ML モデルのライフサイクルのための MLflow
この記事では、Databricks上のMLflowを使用して、高品質の生成AI エージェントと機械学習モデルを開発する方法について説明します。
Databricks を使い始めたばかりの場合は、 Databricks Free Edition で MLflow を試すことを検討してください。
MLflow とは何ですか?
MLflow は、モデルを開発し、アプリケーションを生成するためのオープンソース プラットフォームAI 。 これには、次の主要コンポーネントがあります。
- トラッキング:エクスペリメントを追跡して、パラメーターと結果を記録および比較できます。
- モデル: さまざまな ML ライブラリからさまざまなモデルサービングおよび推論プラットフォームにモデルを管理およびデプロイできます。
- モデルレジストリ: モデルのバージョン管理とアノテーション機能を使用して、ステージングから本番運用までのモデルデプロイプロセスを管理できます。
- AI エージェントの評価とトレース: エージェントの比較、評価、トラブルシューティングを支援することで、高品質の AI エージェントを開発できます。
MLflow は、Java、 Python、R、および REST APIをサポートしています。
MLflow 3
Databricks上のMLflow 3は、Databricksレイクハウスの機械学習モデル、生成AIアプリケーション、エージェントに対する最先端のエクスペリメントの追跡、可観測性、パフォーマンス評価を提供します。Databricks で MLflow 3 を使用すると、次のことができます。
-
開発ノートブックの対話型クエリから本番運用バッチ、またはリアルタイム サービング デプロイまで、すべての環境にわたるモデル、 AI アプリケーション、エージェントのパフォーマンスを一元的に追跡および分析します。
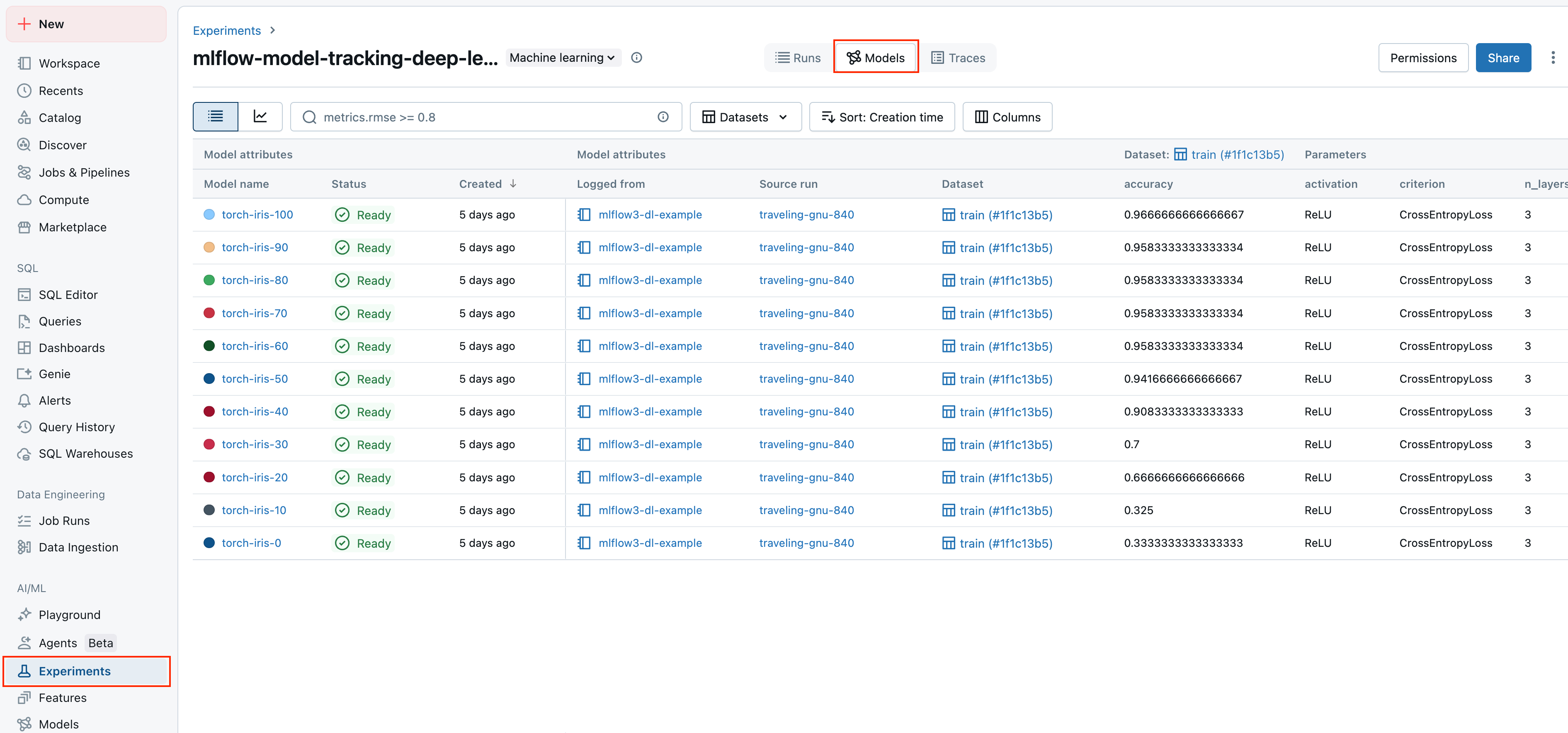
