visão geral e glossário do repositório de recursos
Esta página explica como a Databricks recurso Store funciona e define termos importantes.
Como funciona o recurso engenharia no site Databricks?
O típico fluxo de trabalho de aprendizado de máquina usando recurso engenharia em Databricks segue esse caminho:
-
Escreva um código para converter dados brutos em recurso e crie um Spark DataFrame contendo o recurso desejado.
-
Crie uma tabela Delta em Unity Catalog que tenha um primário key.
-
Treine e log um modelo usando a tabela de recursos. Quando o senhor faz isso, o modelo armazena as especificações do recurso usado para o treinamento. Quando o modelo é usado para inferência, ele automaticamente junta os recursos das tabelas de recursos apropriadas.
-
modelo de registro em Model Registry.
Agora você pode usar o modelo para fazer previsões sobre novos dados. Para muitos casos de uso, o modelo recupera automaticamente o recurso de que precisa no Recurso Store.
-
Para casos de uso de tempo real de atendimento, publique o recurso em uma loja on-line de recursos.
-
No momento da inferência, o modelo de atendimento endpoint usa automaticamente os IDs de entidade nos dados da solicitação para procurar o recurso de pré-computação do armazenamento on-line para pontuar o modelo ML. O site endpoint usa o Unity Catalog para resolver a linhagem do modelo servido para o recurso usado para treinar esse modelo e rastreia a linhagem para o armazenamento de recurso on-line para acesso ao tempo real.
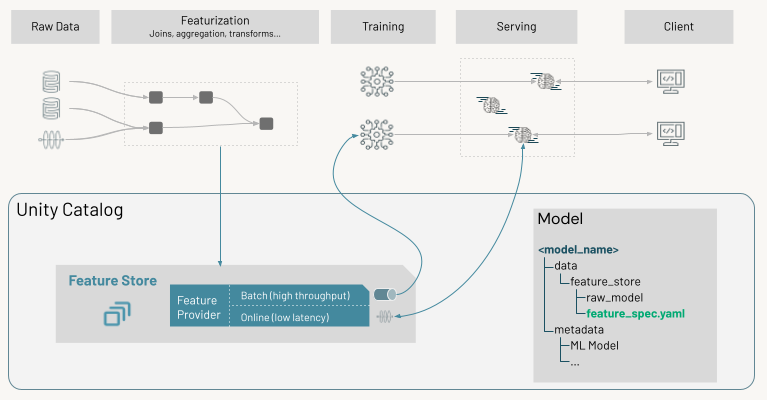
recurso store glossary
loja de recursos
Um recurso store é um repositório centralizado que permite que o site data scientists encontre e compartilhe recursos. O uso de um armazenamento de recurso também garante que o código usado para compute valores de recurso seja o mesmo durante o treinamento do modelo e quando o modelo for usado para inferência. O funcionamento do recurso store em Databricks depende do fato de o site workspace estar habilitado para Unity Catalog ou não.
- No espaço de trabalho habilitado para Unity Catalog, o senhor pode usar qualquer tabela Delta em Unity Catalog que inclua uma restrição primária key como uma tabela de recurso.
- O espaço de trabalho não habilitado para Unity Catalog que foram criados antes de 19 de agosto de 2024, 4:00:00 PM (UTC) têm acesso ao recurso Store do espaço de trabalho legado.
O machine learning usa dados existentes para construir um modelo para prever resultados futuros. Em quase todos os casos, os dados brutos exigem pré-processamento e transformação antes de serem usados para construir um modelo. Esse processo é chamado de engenharia de recursos, e as saídas desse processo são chamadas de recursos, os blocos de construção do modelo.
