Databricks で MLflow プロジェクトを実行する
MLflow プロジェクトはサポートされなくなりました。
このドキュメントは廃止されており、更新されない可能性があります。 このコンテンツに記載されている製品、サービス、またはテクノロジはサポートされなくなりました。
MLflowプロジェクトは、データサイエンスコードを再利用可能で再現可能な方法でパッケージ化するための形式です。MLflow プロジェクト コンポーネントには、プロジェクトを実行するための API とコマンドライン ツールが含まれており、これらは Tracking コンポーネントとも統合して、ソース コードのパラメーターと git コミットを自動的に記録して再現性を高めます。
この記事では、MLflow プロジェクトの形式と、MLflow Databricksを使用して クラスターでMLflowCLI プロジェクトをリモートで実行する方法について説明します。これにより、データサイエンスコードを垂直方向に簡単にスケーリングできます。
MLflow プロジェクトの形式
任意のローカル ディレクトリまたは Git リポジトリを MLflow プロジェクトとして扱うことができます。 プロジェクトを定義するには、次の規則があります。
- プロジェクトの名前は、ディレクトリの名前です。
- ソフトウェア環境は、存在する場合は
python_env.yamlで指定されます。python_env.yamlファイルが存在しない場合、MLflow は、プロジェクトの実行時に Python (具体的には、virtualenv で使用できる最新の Python) のみを含む virtualenv 環境を使用します。 - プロジェクト内の任意の
.pyファイルまたは.shファイルをエントリ ポイントにすることができますが、パラメーターは明示的に宣言されていません。 このようなコマンドを一連のパラメーターと共に実行すると、 MLflow は--key <value>構文を使用してコマンド ラインで各パラメーターを渡します。
より多くのオプションを指定するには、MLproject ファイル (YAML 構文のテキスト ファイル) を追加します。 MLproject ファイルの例は、次のようになります。
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: { type: float, default: 0.1 }
command: 'python train.py -r {regularization} {data_file}'
validate:
parameters:
data_file: path
command: 'python validate.py {data_file}'
Databricks Runtime 13.0 ML 以降では、MLflow プロジェクトは Databricks ジョブ タイプのクラスター内で正常に実行できません。既存の MLflow プロジェクトを Databricks Runtime 13.0 ML 以降に移行するには、「 MLflow Databricks Spark ジョブ プロジェクトの形式」を参照してください。
MLflow Databricks Spark ジョブ プロジェクトの形式
MLflow Databricks Spark ジョブ プロジェクトは、MLflow 2.14 で導入された MLflow プロジェクトの一種です。 このプロジェクトの種類は、MLflow Sparkジョブ クラスター内からの プロジェクトの実行をサポートし、 バックエンドを使用してのみ実行できます。databricks
Databricks Spark ジョブ プロジェクトでは、 databricks_spark_job.python_file または entry_pointsを設定する必要があります。 どちらか一方を指定しないか、両方の設定を指定しないと、例外が発生します。
次に、databricks_spark_job.python_file 設定を使用する MLproject ファイルの例を示します。この設定では、Python 実行ファイルとその引数にハードコードされたパスを使用します。
name: My Databricks Spark job project 1
databricks_spark_job:
python_file: 'train.py' # the file which is the entry point file to execute
parameters: ['param1', 'param2'] # a list of parameter strings