-
Unity Catalog を使用して評価とデプロイのワークフローを調整し、モデル、AI アプリケーション、またはエージェントの各バージョンの包括的なステータスログにアクセスします。
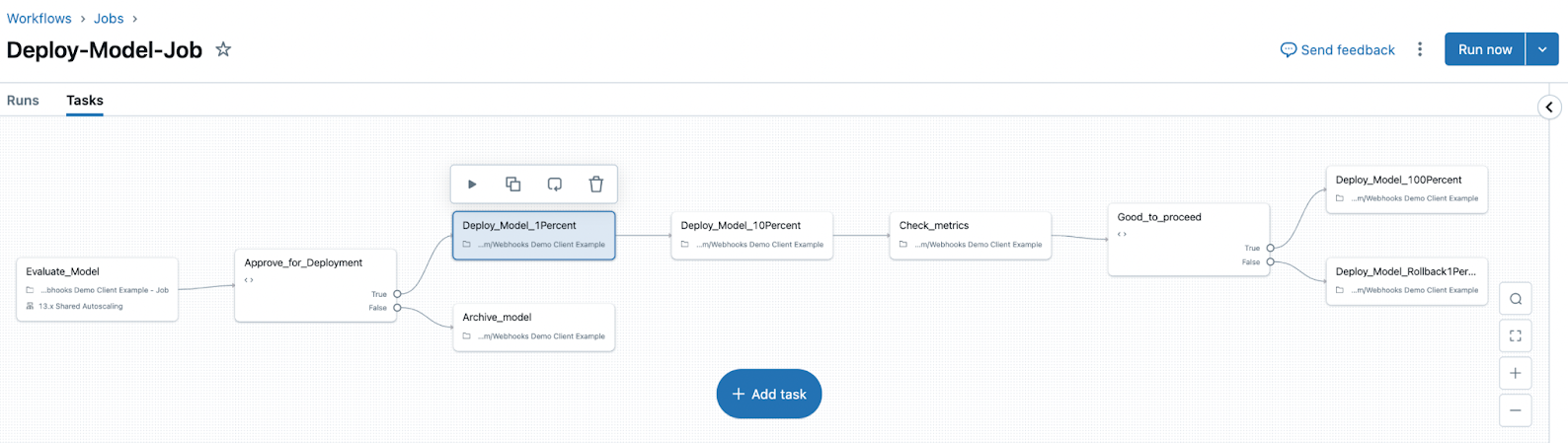
-
Unity Catalog のモデル バージョン ページと REST APIから、モデル メトリクスとパラメーターを表示してアクセスします。
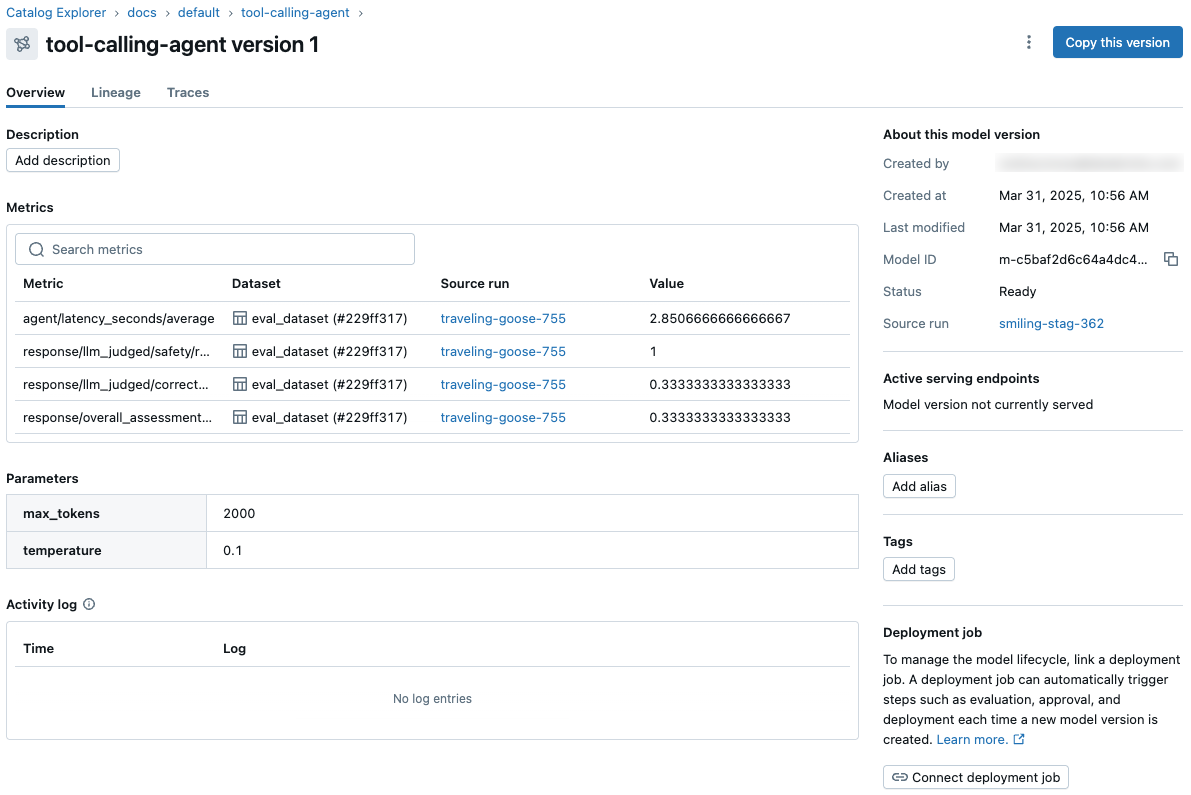
-
すべての 生成AI アプリケーションとエージェントの要求と応答 ( トレース ) に注釈を付け、人間の専門家や自動化された手法 (LLM-as-a-judge など) が豊富なフィードバックを提供できるようにします。このフィードバックを活用して、アプリケーションバージョンのパフォーマンスを評価および比較し、品質を向上させるためのデータセットを構築できます。
![複数のトレースの詳細を示すモデル ページの [トレース] タブ。](/aws/ja/assets/images/model-details-traces-2207f67728bcd54d2d95a640dae97d38.png)
これらの機能により、すべての AI イニシアチブの評価、デプロイ、デバッグ、モニタリングが簡素化および効率化されます。
MLflow 3 では、記録済みモデルとデプロイ ジョブの概念も導入されています。
- 記録済みモデルは 、モデルのライフサイクル全体を通じてモデルの進行状況を追跡するのに役立ちます。
log_model()を使用してモデルをログに記録すると、モデルのライフサイクル全体、さまざまな環境や実行にわたって保持されるLoggedModelが作成され、メタデータ、メトリクス、パラメーター、モデルの生成に使用されたコードなどのアーティファクトへのリンクが含まれます。