O desenvolvimento de recursos é complexo e demorado. Uma complicação adicional é que, no aprendizado de máquina, os cálculos de recurso precisam ser feitos para o treinamento do modelo e, em seguida, novamente quando o modelo é usado para fazer previsões. Essas implementações podem não ser feitas pela mesma equipe ou usando o mesmo ambiente de código, o que pode levar a atrasos e erros. Além disso, equipes diferentes em uma organização geralmente têm necessidades de recursos semelhantes, mas podem não estar cientes do trabalho que outras equipes realizaram. Um recurso store foi projetado para resolver esses problemas.
tabelas de recursos
recurso são organizados como tabelas de recurso. Cada tabela deve ter um key primário e é apoiada por uma tabelaDelta e metadados adicionais. Os metadados da tabela de recurso rastreiam a fonte de dados a partir da qual uma tabela foi gerada e o Notebook e o Job que criaram ou gravaram na tabela.
Com Databricks Runtime 13.3 LTS e acima, se o seu workspace estiver habilitado para Unity Catalog, o senhor poderá usar qualquer tabela Delta em Unity Catalog com um key primário como uma tabela de recurso. Consulte Trabalhar com tabelas de recursos em Unity Catalog. As tabelas de recurso armazenadas no recurso Store do espaço de trabalho local são chamadas de "tabelas de recurso do espaço de trabalho". Consulte Trabalhar com tabelas de recurso no espaço de trabalho Recurso Store (legado).
em uma tabela de recursos são normalmente computados e atualizados usando uma função de computação comum.
O senhor pode publicar uma tabela de recursos em um armazenamento on-line para a inferência de modelos de tempo real.
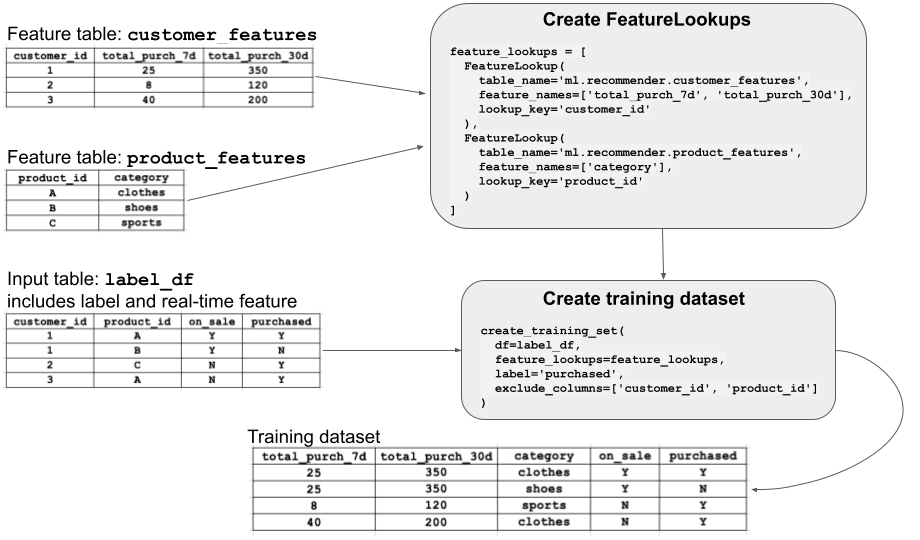
FeatureLookup
Muitos modelos diferentes podem usar recursos de uma determinada tabela de recursos, e nem todos os modelos precisarão de todos os recursos. Para treinar um modelo usando recurso, o senhor cria um FeatureLookup para cada tabela de recurso. O FeatureLookup especifica qual recurso usar da tabela e também define a chave a ser usada para join a tabela de recursos para os dados do rótulo passados para create_training_set.
O diagrama ilustra como funciona um FeatureLookup. Neste exemplo, o senhor deseja treinar um modelo usando recurso de duas tabelas de recurso, customer_features e product_features. O senhor cria um FeatureLookup para cada tabela de recurso, especificando o nome da tabela, o recurso (colunas) a ser selecionado na tabela e a pesquisa key a ser usada quando o recurso de união criar um treinamento dataset.
Em seguida, você chama create_training_set, também mostrado no diagrama. Essa chamada de API especifica o DataFrame que contém os dados de treinamento brutos (label_df), o FeatureLookups a ser usado e label, uma coluna que contém a verdade fundamental. Os dados de treinamento devem conter coluna(s) correspondente(s) a cada uma das chaves primárias das tabelas de recurso. Os dados nas tabelas de recurso são unidos à entrada DataFrame de acordo com essa chave. O resultado é mostrado no diagrama como o "treinamento dataset".
