レイクハウスプラットフォームの範囲
最新のデータおよびAIプラットフォームのフレームワーク
Databricksデータインテリジェンスプラットフォームの範囲について説明するには、まず最新のデータおよびAIプラットフォームの基本的なフレームワークを定義すると役立ちます。
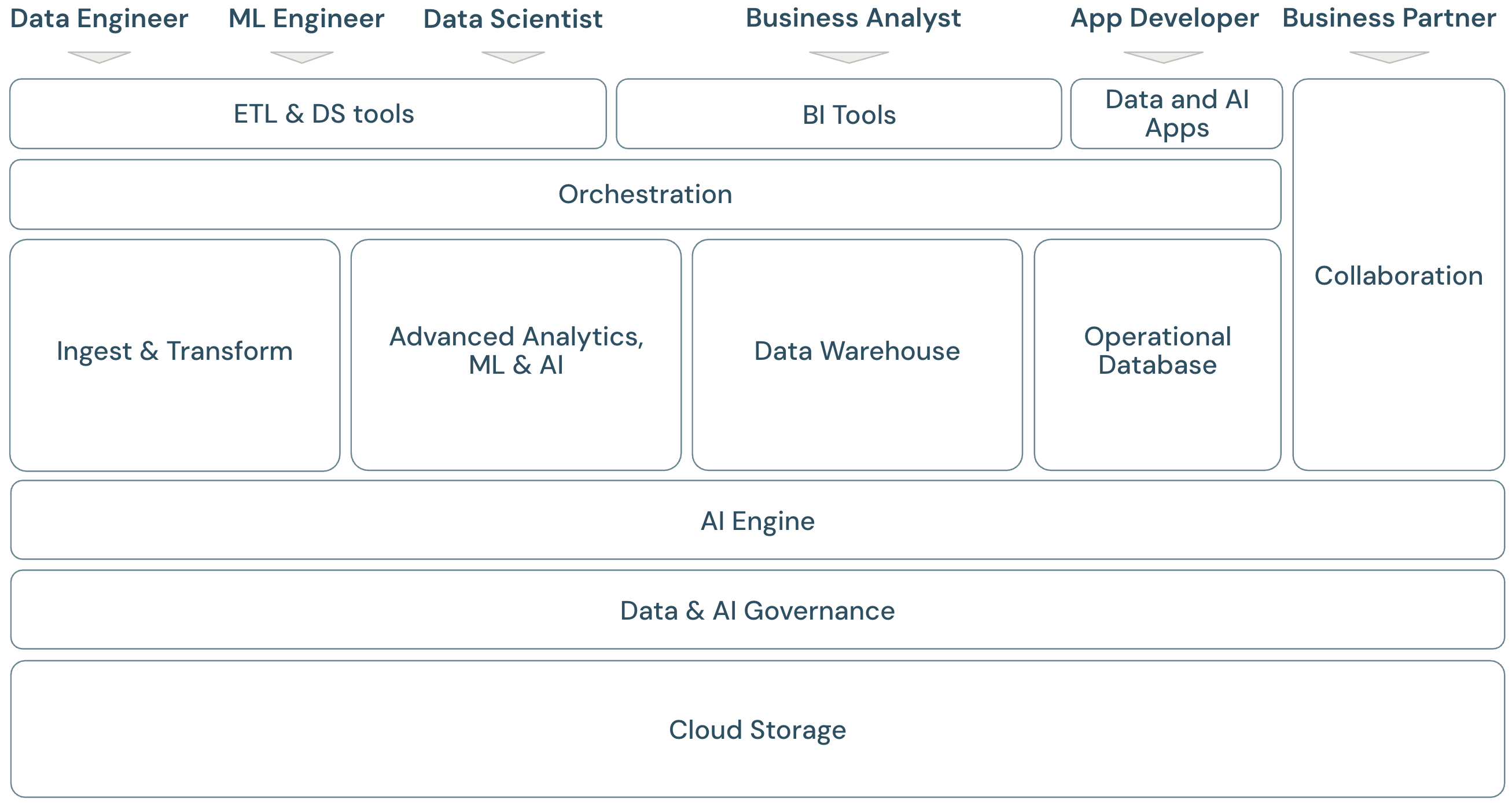
レイクハウススコープの概要
Databricksデータインテリジェンスプラットフォームは、最新のデータプラットフォームフレームワークに完全対応しています。レイクハウス上に構築されており、データの独自性を理解するためのデータインテリジェンスエンジンを搭載しています。これは、ETL、ML/AI、DWH/BIワークロード向けのオープンで統合された基盤であり、Unity Catalogを一元化データおよびAIガバナンスソリューションとして備えています。
プラットフォームフレームワークのペルソナ
このフレームワークは、フレームワーク内のアプリケーションを扱う主要なデータチームメンバー(ペルソナ)を対象としています。
- データエンジニア は、データサイエンティストやビジネスアナリストに正確で再現性のあるデータを提供し、タイムリーな意思決定を行い、リアルタイムの知見が得られるようにします。一貫性と信頼性の高いETLプロセスを導入することで、データに対するユーザーの信頼と信用を高めています。データがビジネスのさまざまな柱とうまく統合されていることを確認し、通常はソフトウェアエンジニアリングのベストプラクティスに従います。
- データサイエンティスト は、分析の専門知識とビジネスの理解を組み合わせて、データを戦略的知見と予測モデルに変換します。彼らは、遡及的な分析的知見や将来を見据えた予測モデリングなどを通じて、ビジネス上の課題をデータ主導のソリューションに変換することに長けています。データモデリングと機械学習技術を活用して、データからパターン、傾向、予測を明らかにするモデルを設計、開発、展開します。これらは橋渡しの役割を果たし、複雑なデータの物語をわかりやすいストーリーに変換します。これにより、ビジネス関係者はデータに基づく推奨事項を理解するだけでなく、それに基づいて行動できるようになります。その結果、組織内の問題解決に対するデータ中心のアプローチが推進されます。
- MLエンジニア (機械学習エンジニア)は、機械学習モデルの構築・デプロイ・保守を通じて、製品やソリューションにおけるデータサイエンスの実用化をリードしています。彼らの主な焦点は、モデルの開発とデプロイのエンジニアリング側面に軸足を移しています。ML エンジニアは、ライブ環境での機械学習システムの堅牢性、信頼性、スケーラビリティを確保し、データの品質、インフラストラクチャ、パフォーマンスに関連する課題に対処します。AIとMLモデルを運用ビジネスプロセスやユーザー向け製品に統合することで、ビジネス課題の解決におけるデータサイエンスの活用を促進し、モデルが研究にとどまらず、具体的なビジネス価値を促進するようにします。
