Feature Serving エンドポイント
Databricks Feature Serving は、Databricks プラットフォームのデータを Databricks の外部にデプロイされたモデルやアプリケーションで使用できるようにします。Feature Serving エンドポイントは、リアルタイムのトラフィックに合わせて自動的にスケーリングし、機能を提供するための高可用性と低遅延のサービスを提供します。このページでは、Feature Serving の設定方法と使用方法について説明します。ステップ バイ ステップ チュートリアルについては、「 例: Feature Serving エンドポイントのデプロイとクエリ」を参照してください。
Databricksの機能を使用して構築されたモデルをモデルサービングで提供する場合、モデルは推論要求のために機能を自動的に検索して変換します。Databricks Feature Servingを使用すると、検索拡張生成(RAG)アプリケーション向けの構造化データだけでなく、Databricks以外で提供されるモデルや、Unity Catalogのデータに基づいた機能を必要とするその他のアプリケーションなど、他のアプリケーションに必要な機能も提供できます。
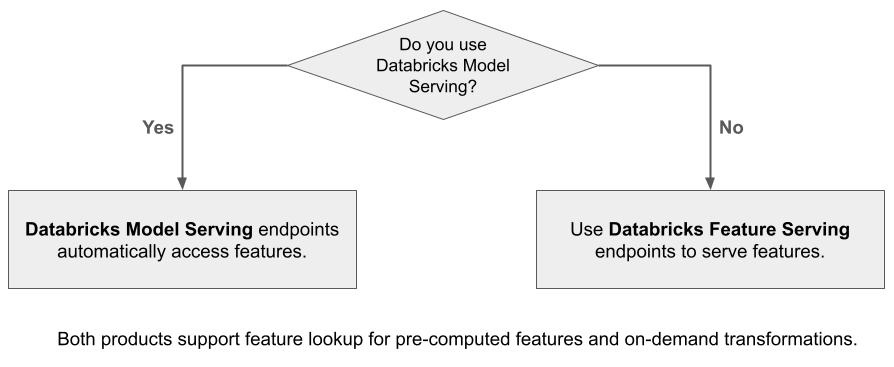
Feature Serving の利点
Databricks 特徴量サービングは、事前にマテリアライズされた機能とオンデマンドの機能を提供する単一のインターフェイスを提供します。 また、次の利点もあります。
- シンプル。 Databricks がインフラストラクチャを処理します。 Databricks は、1 回の API 呼び出しで、本番運用に対応したサービス環境を作成します。
- 高可用性とスケーラビリティ。 特徴量サービングエンドポイントは、処理要求の量に合わせて自動的にスケールアップおよびスケールダウンします。
- 安全。 エンドポイントは、セキュリティで保護されたネットワーク境界にデプロイされ、エンドポイントが削除されるか 0 にスケーリングされたときに終了する専用のコンピュートを使用します。
必要条件
- Databricks Runtime 14.2 ML以上。
- Python API を使用するには、特徴量サービングには
databricks-feature-engineeringバージョン 0.1.2 が必要です 以降。Databricks Runtime 14.2 MLに組み込まれています。 以前の Databricks Runtime MLバージョンの場合は、%pip install databricks-feature-engineering>=0.1.2を使用して必要なバージョンを手動でインストールします。 Databricks ノートブックを使用している場合は、新しいセルdbutils.library.restartPython()でこのコマンドを実行して、Python カーネルを再起動する必要があります。 - Databricks SDK を使用するには、特徴量サービングに
databricks-sdkバージョン 0.18.0 以降が必要です。 必要なバージョンを手動でインストールするには、%pip install databricks-sdk>=0.18.0を使用します。 Databricks ノートブックを使用している場合は、新しいセルdbutils.library.restartPython()でこのコマンドを実行して、Python カーネルを再起動する必要があります。
Databricks 特徴量サービングは、エンドポイントを作成、更新、クエリ、削除するための UI といくつかのプログラム オプションを提供します。 この記事では、次の各オプションについて説明します。
- Databricks UI
- REST API
- Python API
- Databricks SDK
REST API または MLflow デプロイ SDK を使用するには、Databricks API トークンが必要です。
本番運用シナリオのセキュリティのベスト プラクティスとして、 Databricks では、本番運用中の認証に マシン間 OAuth トークン を使用することをお勧めします。
テストと開発のために、 Databricks ワークスペース ユーザーではなく 、サービスプリンシパル に属する個人用アクセス トークンを使用することをお勧めします。 サービスプリンシパルのトークンを作成するには、「 サービスプリンシパルのトークンの管理」を参照してください。
Feature Servingの認証
認証については、 Databricksリソースへのアクセスを承認する」を参照してください。
を作成します。 FeatureSpec
FeatureSpecは、ユーザー定義の機能のセットです。FeatureSpecで機能を組み合わせることができます。FeatureSpecs は Unity Catalog に保存され、Unity Catalog によって管理され、カタログエクスプローラ に表示されます。
FeatureSpecで指定されたテーブルは、オンライン フィーチャ ストアまたはサードパーティのオンライン ストアに公開する必要があります。「Databricks Online Feature Stores」を参照してください。
FeatureSpecを作成するには、databricks-feature-engineeringパッケージを使用する必要があります。
まず、関数を定義します。
from unitycatalog.ai.core.databricks import DatabricksFunctionClient
client = DatabricksFunctionClient()
CATALOG = "main"
SCHEMA = "default"
def difference(num_1: float, num_2: float) -> float:
"""
A function that accepts two floating point numbers, subtracts the second one
from the first, and returns the result as a float.
