DatabricksのShiny
Shiny は CRAN で利用可能な R パッケージで、対話型の R アプリケーションとダッシュボードの構築に使用されます。 クラスターでホストされているRStudio Server 内で Shiny を使用できます。Databricksまた、 Databricks ノートブックから直接 Shiny アプリケーションを開発、ホスト、共有することもできます。
Shiny の使用を開始するには、 Shiny のチュートリアルを参照してください。 これらのチュートリアルは、Databricks ノートブックで実行できます。
この記事では、Databricks で Shiny アプリケーションを実行し、Shiny アプリケーション内で Apache Spark を使用する方法について説明します。
Shiny inside R ノートブック
Shiny inside R ノートブックの使用を開始する
Shiny パッケージは Databricks Runtimeに含まれています。ホストされている RStudio と同様に、Databricks R ノートブック内で Shiny アプリケーションを対話的に開発およびテストできます。
開始するには、次の手順に従ってください。
-
R ノートブックを作成します。
-
Shiny パッケージをインポートし、次のようにサンプル アプリの
01_helloを実行します。Rlibrary(shiny)
runExample("01_hello") -
アプリの準備ができると、新しいタブを開くクリック可能なリンクとして、Shiny アプリの URL が出力に含まれます。 このアプリを他のユーザーと共有するには、「 Shiny アプリの URL を共有する」を参照してください。
- ログ・メッセージは、例に示されているデフォルトのログ・メッセージ(
Listening on http://0.0.0.0:5150)と同様に、コマンド結果に表示されます。 - Shinyアプリケーションを停止するには、 キャンセルをクリックしてください 。
- Shiny アプリケーションは、ノートブックの R プロセスを使用します。 ノートブックをクラスターから切り離すか、アプリケーションを実行しているセルをキャンセルすると、Shiny アプリケーションは終了します。 Shiny アプリケーションの実行中に他のセルを実行することはできません。
Databricks Git フォルダーから Shiny アプリを実行する
Databricks Git フォルダーにチェックインされた Shiny アプリを実行できます。
-
アプリケーションを実行します。
Rlibrary(shiny)
runApp("006-tabsets")
ファイルからの Shiny アプリの実行
Shiny アプリケーション コードがバージョン管理によって管理されるプロジェクトの一部である場合は、ノートブック内で実行できます。
絶対パスを使用するか、作業ディレクトリを setwd()で設定する必要があります。
-
リポジトリからコードをチェックアウトするには、次のようなコードを使用します。
%sh git clone https://github.com/rstudio/shiny-examples.git
cloning into 'shiny-examples'... -
アプリケーションを実行するには、別のセルに次のようなコードを入力します。
Rlibrary(shiny)
runApp("/databricks/driver/shiny-examples/007-widgets/")
ShinyアプリのURLを共有する
アプリの起動時に生成される Shiny アプリの URL は、他のユーザーと共有できます。 クラスターに対する 権限を持つ ユーザーは、アプリとクラスターの両方が実行されている限り、アプリを表示して操作できます。DatabricksCan Attach To
アプリが実行されているクラスターが終了すると、アプリにはアクセスできなくなります。 自動終了は、クラスター設定 で無効に できます。
