Classificação de dados
Visualização
Este recurso está em Visualização Pública.
Esta página descreve como usar a Classificação de Dados Databricks no Unity Catalog para classificar e tag automaticamente dados confidenciais no seu catálogo.
Um catálogo de dados pode ter uma grande quantidade de dados, muitas vezes contendo dados confidenciais conhecidos e desconhecidos. É essencial que as equipes de dados entendam que tipo de dados confidenciais existem em cada tabela para que possam governar e democratizar o acesso a esses dados.
Para resolver esse problema, Databricks Data Classification usa um agente AI para classificar e tag automaticamente tabelas no seu catálogo. Isso permite que você descubra dados confidenciais e aplique controles de governança sobre os resultados, usando ferramentas como o controle de acesso baseado em atributos (ABAC) do Unity Catalog. Para obter uma lista de tags suportadas, consulte tagsde classificação suportadas.
Com este recurso, é possível:
- Classificar dados : o mecanismo usa um sistema AI de agente para classificar e tag automaticamente quaisquer tabelas no Unity Catalog.
- Otimize custos por meio de varredura inteligente : o sistema determina de forma inteligente quando escanear seus dados, aproveitando o Unity Catalog e o Data Intelligence Engine. Isso significa que a digitalização é incremental e otimizada para garantir que todos os novos dados sejam classificados sem configuração manual.
- Revisar e proteger dados confidenciais : a exibição de resultados auxilia na visualização de resultados de classificação e na proteção de dados confidenciais por tags e na criação de políticas de controle de acesso para cada classe.
A Classificação de Dados Databricks usa armazenamentodefault para armazenar resultados de classificação. Você não será cobrado pelo armazenamento.
A Classificação de Dados do Databricks usa um modelo de linguagem grande (LLM) para auxiliar na classificação.
Requisitos
A classificação de dados é um recurso de visualização em nível de workspacee só pode ser gerenciada por um administrador workspace ou account . Para obter instruções, consulte gerenciar visualizações Databricks.
O modelo que alimenta essa função é disponibilizado usando as APIs do Mosaic AI Model Serving Foundation. Llama 3.1 está licenciado sob a Licença Llama 3.1 comunidade, Copyright © Meta Platforms, Inc. Todos os direitos reservados. Consulte Licenças e termos de desenvolvedor de modelo aplicáveis para obter mais informações.
Se surgirem modelos no futuro com melhor desempenho de acordo com os benchmarks internos da Databricks, a Databricks poderá alterar os modelos e atualizar a documentação.
- É necessário que você tenha o serverless compute habilitado. Consulte Conecte-se a serverless compute .
- Para habilitar a classificação de dados, você deve ser o proprietário do catálogo ou ter privilégios
USE_CATALOGeMANAGEnele. - Para view a tabela de resultados, você deve ter as seguintes permissões:
USE CATALOGeUSE SCHEMA, além deSELECTna tabela. Veja a tabela do sistema de resultados.
Usar classificação de dados
Para usar a classificação de dados em um catálogo:
-
Navegue até o catálogo e clique na tab Detalhes .
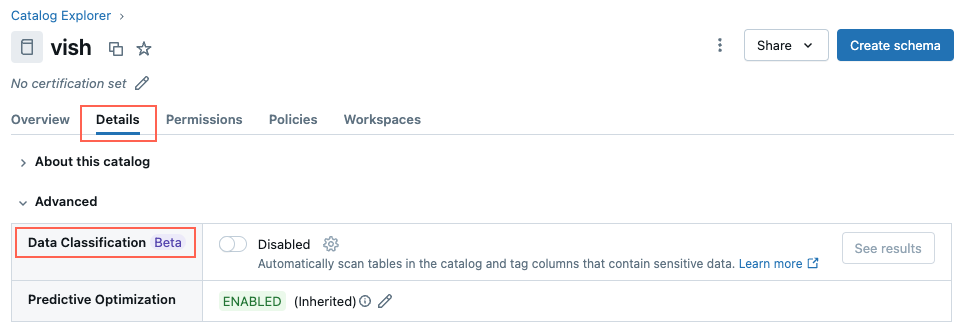
-
Clique no botão Classificação de dados para ativá-lo.
