プロビジョニング済みスループット 基盤モデル API
この記事では、基盤モデルAPI プロビジョニング済みスループットを使用してモデルをデプロイする方法について説明します。Databricks では、本番運用ワークロードのプロビジョニング済みスループットを推奨し、パフォーマンスが保証された基盤モデルに最適化された推論を提供します。
プロビジョニングされたスループットとは
プロビジョニング スループット モデルサービング エンドポイントを作成するときは、 Databricksで専用の推論容量を割り当てて、 スループット 提供する基盤モデルの一贯性を確保します。 基盤モデルを提供するモデルサービングエンドポイントは、 モデルユニットのチャンクでプロビジョニングを行うことができます。 割り当てたモデルユニットの数により、本番運用 GenAI アプリケーションを確実にサポートするために必要なスループットを正確に購入できます。
プロビジョニングされたスループット エンドポイントでサポートされているモデル アーキテクチャの一覧については、 「Mosaic AI Model Serving でサポートされている基盤モデル」を参照してください。
必要条件
要件を参照してください。
[推奨]Unity Catalog から基盤モデルをデプロイする
Databricks では、Unity Catalog にプレインストールされている基盤モデルを使用することをお勧めします。 これらのモデルは、スキーマai (system.ai) のカタログsystemの下にあります。
基盤モデルをデプロイするには:
- カタログエクスプローラで
system.aiに移動します。 - デプロイするモデルの名前をクリックします。
- モデル ページで、 このモデルをサービング ボタンをクリックします。
- サービングエンドポイントの作成 ページが表示されます。 UI を使用してプロビジョニングされたスループットエンドポイントを作成するを参照してください。
Unity Catalog の system.ai から Meta Llama モデルをデプロイするには、該当する Instruct バージョンを選択する必要があります。Meta Llama モデルの基本バージョンは、Unity Catalog からのデプロイではサポートされていません。サポートされている Meta Llama モデルのバリアントについては、 Databricks でホストされている基盤モデル を参照してください。
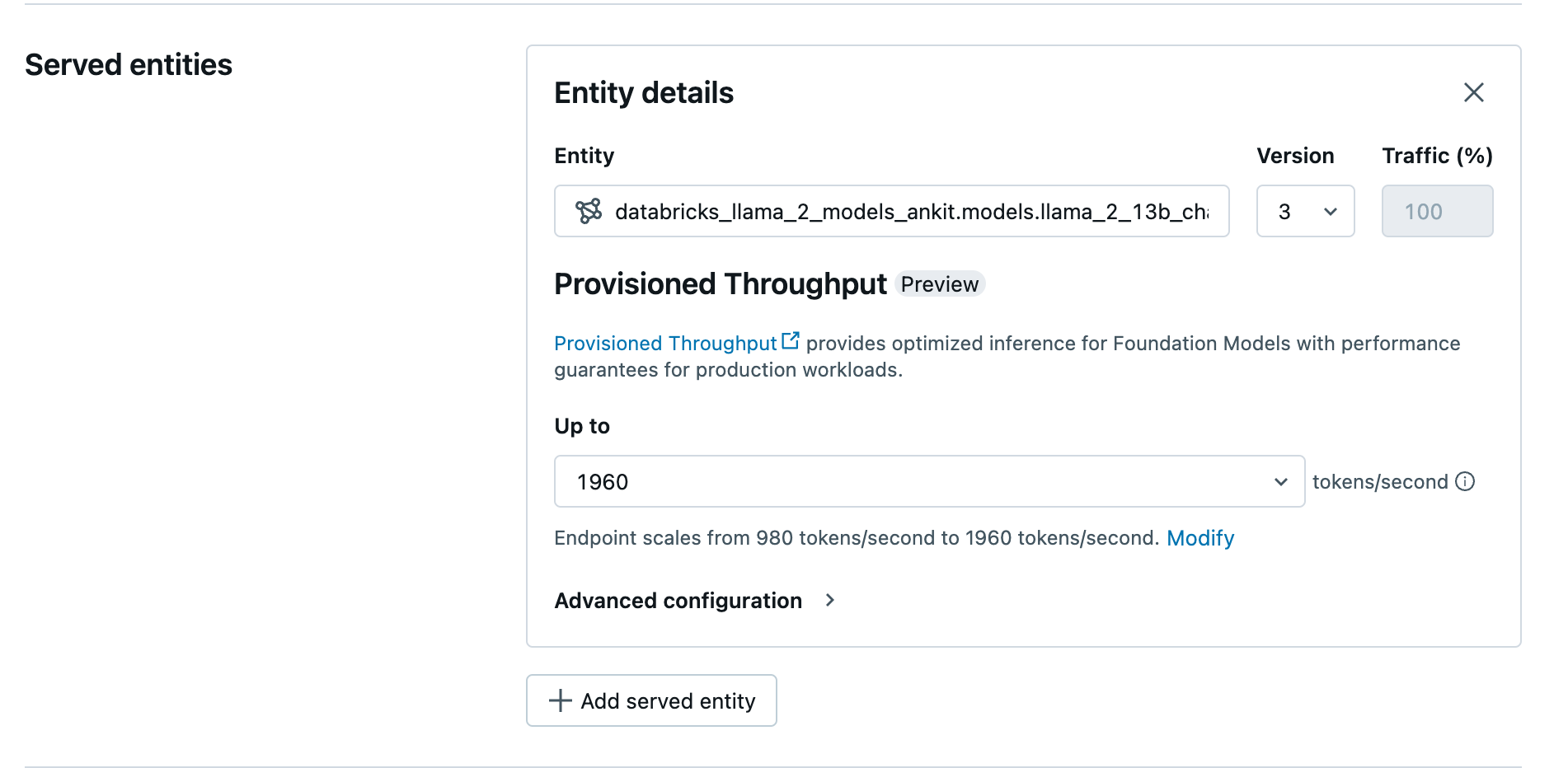
UI を使用してプロビジョニングされたスループットエンドポイントを作成する
記録済みモデルが Unity Catalogになったら、次の手順でプロビジョニング スループット サービング エンドポイントを作成します。
- ワークスペースの サービング UI に移動します。
