本番運用で GenAI を監視する
ベータ版
この機能はベータ版です。ワークスペース管理者は、 プレビュー ページからこの機能へのアクセスを制御できます。「Databricks プレビューの管理」を参照してください。
Databricksの 生成AI の本番運用モニタリングを使用すると、本番運用 生成AI アプリからのトレースに対してMLflow 3 スコアラーを自動的に実行して、品質を継続的に監視できます。
本番運用トラフィックのサンプルを自動的に評価するスコアラーをスケジュールできます。 スコアラーの評価結果は、評価されたトレースにフィードバックとして自動的に添付されます。
本番運用モニタリングには次の内容が含まれます。
- 組み込みまたはカスタムのスコアラーを使用した自動品質評価。
- サンプリング レートを設定できるため、カバレッジと計算コストのトレードオフを制御できます。
- 一貫した評価を確保するために、開発と本番運用で同じスコアラーを使用します。
- バックグラウンドで実行されるモニタリングによる継続的な品質評価。
MLflow 3 本番運用 モニタリングは、 MLflow 2 からログに記録されたトレースと互換性があります。
レガシー本番運用モニタリングの詳細については、 本番運用モニタリングAPIリファレンス (レガシー)を参照してください。
前提 条件
品質モニタリングを設定する前に、次のことを確認してください。
-
MLflowエクスペリメント : トレースが記録されるMLflowエクスペリメント。 エクスペリメントが指定されていない場合は、アクティブなエクスペリメントが使用されます。
-
計測可能になっている本番運用アプリケーション : 生成 AI アプリは、 MLflow Tracingを使用してトレースをログに記録する必要があります。 本番運用のトレーシングガイドを参照してください。
-
