Legacy MLflow モデルサービング を Databricks
プレビュー
この機能は パブリック プレビュー段階です。
- このドキュメントは廃止されており、更新されない可能性があります。 このコンテンツに記載されている製品、サービス、またはテクノロジはサポートされなくなりました。
- この記事のガイダンスは、レガシ MLflow モデルサービング用です。 Databricks では、モデルサービング ワークフローをモデルサービングに移行して、拡張モデル エンドポイントのデプロイとスケーラビリティを実現することをお勧めします。 詳細については、「 Mosaic AI Model Servingを使用したモデルのデプロイ」を参照してください。
Legacy MLflow モデルサービングを使用すると、 Model Registry as REST エンドポイントから機械学習モデルをホストでき、モデルバージョンとそのステージの可用性に基づいて自動的に更新されます。 これは、現在クラシック コンピュート プレーンと呼ばれているもの内で独自のアカウントで実行される単一ノード クラスターを使用します。 このコンピュート プレーンには、仮想ネットワークとそれに関連付けられているコンピュート リソース (ノートブックとジョブのクラスター、プロ ウェアハウスとクラシック SQLウェアハウス、レガシ モデル サービング エンドポイントなど) が含まれています。
特定の登録済みモデルに対してモデルサービングを有効にすると、 Databricks によってモデルの一意のクラスターが自動的に作成され、そのクラスターにモデルのアーカイブされていないすべてのバージョンがデプロイされます。 Databricks は、エラーが発生した場合にクラスターを再開し、モデルのモデルサービングを無効にするとクラスターを終了します。 モデルサービングは、 Model Registry と自動的に同期し、新しく登録されたモデルバージョンをデプロイします。 デプロイされたモデル バージョンは、標準の REST API 要求を使用してクエリを実行できます。 Databricks は、標準認証を使用してモデルへの要求を認証します。
このサービスはプレビュー段階ですが、Databricks では、低スループットで重要でないアプリケーションに使用することをお勧めします。 ターゲットスループットは200 qps、ターゲット可用性は99.5%ですが、どちらも保証されていません。 さらに、要求ごとに 16 MB のペイロード サイズ制限があります。
各モデル バージョンは、MLflow モデル デプロイ を使用してデプロイされ、その依存関係で指定された Conda 環境で実行されます。
- クラスターは、アクティブなモデルバージョンが存在しない場合でも、サービスが有効になっている限り維持されます。 サービング クラスターを終了するには、登録済みモデルのモデルサービングを無効にします。
- クラスターは汎用クラスターと見なされ、汎用 Workload Priceが適用されます。
- Global initスクリプト はモデルサービング クラスターでは実行されません。
株式会社Anacondaは、anaconda.org チャンネル の利用規約 を更新しました。 新しいサービス条件に基づき、Anacondaのパッケージングと配布に依存する場合は、商用ライセンスが必要になる場合があります。 詳細については、 Anaconda Commercial Edition の FAQ を参照してください。 Anacondaチャンネルの使用は、その利用規約に準拠します。
MLflowv1.18 より前 (Databricks Runtime 8.3ML 以前) で記録された モデルは、デフォルトによって condadefaults チャンネル (https://repo.anaconda.com/pkgs/) で記録されていました依存関係として。 このライセンス変更に伴い、 Databricks は MLflow v1.18 以降を使用してログインしたモデルでの defaults チャンネルの使用を停止しました。 ログに記録されたデフォルト チャンネルは、コミュニティが管理する https://conda-forge.org/ を指す conda-forgeになりました。
MLflow v1.18より前のモデルをログに記録し、そのモデルのconda環境からdefaultsチャンネルを除外しなかった場合、そのモデルは意図していないdefaultsチャンネルに依存している可能性があります。モデルにこの依存関係があるかどうかを手動で確認するには、記録済みモデルにパッケージ化されているconda.yaml ファイル内のchannel値を調べます。たとえば、defaults チャンネルの依存関係を持つモデルのconda.yamlは、次のようになります。
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Databricksは、Anacondaとの関係の下で、モデルと対話するためのAnacondaリポジトリの使用が許可されているかどうかを判断できないため、Databricksは顧客に変更を加えることを強制していません。Databricks の使用による Anaconda.com リポジトリの使用が Anaconda の条件で許可されている場合は、何もする必要はありません。
