MLflowモデルの記録、ロード、登録
MLflow モデルは 、Apache Spark でのバッチ推論や REST API を介したリアルタイム サービスなど、さまざまなダウンストリーム ツールで使用できる機械学習モデルをパッケージ化するための標準形式です。 この形式では、さまざまなモデル サービングおよび推論プラットフォーム で解釈可能なさまざまな フレーバー(Python関数、PyTorch 、sklearn など) でモデルを保存できる規則を定義します。
ストリーミング モデルをログに記録してスコアを付ける方法については、 「ストリーミング モデルを保存および読み込む方法」を参照してください。
MLflow 3 では、メトリクスやパラメーターなどの独自のメタデータを持つ新しい専用の LoggedModel オブジェクトを導入することで、MLflow モデルに大幅な機能強化が導入されています。詳細については、「MLflow 記録済みモデルを使用したモデルの追跡と比較」を参照してください。
モデルの記録とロード
モデルをログに記録すると、MLflow によって requirements.txt ファイルと conda.yaml ファイルが自動的に記録されます。 これらのファイルを使用して、モデル開発環境を再作成し、 virtualenv (推奨) または condaを使用して依存関係を再インストールできます。
株式会社Anacondaは、anaconda.org チャンネル の利用規約 を更新しました。 新しいサービス条件に基づき、Anacondaのパッケージングと配布に依存する場合は、商用ライセンスが必要になる場合があります。 詳細については、 Anaconda Commercial Edition の FAQ を参照してください。 Anacondaチャンネルの使用は、その利用規約に準拠します。
MLflowv1.18 より前 (Databricks Runtime 8.3ML 以前) で記録された モデルは、デフォルトでは依存関係として condadefaults チャンネル (https://repo.anaconda.com/pkgs/) を用いて記録されていましたこのライセンス変更に伴い、 Databricks は MLflow v1.18 以降を使用してログインしたモデルでの defaults チャンネルの使用を停止しました。 記録されたデフォルト チャンネルは、コミュニティが管理する https://conda-forge.org/ を指す conda-forgeになりました。
MLflow v1.18より前のモデルをログに記録し、そのモデルのconda環境からdefaultsチャンネルを除外しなかった場合、そのモデルは意図していないdefaultsチャンネルに依存している可能性があります。モデルにこの依存関係があるかどうかを手動で確認するには、記録済みモデルにパッケージ化されているconda.yaml ファイル内のchannel値を調べます。たとえば、defaults チャンネルの依存関係を持つモデルのconda.yamlは、次のようになります。
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Databricksは、Anacondaとの関係の下で、モデルと対話するためのAnacondaリポジトリの使用が許可されているかどうかを判断できないため、Databricksは顧客に変更を加えることを強制していません。Databricks の使用による Anaconda.com リポジトリの使用が Anaconda の条件で許可されている場合は、何もする必要はありません。
モデルの環境で使用するチャンネルを変更したい場合は、新しい conda.yamlでモデルをモデルレジストリに再登録することができます。 これを行うには、log_model()の conda_env パラメーターでチャンネルを指定します。
log_model() APIの詳細については、使用しているモデル フレーバーのMLflowドキュメンテーション(log_model for a scikit-learnなど)を参照してください。
conda.yamlファイルの詳細については、 MLflow のドキュメントを参照してください。
API コマンド