-
A caixa de diálogo Habilitar classificação de dados é exibida. Por default, todos os esquemas são incluídos. Para incluir apenas alguns esquemas, selecione-os no menu dropdown Esquemas a serem incluídos .
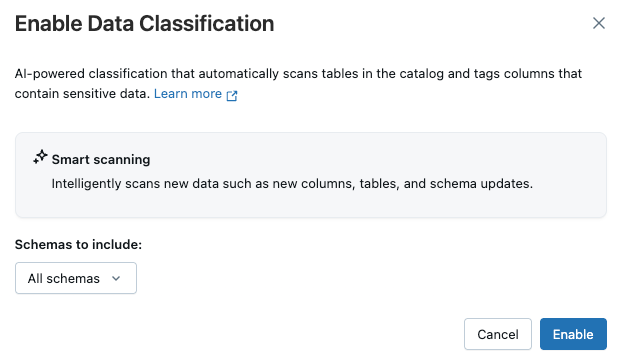
-
Clique em Habilitar .
Isso cria uma tarefa em segundo plano que verifica incrementalmente todas as tabelas no catálogo ou nos esquemas selecionados.
O mecanismo de classificação depende de varredura inteligente para determinar quando varrer uma tabela. Novas tabelas e colunas em um catálogo geralmente são digitalizadas dentro de 24 horas após sua criação.
visualizar resultados da classificação
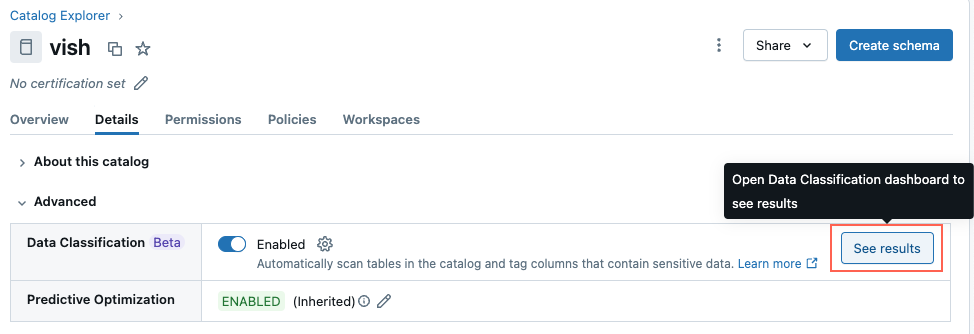
Para view os resultados da classificação, clique em Ver resultados ao lado do botão de alternância.
Uma página de resultados é aberta, mostrando os resultados da classificação para todas as tabelas no catálogo. Para selecionar um catálogo diferente, use o seletor no canto superior esquerdo da página. Um SQL warehouse serverless é necessário e aparece no canto superior direito da página.
A página de resultados lista todas as tags de classificação que foram identificadas no catálogo. Todas as políticas ABAC existentes que fazem referência às tags do sistema de classificação de dados (class.xx) aparecem na tabela.