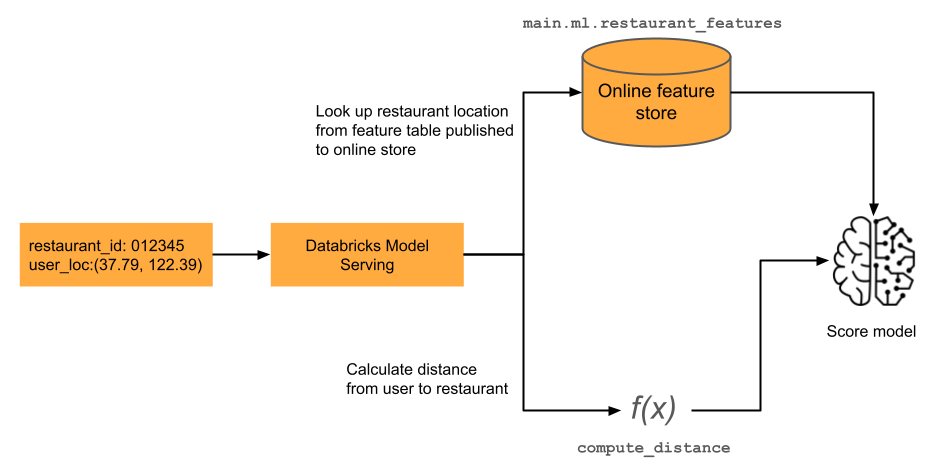
FeatureFunction
Um recurso pode depender de informações que só estão disponíveis no momento da inferência. É possível especificar uma configuração de recurso ( FeatureFunction ) que combine entradas em tempo real com valores de recurso para atualizar valores de recurso atualizados ( compute ). Um exemplo é mostrado no diagrama. Para obter detalhes, consulte Cálculo de recursos sob demanda.
Conjunto de treinamento
Um conjunto de treinamento consiste em uma lista de recursos e um DataFrame que contém dados brutos de treinamento, rótulo e chave primária para procurar o recurso. O senhor cria o conjunto de treinamento especificando o recurso a ser extraído do recurso Store e fornece o conjunto de treinamento como entrada durante o treinamento do modelo.
Consulte Criar um treinamento dataset para ver um exemplo de como criar e usar um conjunto de treinamento.
Quando o senhor treina e log um modelo usando recurso engenharia em Unity Catalog, pode view a linhagem do modelo no Catalog Explorer. Tabelas e funções que foram usadas para criar o modelo são automaticamente rastreadas e exibidas. Ver recurso governança e linhagem.
FeatureSpec
Um FeatureSpec é uma entidade Unity Catalog que define um conjunto reutilizável de recursos e funções para atendimento. FeatureSpecs combinam FeatureLookups de tabelas de recursos e FeatureFunctions em uma única unidade lógica que pode ser usada no modelo de treinamento ou servida usando o ponto de extremidade Feature Serving.
FeatureSpecs são armazenados e gerenciados pelo site Unity Catalog, com acompanhamento de linhagem completa para suas funções e tabelas de recursos off-line constituintes. Isso permite governança, descoberta e reutilização em diferentes modelos e aplicativos.
Você pode usar um FeatureSpec das seguintes maneiras:
- Crie um endpoint do Feature Serving usando a API Python ou a API REST. Consulte Feature Serving endpoint ou implantado diretamente usando a UI do modelo servindo. Para aplicativos de alto desempenho, ative a otimização de rotas.
- Use no treinamento do modelo fazendo referência ao site
FeatureSpecemcreate_training_set.
O site FeatureSpec sempre faz referência às tabelas de recurso off-line, mas elas devem ser publicadas em um armazenamento on-line para cenários de tempo real de atendimento.