記録済みモデルを使用すると、モデルを相互に比較し、最もパフォーマンスの高いモデルを見つけ、デバッグ中に情報を追跡できます。 - デプロイ ジョブ は、評価、承認、デプロイなどの手順を含む、モデルのライフサイクルを管理するために使用できます。これらのモデル ワークフローは Unity Catalog によって管理され、すべてのイベントは Unity Catalog のモデル バージョン ページで使用できるアクティビティ ログに保存されます。
MLflow 3 をインストールして使用を開始するには、次の記事を参照してください。
- モデル用の MLflow 3 の使用を開始します。
- MLflow 記録済みモデルを使用してモデルを追跡および比較します。
- MLflow 3によるモデルレジストリの改善。
- MLflow 3 デプロイ ジョブ。
Databricks マネージド MLflow
Databricks は、フルマネージドおよびホスト型の MLflow バージョンを提供し、オープンソースのエクスペリエンスに基づいて構築されているため、エンタープライズでの使用に対してより堅牢でスケーラブルなものになっています。
次の図は、Databricks が MLflow と統合して機械学習モデルをトレーニングおよびデプロイする方法を示しています。
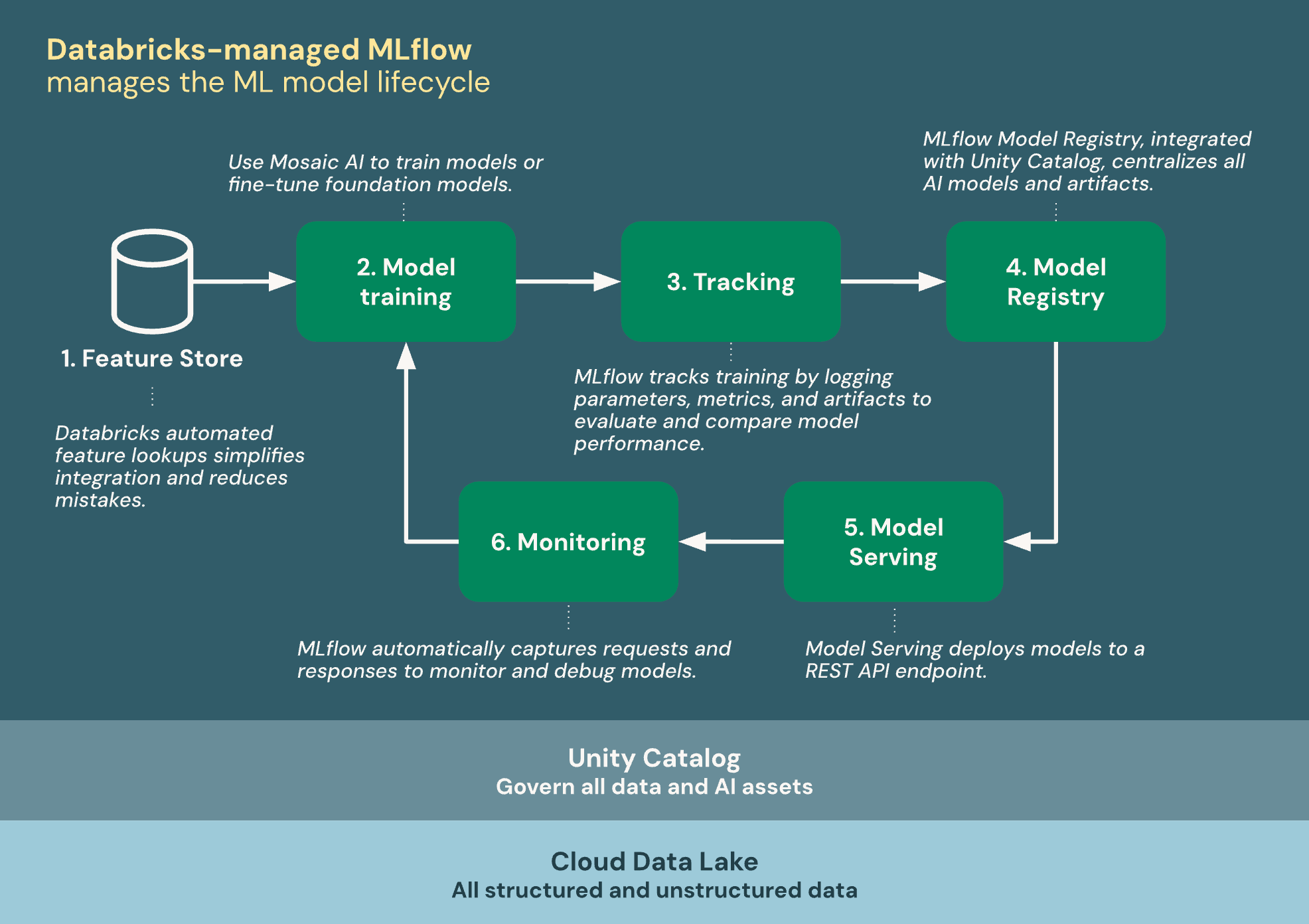
DatabricksマネージドMLflow は、Unity Catalog と クラウドデータレイクを基盤として構築されており、MLライフサイクル内のすべてのデータとAIアセットを統合します。
- 特徴量ストア: Databricks の自動機能検索により、統合が簡素化され、ミスが減ります。
- モデルのトレーニング: Mosaic AIを使用してモデルをトレーニングしたり、基盤モデルをファインチューンしたりします。
- トラッキング : MLflow は、パラメーター、メトリクス、アーティファクトをログに記録してトレーニングを追跡し、モデルのパフォーマンスを評価および比較します。
