Apply AI on data using Databricks AI Functions
This feature is in Public Preview.
This article describes Databricks AI Functions and the supported functions.
What are AI Functions?
AI Functions are built-in functions that you can use to apply AI, like text translation or sentiment analysis, on your data that is stored on Databricks. They can be run from anywhere on Databricks, including Databricks SQL, notebooks, Lakeflow Spark Declarative Pipelines, and Workflows.
AI Functions are simple to use, fast, and scalable. Analysts can use them to apply data intelligence to their proprietary data, while data scientists and machine learning engineers can use them to build production-grade batch pipelines.
AI Functions provide task-specific and general-purpose functions.
- Task-specific functions provide high-level AI capabilities for tasks like summarizing text and translation. These task-specific functions are powered by state of the art generative AI models that are hosted and managed by Databricks. See Task-specific AI functions for supported functions and models.
ai_queryis a general-purpose function that allows you to apply any type of AI model on your data. See General purpose function:ai_query.
Task-specific AI functions
Task-specific functions are scoped for a certain task so you can automate routine actions, like simple summaries and quick translations. Databricks recommends these functions for getting started because they invoke a state-of-the-art generative AI models maintained by Databricks and do not require any customization.
See Analyze customer reviews using AI Functions for an example.
The following table lists supported functions and the task they perform.
Function | Description |
|---|---|
Perform sentiment analysis on input text using a state-of-the-art generative AI model. | |
Classify input text according to labels you provide using a state-of-the-art generative AI model. | |
Extract entities specified by labels from text using a state-of-the-art generative AI model. | |
Correct grammatical errors in text using a state-of-the-art generative AI model. | |
Answer the user-provided prompt using a state-of-the-art generative AI model. | |
Mask specified entities in text using a state-of-the-art generative AI model. | |
Extract structured content from unstructured documents using a state-of-the-art generative AI model. | |
Compare two strings and compute the semantic similarity score using a state-of-the-art generative AI model. | |
Generate a summary of text using SQL and state-of-the-art generative AI model. | |
Translate text to a specified target language using a state-of-the-art generative AI model. | |
Forecast data up to a specified horizon. This table-valued function is designed to extrapolate time series data into the future. | |
Search and query a Mosaic AI Vector Search index using a state-of-the-art generative AI model. |
General purpose function: ai_query
The ai_query() function allows you to apply any AI model to data for both generative AI and classical ML tasks, including extracting information, summarizing content, identifying fraud, and forecasting revenue. For syntax details and parameters, see ai_query function.
The following table summarizes the supported model types, the associated models, and model serving endpoint configuration requirements for each.
Type | Description | Supported models | Requirements |
|---|---|---|---|
Pre-deployed models | These foundation models are hosted by Databricks and offer preconfigured endpoints that you can query using | These models are supported and optimized for getting started with batch inference and production workflows:
Other Databricks-hosted models are available for use with AI Functions, but are not recommended for batch inference production workflows at scale. These other models are made available for real-time inference using Foundation Model APIs pay-per-token. | Databricks Runtime 15.4 LTS or above is required to use this functionality. Requires no endpoint provisioning or configuration. Your use of these models is subject to the Applicable model developer licenses and terms and AI Functions region availability. |
Bring your own model | You can bring your own models and query them using AI Functions. AI Functions offers flexibility so you can query models for real-time inference or batch inference scenarios. |
|
|
Use ai_query with foundation models
The following example demonstrates how to use ai_query using a foundation model hosted by Databricks.
- See
ai_queryfunction for syntax details and parameters. - See Multimodal inputs for multimodal input query examples.
- See Examples for advanced scenarios for guidance on how to configure parameters for advanced use cases such as:
- Handle errors using
failOnError - Structured outputs on Databricks for how to specify structured output for your query responses.
- Handle errors using
SELECT text, ai_query(
"databricks-meta-llama-3-3-70b-instruct",
"Summarize the given text comprehensively, covering key points and main ideas concisely while retaining relevant details and examples. Ensure clarity and accuracy without unnecessary repetition or omissions: " || text
) AS summary
FROM uc_catalog.schema.table;
Example notebook: Batch inference and structured data extraction
The following example notebook demonstrates how to perform basic structured data extraction using ai_query to transform raw, unstructured data into organized, useable information through automated extraction techniques. This notebook also shows how to leverage Mosaic AI Agent Evaluation to evaluate the accuracy using ground truth data.