Shiny アプリをホストしているノートブックを別のクラスターにアタッチして実行すると、Shiny URL が変更されます。 また、同じクラスターでアプリを再起動すると、Shiny は別のランダム ポートを選択する場合があります。 安定した URL を確保するために、オプションを shiny.port 設定するか、同じクラスターでアプリを再起動するときに引数を port 指定できます。
ホストされたRStudioサーバー上の光沢
必要条件
RStudio Server Pro では、プロキシ認証を無効にする必要があります。auth-proxy=1が/etc/rstudio/rserver.conf内に存在しないことを確認してください。
ホスト型RStudioサーバーでShinyを使い始める
-
Databricks で RStudio を開きます。
-
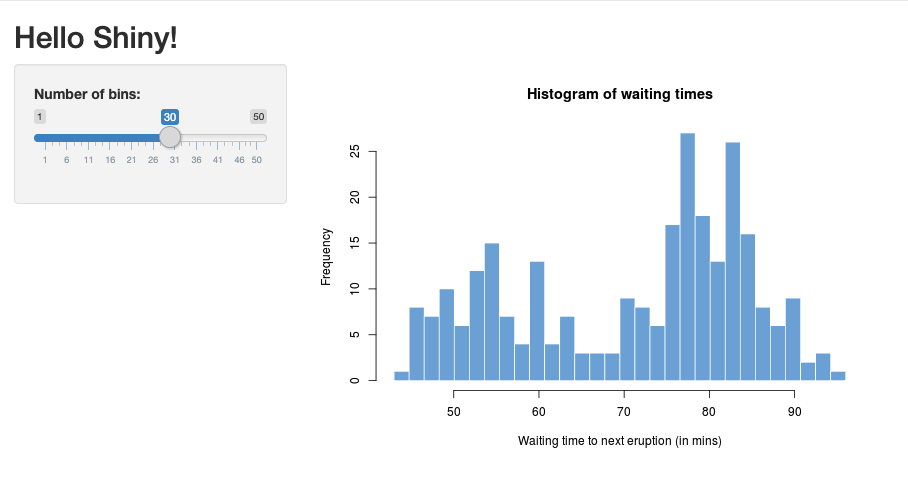
RStudio で Shiny パッケージをインポートし、次のようにサンプル アプリ
01_hello実行します。R> library(shiny)
> runExample("01_hello")
Listening on http://127.0.0.1:3203新しいウィンドウが表示され、Shinyアプリケーションが表示されます。
R スクリプトから Shiny アプリを実行する
R スクリプトから Shiny アプリを実行するには、 RStudio エディターで R スクリプトを開き、右上の [アプリの実行 ] ボタンをクリックします。
Shiny アプリ内で Apache Spark を使用する
Shinyアプリケーション内の Apache Spark は、 SparkR またはSparklyrのいずれかで使用できます。
SparkRとShinyをノートブックで使用する
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
ノートブックでSparklyrとShinyを使用する
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
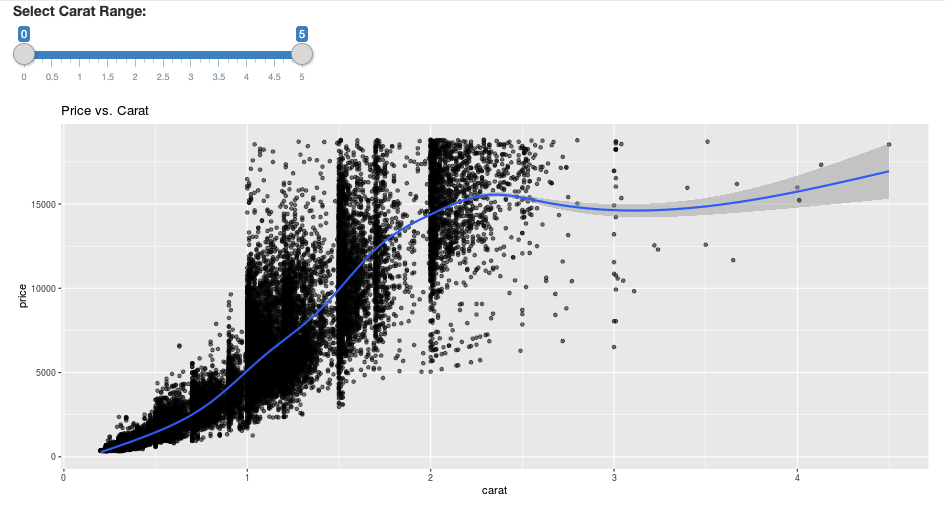
# Define the UI
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
よくある質問(FAQ)
- しばらくするとShinyアプリがグレー表示されるのはなぜですか?
- しばらくすると Shiny ビューアウィンドウが消えるのはなぜですか?
- なぜ長い Spark ジョブは戻ってこないのですか?
- タイムアウトを回避するにはどうすればいいですか?
- アプリを起動した直後にクラッシュしますが、コードは正しいようです。どうなっているのですか。
- 開発中、1つのShinyアプリリンクでいくつの接続を受け入れることができますか?
- Databricks Runtime にインストールされているものとは異なるバージョンの Shiny パッケージを使用できますか?
- Shiny サーバーに公開して Databricks 上のデータにアクセスできる Shiny アプリケーションを開発するにはどうすればよいですか?
- Databricksノートブック内でShinyアプリケーションを開発できますか?
- ホストされたRStudioサーバーで開発した Shiny アプリケーションを保存するにはどうすればよいですか?
しばらくするとShinyアプリがグレー表示されるのはなぜですか?
Shiny アプリとのインタラクションがない場合、アプリへの接続は約 10 分後に終了します。
再接続するには、Shiny アプリのページを更新します。 ダッシュボードの状態がリセットされます。
しばらくするとShinyのビューアーウィンドウが消えてしまうのはなぜですか?
数分間アイドリングした後に Shiny ビューアウィンドウが消える場合は、「グレーアウト」シナリオと同じタイムアウトが原因です。
なぜ長い Spark ジョブは戻ってこないのですか?
これもアイドル タイムアウトが原因です。 前述のタイムアウトより長く実行されている Spark ジョブは、ジョブが戻る前に接続が閉じられるため、結果をレンダリングできません。
タイムアウトを回避するにはどうすればよいですか?