- モデルレジストリ: Unity Catalogと統合されたMLflowモデルレジストリはAIモデルとアーティファクトを一元管理します。
- モデルサービング: Mosaic AI Model Serving は、モデルを REST API エンドポイントにデプロイします。
- モニタリング: Mosaic AI Model Serving は、モデルの監視とデバッグのためのリクエストとレスポンスを自動的にキャプチャします。 MLflow は、要求ごとにトレース データを使用してこのデータを補強します。
モデルトレーニング
MLflow モデルは、Databricks での AI と ML 開発の中核をなすものです。 MLflow モデルは、機械学習モデルをパッケージ化し、AI エージェントを生成するための標準化された形式です。 標準化された形式により、モデルとエージェントを Databricks のダウンストリーム ツールとワークフローで使用できます。
- MLflow のドキュメント - モデル。
Databricks には、さまざまな種類の ML モデルのトレーニングに役立つ機能が用意されています。
エクスペリメント トラッキング
Databricks では MLflow エクスペリメントを組織単位として使用して、モデルの開発中に作業を追跡します。
エクスペリメント追跡を使用すると、機械学習トレーニングおよびエージェント開発中に、パラメーター、メトリクス、アーティファクト、およびコードのバージョンをログに記録および管理できます。 ログをエクスペリメントに整理して実行すると、モデルの比較、パフォーマンスの分析、反復処理が容易になります。
- Databricksを用いたエクスペリメント トラッキング。
- 実行とエクスペリメントの追跡 に関する一般的な情報については、 MLflowのドキュメントを参照してください。
