ワークフロー向けサーバレス コンピュートによるLakeflowジョブの実行
サーバーレス コンピュート for ワークフローを使用すると、インフラストラクチャの構成や展開を行わずにジョブを実行できます。 サーバレス コンピュートを使用すると、データ処理と分析パイプラインの実装に集中でき、 Databricksワークロードに合わせたコンピュートの最適化やスケーリングなど、コンピュート リソースを効率的に管理します。 オートスケールとPhoton 、ジョブを実行するコンピュート リソースに対して自動的に有効になります。
ワークフロー向けサーバレス コンピュートは、インスタンスタイプ、メモリ、処理エンジンなどのインフラストラクチャを自動的かつ継続的に最適化し、ワークロードの特定の処理要件に基づいて最高のパフォーマンスを確保します。
Databricks は、ジョブの安定性を確保しながら、プラットフォームの機能強化とアップグレードをサポートするために、Databricks Runtime バージョンを自動的にアップグレードします。サーバレス コンピュートがワークフローに使用している現在の Databricks Runtime バージョンを確認するには、 サーバレス コンピュート リリースノートを参照してください。
クラスターの作成権限は必要ないため、すべてのワークスペース ユーザーはサーバレス コンピュートを使用してワークフローを実行できます。
このページでは、 LakeFlowジョブ UI を使用して、サーバレス コンピュートを使用するジョブを作成および実行する方法について説明します。 Jobs API 、Declarative Automation Bundles、 Databricks SDK for Pythonを使用して、サーバレス コンピュートを使用するジョブの作成と実行を自動化することもできます。
- Jobs APIを使用して、サーバレス コンピュートを使用するジョブを作成および実行する方法については、REST APIリファレンスのJobsを参照してください。
- 宣言的オートメーション バンドルを使用して、サーバレス コンピュートを使用するジョブを作成および実行する方法については、 「宣言的オートメーション バンドルを使用したジョブの開発」を参照してください。
- Databricks SDK for Pythonを使用して、サーバレス コンピュートを使用するジョブを作成および実行する方法については、Databricks SDK for Pythonを参照してください。
必要条件
- Databricks ワークスペースで Unity Catalog が有効になっている必要があります。
- サーバレス コンピュート for ワークフローは 標準アクセスモードを使用するため、ワークロードはこのアクセスモードをサポートする必要があります。
サーバレス コンピュートを使用してジョブを作成する
ワークフロー向けサーバレスコンピュートは、ワークロードを実行するのに十分なリソースがプロビジョニングされるようにするため、大量のメモリを必要とするジョブや多数のタスクを含むジョブを実行すると、起動時間が長くなる可能性があります。
サーバーレス コンピュートは、ノートブック、 Pythonスクリプト、 dbt 、 Python wheel 、およびJARタスク タイプでサポートされています。 当然、ジョブを作成し、これらのサポートされているタスク タイプのいずれかを追加すると、コンピュート タイプとしてサーバレス コンピュートが選択されます。
プレビュー
JARタスクに対するサーバレスコンピュートの使用はパブリックプレビュー中です。
Databricks では、すべてのジョブ タスクにサーバレス コンピュートを使用することをお勧めします。 また、ジョブ内のタスクに異なるコンピュートタイプを指定することもできます。これは、タスクタイプがサーバレス ワークフローのコンピュートでサポートされていない場合に必要になることがあります。
ジョブのアウトバウンドネットワーク接続を管理するには、 サーバレスエグレス制御とはを参照してください。
サーバレス コンピュートを使用するように既存のジョブを構成する
既存のジョブを切り替えて、サポートされているタスクタイプにサーバレス コンピュートを使用するように切り替えることができます。 サーバレス コンピュートに切り替えるには、次のいずれかを実行します。
- ジョブ詳細 サイドパネルで、 コンピュート の下の スワップ をクリックし、 新規 をクリックして、設定を入力または更新し、 更新 をクリックします。
- コンピュート ドロップダウンメニューで
 をクリックし、 サーバレス を選択します。
をクリックし、 サーバレス を選択します。

サーバレス コンピュートを使用してノートブックをスケジュールする
ジョブUIを使用してサーバレス コンピュートを使用してジョブを作成およびスケジュールするだけでなく、サーバレス コンピュートを使用するジョブを Databricks ノートブックから直接作成および実行することもできます。 スケジュールされたノートブック ジョブの作成と管理を参照してください。
サーバレス使用ポリシーの選択
プレビュー
この機能は パブリック プレビュー段階です。
サーバーレス使用ポリシーにより、組織は、詳細な請求属性を得るために、サーバーレス使用量にカスタム タグを適用できます。
ワークスペースでサーバレス使用状況ポリシーを使用してサーバレスの使用状況を属性付けしている場合は、ジョブの詳細 UI の 使用状況ポリシー 設定を使用して、ジョブのサーバレス使用状況ポリシーを選択できます。1 つのサーバレス使用ポリシーにのみ割り当てられている場合、そのポリシーは新しいジョブに対して自動的に選択されます。
サーバーレス使用ポリシーが割り当てられた後、既存のジョブには自動的にポリシーのタグが付けられません。 既存のジョブにポリシーを関連付けるには、手動でジョブを更新する必要があります。