-
Github の一部のロードバランサーで TCP タイムアウトを防ぐために、機能リクエスト: クライアントにキープアライブメッセージを送信させる で推奨される回避策があります。回避策では、アプリがアイドル状態のときに WebSocket 接続を維持するためにハートビートを送信します。 ただし、実行時間の長い計算によってアプリがブロックされている場合、この回避策は機能しません。
-
Shiny は長時間実行されるタスクをサポートしていません。 Shinyのブログ記事では 、PromiseとFuture を使用して長いタスクを非同期に実行し、アプリのブロックを解除することを推奨しています。 次の例は、ハートビートを使用して Shiny アプリを存続させ、
futureコンストラクトで長時間実行される Spark ジョブを実行する例です。R# Write an app that uses spark to access data on Databricks
# First, install the following packages:
install.packages('future')
install.packages('promises')
library(shiny)
library(promises)
library(future)
plan(multisession)
HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second
# Define the long Spark job here
run_spark <- function(x) {
# Environment setting
library("SparkR", lib.loc = "/databricks/spark/R/lib")
sparkR.session()
irisDF <- createDataFrame(iris)
collect(irisDF)
Sys.sleep(3)
x + 1
}
run_spark_sparklyr <- function(x) {
# Environment setting
library(sparklyr)
library(dplyr)
library("SparkR", lib.loc = "/databricks/spark/R/lib")
sparkR.session()
sc <- spark_connect(method = "databricks")
iris_tbl <- copy_to(sc, iris, overwrite = TRUE)
collect(iris_tbl)
x + 1
}
ui <- fluidPage(
sidebarLayout(
# Display heartbeat
sidebarPanel(textOutput("keep_alive")),
# Display the Input and Output of the Spark job
mainPanel(
numericInput('num', label = 'Input', value = 1),
actionButton('submit', 'Submit'),
textOutput('value')
)
)
)
server <- function(input, output) {
#### Heartbeat ####
# Define reactive variable
cnt <- reactiveVal(0)
# Define time dependent trigger
autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS)
# Time dependent change of variable
observeEvent(autoInvalidate(), { cnt(cnt() + 1) })
# Render print
output$keep_alive <- renderPrint(cnt())
#### Spark job ####
result <- reactiveVal() # the result of the spark job
busy <- reactiveVal(0) # whether the spark job is running
# Launch a spark job in a future when actionButton is clicked
observeEvent(input$submit, {
if (busy() != 0) {
showNotification("Already running Spark job...")
return(NULL)
}
showNotification("Launching a new Spark job...")
# input$num must be read outside the future
input_x <- input$num
fut <- future({ run_spark(input_x) }) %...>% result()
# Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result()
busy(1)
# Catch exceptions and notify the user
fut <- catch(fut, function(e) {
result(NULL)
cat(e$message)
showNotification(e$message)
})
fut <- finally(fut, function() { busy(0) })
# Return something other than the promise so shiny remains responsive
NULL
})
# When the spark job returns, render the value
output$value <- renderPrint(result())
}
shinyApp(ui = ui, server = server) -
最初のページの読み込みから 12 時間というハード制限があり、その後は、アクティブであっても接続が終了します。 このような場合、再接続するには Shiny アプリを更新する必要があります。 ただし、基になる WebSocket 接続は、ネットワークの不安定性やコンピューターのスリープ モードなど、さまざまな要因によっていつでも閉じる可能性があります。 Databricks では、長期間の接続を必要とせず、セッション状態に過度に依存しないように、Shiny アプリを書き換えることをお勧めします。
アプリを起動した直後にクラッシュしますが、コードは正しいようです。どうなっているのですか。
Databricks の Shiny アプリに表示できるデータの合計量には 50 MB の制限があります。アプリケーションの合計データサイズがこの制限を超えると、起動直後にクラッシュします。これを回避するために、Databricks では、表示されるデータをダウンサンプリングしたり、画像の解像度を下げたりするなどして、データ サイズを小さくすることをお勧めします。
開発中、1つのShinyアプリリンクに対していくつの接続を受け入れることができますか?
Databricks では最大 20 個まで推奨されます。
Databricks Runtime にインストールされているものとは異なるバージョンの Shiny パッケージを使用できますか?
はい。 「R パッケージのバージョンの修正」を参照してください。
Shiny サーバーに公開して Databricks 上のデータにアクセスできる Shiny アプリケーションを開発するにはどうすればよいですか?
SparkRでの開発およびテスト中に または SparklyrDatabricks を使用してデータに自然にアクセスできますが、Shiny アプリケーションがスタンドアロンのホスティング サービスに公開された後は、Databricks 上のデータとテーブルに直接アクセスすることはできません。
アプリケーションを Databricks の外部で機能させるには、データへのアクセス方法を書き換える必要があります。 いくつかのオプションがあります。
- JDBC/ODBC を使用して、Databricks クラスターにクエリを送信します。
- Databricks Connect を使用します。
- オブジェクトストレージ上のデータに直接アクセスします。
Databricks では、 Databricks ソリューション チームと協力して、既存のデータとアナリティクス アーキテクチャに最適なアプローチを見つけることをお勧めします。
Databricksノートブック内でShinyアプリケーションを開発できますか?
はい、Databricks ノートブック内で Shiny アプリケーションを開発できます。
ホストされたRStudioサーバーで開発したShinyアプリケーションを保存するにはどうすればよいですか?
アプリケーション コードを DBFS に保存するか、コードをバージョン管理にチェックインできます。