専用のコンピュートによるきめ細かなアクセス制御
きめ細かなアクセス制御により、ビュー、行フィルター、および列マスクを使用して、特定のデータへのアクセスを制限できます。このページでは、サーバレス コンピュートを使用して、専用のコンピュート リソースに対してきめ細かなアクセス制御を適用する方法について説明します。
専用コンピュートは、 専用 アクセスモード(旧シングルユーザーアクセスモード)で構成された汎用またはジョブコンピュートです。 アクセスモードを参照してください。
必要条件
専用のコンピュートを使用して、きめ細かなアクセス制御でビューまたはテーブルをクエリするには:
- 専用のコンピュート リソースは、 Databricks Runtime 15.4 LTS 以降に存在する必要があります。
- サーバレス コンピュートのワークスペースを有効にする必要があります。
専用のコンピュート リソースとワークスペースがこれらの要件を満たしている場合、データ フィルタリングは自動的に実行されます。
専用コンピュートでのデータフィルタリングの仕組み
クエリがきめ細かなアクセス制御を使用してデータベースオブジェクトにアクセスするたびに、専用のコンピュートリソースがクエリをワークスペースのサーバレスコンピュートに渡して、データフィルタリングを実行します。 フィルタリングされたデータは、ワークスペース内部クラウドストレージ上の一時ファイルを使用して、サーバレスと専用コンピュート間で転送されます。
、一時的な結果セットを内部ワークスペース ストレージDatabricks (ワークスペースのDBFSルート)に書き込む機能である Cloud Fetch を使用して、フィルタリングされたデータを転送します。Databricks はこれらのファイルを自動的にガベージ コレクションし、24 時間後に削除対象としてマークし、さらに 24 時間後に完全に削除します。
DBFSルートでS3バケットのバージョン管理を有効にすると、 Databricks一時結果セットの古いバージョンのガベージ コレクションを実行できなくなります。 これにより、最新ではないファイル バージョンが蓄積され、ストレージが急激に増加する可能性があります。設定の推奨事項については、 S3 バケットのバージョン管理に関する考慮事項を参照してください。
この機能は、次のデータベースオブジェクトに適用されます。
- ダイナミック ビュー
- 行フィルターまたは列マスクを持つテーブル
- ユーザーが
SELECT権限を持っていないテーブルに対して構築されたビュー - マテリアライズドビュー
- ストリーミングテーブル
次の図では、ユーザーは table_1、 view_2、および table_w_rlsに対する SELECT 権限を持ち、行フィルターが適用されています。ユーザーには、 view_2によって参照される table_2に対する SELECT 権限がありません。
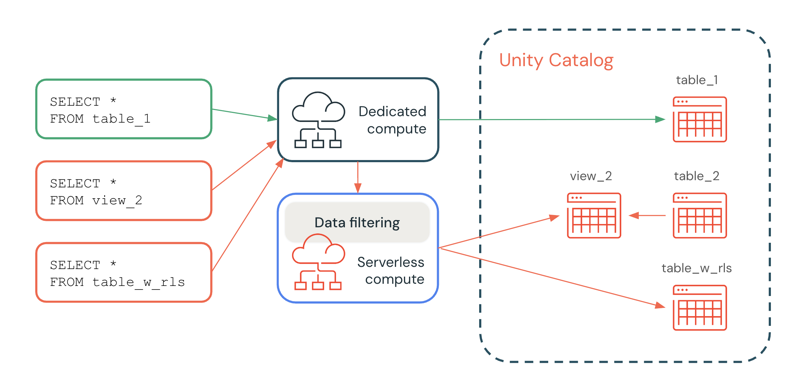
table_1 に対するクエリは、フィルター処理が不要なため、専用のコンピュート リソースによって完全に処理されます。view_2 と table_w_rls のクエリでは、ユーザーがアクセスできるデータを返すためにデータ フィルタリングが必要です。これらのクエリは、サーバレス コンピュートのデータ フィルタリング機能によって処理されます。
書き込み操作のサポート
プレビュー
この機能は パブリック プレビュー段階です。
Databricks Runtime 16.3 以降では、次のオプションを使用して、行フィルターまたは列マスクが適用されているテーブルに書き込むことができます。
- MERGE INTO SQL コマンド (これを使用して、
INSERT、UPDATE、およびDELETEの機能を実現できます。 - Deltaマージ操作。
DataFrame.write.mode("append")API。
INSERT、UPDATE、および DELETE の機能を実現するには、ステージング テーブルと MERGE INTO ステートメントの WHEN MATCHED 句と WHEN NOT MATCHED 句を使用できます。