Unity Catalogのモデルレジストリ
MLflowモデルレジストリは、モデルデプロイプロセスを管理するための一元化されたモデルリポジトリ、UI、および API のセットです。
Databricks は、モデルレジストリと Unity Catalog を統合して、モデルのガバナンスを一元化します。 Unity Catalog 統合により、ワークスペース全体でモデルにアクセスしたり、モデルのリネージを追跡したり、再利用するモデルを見つけたりすることができます。
- Databricks Unity Catalog を使用してモデルを管理します。
- MLflowの一般的な情報についてはModel Registry ドキュメントを参照してください。
モデルサービング
Databricks モデルサービングは MLflow Model Registry と緊密に統合されており、 AI モデルのデプロイ、管理、クエリのための統一されたスケーラブルなインターフェイスを提供します。 提供する各モデルは、Web アプリケーションまたはクライアント アプリケーションに統合できる REST API として使用できます。
これらは異なるコンポーネントですが、モデルサービングは、モデルのバージョン管理、依存関係の管理、検証、ガバナンスの処理を MLflow Model Registry に大きく依存しています。
AIエージェントの開発と評価
AI エージェント開発の場合、Databricks は ML モデル開発と同様に MLflow と統合されます。 ただし、いくつかの重要な違いがあります。
- Databricksで エージェントを作成するには、エージェント コード、パフォーマンス メトリクス、およびエージェント AIトレース を追跡するためにMLflowを活用するMosaic AI エージェント フレームワーク を使用します。
- Databricks でエージェントを評価するには、MLflow に依存して評価結果を追跡する Mosaic AI エージェント評価を使用します。