- ビジネスアナリスト と ビジネスユーザー : ビジネスアナリストは、ステークホルダーとビジネスチームに実用的なデータを提供します。 多くの場合、データを解釈し、標準のBIツールを使用して管理用のレポートやその他のドキュメントを作成します。 通常、技術者以外のビジネスユーザーや運用担当者が分析に関する質問を迅速に行うための最初の窓口となります。 Databricks プラットフォーム上で提供されるダッシュボードとビジネスアプリは、ビジネスユーザーが直接使用できます。
- Apps Developer は、データプラットフォーム上で安全なデータとAIアプリケーションを作成し、それらのアプリをビジネスユーザーと共有します。
- ネットワーク化が進むビジネス界において、 ビジネスパートナー は重要なステークホルダーです。ビジネスパートナーとは、共通の目標を達成するために企業が正式な関係を持つ企業または個人と定義されます。これにはベンダー、サプライヤー、代理店、その他の第三者パートナーが含まれます。データ共有はビジネスパートナーシップの重要な側面です。データの転送と交換を可能にすることで、コラボレーションとデータドリブンの意思決定が強化されます。
プラットフォームフレームワークのドメイン
プラットフォームは複数のドメインで構成されています。
- ストレージ :クラウドでは、データは主に、クラウドプロバイダー上の、スケーラブルで効率的かつ復元力のあるオブジェクトストレージに保存されます。
- ガバナンス :すべてのデータおよびAI資産のアクセス制御、監査、メタデータ管理、リネージトラッキング、モニタリングなど、データガバナンスに関する機能です。
- AIエンジン :AIエンジンは、プラットフォーム全体に生成AI機能を提供します。
- 取り込みと変換: ETL ワークロードの機能。
- アドバンスド アナリティクス, ML, AI: 機械学習、 AI、生成AI、およびストリーミング分析に関するすべての機能。
- データウェアハウス: DWH と BI のユースケースをサポートするドメイン。
- 運用データベース: OLTPデータベース(オンライントランザクション処理)、キーバリューストアなどの運用データベースに関する機能とサービス。
- 自動化: データ処理、機械学習、アナリティクス パイプライン ( CI/CD および MLOps のサポートを含む) のワークフロー管理。
- ETLおよびデータサイエンスツール: データエンジニアやdata scientists、MLエンジニアが主に業務で使うフロントエンドツール。
- BIツール: BIアナリストが主に仕事に使用するフロントエンドツール。
- データおよび AI アプリ 基盤となるプラットフォームによって管理されるデータを使用し、その分析機能と AI 機能を安全でガバナンスに準拠した方法で活用するアプリケーションを構築およびホストするツール。
- コラボレーション :2人以上の関係者間でデータを共有する機能。
Databricks プラットフォームの範囲