次に、MERGE INTOを使用したUPDATEの例を示します。
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET
t.column1 = s.column1,
t.column2 = s.column2;
次に、MERGE INTO を使用した INSERT の例を示します。
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN NOT MATCHED THEN
INSERT (id, column1, column2) VALUES (s.id, s.column1, s.column2);
次に、MERGE INTO を使用した DELETE の例を示します。
MERGE INTO target_table AS t
USING source_table AS s ON t.id = s.id
WHEN MATCHED AND s.some_column = TRUE THEN DELETE;
DDL、SHOW、DESCRIBE、およびその他のコマンドのサポート
Databricks Runtime 17.1 以降では、次のコマンドを、専用コンピュートのきめ細かなアクセス制御オブジェクトと組み合わせて使用できます。
- DDLステートメント
- 表示関連のステートメント
- DESCRIBEステートメント
- OPTIMIZE
- 履歴の説明
- FSCK REPAIR TABLE (Databricks Runtime 17.2 以降)
必要に応じて、これらのコマンドはサーバレス コンピュートで自動的に実行されます。
VACCUM、RESTORE、REORG TABLE など、一部のコマンドはサポートされません。
サーバレス コンピュートのコスト
お客様は、データ フィルタリング操作を実行するサーバレス コンピュート リソースに対して課金されます。 価格 情報については、 プラットフォーム階層とアドオン を参照してください。
アクセス権を持つユーザーは、 system.billing.usage テーブルをクエリして、請求された金額を確認できます。たとえば、次のクエリは、コンピュートのコストをユーザー別に分類します。
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
このクエリは、きめ細かなアクセス制御 (FGAC) の使用にかかるコストを表示しますが、蓄積された一時結果ファイルのストレージ コストは含めません。 S3 バケットのバージョン管理が有効になっている場合、最新ではないファイルバージョンは標準の課金クエリにカウントされませんが、ストレージ料金は発生します。
データフィルタリングが行われているときのクエリパフォーマンスの表示
専用コンピュートの Spark UI には、クエリのパフォーマンスを理解するために使用できるメトリクスが表示されます。 コンピュート リソースで実行するクエリごとに、 SQL/Dataframe タブにクエリ グラフ表現が表示されます。 クエリがデータ フィルター処理に関係している場合、UI のグラフの下部に RemoteSparkConnectScan 演算子ノードが表示されます。このノードには、クエリのパフォーマンスを調査するために使用できるメトリクスが表示されます。 「 Spark UIでのコンピュート情報の表示」を参照してください。
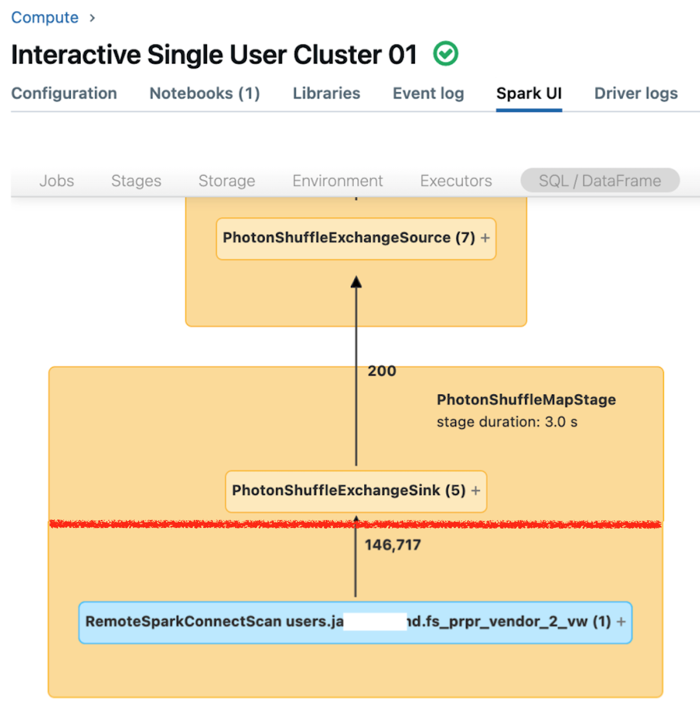
RemoteSparkConnectScan 演算子ノードを展開して、次のような質問に対処するメトリクスを表示します。
- データのフィルタリングにはどのくらいの時間がかかりましたか? 「total remote execution time」を参照します。
- データフィルタリング後にはいくつの行が残っていましたか? 「rows output」を参照します。
- データ フィルタリング後に返されたデータの量 (バイト単位) はどれくらいですか? 「rows output size」を表示します。