モデルの環境で使用するチャンネルを変更したい場合は、新しい conda.yamlでモデルをモデルレジストリに再登録することができます。 これを行うには、log_model()の conda_env パラメーターでチャンネルを指定します。
log_model() APIの詳細については、使用しているモデル フレーバーのMLflowドキュメンテーション(log_model for a scikit-learnなど)を参照してください。
conda.yamlファイルの詳細については、 MLflow のドキュメントを参照してください。
必要条件
- Legacy MLflow モデルサービングは Python MLflow モデルでご利用いただけます。 すべてのモデルの依存関係は、conda環境で宣言する必要があります。 記録済みモデルの依存関係を参照してください。
- モデルサービングを有効にするには、 クラスター作成権限が必要です。
モデルサービング from Model Registry
モデルサービングはDatabricks からModel Registry で入手できます。
モデルサービングの有効化と無効化
モデルの配信は、 登録済みのモデルページから有効にします。
-
「Serving 」タブをクリックします。モデルでサービングが有効になっていない場合は、[ サービングを有効にする] ボタンが表示されます。
![[提供を有効にする] ボタン](/gcp/ja/assets/images/enable-serving-9a4b76edfd9316c53c5354dd1d788160.png)
-
「 Enable Serving」 をクリックします。 [サービス] タブが表示され、[ ステータス ] が [保留中] と表示されます。 数分後、[ ステータス ] が [準備完了] に変わります。
モデルの配信を無効にするには、[ 停止] をクリックします。
Validate モデルサービング
[ Serving ] タブでは、提供されたモデルにリクエストを送信し、レスポンスを表示できます。

モデル バージョン URI
デプロイされた各モデル バージョンには、1 つまたは複数の一意の URI が割り当てられます。 少なくとも、各モデルバージョンには、次のように構築されたURIが割り当てられます。
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
たとえば、 iris-classifierとして登録されたモデルのバージョン 1 を呼び出すには、次の URI を使用します。
https://<databricks-instance>/model/iris-classifier/1/invocations
モデルバージョンをステージごとに呼び出すこともできます。 たとえば、バージョン 1 が 本番運用 ステージにある場合は、次の URI を使用してスコアリングすることもできます。
https://<databricks-instance>/model/iris-classifier/Production/invocations
使用可能なモデル URI のリストは、配信ページの [モデル バージョン] タブの上部に表示されます。
提供済みバージョンの管理
すべてのアクティブな (アーカイブされていない) モデル バージョンがデプロイされ、URI を使用してクエリを実行できます。 Databricks は、新しいモデル バージョンが登録されると自動的にデプロイされ、古いバージョンがアーカイブされると自動的に削除されます。
登録済みモデルのデプロイされたすべてのバージョンは、同じクラスターを共有します。
モデルのアクセス権を管理する
モデルのアクセス権は、 Model Registryから継承されます。 サービング機能を有効または無効にするには、登録済みモデルに対する「管理」権限が必要です。読み取り権限を持つユーザーは、デプロイされた任意のバージョンをスコアリングできます。
デプロイされたモデルバージョンのスコアリング
デプロイされたモデルをスコアリングするには、UI を使用するか、モデル URI に REST API 要求を送信します。
UIによるスコア
これは、モデルをテストする最も簡単で最速の方法です。 モデル入力データをJSON形式で挿入し、[ リクエストを送信 ]をクリックできます。 モデルが入力例でログ記録されている場合 (上の図を参照)、 Load Example をクリックして入力例を読み込みます。
REST API リクエストによるスコアリング
標準の Databricks 認証を使用して、REST API を介してスコアリング要求を送信できます。次の例は、MLflow 1.x でのパーソナル アクセス トークンを使用した認証を示しています。
セキュリティのベストプラクティスとして、自動化されたツール、システム、スクリプト、アプリで認証する場合、Databricks では、ワークスペースユーザーではなく 、サービスプリンシパル に属する個人用アクセストークンを使用することをお勧めします。 サービスプリンシパルのトークンを作成するには、「 サービスプリンシパルのトークンの管理」を参照してください。
