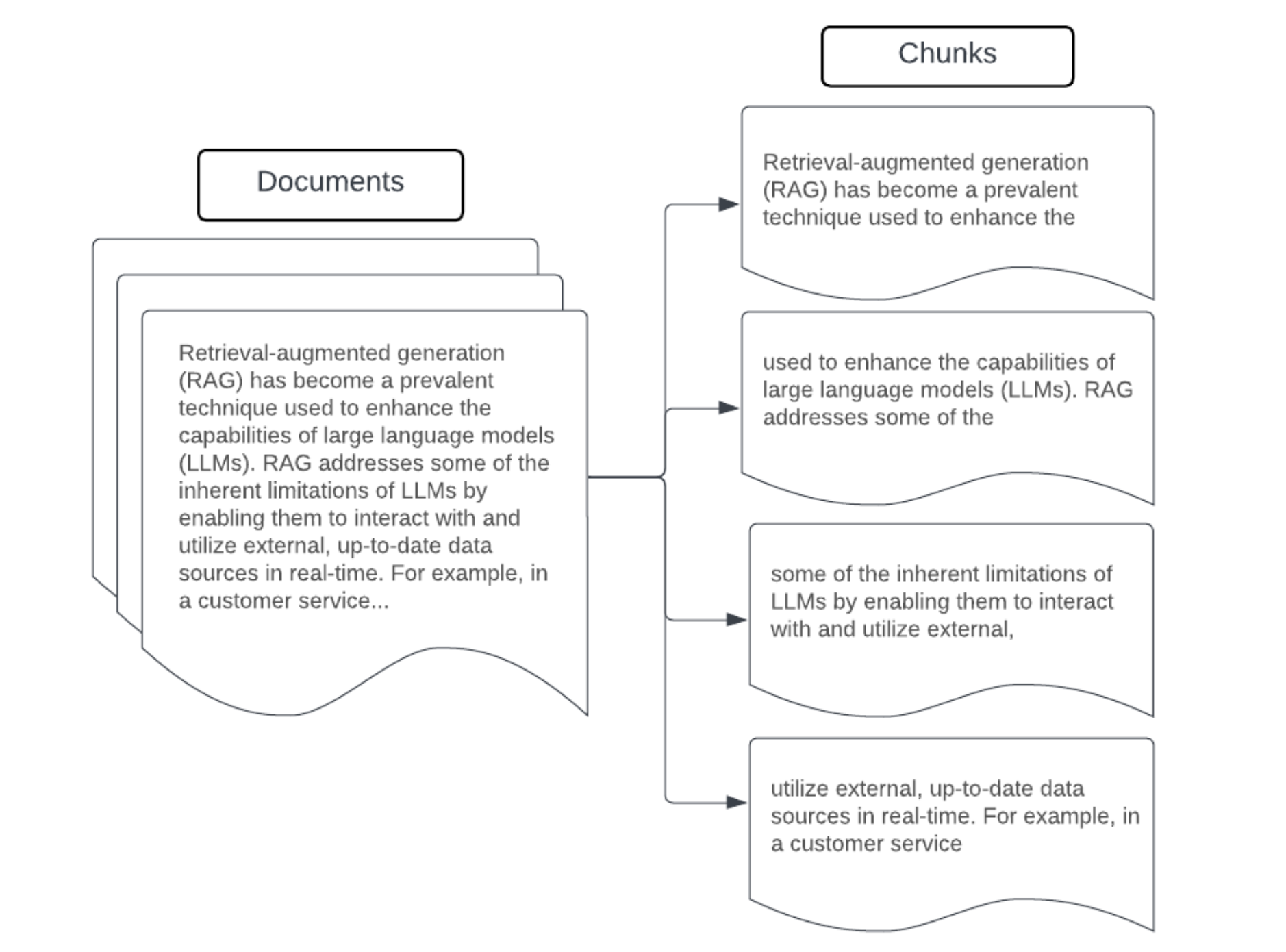
LangChain の RecursiveCharacterTextSplitter を chunk_size=100 と chunk_overlap=20 で使用した固定サイズのチャンクの例。ChunkViz は、Langchainのキャラクタースプリッターを使用して、さまざまなチャンクサイズとチャンクのオーバーラップ値が結果のチャンクにどのように影響するかを視覚化するインタラクティブな方法を提供します。
エンベディング
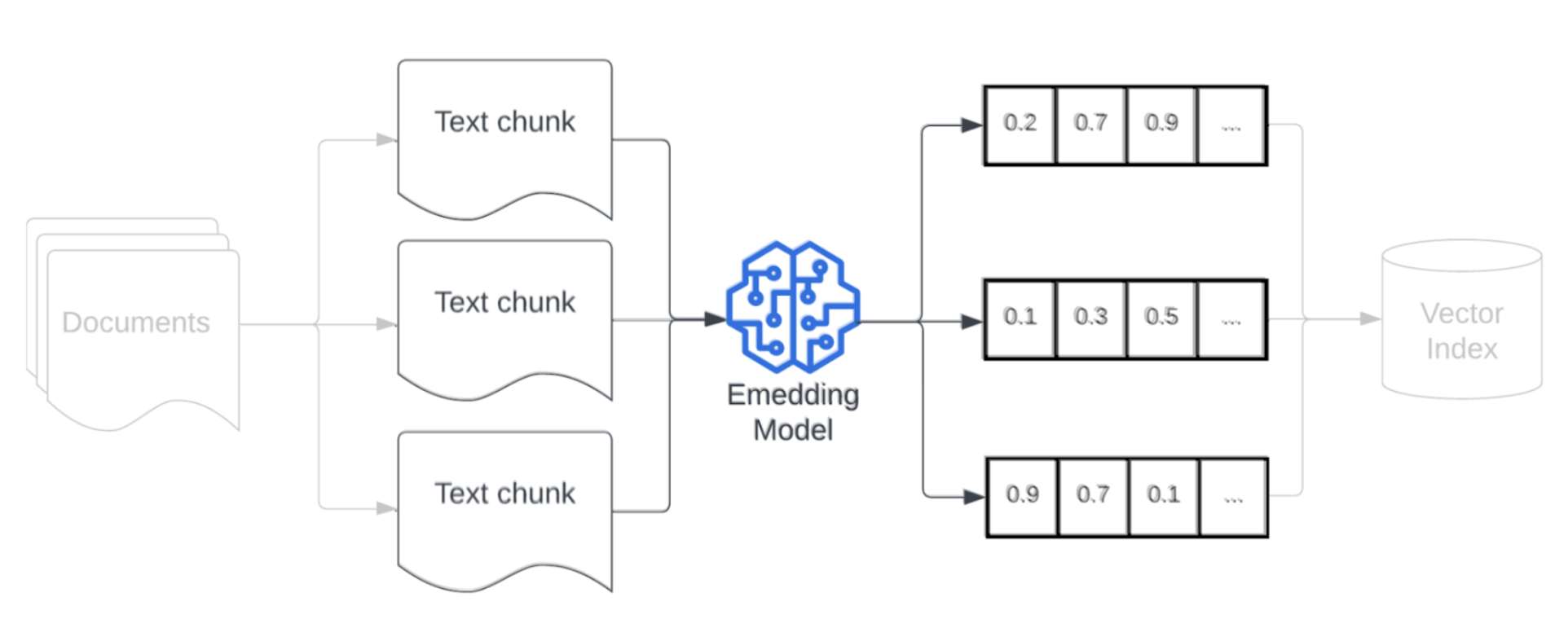
データをチャンク化した後、次のステップは、エンベディングモデルを使用してテキストチャンクをベクトル表現に変換することです。 埋め込みモデルは、各テキスト チャンクを、そのセマンティックな意味をキャプチャするベクトル表現に変換します。 エンベディングでは、チャンクを密なベクトルとして表現することで、検索クエリとの意味的類似性に基づいて、最も関連性の高いチャンクを迅速かつ正確に取得できます。 取得クエリは、データ パイプラインにチャンクを埋め込むために使用されるのと同じエンベディングモデルを使用して、クエリ時に変換されます。
エンベディングモデルを選択するときは、次の要素を考慮してください。
-
モデルの選択: 各埋め込みモデルには微妙な違いがあり、使用可能なベンチマークではデータの特定の特性を捉えていない可能性があります。類似のデータでトレーニングされたモデルを選択することが重要です。また、特定のタスク用に設計された使用可能な埋め込みモデルを調べることも有益です。エクスペリメントは、 MTEBのような標準的なリーダーボードで下位にランクされている可能性のあるものも含めて、さまざまな既製の埋め込みモデルを備えています。 考慮すべきいくつかの例:
-