Databricks Data Intelligence Platformとそのコンポーネントは、次のようにフレームワークにマッピングできます。
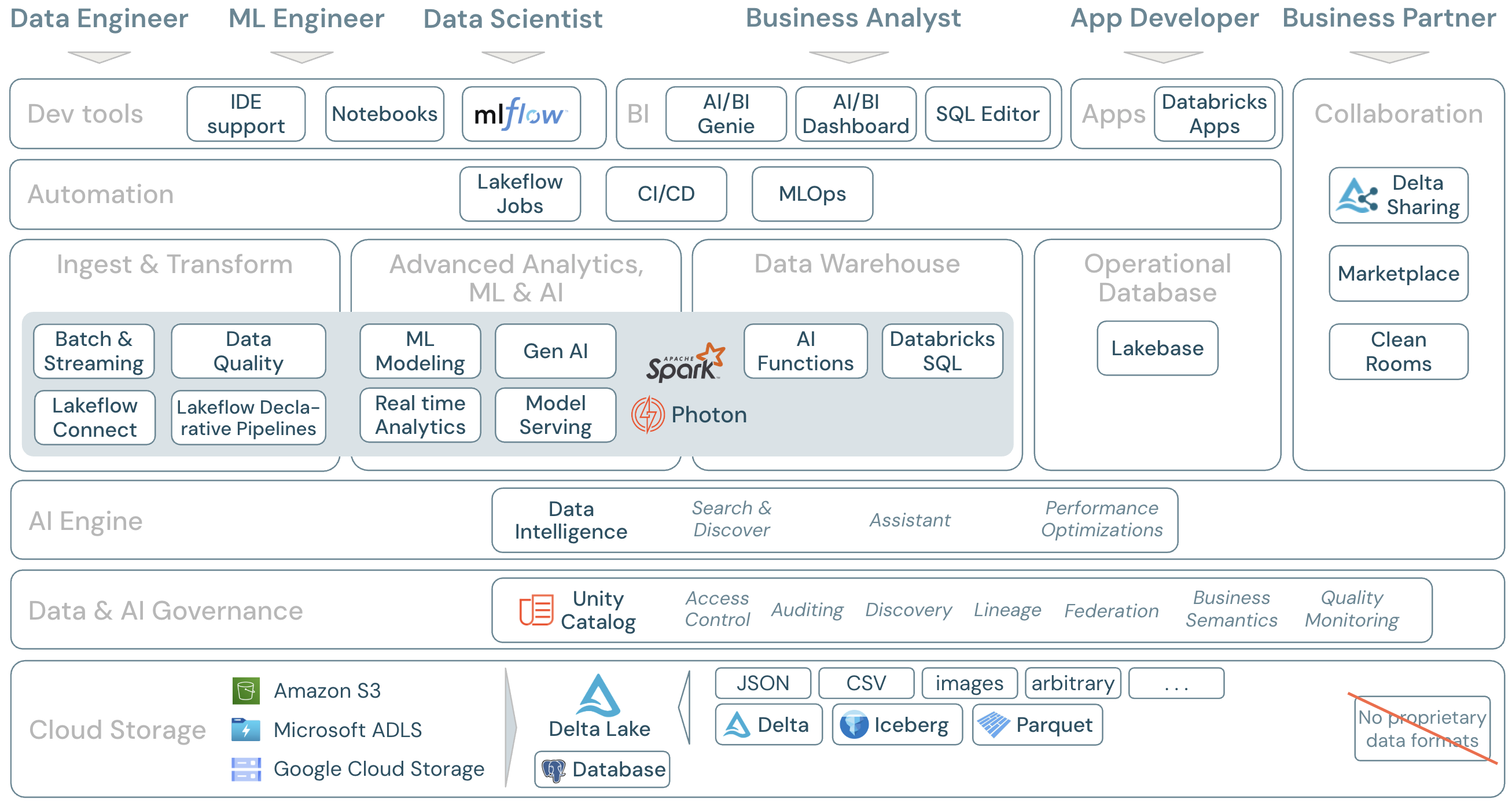
ダウンロード:レイクハウスのスコープ - Databricksコンポーネント
Databricks 上のデータワークロード
最も重要なことは、Databricks Data Intelligence Platform は、 Apache Spark/Photon をエンジンとして、データドメインに関連するすべてのワークロードを 1 つのプラットフォームでカバーすることです。
-
取り込みと変換
Databricks では、データ取り込みの方法をいくつか提供しています。
- Databricks Lakeflow Connect 、エンタープライズ アプリケーションやデータベースから取り込むための組み込みコネクタを提供します。 結果として得られる取り込みパイプラインはUnity Catalogによって管理され、サーバレス コンピュートとLakeflow Spark宣言型パイプラインによって強化されます。
- Auto Loader は、スケジュールされたジョブまたは継続的なジョブでクラウド ストレージに到着するファイルを段階的かつ自動的に処理します。状態情報を管理する必要はありません。取り込んだ生データを変換して、BIとML/AIに対応できるようにする必要があります。DatabricksETLは、データエンジニア、data scientists 、およびアナリスト向けの強力な 機能を提供します。
Lakeflow Spark宣言型パイプラインを使用すると、宣言的な方法でETLジョブを作成できるため、実装プロセス全体が簡素化されます。 データの期待値を定義することでデータの品質を向上させることができます。
-
高度な分析、ML、AI
このプラットフォームには、 Databricks Mosaic AI AI従来のマシンラーニングとディープラーニング 用の完全に統合された機械学習および ツールのセットである 、および生成AI および大規模言語モデル(LLM) が含まれています。データの準備から機械学習モデルやディープラーニングモデルの構築、Mosaic AI Model Servingまでのワークフロー全体をカバーしています。
Spark構造化ストリーミングとLakeflow Spark宣言型パイプラインにより、リアルタイム分析が可能になります。
-
データウェアハウス
Databricks Data Intelligence Platform には、 Databricks SQL を備えた完全なデータウェアハウスソリューションもあり、 Unity Catalog によって一元管理され、きめ細かなアクセス制御が可能です。
AI 関数は 、SQL から直接データに AI を適用できる組み込みの SQL 関数です。AIを分析ジョブに統合することで、アナリストはこれまでアクセスできなかった情報にアクセスできるようになり、データドリブンなイノベーションと効率性を通じて、より多くの情報に基づいた意思決定を行い、リスクを管理し、競争上の優位性を維持できるようになります。