https://<databricks-instance>/model/iris-classifier/Production/invocations のようなMODEL_VERSION_URI (<databricks-instance> は Databricks インスタンスの名前) と Databricks REST API トークン DATABRICKS_API_TOKENを指定すると、次の例は、提供されるモデルをクエリする方法を示しています。
次の例は、MLflow 1.x で作成されたモデルのスコアリング形式を反映しています。 MLflow 2.0 を使用する場合は、 要求ペイロードの形式を更新する必要があります。
- Bash
- Python
- PowerBI
データフレーム入力を受け入れるモデルをクエリするスニペット。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
テンソル入力を受け入れるモデルをクエリするスニペット。Tensor 入力は、 TensorFlow Serving の API ドキュメントで説明されているようにフォーマットする必要があります。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
Power BI Desktop でデータセットをスコアリングするには、次の手順を使用します。
-
スコアリングするデータセットを開きます。
-
[データの変換] に移動します。
-
左側のパネルを右クリックし、[ 新しいクエリの作成 ] を選択します。
-
[詳細エディター> [表示 ] に移動します。
-
適切な
DATABRICKS_API_TOKENを入力してMODEL_VERSION_URIに入力した後、クエリ本文を次のコードスニペットに置き換えます。(dataset as table ) as table =>
let
call_predict = (dataset as table ) as list =>
let
apiToken = DATABRICKS_API_TOKEN,
modelUri = MODEL_VERSION_URI,
responseList = Json.Document(Web.Contents(modelUri,
[
Headers = [
#"Content-Type" = "application/json",
#"Authorization" = Text.Format("Bearer #{0}", {apiToken})
],
Content = Json.FromValue(dataset)
]
))
in
responseList,
predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))),
predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}),
datasetWithPrediction = Table.Join(
Table.AddIndexColumn(predictionsTable, "index"), "index",
Table.AddIndexColumn(dataset, "index"), "index")
in
datasetWithPrediction -
クエリに目的のモデル名を付けます。
-
データセットの高度なクエリ エディターを開き、モデル関数を適用します。
モニター提供モデル
サービング ページには、サービング クラスターのステータス インジケータと個々のモデル バージョンが表示されます。
- サービング クラスターの状態を調べるには、このモデルのすべてのサービング イベントの一覧を表示する [モデル イベント ] タブを使用します。
- 1 つのモデルバージョンの状態を調べるには、「 モデルバージョン 」タブをクリックし、スクロールして 「ログ 」タブまたは 「バージョンイベント 」タブを表示します。
![[サービング] タブ](/gcp/ja/assets/images/serving-tab-1d20e41a2a8d52dc02eee7c224665b52.png)
サービングクラスターのカスタマイズ
サービング クラスターをカスタマイズするには、[ サービング ] タブの [クラスター設定 ] タブを使用します。
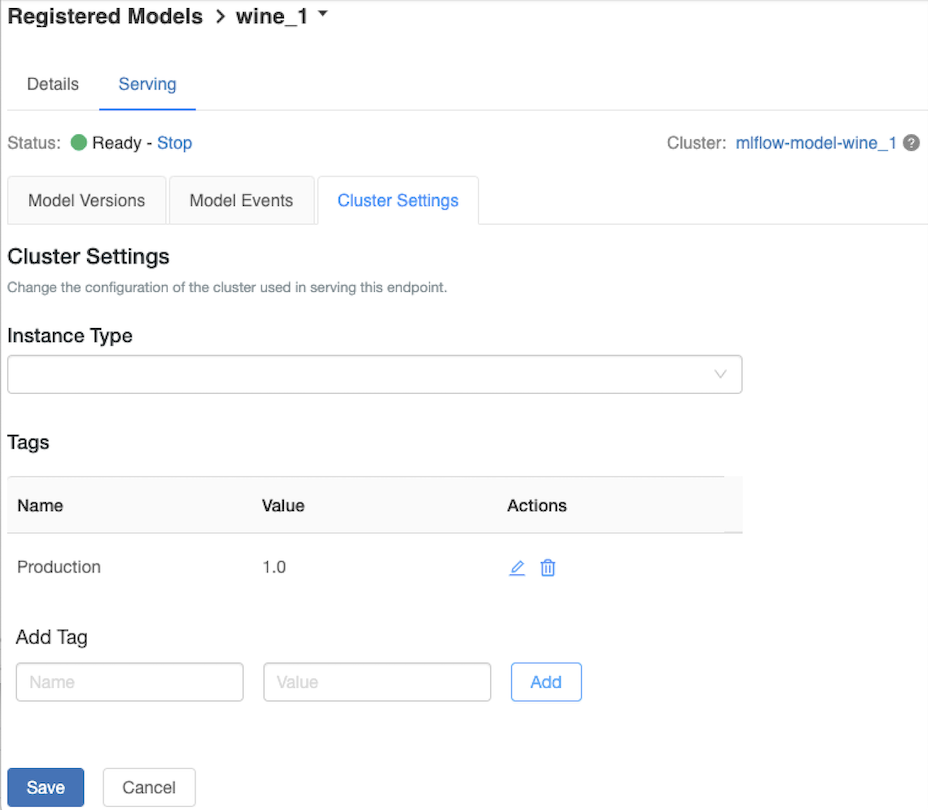
- サービングクラスターのメモリサイズとコア数を変更するには、[ Instance Type ] ドロップダウンメニューを使用して、目的のクラスター設定を選択します。 [保存 ] をクリックすると、既存のクラスターが終了し、指定した設定で新しいクラスターが作成されます。
- タグを追加するには、[ タグの追加 ] フィールドに名前と値を入力し、[ 追加 ] をクリックします。
- 既存のタグを編集または削除するには、「 タグ」(Tags ) テーブルの 「アクション」(Actions ) コラムにあるアイコンの 1 つをクリックします。
既知のエラー
ResolvePackageNotFound: pyspark=3.1.0