python_libraries: # dependencies required by this project
- mlflow==2.4.1 # MLflow dependency is required
- scikit-learn
次に、entry_points 設定を使用する MLproject ファイルの例を示します。
name: My Databricks Spark job project 2
databricks_spark_job:
python_libraries: # dependencies to be installed as databricks cluster libraries
- mlflow==2.4.1
- scikit-learn
entry_points:
main:
parameters:
model_name: { type: string, default: model }
script_name: { type: string, default: train.py }
command: 'python {script_name} {model_name}'
entry_points設定を使用すると、次のようなコマンド ライン パラメーターを使用するパラメーターを渡すことができます。
mlflow run . -b databricks --backend-config cluster-spec.json \
-P script_name=train.py -P model_name=model123 \
--experiment-id <experiment-id>
Databricks Spark ジョブ プロジェクトには、次の制限が適用されます。
- このプロジェクトの種類では、
MLprojectファイル内のdocker_env、python_env、またはconda_envのセクションの指定はサポートされていません。 - プロジェクトの依存関係は、
databricks_spark_jobセクションのpython_librariesフィールドで指定する必要があります。Pythonのバージョンは、このプロジェクトタイプではカスタマイズできません。 - Spark実行環境は、Databricks Runtime 13.0 以降を使用するジョブ クラスターで実行するために、メインの ドライバー ランタイム環境を使用する必要があります。
- 同様に、プロジェクトに必須として定義されているすべての Python 依存関係は、 Databricks クラスター依存関係としてインストールする必要があります。 この動作は、ライブラリを別の環境にインストールする必要があった以前のプロジェクト実行動作とは異なります。
MLflow プロジェクトを実行する
MLflowDatabricksデフォルト ワークスペースの クラスターで プロジェクトを実行するには、次のコマンドを使用します。
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
ここで、 <uri> は MLflow プロジェクトを含む Git リポジトリ URI またはフォルダー、 <json-new-cluster-spec> は new_cluster 構造体を含む JSON ドキュメントです。 Git URI は https://github.com/<repo>#<project-folder>の形式にする必要があります。
クラスター仕様の例を次に示します。
{
"spark_version": "7.5.x-scala2.12",
"num_workers": 1,
"node_type_id": "memoptimized-cluster-1"
}
ワーカーにライブラリをインストールする必要がある場合は、「クラスター仕様」形式を使用してください。 Python wheel ファイルは DBFS にアップロードし、 pypi 依存関係として指定する必要があることに注意してください。 例えば:
{
"new_cluster": {
"spark_version": "7.5.x-scala2.12",
"num_workers": 1,
"node_type_id": "memoptimized-cluster-1"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
.eggまた、.jar依存関係は MLflow プロジェクトではサポートされていません。- Docker 環境を含む MLflow プロジェクトの実行はサポートされていません。