Batch inference and structured data extraction notebook
Use ai_query with traditional ML models
ai_query supports traditional ML models, including fully custom ones. These models must be deployed on Model Serving endpoints. For syntax details and parameters, see ai_query function function.
SELECT text, ai_query(
endpoint => "spam-classification",
request => named_struct(
"timestamp", timestamp,
"sender", from_number,
"text", text),
returnType => "BOOLEAN") AS is_spam
FROM catalog.schema.inbox_messages
LIMIT 10
Example notebook: Batch inference using BERT for named entity recognition
The following notebook shows a traditional ML model batch inference example using BERT.
Batch inference using BERT for named entity recognition notebook
Use AI Functions in existing Python workflows
AI Functions can be easily integrated in existing Python workflows.
The following writes the output of the ai_query to an output table:
df_out = df.selectExpr(
"ai_query('databricks-meta-llama-3-3-70b-instruct', CONCAT('Please provide a summary of the following text: ', text), modelParameters => named_struct('max_tokens', 100, 'temperature', 0.7)) as summary"
)
df_out.write.mode("overwrite").saveAsTable('output_table')
The following writes the summarized text into a table:
df_summary = df.selectExpr("ai_summarize(text) as summary")
df_summary.write.mode('overwrite').saveAsTable('summarized_table')
Use AI Functions in production workflows
For large-scale batch inference, you can integrate task-specific AI Functions, or the general purpose function ai_query into your production workflows, like Lakeflow Spark Declarative Pipelines, Databricks workflows and Structured Streaming. This enables production-grade processing at scale. See Deploy batch inference pipelines for examples and details.
Monitor AI Functions progress
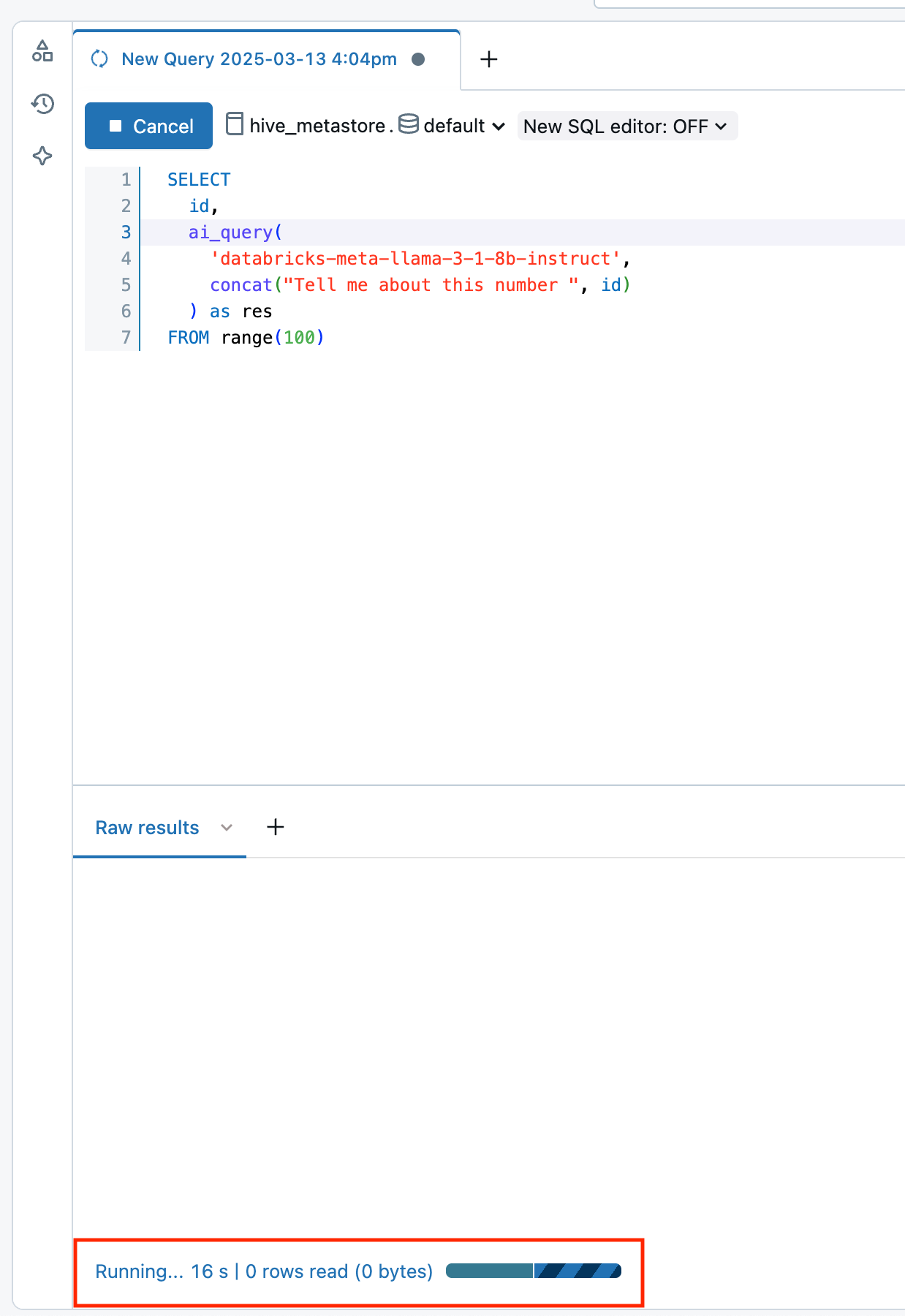
To understand how many inferences have completed or failed and troubleshoot performance, you can monitor the progress of AI Functions using the query profile feature.