このエラーは、モデルが pyspark に依存し、Databricks Runtime 8.x を使用してログに記録されている場合に発生する可能性があります。このエラーが表示された場合は、モデルのログ記録時にpysparkバージョンを明示的に指定します。
conda_env パラメーター。
Unrecognized content type parameters: format
このエラーは、新しい MLflow 2.0 スコアリング プロトコル形式の結果として発生する可能性があります。 このエラーが表示される場合は、古いスコアリング要求形式を使用している可能性があります。 このエラーを解決するには、次の操作を行います。
- スコアリング要求の形式を最新のプロトコルに更新します。
次の例は、MLflow 2.0 で導入されたスコアリング形式を反映しています。 MLflow 1.x を使用する場合は、 log_model() API 呼び出しを変更して、目的の MLflow バージョンの依存関係を extra_pip_requirements パラメーターに含めることができます。 これにより、適切なスコアリング形式が使用されることが保証されます。
mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])
タブ :::タブ-item[bash] Pandas データフレーム入力を受け入れるモデルのクエリを実行します。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{
"dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2},
{"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}]
}'
テンソル入力を受け入れるモデルをクエリします。Tensor 入力は、 TensorFlow Serving の API ドキュメントで説明されているようにフォーマットする必要があります。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
:::
タブ-item[Python]
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
data_json = json.dumps(data_dict)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
:::
タブ-item[PowerBI] Power BI Desktopでデータセットをスコアリングするには、次の手順に従います。
-
スコアリングするデータセットを開きます。
-
[データの変換] に移動します。
-
左側のパネルを右クリックし、[ 新しいクエリの作成 ] を選択します。
-
[詳細エディター> [表示 ] に移動します。
-
適切な
DATABRICKS_API_TOKENを入力してMODEL_VERSION_URIに入力した後、クエリ本文を次のコードスニペットに置き換えます。(dataset as table ) as table =>
let
call_predict = (dataset as table ) as list =>
let
apiToken = DATABRICKS_API_TOKEN,
modelUri = MODEL_VERSION_URI,
responseList = Json.Document(Web.Contents(modelUri,
[
Headers = [
#"Content-Type" = "application/json",
#"Authorization" = Text.Format("Bearer #{0}", {apiToken})
],
Content = Json.FromValue(dataset)
]
))
in
responseList,
predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))),
predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}),
datasetWithPrediction = Table.Join(
Table.AddIndexColumn(predictionsTable, "index"), "index",
Table.AddIndexColumn(dataset, "index"), "index")
in
datasetWithPrediction -
クエリに目的のモデル名を付けます。
-
データセットの高度なクエリ エディターを開き、モデル関数を適用します。::: ::::
- スコアリング要求で MLflow クライアント (
mlflow.pyfunc.spark_udf()など) を使用している場合は、MLflow クライアントをバージョン 2.0 以降にアップグレードして最新の形式を使用します。 MLflow 2.0 で更新された MLflow モデル スコアリング プロトコルの詳細については、こちらを参照してください。
サーバーが受け入れる入力データ形式Pandas (分割指向形式など) の詳細についてはMLflow の資料 を参照してください。