サーバレス使用ポリシーの詳細については、 「サーバレス使用ポリシーでの属性の使用」を参照してください。
パフォーマンスモードを選択する
ジョブの詳細ページの パフォーマンス最適化 設定を使用して、ジョブのサーバレス タスクの実行速度を選択できます。
-
パフォーマンスの最適化 が無効になっている場合、ジョブは標準パフォーマンス モードを使用します。このモードは、コストを削減するためにコンピュートの使用量を減らし、コンピュートの可用性と最適化されたスケジューリングに応じて、4 ~ 6 分のわずかに長い起動遅延を許容できるワークロードに適しています。
-
パフォーマンスの最適化 を有効にすると、ジョブの開始と実行が速くなります。このモードは、時間的制約のあるワークロード向けに設計されています。
どちらのモードも同じSKUを使用しますが、標準パフォーマンス モードは、コンピュート使用量の低下を反映して消費する DBU が少なくなります。
UI で パフォーマンス最適化 設定を構成するには、ジョブに少なくとも 1 つのサーバレス タスクが必要です。 この設定は、ジョブ内のサーバレス タスクにのみ影響します。
標準パフォーマンス モードは、 runs/submit エンドポイントを使用して作成された 1 回限りの実行ではサポートされていません。
Spark 構成パラメーターの設定
サーバレス コンピュートでの Spark の設定を自動化するために、 Databricks では特定の Spark 設定パラメータのみを設定できます。 許容されるパラメーターのリストについては、 サポートされる Spark 構成パラメーターを参照してください。
Spark構成はセッションレベルでのみ設定できます。 これを行うには、それらをノートブックに設定し、そのノートブックを、その 引数 を使用する同じ ジョブ に含まれるタスクに追加します。 「Databricks での Spark 構成プロパティの設定」を参照してください。
環境と依存関係を設定する
サーバレス コンピュートを使用してライブラリと依存関係をインストールする方法については、 サーバレス環境の設定を参照してください。
ノートブックのタスク用にハイメモリを構成する
プレビュー
この機能は パブリック プレビュー段階です。
ノートブックのタスクは、より大きなメモリサイズを使用するように設定できます。これを行うには、ノートブックの 環境 サイド パネルで メモリ 設定を構成します。ハイメモリー サーバレス コンピュートの使用を参照してください。
ハイメモリは、ノートブックのタスクタイプでのみ使用できます。
サーバレス コンピュートの自動最適化を構成して再試行を許可しないようにします
ワークフロー向けサーバレス コンピュートの自動最適化処理 は、ジョブの実行に使用されたコンピュートを自動的に最適化し、失敗したタスクを再試行します。 自動最適化はデフォルトで有効になっており、Databricks では、重要なワークロードが少なくとも 1 回は正常に実行されるように、有効のままにしておくことをお勧めします。 ただし、べき等でないジョブなど、最大で一度に実行する必要があるワークロードがある場合は、タスクを追加または編集するときに自動最適化をオフにできます。
- 再試行 の横にある 追加 をクリックします (再試行ポリシーがすでに存在する場合は
 をクリックします)。
をクリックします)。 - 再試行ポリシー ダイアログで、 サーバーレス自動最適化を有効化(最大3回の再試行を含む) のチェックを外します。
- 確認 をクリックします。
- タスクの保存 をクリックします。
ワークフロー向けサーバレス コンピュートを使用するジョブのコストを監視する
サーバレス コンピュートをワークフローに使用しているジョブのコストは、 課金利用 システムテーブルを照会することで監視できます。 このテーブルは、サーバレスのコストに関するユーザ属性とワークロード属性を含むように更新されています。 課金利用 システムテーブル リファレンスを参照してください。
現在の価格とプロモーションに関する情報については、 ワークフロー 価格 ページを参照してください。
ジョブ実行のクエリ詳細を表示する
Spark ステートメントの詳細なランタイム情報 (メトリクスやクエリプランなど) を表示できます。
ジョブ UI からクエリの詳細にアクセスするには、次の手順に従います。
-
Databricks ワークスペースのサイドバーで、[ ジョブとパイプライン] をクリックします。
-
必要に応じて、[ ジョブ] フィルターを選択します。
-
表示するジョブ の名前 をクリックします。
-
表示する特定の実行をクリックします。
-
[タイムライン] をクリックすると、実行がタイムラインとして表示され、個々のタスクに分割されます。
-
タスク名の横にある矢印をクリックすると、クエリステートメントとそのランタイムが表示されます。
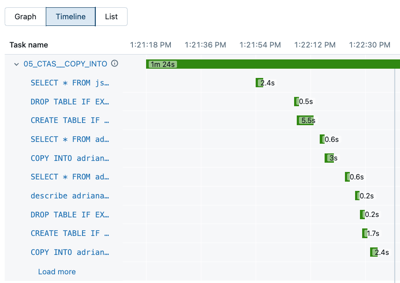
-
ステートメントをクリックすると、そのクエリのプロファイルに移動し、クエリの実行詳細とメトリクスが表示されます。
タスクのクエリ履歴を表示するには:
- 「**タスク実行**」サイドペインの「**コンピュート**」セクションで、「**クエリ履歴**」をクリックします。
- クエリー履歴にリダイレクトされ、参加していたタスクのタスク実行 ID に基づいて事前にフィルタリングされます。
クエリ履歴の使用方法については、 「パイプラインのクエリ履歴にアクセスする」および「クエリ履歴」を参照してください。
制限
ワークフローの制限事項に関するサーバレス コンピュートのリストについては、サーバレス コンピュート リリースノートの サーバレス コンピュートの制限事項 を参照してください。