Args:
num_1 (float): The first number.
num_2 (float): The second number.
Returns:
float: The resulting difference of the two input numbers.
"""
return num_1 - num_2
client.create_python_function(
func=difference,
catalog=CATALOG,
schema=SCHEMA,
replace=True
)
その後、関数を FeatureSpecで使用できます。
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates num_1 - num_2.
input_bindings={"num_1": "ytd_spend", "num_2": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
デフォルト値の指定
フィーチャのデフォルト値を指定するには、FeatureLookupの default_values パラメーターを使用します。次の例を参照してください。
feature_lookups = [
FeatureLookup(
table_name="ml.recommender_system.customer_features",
feature_names=[
"membership_tier",
"age",
"page_views_count_30days",
],
lookup_key="customer_id",
default_values={
"age": 18,
"membership_tier": "bronze"
},
),
]
rename_outputs パラメーターを使用してフィーチャ列の名前を変更する場合は、名前を変更したフィーチャ名を使用するdefault_values必要があります。
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
rename_outputs={"materialized_feature_value": "feature_value"},
default_values={
"feature_value": 0
}
)
エンドポイントを作成する
FeatureSpecはエンドポイントを定義します。詳細については、「カスタム モデル サービング エンドポイントの作成」、Python API のドキュメンテーション、またはDatabricks SDKのドキュメンテーションを参照してください。
レイテンシーの影響を受けやすいワークロードや、1 秒あたりのクエリ数が多いワークロードの場合、モデルサービングはカスタムモデルサービングエンドポイントでのルート最適化を提供します ( 「サービスエンドポイントでのルート最適化」を参照)。
- Databricks SDK - Python
- Python API
- REST API
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
エンドポイントを表示するには、Databricks UIの左側のサイドバーにある 「Serving」 をクリックします。状態が 「準備完了」 になると、エンドポイントはクエリに応答する準備が整います。モデルサービングの詳細については、 「モデルサービング」を参照してください。
拡張された データフレーム を推論テーブルに保存します
2025 年 2 月以降に作成されたエンドポイントでは、検索された機能値と関数の戻り値を含む拡張 データフレーム をログに記録するようにモデルサービングエンドポイントを設定できます。 データフレーム は、提供されたモデルの推論テーブルに保存されます。
この構成の設定手順については、「 推論テーブルへのフィーチャルックアップ データフレーム のログ記録」を参照してください。
推論テーブルに関する情報については、AI Gateway対応推論テーブルを使用して提供されたモデルを監視するを参照してください。
エンドポイントを取得する
Databricks SDK または Python API を使用して、エンドポイントのメタデータとステータスを取得できます。
- Databricks SDK - Python
- Python API
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
エンドポイントのスキーマを取得する
Databricks SDK または REST API を使用して、エンドポイントのスキーマを取得できます。エンドポイント スキーマの詳細については、「 モデルサービング エンドポイント スキーマを取得する」を参照してください。
- Databricks SDK - Python
- REST API
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
# Create endpoint
endpoint = workspace.serving_endpoints.get_open_api(name="customer-features")
ACCESS_TOKEN=<token>
ENDPOINT_NAME=<endpoint name>
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
エンドポイントのクエリ
REST API、MLflow デプロイ SDK、またはサービング UI を使用して、エンドポイントに対してクエリを実行できます。
次のコードは、MLflow Deployments SDK を使用する場合に資格情報を設定し、クライアントを作成する方法を示しています。
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
自動化されたツール、システム、スクリプト、アプリで認証する際のセキュリティのベストプラクティスとして、Databricks では OAuth トークンを使用することをお勧めします。