MLflow 追跡サーバーにモデルを記録するには、 mlflow.<model-type>.log_model(model, ...)を使用します。
推論またはさらなる開発のために以前に記録済みモデルを読み込むには、 mlflow.<model-type>.load_model(modelpath)を使用します。ここで、 modelpath は次のいずれかです。
- モデル パス (
models:/{model_id}など) (MLflow 3 のみ) - ラン相対パス (
runs:/{run_id}/{model-path}など) - Unity Catalog ボリューム パス (
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}など) - MLflow で管理されるアーティファクト ストレージ パス
dbfs:/databricks/mlflow-tracking/ - 登録されているモデルパス(
models:/{model_name}/{model_stage}など)。
Python MLflow モデルの場合、追加のオプションは、 mlflow.pyfunc.load_model() を使用してモデルを汎用 Python 関数として読み込むことです。
次のコード スニペットを使用して、モデルを読み込み、データポイントをスコア付けできます。
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
別の方法として、バッチジョブあるいはリアルタイムのSpark ストリーミング ジョブとして、Sparkクラスター上でのスコアリングにモデルを使用するために、モデルをApache Spark UDFとしてエクスポートすることができます。
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
記録済みモデルの依存関係
モデルを正確に読み込むには、モデルの依存関係が正しいバージョンでノートブック環境に読み込まれていることを確認する必要があります。Databricks Runtime 10.5 ML 以降では、現在の環境とモデルの依存関係との間に不一致が検出された場合、MLflow によって警告が表示されます。
モデルの依存関係の復元を簡略化する追加機能は、 Databricks Runtime 11.0 ML以降に含まれています。 Databricks Runtime 11.0 ML以降では、 pyfunc フレーバーモデルの場合、 mlflow.pyfunc.get_model_dependencies を呼び出してモデルの依存関係を取得およびダウンロードできます。この関数は、 %pip install <file-path>を使用してインストールできる依存関係ファイルへのパスを返します。 モデルを PySpark UDF として読み込む場合は、 mlflow.pyfunc.spark_udf 呼び出しで env_manager="virtualenv" を指定します。これにより、PySpark UDF のコンテキストでモデルの依存関係が復元され、外部環境には影響しません。
この機能は、 MLflow バージョン 1.25.0 以降を手動でインストールすることで、Databricks Runtime 10.5 以下でも使用できます。
%pip install "mlflow>=1.25.0"
記録済みモデルの依存関係 (Python と非Python) とアーティファクトの方法に関する追加情報については、「 記録済みモデルの依存関係」を参照してください。
モデルサービングの文書化済みモデルの依存関係とカスタムアーティファクトの方法を学びます。
MLflow UI で自動的に生成されたコードスニペット
Databricks ノートブックにモデルを記録すると、Databricksはモデルをロード、実行するためにコピーして使用できるコード スニペットを自動的に生成します。 これらのコード スニペットを表示するには:
- モデルを生成した実行の実行画面に移動します。 (実行画面の表示方法については、 ノートブック エクスペリメントの参照 を参照してください。
- アーティファクト セクションまでスクロールします。