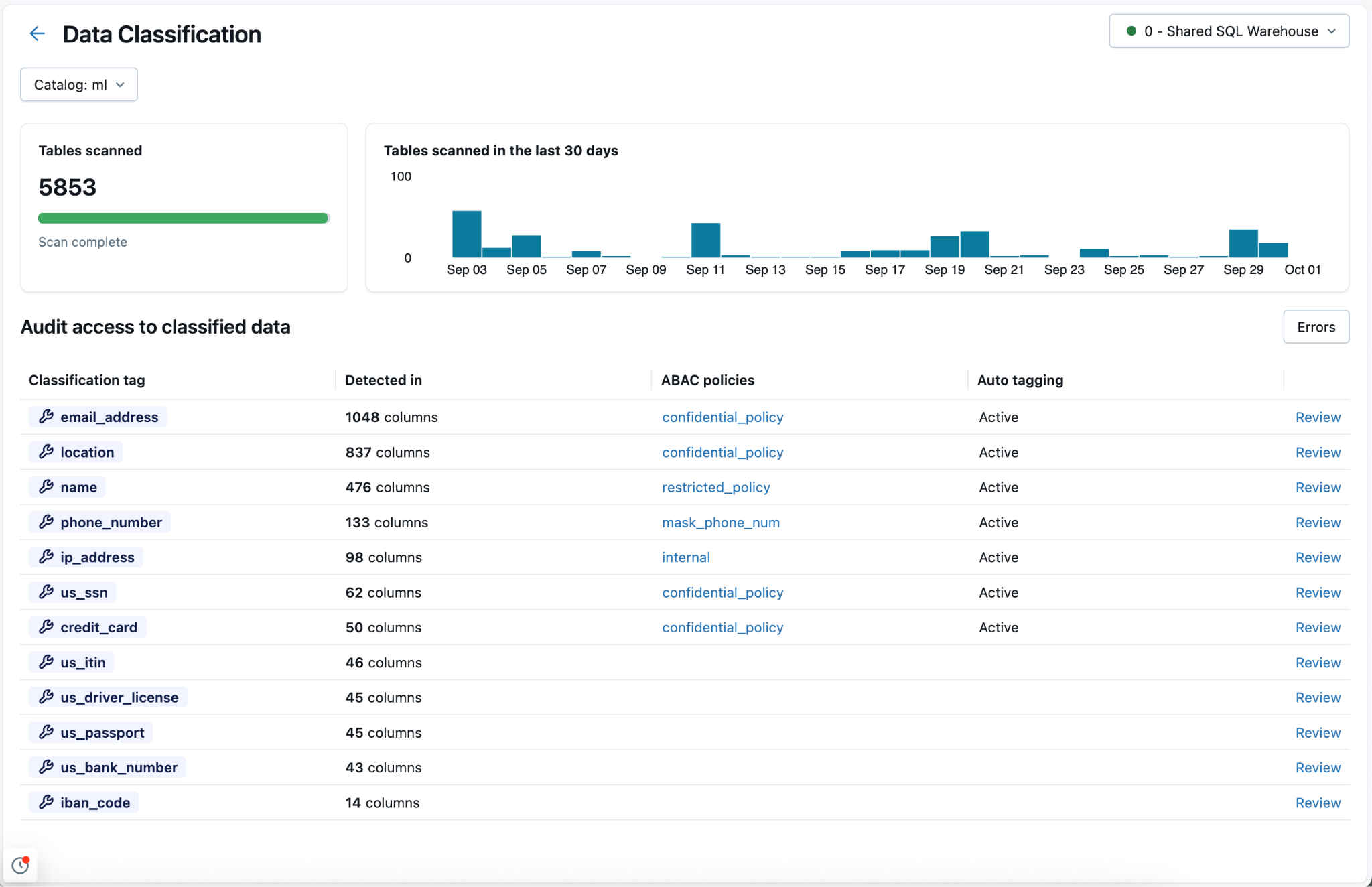
Para revisar os resultados de uma tag de classificação específica, clique em Revisar na coluna mais à direita da linha correspondente.