- サービング エンドポイントの作成 を選択します。
- エンティティ フィールドで、Unity Catalog からモデルを選択します。対象モデルの場合、提供されるエンティティの UI には プロビジョニングされたスループット 画面が表示されます。
- 最大 ドロップダウンでは、エンドポイントの 1 秒あたりの最大トークンスループットを構成できます。
- プロビジョニングされたスループットエンドポイントは自動的にスケーリングされるため、 変更 を選択して、エンドポイントがスケールダウンできる 1 秒あたりの最小トークン数を表示できます。
REST API を使用してプロビジョニングされたスループットエンドポイントを作成する
REST API を使用してプロビジョニングされたスループット モードでモデルをデプロイするには、リクエストで min_provisioned_throughput フィールドと max_provisioned_throughput フィールドを指定する必要があります。 Python を使用する場合は、 MLflow デプロイ SDK を使用してエンドポイントを作成することもできます。
モデルに適したプロビジョニング済みスループットの範囲を特定するには、 プロビジョニング済みスループットを段階的に取得するを参照してください。
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
チャット完了タスクのログ確率
チャット完了タスクの場合、 logprobsを使用して、大規模言語モデル生成プロセスの一部としてサンプリングされるオフラインのログ確率を提供できます。 logprobs 、分類、モデルの不確実性の評価、評価メトリックの実行など、さまざまなシナリオに使用できます。 詳細については、 Chat Completions API参照してください。
プロビジョニングされたスループットを段階的に取得
プロビジョニングされたスループットは、1 秒あたりのトークンの増分で使用でき、特定の増分はモデルによって異なります。 ニーズに適した範囲を特定するために、Databricks では、プラットフォーム内でモデル最適化情報 API を使用することをお勧めします。
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
API からの応答の例を次に示します。
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 980
}
{
"optimizable": true,
"model_type": "gte",
"throughput_chunk_size": 980
}
制限
- GPU 容量の問題により、モデルのデプロイが失敗する場合があり、その結果、エンドポイントの作成または更新中にタイムアウトが発生します。 Databricksアカウントチームに連絡して解決してください。