For eachタスクの大きなパラメーター配列にルックアップテーブルを使用する
For each タスクは、パラメーター配列をネストされたタスクに反復的に渡して、ネストされた各タスクにその実行に関する情報を提供します。 パラメーター配列は 10,000 文字に制限されており、タスク値参照を使用して渡す場合は 48 KB に制限されています。 入れ子になったタスクに渡すデータ量が多い場合、入力、タスク値、またはジョブ パラメーターを直接使用してそのデータを渡すことはできません。
完全なデータを渡す代わりに、タスクデータを JSON ファイルとして保存し、完全なデータではなくタスク入力を介して (JSON データに) ルックアップキーを渡す方法があります。 ネストされたタスクでは、キーを使用して、各イテレーションに必要な特定のデータを取得できます。
次の例は、サンプルの JSON 構成ファイルと、 JSON 構成の値を検索するネストされたタスクにパラメーターを渡す方法を示しています。
サンプル JSON 構成
この構成例は、各イテレーションのパラメーター (args) を含むステップのリストです (この例では 3 つのステップのみを示しています)。 この JSON ファイルが /Workspace/Users/<user>/copy-filtered-table-config.jsonとして保存されているとします。 これは、ネストされたタスク内で参照します。
{
"steps": [
{
"key": "table_1",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_1",
"destination_table": "filtered_table_1",
"filter_column": "col_a",
"filter_value": "value_1"
}
},
{
"key": "table_2",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_2",
"destination_table": "filtered_table_2",
"filter_column": "col_b",
"filter_value": "value_2"
}
},
{
"key": "table_3",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_3",
"destination_table": "filtered_table_3",
"filter_column": "col_c",
"filter_value": "value_3"
}
}
]
}
サンプル For each タスク
ジョブの For each タスクには、各イテレーションのキーを含む入力が含まれます。 この例では、 入力が ["table_1","table_2","table_3"]に設定された copy-filtered-tables というタスクを示しています。このリストは 10,000 文字に制限されていますが、キーを渡すだけなので、完全なデータよりもはるかに小さくなります。
この例では、ステップは他のステップやタスクに依存しないため、1 より大きいコンカレンシーを設定して、タスクの実行を高速化できます。
ネストされたタスクのサンプル
ネストされたタスクには、親 For each タスクからの入力が渡されます。 この場合、設定ファイルの Key として使用する入力を設定します。 次の図は、key という パラメーター と の値 ({{input}}の設定など、ネストされたタスクを示しています。
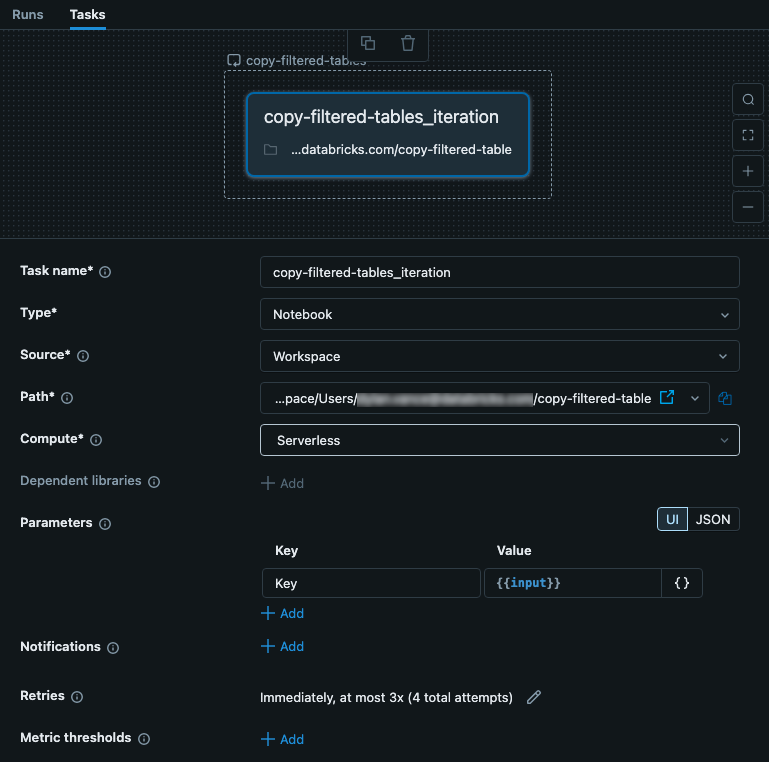
このタスクは、コードを含むノートブックです。 ノートブックでは、次の Python コードを使用して入力を読み取り、それを構成 JSON ファイルのキーとして使用できます。 JSON ファイルのデータは、テーブルからのデータの読み取り、フィルタリング、および書き込みに使用されます。
静的な JSON ファイルではなく、ライブ Delta テーブルからFor eachタスクを駆動する例については、 「制御テーブルを使用してFor eachジョブを駆動する」を参照してください。
# copy-filtered-table (iteratable task code to read a table, filter by a value, and write as a new table)
from pyspark.sql.functions import expr
from types import SimpleNamespace
import json
# If the notebook is run outside of a job with a key parameter, this provides
# a default. This allows testing outside of a For each task
dbutils.widgets.text("key", "table_1", "key")
# load configuration (note that the path must be set to valid configuration file)
config_path = "/Workspace/Users/<user>/copy-filtered-table-config.json"
with open(config_path, "r") as file:
config = json.loads(file.read())
# look up step and arguments
key = dbutils.widgets.get("key")
current_step = next((step for step in config['steps'] if step['key'] == key), None)
if current_step is None:
raise ValueError(f"Could not find step '{key}' in the configuration")
args = SimpleNamespace(**current_step["args"])
# read the source table defined for the step, and filter it
df = spark.read.table(f"{args.catalog}.{args.schema}.{args.source_table}") \
.filter(expr(f"{args.filter_column} like '%{args.filter_value}%'"))
# write the filtered table to the destination
df.write.mode("overwrite").saveAsTable(f"{args.catalog}.{args.schema}.{args.destination_table}")