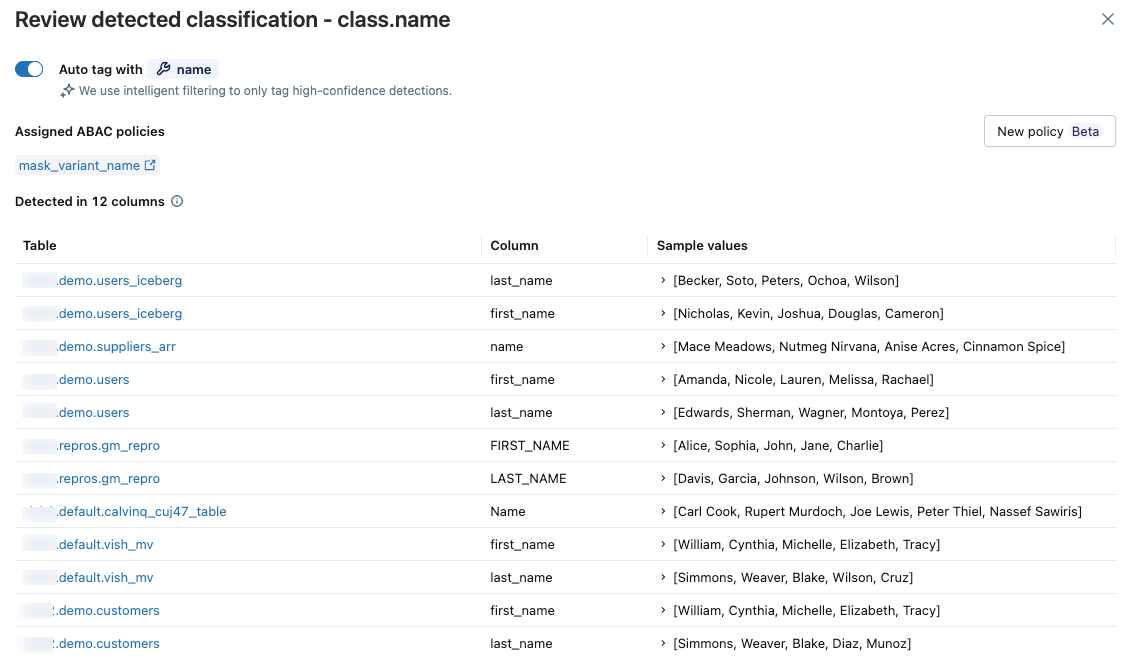
Um painel é exibido, exibindo as tabelas para as quais a classificação de dados detectou a tag de classificação com alta confiança. Revise as tabelas, colunas e valores de amostra. Os valores de amostra só aparecem se você tiver acesso à tabela de resultados. Veja a tabela do sistema de resultados.
Se as colunas identificadas corresponderem às suas expectativas, você poderá habilitar tags automáticas para a tag de classificação deste catálogo. Quando as tags automáticas estão ativadas, todas as detecções existentes e futuras dessa classificação são tags.
Para habilitar tags automáticas, alterne a tag automática com ... . Mais tarde, você pode desabilitar as tags automáticas usando o mesmo botão. Quando você desabilita tags, nenhuma tags futura é aplicada, mas tags existentes não são removidas.
Quando você habilita tags automáticas, tags não são preenchidas imediatamente. Eles serão preenchidos na próxima verificação, que deverá entrar em vigor em 24 horas. Classificações subsequentes serão marcadas imediatamente.
A tabela do sistema de resultados
A classificação de dados cria uma tabela de sistema chamada system.data_classification.results para armazenar resultados que, por default são acessíveis somente ao administrador account . O administrador account pode compartilhar esta tabela. A tabela só fica acessível quando você usa compute serverless . Para obter detalhes sobre esta tabela, consulte Referência da tabela do sistema de classificação de dados.
A tabela de resultados system.data_classification.results contém todos os resultados de classificação em todo o metastore e inclui valores de amostra de tabelas em cada catálogo. Você deve compartilhar esta tabela somente com usuários que tenham o privilégio de ver os resultados da classificação em todo o metastore, incluindo valores de amostra.
As seguintes permissões são necessárias para view a tabela de resultados: USE CATALOG e USE SCHEMA, além de SELECT na tabela. Usuários com acesso MANAGE ou SELECT a um catálogo podem ver resultados na página, mas não podem ver valores de amostra.