パーソナルアクセストークン認証 を使用する場合、 Databricks では、ワークスペース ユーザーではなく 、サービスプリンシパル に属する パーソナルアクセストークン を使用することをお勧めします。 サービスプリンシパルのトークンを作成するには、「 サービスプリンシパルのトークンの管理」を参照してください。
API を使用してエンドポイントをクエリする
このセクションには、REST API または MLflow デプロイ SDK を使用してエンドポイントをクエリする例が含まれています。
- MLflow Deployments SDK
- REST API
次の例では、MLflow Deployments SDK の predict() API を使用しています。この API は 試験段階 であり、API 定義は変更される可能性があります。
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
UIを使用してエンドポイントをクエリします
サービング UI から直接、サービングエンドポイントをクエリできます。 UI には、エンドポイントのクエリに使用できる生成されたコード例が含まれています。
-
Databricks ワークスペースの左側のサイドバーで、[ サービス提供 ] をクリックします。
-
クエリを実行するエンドポイントをクリックします。
-
画面の右上にある [ クエリ エンドポイント ] をクリックします。
-
[要求 ] ボックスに、要求本文を JSON 形式で入力します。
-
「 リクエストを送る 」をクリックします。
// Example of a request body.
{
"dataframe_records": [
{ "user_id": 1, "ytd_spend": 598 },
{ "user_id": 2, "ytd_spend": 280 }
]
}
[クエリ エンドポイント ] ダイアログには、curl、Python、および SQL で生成されたサンプル コードが含まれています。タブをクリックして、サンプルコードを表示およびコピーします。
コードをコピーするには、テキストボックスの右上にあるコピーアイコンをクリックします。
エンドポイントを更新してください
Feature Servingエンドポイントの設定( FeatureSpecやワークロードサイズの変更など)を変更する場合は、必ずこのセクションで説明する更新APIs使用してください。 変更を適用するためにエンドポイントを削除して再作成しないでください。稼働中のエンドポイントを削除すると、即座にダウンタイムが発生し、そのエンドポイントにクエリを実行するすべてのアプリケーションが中断されます。
エンドポイントは、REST API、Databricks SDK、または Serving UI を使用して更新できます。
API を使用してエンドポイントを更新する
- Databricks SDK - Python
- REST API
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
UI を使用したエンドポイントの更新
サービングUIを使用するには、次の手順に従います。
- Databricks ワークスペースの左側のサイドバーで、[ サービス提供 ] をクリックします。
- テーブルで、更新するエンドポイントの名前をクリックします。 エンドポイント画面が表示されます。
- 画面の右上にある [ エンドポイントの編集 ] をクリックします。
- 「 配信エンドポイントの編集 」ダイアログで、必要に応じてエンドポイント設定を編集します。
- [更新 ] をクリックして、変更を保存します。

エンドポイントの削除
この行為は取り返しがつかない。Feature Servingエンドポイントを削除すると、そのエンドポイントにクエリを実行するすべてのアプリケーションが即座にダウンタイムに見舞われます。 エンドポイントの設定を変更する場合は、エンドポイントを削除して再作成するのではなく、 「エンドポイントの更新」を使用してください。
エンドポイントは、REST API、Databricks SDK、Python API、または Serving UI を使用して削除できます。
API を使用してエンドポイントを削除する
- Databricks SDK - Python
- Python API
- REST API
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.delete(name="customer-features")
fe.delete_feature_serving_endpoint(name="customer-features")
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
UI を使用したエンドポイントの削除
次の手順に従って、Serving UI を使用してエンドポイントを削除します。
- Databricks ワークスペースの左側のサイドバーで、[ サービス提供 ] をクリックします。
- テーブルで、削除するエンドポイントの名前をクリックします。 エンドポイント画面が表示されます。
- 画面の右上にあるケバブメニュー
 をクリックし、[ 削除 ]を選択します。
をクリックし、[ 削除 ]を選択します。

エンドポイントの正常性を監視する
Feature Servingエンドポイントで使用できるログとメトリクスに関する情報については、「モデルの品質とエンドポイントの正常性のモニタリング」を参照してください。
アクセス制御
Feature Servingエンドポイントの権限を管理する」を参照してください。
ノートブックの例
このノートブックでは、 Databricks SDKを使用して、 Databricks Online Feature Storeを使用してFeature Servingエンドポイントを作成する方法を説明します。