Hyperopt ハイパーパラメーターチューニングの並列化
このノートブックの例では、 HyperoptとSparkTrialsを使用して、単一マシンのハイパーチューニングをDatabricksクラスターにスケールする方法を示します。 Iris データセットでscikit-learn SVM 分類器を調整するには、まず単一マシンfmin()ワークフローを構築し、それをSparkワーカー全体で並列化して、 MLflowすべてのトライアルを自動的に追跡します。
必要なパッケージをインポートし、データセットをロードします。
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
from hyperopt import fmin, tpe, hp, SparkTrials, STATUS_OK, Trials
# If you are running Databricks Runtime for Machine Learning, `mlflow` is already installed and you can skip the following line.
import mlflow
# Load the iris dataset from scikit-learn
iris = iris = load_iris()
X = iris.data
y = iris.target
パート 1. 単一マシンのHyperoptワークフロー
Hyperoptワークフローのステップは次のとおりです。
- 最小化する関数を定義する。
- ハイパーパラメータに関する探索空間を定義する。
- 検索アルゴリズムを選択してください。
- Hyperopt
fmin()を使用してチューニングアルゴリズムを実行します。
詳細については、 Hyperoptドキュメントを参照してください。
最小化する関数を定義する
この例では、サポートベクターマシン分類器を使用します。目的は、正則化の最適値を見つけることですC 。
Hyperoptワークフローのコードの大部分は目的関数内にあります。 この例では、scikit-learn のサポートベクター分類器を使用しています。
クラスターが Databricks Runtime 11.3 ML を使用している場合は、サポートベクター分類器を編集して位置引数clf = SVC(C)を受け取るようにします。
def objective(C):
# Create a support vector classifier model
clf = SVC(C=C)
# Use the cross-validation accuracy to compare the models' performance
accuracy = cross_val_score(clf, X, y).mean()
# Hyperopt tries to minimize the objective function. A higher accuracy value means a better model, so you must return the negative accuracy.
return {'loss': -accuracy, 'status': STATUS_OK}
ハイパーパラメータに関する探索空間を定義する
検索スペースと問題式の定義の詳細については、 Hyperoptドキュメントを参照してください。
search_space = hp.lognormal('C', 0, 1.0)
検索アルゴリズムを選択してください
主な選択肢は以下の2つです。
hyperopt.tpe.suggest: ツリー・オブ・パーゼン推定器は、過去の結果に基づいて探索する新しいハイパーパラメータ設定を反復的かつ適応的に選択するベイジアンのアプローチです。hyperopt.rand.suggestランダムサーチは、探索空間をサンプリングする非適応的なアプローチです。
algo=tpe.suggest
Hyperoptを使用してチューニングアルゴリズムを実行します。 fmin()
max_evals 、テストするハイパーパラメータ空間内の最大点数、つまり適合および評価するモデルの最大数に設定します。
argmin = fmin(
fn=objective,
space=search_space,
algo=algo,
max_evals=16)
# Print the best value found for C
print("Best value found: ", argmin)
パート2:Apache SparkとMLflowを使用した分散チューニング
チューニングを分散させるには、 fmin()に引数をもう 1 つ追加します。それはSparkTrialsと呼ばれるTrialsクラスです。
SparkTrials オプションの引数を2つ取ります。
parallelism:同時に適合および評価するモデルの数。余裕は、利用可能なSparkタスク スロットの数です。timeout:fmin()が実行できる最大時間(秒単位)。デフォルトでは、最大時間制限はありません。
この例では、コマンド 7 で定義された非常に単純な目的関数を使用しています。この場合、関数はすぐに実行され、 Sparkの起動オーバーヘッドが計算時間の大部分を占めるため、分散処理の場合の計算にはより多くの時間がかかります。 実際の問題では、目的関数はより複雑になり、 SparkTrailsを使用して計算を分散させる方が、単一マシンでのチューニングよりも高速になります。
MLflowの自動追跡はデフォルトで有効になっています。使用するには、例に示すように、 fmin()を呼び出す前にmlflow.start_run()を呼び出します。
