評価のトラブルシューティング (MLflow 2)
この記事では、Mosaic AIエージェント評価を使用して生成AIアプリケーションを評価する際に発生する可能性のある問題と、その修正方法について説明します。
モデルエラー
mlflow.evaluate(..., model=<model>, model_type="databricks-agent") 評価セットの各行で指定されたモデルを呼び出します。たとえば、生成モデルが一時的に利用できない場合、モデルの呼び出しが失敗する可能性があります。この場合、出力には次の行が含まれます。nは評価された行の総数、kはエラーのある行の数です。
**Evaluation completed**
- k/n contain model errors
このエラーは、評価セットの特定の行の詳細を表示するときに MLFlow UI に表示されます。
評価結果 データフレーム でエラーを表示することもできます。 この場合、評価結果には model_error_messageを含む行が表示されます。 これらのエラーを表示するには、次のコード スニペットを使用します。
result = mlflow.evaluate(..., model=<your model>, model_type="databricks-agent")
eval_results_df = result.tables['eval_results']
display(eval_results_df[eval_results_df['model_error_message'].notna()][['request', 'model_error_message']])

エラーが回復可能な場合は、失敗した行のみで評価を再実行できます。
result = mlflow.evaluate(..., model_type="databricks-agent")
eval_results_df = result.tables['eval_results']
# Filter rows where 'model_error_message' is not null and select columns required for evaluation.
input_cols = ['request_id', 'request', 'expected_retrieved_context', 'expected_response']
retry_df = eval_results_df.loc[
eval_results_df['model_error_message'].notna(),
[col for col in input_cols if col in eval_results_df.columns]
]
retry_result = mlflow.evaluate(
data=retry_df,
model=<your model>,
model_type="databricks-agent"
)
retry_result_df = retry_result.tables['eval_results']
merged_results_df = eval_results_df.set_index('request_id').combine_first(
retry_result.tables['eval_results'].set_index('request_id')
).reset_index()
# Reorder the columns to match the original eval_results_df column order
merged_results_df = merged_results_df[eval_results_df.columns]
display(merged_results_df)
mlflow.evaluateを再実行すると結果がログに記録され、メトリクスが新しいMLflow実行に集約されます。上記で生成されたマージされたデータフレームはノートブックで表示できます。
ジャッジエラー
mlflow.evaluate(..., model_type="databricks-agent") 組み込みのジャッジと、オプションでカスタムジャッジを使用してモデル出力を評価します。たとえば、TOKEN_RATE_LIMIT_EXCEEDEDまたはMISSING_INPUT_FIELDSが原因で、ジャッジが入力データの行を評価できない場合があります。
ジャッジが行を評価しなかった場合、出力には次の行が含まれます。nは評価された行の総数、kは次のエラーのある行の数です。
**Evaluation completed**
- k/n contain judge errors
このエラーは MLFlow UI に表示されます。 特定の評価をクリックすると、ジャッジエラーが対応する評価名の下に表示されます。

この場合、評価結果には<judge_name>/error_messageを含む行が表示されます (例:response/llm_judged/faithfulness/error_message)。次のコードスニペットを使用してこれらのエラーを表示できます。