Tabelas de recurso de séries temporais (pesquisas pontuais)
Os dados usados para treinar um modelo geralmente têm dependências de tempo incorporadas. Ao criar o modelo, o senhor deve considerar apenas os valores do recurso até o momento do valor-alvo observado. Se o senhor treinar com recurso baseado em dados medidos após o registro de data e hora do valor-alvo, o desempenho do modelo poderá ser prejudicado.
As tabelas de recurso de séries temporais incluem uma coluna de registro de data e hora que garante que cada linha do treinamento dataset represente os valores de recurso mais recentes conhecidos a partir do registro de data e hora da linha. O senhor deve usar tabelas de recurso de série temporal sempre que os valores de recurso mudarem ao longo do tempo, por exemplo, com dados de série temporal, dados baseados em eventos ou dados agregados no tempo.
Ao criar uma tabela de recurso de série temporal, o senhor especifica as colunas relacionadas ao tempo na chave primária para serem colunas de série temporal usando o argumento timeseries_columns (para recurso engenharia em Unity Catalog) ou o argumento timestamp_keys (para espaço de trabalho Feature Store). Isso permite pesquisas pontuais quando você usa create_training_set ou score_batch. O sistema executa um carimbo de data/hora "as-of" join, usando o timestamp_lookup_key que o senhor especificar.
Se o senhor não usar o argumento timeseries_columns ou o argumento timestamp_keys e designar apenas uma coluna de série temporal como coluna primária key, o site Feature Store não aplicará a lógica point-in-time à coluna de série temporal durante a união. Em vez disso, ele corresponde apenas às linhas com uma correspondência de hora exata, em vez de corresponder a todas as linhas antes do carimbo de data/hora.
armazenamento offline
O armazenamento de recursos off-line é usado para descoberta de recursos, treinamento de modelos e inferência de lotes. Ele contém tabelas de recurso materializadas como tabelasDelta.
Loja de recursos on-line
O Databricks Online Feature Store é uma solução escalável e de alto desempenho para fornecer dados de recursos a aplicativos on-line e um modelo de tempo real do machine learning.
Com a tecnologia Databricks Lakebase, ele fornece acesso de baixa latência a dados de recurso em alta escala, mantendo a governança, a linhagem e a consistência com suas tabelas de recurso off-line.
O senhor pode provisionar Online Stores na plataforma serverless Lakebase. APIs permitem que o senhor gerencie instâncias, leia réplicas e escale instâncias conforme necessário. O senhor pode usar APIs convenientes para publicar tabelas do Unity Catalog em lojas on-line. Essas tabelas também são entidades do Unity Catalog que rastreiam nativamente a linhagem das tabelas de origem. A Databricks também oferece suporte a lojas on-line de terceiros.
transmissão
Além de muitas gravações, o Databricks recurso Store oferece suporte à transmissão. O senhor pode gravar valores de recurso em uma tabela de recurso a partir de uma fonte de transmissão, e o código de computação de recurso pode utilizar a transmissão estruturada para transformar dados brutos em recurso.
O senhor também pode transmitir tabelas de recurso do armazenamento off-line para um armazenamento on-line.
Embalagem modelo
Quando o senhor treina um modelo de aprendizado de máquina usando recurso engenharia em Unity Catalog ou no espaço de trabalho Recurso Store e log ele usa o método log_model() do cliente, o modelo retém referências a esses recursos. No momento da inferência, o modelo pode, opcionalmente, recuperar valores de recurso automaticamente. O chamador só precisa fornecer o endereço primário key do recurso usado no modelo (por exemplo, user_id), e o modelo recupera todos os valores de recurso necessários.
Na inferência de lotes, os valores de recurso são recuperados do armazenamento off-line e unidos a novos dados antes da pontuação. Na inferência de tempo real, os valores de recurso são recuperados do armazenamento on-line.
Para empacotar um modelo com metadados de recurso, use FeatureEngineeringClient.log_model (para recurso de engenharia em Unity Catalog) ou FeatureStoreClient.log_model (para recurso de espaço de trabalho Store).