from hyperopt import SparkTrials
# To display the API documentation for the SparkTrials class, uncomment the following line.
# help(SparkTrials)
spark_trials = SparkTrials()
with mlflow.start_run():
argmin = fmin(
fn=objective,
space=search_space,
algo=algo,
max_evals=16,
trials=spark_trials)
# Print the best value found for C
print("Best value found: ", argmin)
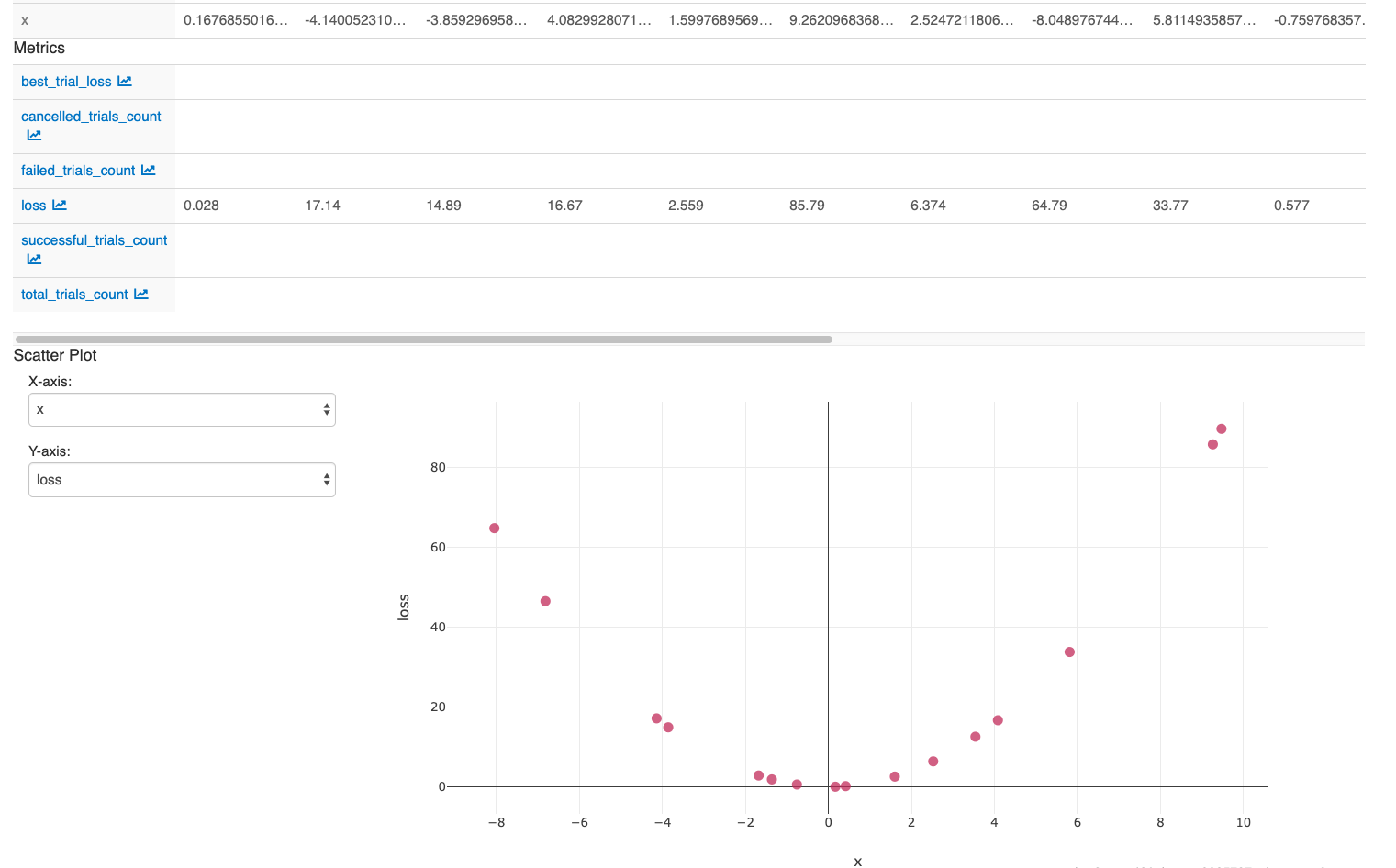
ノートブックに関連付けられたMLflowエクスペリメントを表示するには、右上のノートブック コンテキスト バーにある エクスペリメント アイコンをクリックします。 そこでは、すべての実行結果を見ることができます。MLflow UI で実行を表示するには、 「エクスペリメント 実行」 の右端にあるアイコンをクリックします。
チューニングCの効果を調べるには:
- 結果の実行結果を選択し、 「比較」 をクリックします。
- 散布図のページで、X軸に C 、Y軸に losthを 選択します。
ノートブックの最後のセルでアクションを実行すると、MLflow UI に次の情報が表示されます。