- エージェントのMLflow追跡には、MLflow Tracingも含まれます。MLflow Tracing では、エージェントのサービスの実行に関する詳細な情報を確認できます。 トレースでは、リクエストの各中間ステップに関連付けられた入力、出力、メタデータが記録されるため、エージェントの予期しない動作の原因をすばやく見つけることができます。
次の図は、Databricks が MLflow と統合して AI エージェントを作成およびデプロイする方法を示しています。
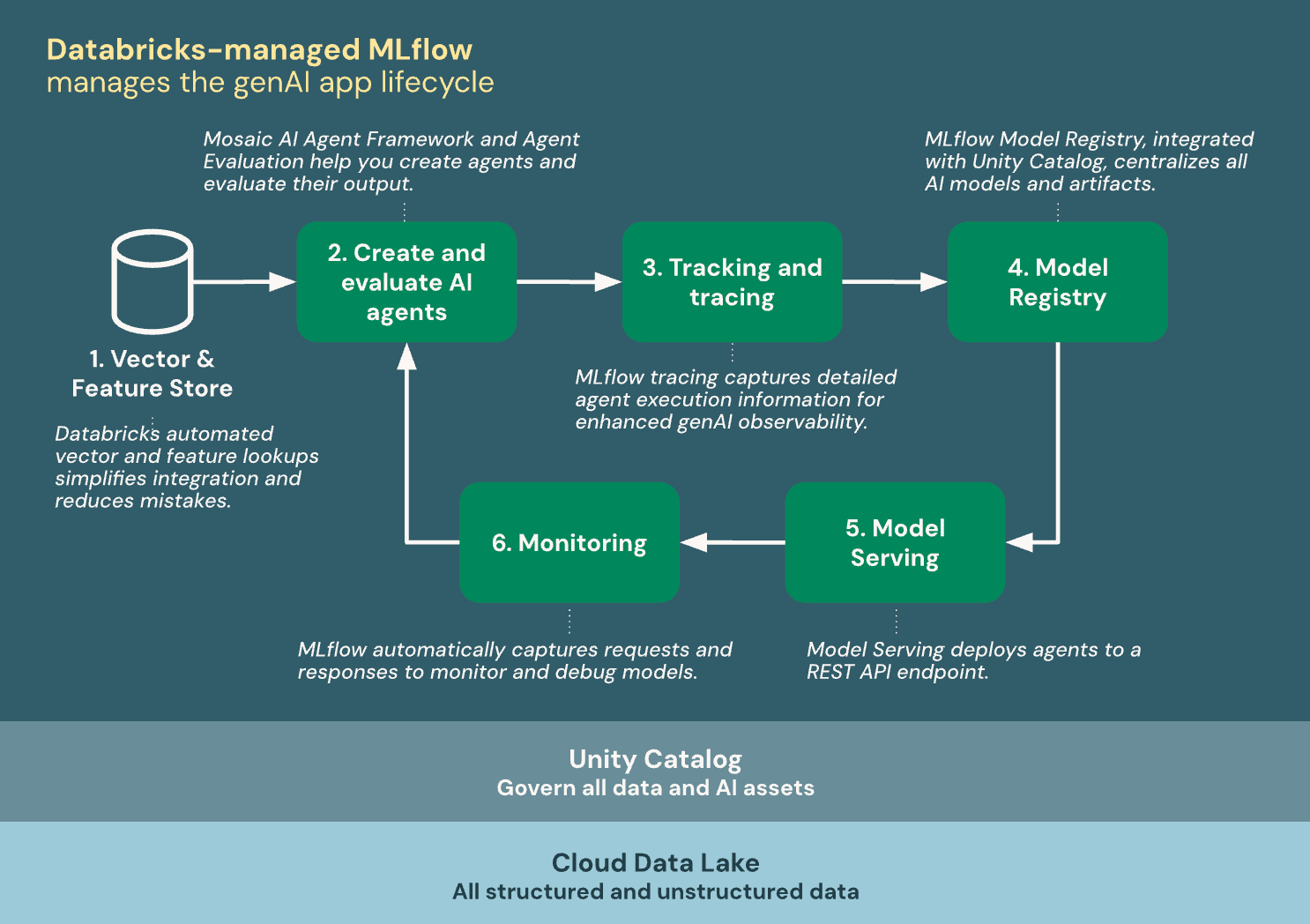
Databricksマネージド MLflow は、 Unity Catalog と クラウドデータレイクに基づいて構築されており、生成AI アプリのライフサイクル内のすべてのデータと AI アセットを統合します。
- ベクトル&フィーチャストア: Databricks のベクトルと特徴の自動ルックアップにより、統合が簡素化され、ミスが減ります。
- AIエージェントの作成と評価: Mosaic AI Agent Framework と Agent Evaluation は、エージェントを作成し、その出力を評価するのに役立ちます。
- トラッキングとトレーシング: MLflowトレーシングは、生成AIオブザーバビリティを強化するための詳細なエージェント実行情報をキャプチャします。
- モデルレジストリ: Unity Catalogと統合されたMLflowモデルレジストリはAIモデルとアーティファクトを一元管理します。
- モデルサービング: Mosaic AI Model Serving は、モデルを REST API エンドポイントにデプロイします。
- モニタリング: MLflow は、モデルを監視およびデバッグするための要求と応答を自動的にキャプチャします。