Configurar controles de governança com base nos resultados da classificação de dados
Mascarar uso de dados confidenciais em uma política ABAC
A Databricks recomenda usar o controle de acesso baseado em atributos (ABAC) do Unity Catalog para criar controles de governança com base nos resultados da classificação de dados.
Para criar uma política, clique em Nova política . O formulário de política é pré-preenchido para mascarar colunas com a tag de classificação que está sendo revisada. Para mascarar os dados, especifique qualquer função de mascaramento registrada no Unity Catalog e clique em Salvar .
Você também pode criar uma política que abranja diversas tags de classificação, alterando a coluna Quando para atende à condição e fornecendo diversas tags.
Por exemplo, para criar uma política chamada "Confidencial" que mascara qualquer nome, email ou número de telefone, defina a condição meets como hasTag("class.name") OR hasTag("class.email_address") OR hasTag("class.phone_number").
Descoberta e exclusão do GDPR
Este exemplo de Notebook mostra como você pode usar a classificação de dados para auxiliar na descoberta e exclusão de dados para compliance GDPR .
Descoberta e exclusão GDPR usando o Notebook de classificação de dados
Como lidar com tags incorretas
Se os dados estiverem marcados incorretamente, você pode remover a tag manualmente. A tag não será reaplicada em verificações futuras.
Para remover uma tag usando a interface do usuário, navegue até a tabela no Catalog Explorer e edite as tags da coluna.
Para remover uma tag usando SQL:
ALTER TABLE catalog.schema.table
ALTER COLUMN col
UNSET TAGS ('class.phone_number', 'class.us_ssn')
Erros de digitalização
Se ocorrer algum erro durante a verificação, um botão Erros aparecerá no canto superior direito da tabela de resultados.
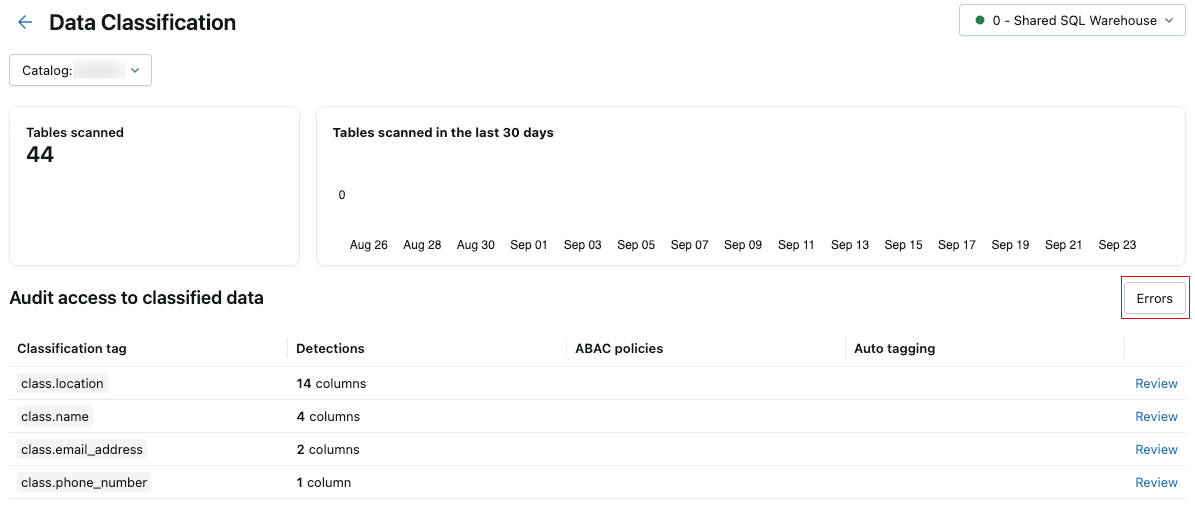
Clique no botão para exibir as tabelas que falharam na verificação e as mensagens de erro associadas.