result = mlflow.evaluate(..., model=<your model>, model_type="databricks-agent")
eval_results_df = result.tables['eval_results']
llm_judges_error_columns = [col for col in eval_results_df.columns if 'llm_judged' in col and 'error_message' in col]
columns_to_display = ['request_id', 'request'] + llm_judges_error_columns
# Display the filtered DataFrame
display(eval_results_df[eval_results_df[llm_judges_error_columns].notna().any(axis=1)][columns_to_display])
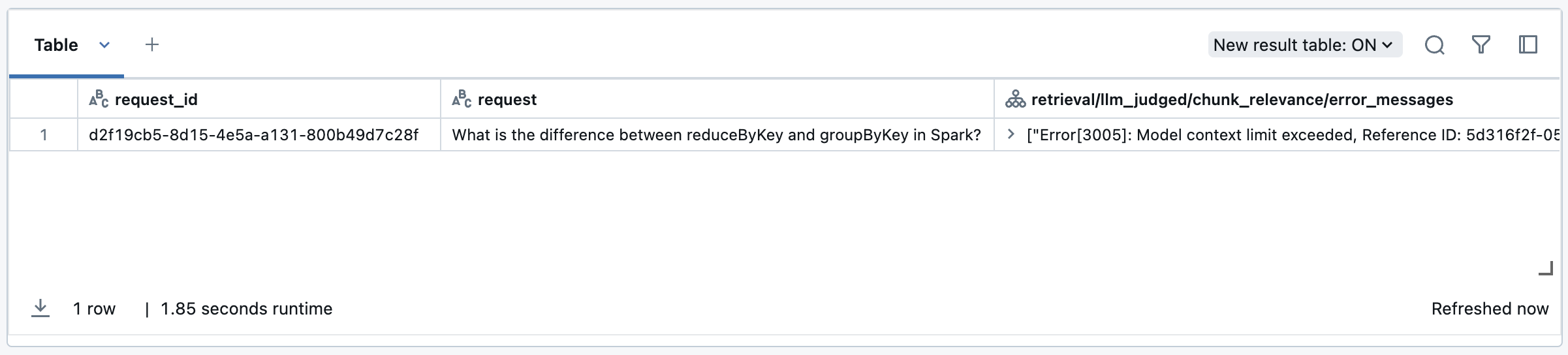
エラーが解決した後、または回復可能な場合は、次の例に従って、障害のある行だけで評価を再実行できます。
result = mlflow.evaluate(..., model_type="databricks-agent")
eval_results_df = result.tables['eval_results']
llm_judges_error_columns = [col for col in eval_results_df.columns if 'llm_judges' in col and 'error_message' in col]
input_cols = ['request_id', 'request', 'expected_retrieved_context', 'expected_response']
retry_df = eval_results_df.loc[
eval_results_df[llm_judges_error_columns].notna().any(axis=1),
[col for col in input_cols if col in eval_results_df.columns]
]
retry_result = mlflow.evaluate(
data=retry_df,
model=<your model>,
model_type="databricks-agent"
)
retry_result_df = retry_result.tables['eval_results']
merged_results_df = eval_results_df.set_index('request_id').combine_first(
retry_result_df.set_index('request_id')
).reset_index()
merged_results_df = merged_results_df[eval_results_df.columns]
display(merged_results_df)
mlflow.evaluateを再実行すると結果がログに記録され、メトリクスが新しいMLflow実行に集約されます。上記で生成されたマージされたデータフレームはノートブックで表示できます。
一般的なエラー
これらのエラーコードが引き続き発生する場合は、Databricksアカウントチームにお問い合わせください。 次に、一般的なエラーコードの定義とその解決方法を示します
エラーコード | 意味 | 解決方法 |
|---|---|---|
1001 | 入力フィールドの欠落 | 必須入力フィールドを確認して更新します。 |
1002 | いくつかのショットプロンプトにおけるフィールドの欠落 | 提供されているいくつかのショットの例の必須入力フィールドを確認して更新します。 「数ショットの例を作成する」を参照してください。 |
1005 | いくつかのショットプロンプトにおける無効なフィールド | 提供されているいくつかのショットの例の必須入力フィールドを確認して更新します。 「数ショットの例を作成する」を参照してください。 |
3001 | 依存関係のタイムアウト | ログを確認し、エージェントを再実行してみてください。タイムアウトが続く場合は、Databricksアカウントチームに問い合わせてください。 |
3003 | 依存率の上限を超過 | Databricksアカウントチームにお問い合わせください。 |
3004 | トークンレート制限を超過 | Databricksアカウントチームにお問い合わせください。 |
3006 | パートナーが提供する AI 機能は無効になります。 | パートナー主導の AI 機能を有効にします。 LLMジャッジを動かすモデルに関する情報を参照してください。 |