最大トークン: 選択した埋め込みモデルのトークンの最大制限を把握します。 この制限を超えるチャンクを渡すと、チャンクは切り捨てられ、重要な情報が失われる可能性があります。 たとえば、 bge-large-en-v1.5 の最大トークン制限は 512 です。
-
モデルサイズ: 大規模な埋め込みモデルは、一般的にパフォーマンスが向上しますが、より多くの計算リソースが必要になります。 特定のユースケースと利用可能なリソースに基づいて、パフォーマンスと効率のバランスを取る必要があります。
-
ファインチューニング: RAGアプリケーションがドメイン固有言語(社内の頭字語や用語など)を扱う場合は、ドメイン固有データへの埋め込みモデルをファインチューニングすることを検討してください。 これにより、モデルが特定のドメインのニュアンスや用語をより適切に捉えるのに役立ち、多くの場合、取得パフォーマンスの向上につながります。
インデックス作成とストレージ
パイプラインの次の手順では、前の手順で生成されたエンベディングとメタデータにインデックスを作成します。 この段階では、高次元ベクトルのエンベディングを効率的なデータ構造に整理し、高速で正確な類似検索を可能にします。
Mosaic AI Vector Search では、ベクトル検索エンドポイントとインデックスをデプロイするときに最新のインデックス作成手法を使用して、ベクトル検索クエリの高速かつ効率的な検索を保証します。 最適なインデックス作成手法のテストと選択について心配する必要はありません。
インデックスを作成してデプロイすると、スケーラブルで待機時間の短いクエリをサポートするシステムにインデックスを格納する準備が整います。 大規模なデータセットを持つ本番運用 RAG パイプラインの場合は、ベクトル データベースまたはスケーラブルな検索サービスを使用して、低遅延と高スループットを確保します。 追加のメタデータを埋め込みと共に保存して、取得中の効率的なフィルタリングを可能にします。