- MLflow プロジェクトを Databricksで実行する場合は、新しいクラスター仕様を使用する必要があります。既存のクラスターに対するプロジェクトの実行はサポートされていません。
SparkRの使用
MLflow プロジェクトの実行で SparkR を使用するには、まずプロジェクト コードで次のように SparkR をインストールしてインポートする必要があります。
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
その後、プロジェクトで SparkR セッションを初期化し、通常どおり SparkR を使用できます。
sparkR.session()
...
例
この例では、エクスペリメントを作成し、MLflow Databricksクラスターで チュートリアル プロジェクトを実行し、ジョブ 実行出力を表示し、エクスペリメントでの実行を表示する方法を示します。
必要条件
pip install mlflowを使用して MLflow をインストールします。- Databricks CLI をインストールして構成します。Databricks CLI認証メカニズムは、Databricksクラスターでジョブを実行するために必要です。
ステップ1:エクスペリメントを作成する
-
ワークスペースで、 エクスペリメントの作成 > MLflow を選択します。
-
「名前」フィールドに「
Tutorial」と入力します。 -
「作成 」をクリックします。エクスペリメント ID をメモします。 この例では、
14622565です。
手順 2: MLflow チュートリアル プロジェクトを実行する
次の手順では、 MLFLOW_TRACKING_URI 環境変数を設定してプロジェクトを実行し、トレーニング パラメーター、メトリクス、トレーニング済みモデルを前の手順でメモしたエクスペリメントに記録します。
-
MLFLOW_TRACKING_URI環境変数を Databricks ワークスペースに設定します。Bashexport MLFLOW_TRACKING_URI=databricks -
MLflow チュートリアル プロジェクトを実行し、 ワイン モデルをトレーニングします。
<experiment-id>を、前の手順でメモしたエクスペリメント ID に置き換えます。Bashmlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>Console=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u ===
=== Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz ===
=== Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz ===
=== Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks ===
=== Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... ===
=== Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 === -
MLflow 実行出力の最後の行にある URL
https://<databricks-instance>#job/<job-id>/run/1をコピーします。
ステップ 3: Databricks ジョブの実行を表示する
-
前の手順でコピーした URL をブラウザーで開き、Databricks ジョブ実行の出力を表示します。

ステップ 4: エクスペリメントと MLflow 実行の詳細を表示する
-
Databricksワークスペースのエクスペリメントに移動します。
-
エクスペリメントをクリックします。
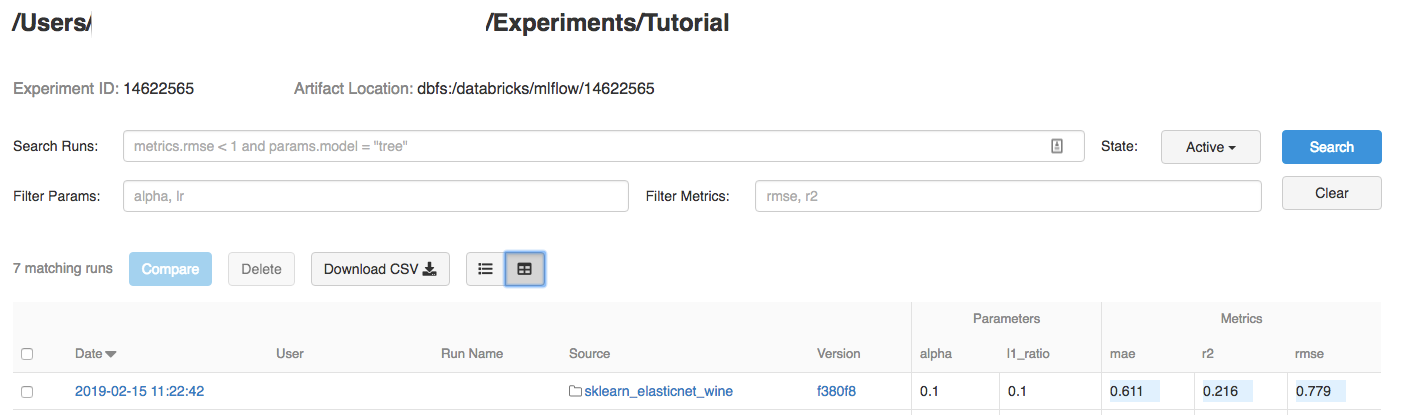
-
実行の詳細を表示するには、[日付] 列のリンクをクリックします。
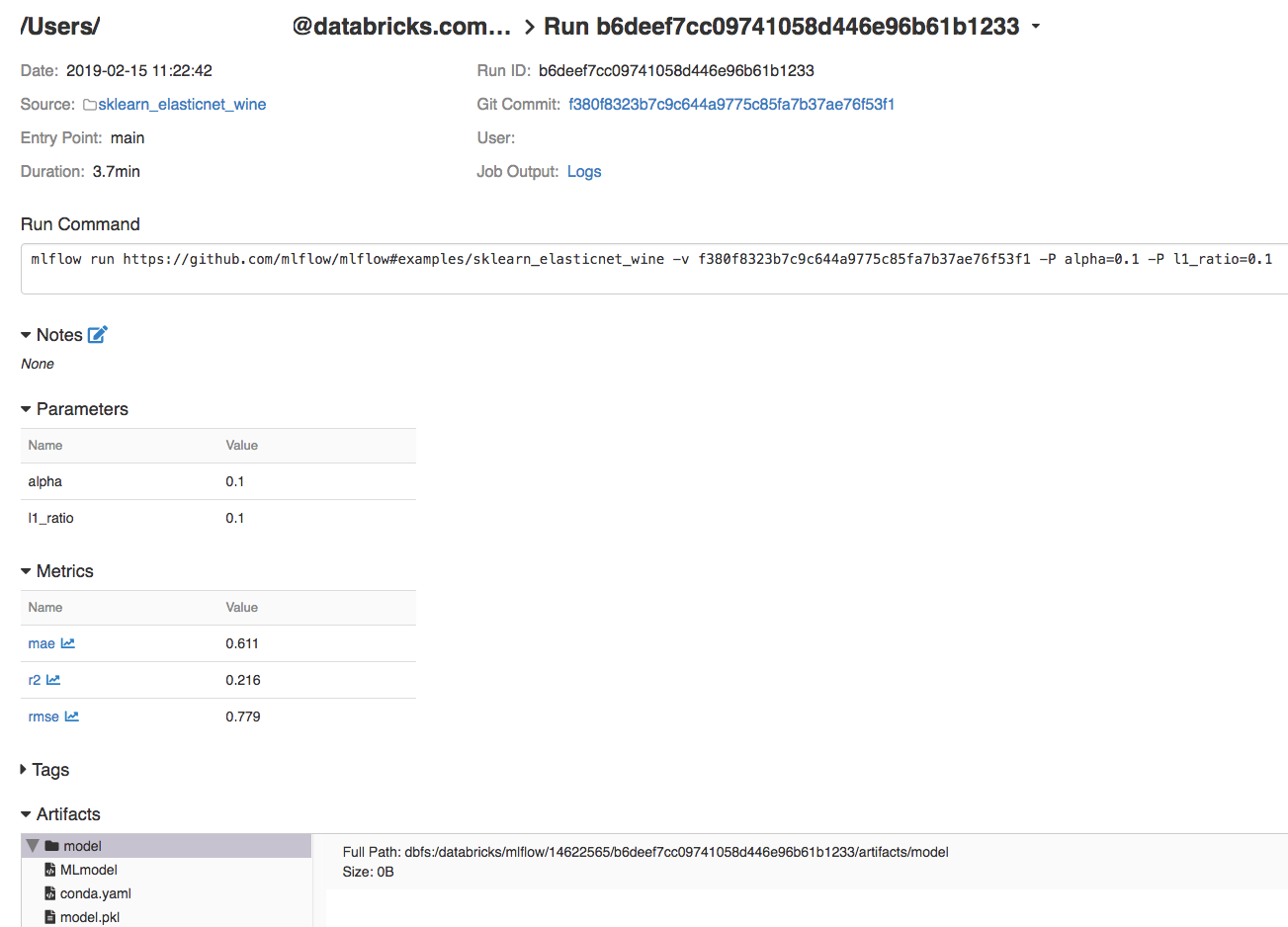
実行のログを表示するには、「ジョブ出力」フィールドの 「ログ 」リンクをクリックします。
リソース
機械学習フロー プロジェクトの例については、機械学習機能をコードに簡単に含めることを目的とした、すぐに実行できるプロジェクトのリポジトリを含む MLflow App Libraryを参照してください。