- パーティションプルーニングされ、ストレージから読み取る必要がなかったデータファイルはいくつありますか? 「Files pruned」と「Size of files pruned」を表示します。
- プルーニングできず、ストレージから読み取らなければならなかったデータ・ファイルはいくつありますか。 「Files read」と「Size of files read」を表示します。
- 読み取る必要があったファイルのうち、キャッシュにすでにいくつありましたか? 「Cache hits size」および「Cache misses size」を表示します。
制限
-
ストリーミングテーブルでは、バッチ読み取りのみがサポートされます。行フィルターまたは列マスクを持つテーブルは、専用のコンピュートでのストリーミングワークロードをサポートしていません。
-
デフォルトのカタログ(
spark.sql.catalog.spark_catalog)は変更できません。 -
Databricks Runtime 16.2 以前では、行フィルターまたは列マスクが適用されているテーブルに対するテーブルの書き込みまたは更新操作はサポートされていません。
具体的には、
INSERT、DELETE、UPDATE、REFRESH TABLE、MERGEなどの DML 操作はサポートされていません。これらのテーブルからのみ (SELECT) を読み取ることができます。 -
Databricks Runtime 16.3 以降では、
INSERT、DELETE、UPDATEなどのテーブル書き込み操作はサポートされていませんが、サポートされているMERGEを使用して実行できます。 -
FGAC 対応テーブルの専用コンピュートで
DeltaTable.forName()またはDeltaTable.forPath()を使用する場合、merge()およびtoDF()操作のみがサポートされます。 その他の DeltaTable 操作については、代わりに対応する SQL コマンドを使用します。たとえば、history()の代わりにDESCRIBE HISTORYを使用し、clone()の代わりにSHALLOW CLONEまたはDEEP CLONE使用します。 -
Databricks Runtime 16.2 以前では、データフィルタリングが呼び出されると、これらのクエリが同じリモートテーブルの異なるスナップショットを返す可能性があるため、自己結合はデフォルトによってブロックされます。ただし、これらのコマンドを実行しているコンピュートで
spark.databricks.remoteFiltering.blockSelfJoinsをfalseに設定することで、これらのクエリを有効にすることができます。Databricks Runtime 16.3 以降では、スナップショットは dedicated リソースとサーバレス コンピュート リソース間で自動的に同期されます。この同期により、データ・フィルタリング機能を使用する自己ジョイン・クエリは同一のスナップショットを返し、デフォルトで有効になります。例外は、マテリアライズドビューと任意のビュー、マテリアライズドビュー、および Delta Sharingを使用して共有されるストリーミングテーブルです。 これらのオブジェクトの場合、自己結合はデフォルトによってブロックされますが、これらのコマンドを実行しているコンピュートで
spark.databricks.remoteFiltering.blockSelfJoinsを false に設定することで、これらのクエリを有効にできます。マテリアライズドビューと任意のビュー、マテリアライズドビュー、およびストリーミングテーブルに対して自己結合クエリを有効にする場合は、結合されるオブジェクトへの並列書き込みがないことを確認する必要があります。
-
Dockerイメージはサポートされていません。
-
Databricks Container Services の使用には対応していません。
-
ワークスペースが 2024 年 11 月より前にファイアウォールを使用してデプロイされた場合は、ポート 8443 と 8444 を開いて、専用のコンピュートできめ細かなアクセス制御を有効にする必要があります。 セキュリティグループを参照してください。