In Databricks Runtime 16.1 ML and above, from the SQL editor query window in your workspace:
- Select the link, Running--- at the bottom of the Raw results window. The performance window appears on the right.
- Click See query profile to view performance details.
- Click AI Query to see metrics for that particular query including the number of completed and failed inferences and the total time the request took to complete.
View costs for AI Function workloads
AI Function costs are recorded as part of the MODEL_SERVING product under the BATCH_INFERENCE offering type. See View costs for batch inference workloads for an example query.
For ai_parse_document costs are recorded as part of the AI_FUNCTIONS product. See View costs for ai_parse_document runs for an example query.
View costs for batch inference workloads
The following examples show how to filter batch inference workloads based on job, compute, SQL warehouses, and Lakeflow Spark Declarative Pipelines.
See Monitor model serving costs for general examples on how to view costs for your batch inference workloads that use AI Functions.
- Jobs
- Compute
- Lakeflow Spark Declarative Pipelines
- SQL warehouse
The following query shows which jobs are being used for batch inference using the system.workflow.jobs systems table. See Monitor job costs & performance with system tables.
SELECT *
FROM system.billing.usage u
JOIN system.workflow.jobs x
ON u.workspace_id = x.workspace_id
AND u.usage_metadata.job_id = x.job_id
WHERE u.usage_metadata.workspace_id = <workspace_id>
AND u.billing_origin_product = "MODEL_SERVING"
AND u.product_features.model_serving.offering_type = "BATCH_INFERENCE";
The following shows which clusters are being used for batch inference using the system.compute.clusters systems table.
SELECT *
FROM system.billing.usage u
JOIN system.compute.clusters x
ON u.workspace_id = x.workspace_id
AND u.usage_metadata.cluster_id = x.cluster_id
WHERE u.usage_metadata.workspace_id = <workspace_id>
AND u.billing_origin_product = "MODEL_SERVING"
AND u.product_features.model_serving.offering_type = "BATCH_INFERENCE";
The following shows which Lakeflow Spark Declarative Pipelines are being used for batch inference using the system.lakeflow.pipelines systems table.
SELECT *
FROM system.billing.usage u
JOIN system.lakeflow.pipelines x
ON u.workspace_id = x.workspace_id
AND u.usage_metadata.dlt_pipeline_id = x.pipeline_id
WHERE u.usage_metadata.workspace_id = <workspace_id>
AND u.billing_origin_product = "MODEL_SERVING"
AND u.product_features.model_serving.offering_type = "BATCH_INFERENCE";
The following shows which SQL warehouses are being used for batch inference using the system.compute.warehouses systems table.
SELECT *
FROM system.billing.usage u
JOIN system.compute.clusters x
ON u.workspace_id = x.workspace_id
AND u.usage_metadata.cluster_id = x.cluster_id
WHERE u.workspace_id = <workspace_id>
AND u.billing_origin_product = "MODEL_SERVING"
AND u.product_features.model_serving.offering_type = "BATCH_INFERENCE";
View costs for ai_parse_document runs
The following example shows how to query billing system tables to view costs for ai_parse_document runs.
SELECT *
FROM system.billing.usage u
WHERE u.workspace_id = <workspace_id>
AND u.billing_origin_product = "AI_FUNCTIONS"
AND u.product_features.ai_functions.ai_function = "AI_PARSE_DOCUMENT";