- 記録済みモデルの名前をクリックします。 右側にパネルが開き、記録済みモデルを読み込み、 Spark または Pandas データフレームで予測を行うために使用できるコードが表示されます。
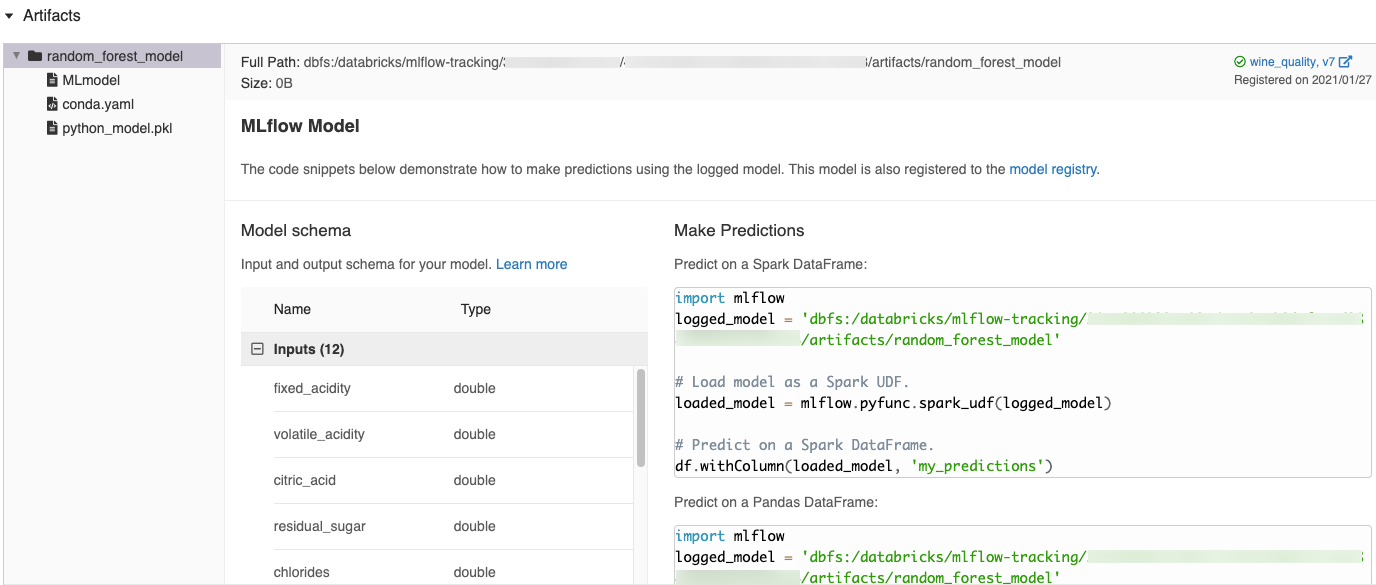
例
モデルの記録の例については、「 機械学習のトレーニングランの追跡の例」を参照してください。
Model Registryで登録するモデル
Mlflowモデルの完全なライフサイクルを管理するには、UIと一連のAPIを提供する集中管理されたモデルストアであるMLflowモデルレジストリにモデルを登録することができます。モデルレジストリを使用してDatabricks Unity Catalogでモデルを管理する方法については、「Unity Catalogでのモデルのライフサイクルの管理」を参照してください。Workspace Model Registryを使用するには、「Workspace Model Registry (レガシ) を使用したモデルのライフサイクルの管理」を参照してください。
MLflow 3 で作成されたモデルを Unity Catalog モデルレジストリに登録すると、すべてのエクスペリメントとワークスペース全体で、パラメーターやメトリクスなどのデータを 1 か所で一元的に表示できます。情報については、「Model Registry MLflow3 での の改善 」を参照してください。
API を使用してモデルを登録するには、次のコマンドを使用します。
- MLflow 3
- MLflow 2.x
mlflow.register_model("models:/{model_id}", "{registered_model_name}")
mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}")
モデルを Unity Catalog ボリュームに保存する
モデルをローカルに保存するには、 mlflow.<model-type>.save_model(model, modelpath)を使用します。 modelpath は Unity Catalog ボリューム パスである必要があります。 たとえば、Unity Catalog ボリュームの場所 /Volumes/catalog_name/schema_name/volume_name/my_project_models を使用してプロジェクトの作業を保存する場合は、次のモデル パスを使用する必要があります /Volumes/catalog_name/schema_name/volume_name/my_project_models。
modelpath = "/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
MLlib モデルの場合は、 機械学習パイプラインを使用します。
モデルアーティファクトのダウンロード
さまざまな APIで登録されたモデルの記録済みモデルのアーティファクト(モデルファイル、プロット、メトリクスなど)をダウンロードできます。
Python API の例:
mlflow.set_registry_uri("databricks-uc")
mlflow.artifacts.download_artifacts(f"models:/{model_name}/{model_version}")
Java API の例:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
CLI コマンド の例:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
オンライン サービスのモデルをデプロイする
モデルをデプロイする前に、モデルがサービスを提供できることを確認すると便利です。 デプロイ前に mlflow.models.predict を使用してモデルを検証する方法については、MLflow のドキュメントを参照してください。
Unity Catalogに登録されている機械学習モデルをRESTエンドポイントとしてホストするには、モデルサービングを使用します。 これらのエンドポイントは、モデルバージョンの入手可能性に基づいて自動的に更新されます。