-
運用データベース
Lakebase は、Postgres をベースとし、Databricks Data Intelligence Platform と完全に統合されたオンライン トランザクション処理 (OLTP) データベースです。これにより、Databricks 上に OLTP データベースを作成し、OLTP ワークロードをレイクハウスと統合できます。Lakebaseは、OLTPとオンライン分析処理(OLAP)ワークロード間でデータを同期することができ、 機能管理、 SQLウェアハウス、 Databricksアプリとうまく統合されています。
Databricksの機能領域の概要
これは、Databricksデータインテリジェンスプラットフォームの機能を、フレームワークの他のレイヤーに下から上にマッピングしたものです。
-
クラウドストレージ
レイクハウスのすべてのデータは、クラウド上でプロバイダーのオブジェクトストレージに保存されます。 Databricks は、AWS、Azure、GCP の 3 つのクラウドプロバイダーをサポートしています。さまざまな構造化形式および半構造化形式 ( Parquet、 CSV、 JSON、 Avroなど) のファイル、および非構造化形式 (画像やドキュメントなど) のファイルは、バッチ プロセスまたはストリーミング プロセスを使用して取り込まれ、変換されます。
Delta Lake は、レイクハウスに推奨されるデータ形式 (ファイル トランザクション、信頼性、一貫性、更新など) です。Apache Iceberg クライアントを使用して Delta テーブルを読み取ることもできます。
Databricks Data Intelligence Platform では独自のデータ形式は使用されていません: Delta Lake と Iceberg は、ベンダーロックインを回避するためにオープンソースです。
-
データとAIのガバナンス
ストレージ層に加えて、Unity Catalogは、メタストアでのメタデータ管理、アクセス制御、監査、データディスカバリー、 データリネージなど、幅広いデータとAIのガバナンス機能を提供します。
データ品質モニタリングは、データとAI資産にすぐに使用できる高品質のメトリクスと、これらのメトリクスを視覚化するための自動生成されたダッシュボードを提供します。
外部 SQL ソースは、 レイクハウス フェデレーションを通じてレイクハウスと Unity Catalog に統合できます。
-
AIエンジン
Data Intelligence Platform は、レイクハウスアーキテクチャに基づいて構築され、 Databricks の AI を活用した機能によって強化されています。Databricks AI は、生成AI とレイクハウス アーキテクチャの統合の利点を組み合わせて、データの一意のセマンティクスを理解します。 インテリジェントな検索と Databricks Assistant は、すべてのユーザーのプラットフォームでの作業を簡素化する AI を活用したサービスの例です。