オープンソース vs. DatabricksマネージドのMLflowの機能
一般的な MLflow の概念、 API、およびオープンソース版と Databricksマネージド版で共有される機能については、 MLflow ドキュメントを参照してください。 Databricksマネージド MLflow専用の機能については、Databricksドキュメントを参照してください。
次の表は、オープンソース MLflow と Databricksマネージド MLflow の主な違いと、詳細の学習に役立つドキュメント リンクを示しています。
機能 | オープンソース MLflow で入手可能 | Databricks マネージド MLflow での可用性 |
|---|---|---|
セキュリティ | ユーザーは、独自のセキュリティガバナンスレイヤーを提供する必要があります | |
災害復旧 | 利用不可 | |
実験の追跡 | MLflow Tracking APIはDatabricksの高度なエクスペリメントトラッキングと統合されています | |
モデルレジストリ | ||
Unity Catalogの統合 | Unity Catalog とのオープンソース統合 | |
モデルのデプロイ | 外部サービスソリューション(SageMaker、Kubernetes、コンテナサービスなど)とのユーザー設定の統合 | Databricks モデルサービング と外部サービングソリューション |
AIエージェント | MLflow LLM 開発と Mosaic AI エージェント フレームワークおよびエージェント評価の統合 | |
暗号化 | 利用不可 | 顧客管理のキーを使用した暗号化 |
オープンソース telemetry collection は MLflow 3.2.0 で導入されましたが、 デフォルト によって Databricks で無効 になります。 詳細については、 MLflow の使用状況追跡に関するドキュメントを参照してください。