Por default, falhas que ocorreram em tabelas individuais são ignoradas e repetidas no dia seguinte.
visualizar despesas com classificação de dados
Para entender como a Classificação de Dados é cobrada, consulte a página de preços. Você pode view despesas relacionadas à Classificação de Dados executando uma consulta ou visualizando o painel de uso.
A digitalização inicial é mais custosa do que as digitalizações subsequentes no mesmo catálogo, pois essas digitalizações são incrementais e normalmente geram custos mais baixos.
visualizar o uso na tabela do sistema system.billing.usage
Você pode consultar as despesas de classificação de dados de system.billing.usage. Os campos created_by e catalog_id podem ser usados opcionalmente para detalhar os custos:
created_byIncluir para visualizar os custos por usuário que iniciou o uso.catalog_idInclua para visualizar os custos por catálogo. O ID do catálogo é mostrado na tabelasystem.data_classification.results.
Exemplo de consulta para os últimos 30 dias:
SELECT
usage_date,
identity_metadata.created_by,
usage_metadata.catalog_id,
SUM(usage_quantity) AS dbus
FROM
system.billing.usage
WHERE
usage_date >= DATE_SUB(CURRENT_DATE(), 30)
AND billing_origin_product = 'DATA_CLASSIFICATION'
GROUP BY
usage_date,
created_by,
catalog_id
ORDER BY
usage_date DESC,
created_by;
visualizar o uso no painel de uso
Caso já possua um painel de uso configurado em workspace, é possível utilizá-lo para filtrar o uso selecionando o rótulo “Classificação de dados” em Projeto de origem de faturamento. Se você não tiver um painel de uso configurado, poderá importar um e aplicar a mesma filtragem. Para obter detalhes, consulte Painéis de uso.
tagsde classificação suportadas
As tabelas a seguir listam as tags controladas pelo sistema e suportadas pela Classificação de Dados.
Etiquetas disponíveis para clientes globais
Aula | Descrição |
|---|---|
classe.cartão_de_crédito | Número do cartão de crédito |
classe.endereço_de_email | Endereço de e-mail |
classe.iban_code | Número de conta bancária internacional (IBAN) |
classe.endereço_ip | Endereço de protocolo da Internet (IPv4 ou IPv6) |
classe.localização | Localização |
classe.nome | Nome de uma pessoa |
classe.número_de_telefone | Número de telefone |
classe.url | URL |
classe.us_bank_number | Número do banco dos EUA |
class.us_driver_license | Carteira de motorista dos EUA |
classe.us_itin | Número de identificação de contribuinte individual dos EUA |
class.us_passaporte | Passaporte dos EUA |
classe.us_ssn | Número do Seguro Social dos EUA |
classe.vin | Número de Identificação do Veículo (VIN) |
Etiquetas disponíveis para clientes europeus
Essas tags estão disponíveis no espaço de trabalho em regiões da Europa.
Aula | Descrição |
|---|---|
cartão de identificação da classe | Número do cartão de identidade alemão (Personalausweisnummer) |
classe.de_svnr | Número de seguro social alemão (Sozialversicherungsnummer) |
classe.de_id_imposto | ID fiscal alemão (Steueridentifikationsnummer) |
classe.uk_nhs | Número do Serviço Nacional de Saúde (NHS) do Reino Unido |
classe.uk_nino | Número de Seguro Nacional do Reino Unido (NINO) |
Etiquetas disponíveis para clientes australianos
Essas tags estão disponíveis no Workspace em regiões da Austrália.
Aula | Descrição |
|---|---|
classe.au_medicare | Número do cartão Medicare australiano |
classe.au_tfn | Número de Identificação Fiscal Australiano (TFN) |
Limitações
- view e métricas view não são suportadas. Se a view for baseada em tabelas existentes, Databricks recomenda classificar as tabelas subjacentes para verificar se elas contêm dados confidenciais.