-
オーケストレーション
Lakeflowジョブを使用すると、あらゆるクラウド上でデータとAIライフサイクル全体にわたって多様なワークロードを実行できます。 これらを使用すると、 SQL 、 Spark 、 ノートブック、 DBT、 MLモデルなどのジョブだけでなく、 Lakeflow Spark宣言型パイプラインも調整できます。
-
ETL & DSツール
消費レイヤーでは、データエンジニアとMLエンジニアは通常、IDEを使用してプラットフォームを操作し ます 。データサイエンティスト 多くの場合、 ノートブック を好み、 ML & AI ランタイムを使用し、機械学習ワークフロー システム MLflow エクスペリメントを追跡し、モデルのライフサイクルを管理します。
-
BIツール
ビジネスアナリストは通常、好みの BI ツールを使用して Databricks データウェアハウスにアクセスします。 Databricks SQL は、さまざまな分析ツールと BI ツールでクエリを実行できます (BI と視覚化を参照)
さらに、このプラットフォームではクエリーと分析ツールをすぐに利用できます。
- AI/BIダッシュボードを使用して、ドラッグアンドドロップでデータの視覚化を行い、知見を共有します。
- データアナリストなどのドメイン専門家は、データセット、サンプル クエリ、テキスト ガイドラインを使用して AI/BI Genieスペース を構成し、ビジネス上の質問を分析クエリに Genie 変換するのに役立ちます。 セットアップ後、ビジネス ユーザーは質問をしたり、運用データを理解するための視覚化を生成したりできます。
- SQLSQLアナリストがデータを分析するためのエディター。
-
データおよびAIアプリ
Databricks Apps を使用すると、開発者は Databricks プラットフォーム上で安全なデータアプリケーションと AI アプリケーションを作成し、それらのアプリをユーザーと共有することができます。
-
コラボレーション
Delta Sharingは、使用するコンピューティングプラットフォームに関係なく、他の組織との安全なデータ共有を行うために、Databricksによって開発されたオープンプロトコルです。
Databricks Marketplace は、データ製品を交換するためのオープンフォーラムです。 Delta Sharingを活用して、データプロバイダーはデータ製品を安全に共有するためのツールを提供し、データ消費者は必要なデータおよびデータサービスへのアクセスを探索して拡大することができます。
クリーンルーム は、 Delta Sharing とサーバレス コンピュートを使用して、複数の関係者が互いのデータに直接アクセスすることなく、機密性の高い企業データに対して協力して作業できる、安全でプライバシー保護の環境を提供します。