定義済みのスコアラー : アプリケーションのトレースの形式で動作するテスト済みのスコアラー。開発中に本番運用アプリを
mlflow.genai.evaluate()のpredict_fnとして使用した場合、スコアラーは既に互換性がある可能性があります。 -
SQLウェアハウス ID ( Unity Catalogトレース用) : トレースがUnity Catalogに保存されている場合、モニタリングが機能するようにSQLウェアハウス ID を構成する必要があります。 「本番運用モニタリングの有効化」を参照してください。
本番運用 モニタリングを始める
このセクションには、さまざまな種類のスコアラーを作成する方法を示すコード例が含まれています。
スコアラーの詳細については、以下を参照してください。
いつでも、最大20個のスコアラーをエクスペリメントに関連付けて、継続的な品質モニタリングを行うことができます。
UI を使用して LLM 審査員を作成し、スケジュールを設定します
MLflow UI を使用して、LLM 審査員に基づいてスコアラーを作成し、テストすることができます。
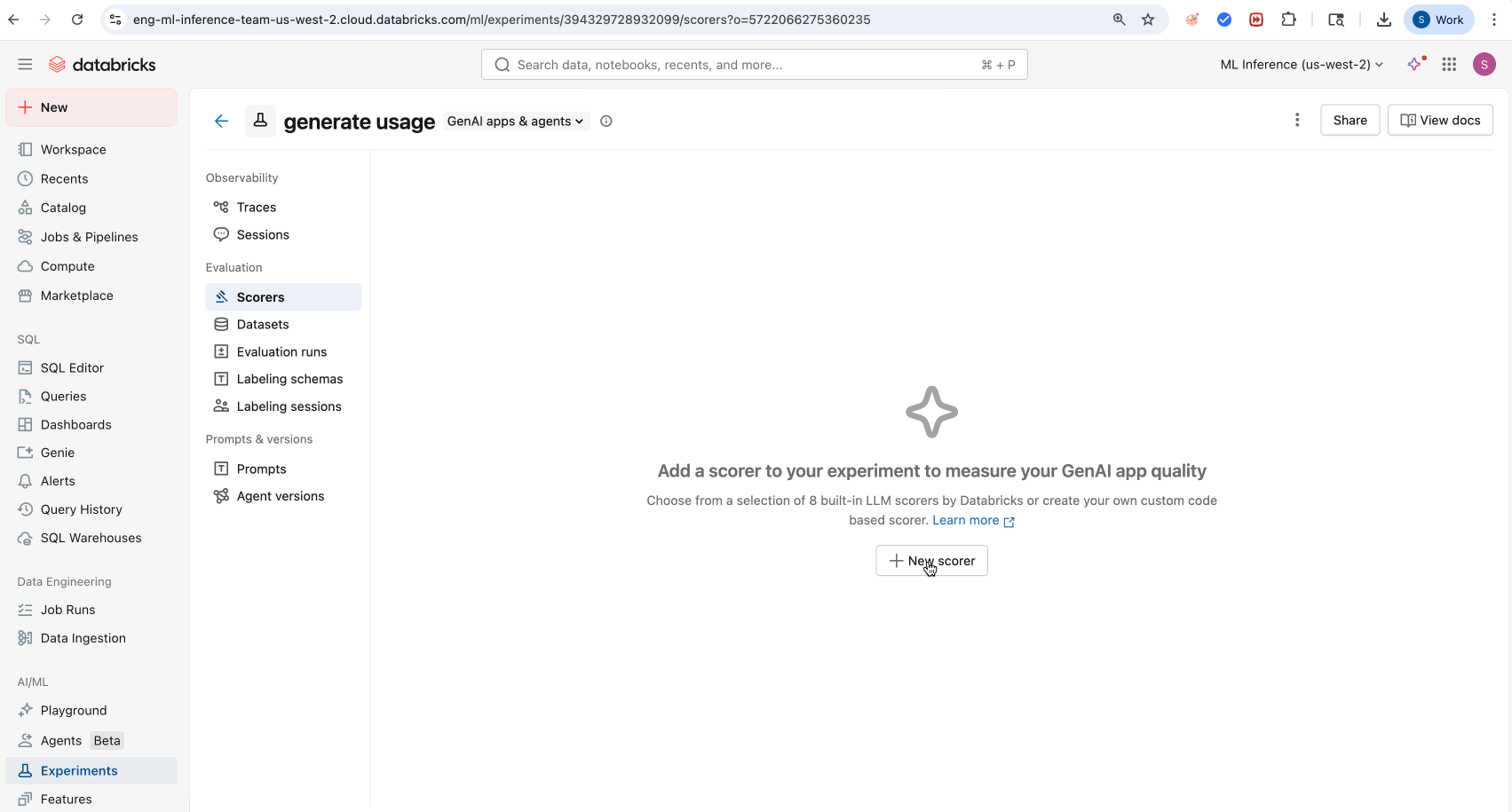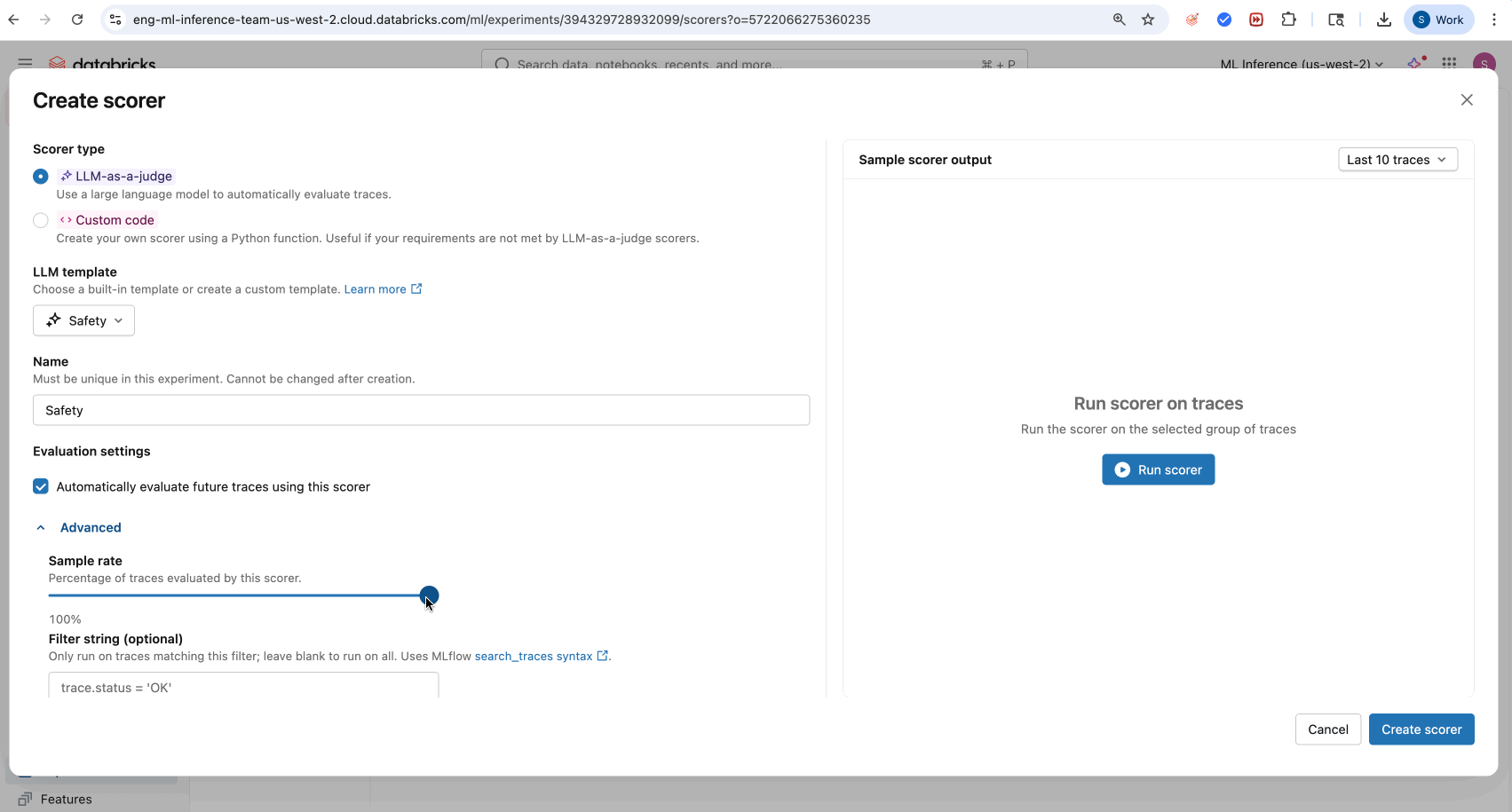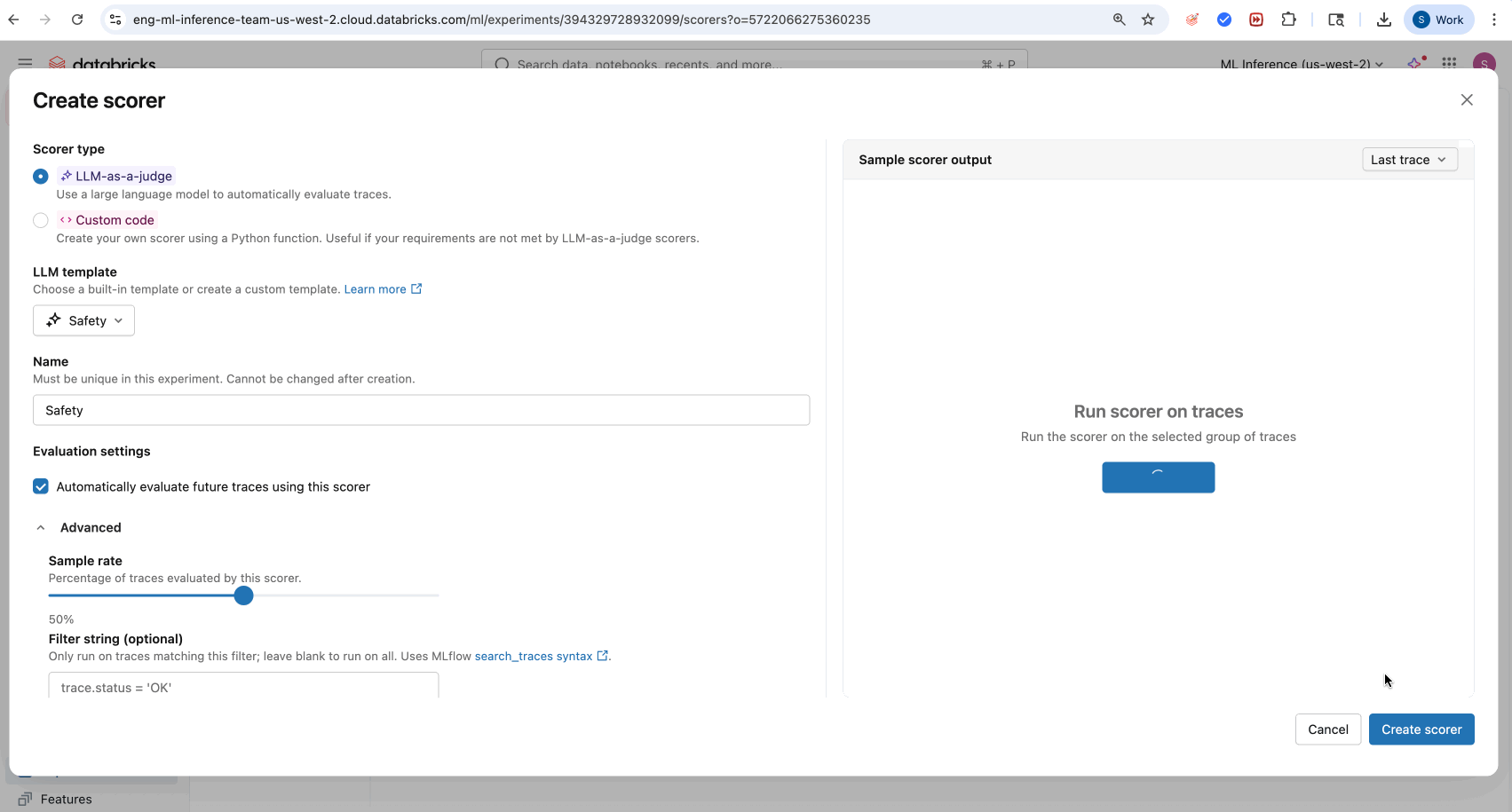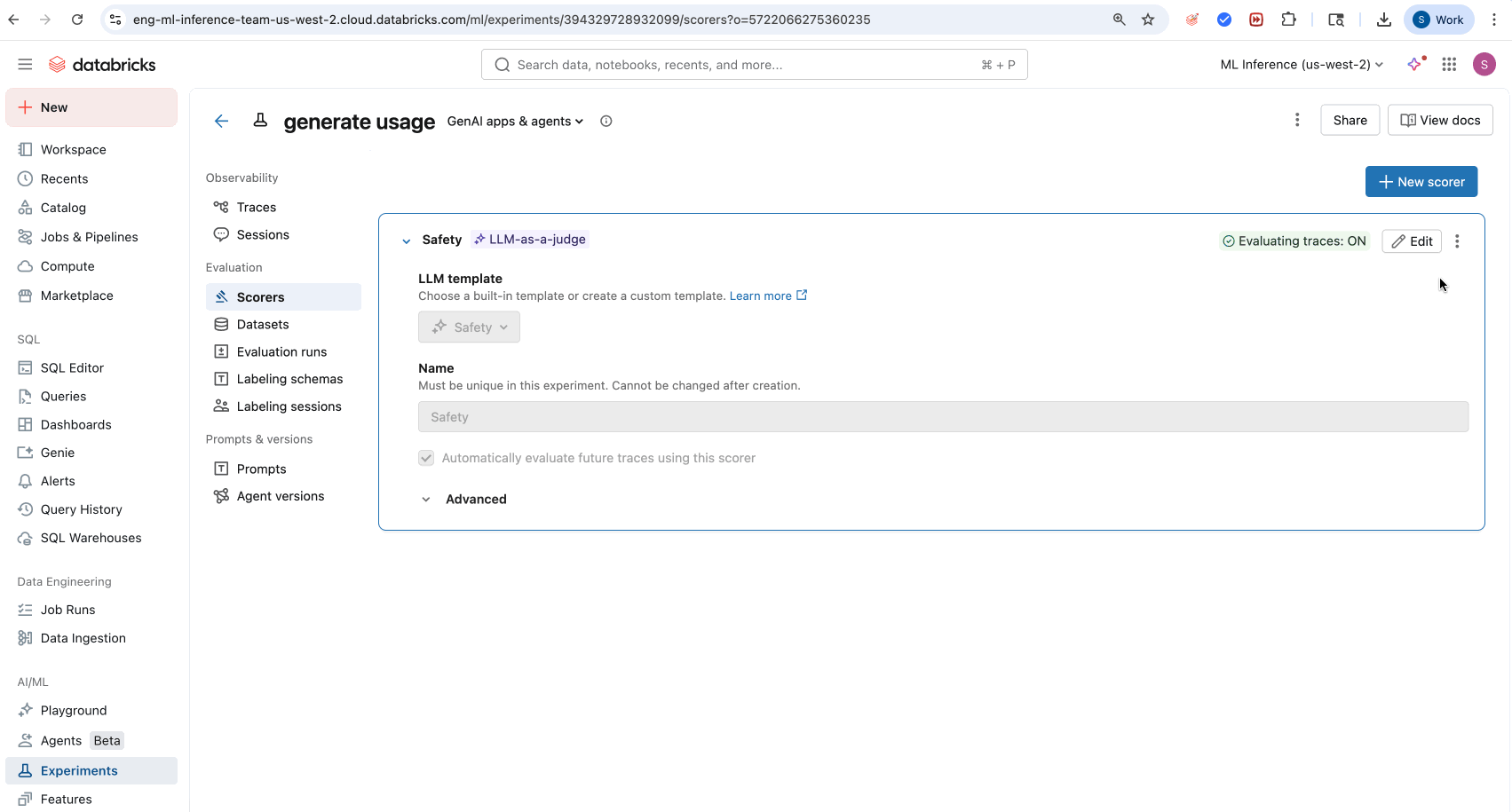
- MLflowエクスペリメント UI の [スコアラー] タブに移動します。
- [新しいスコアラー] をクリックします。
- LLM テンプレート ドロップダウン メニューから組み込みの LLM 審査員を選択します。
- (オプション) [実行スコアラー] をクリックして、トレースのサブセットを実行します。
- (オプション) 今後のトレースに関する本番運用モニタリングの 評価設定を 調整します。
- [スコアラーを作成] をクリックします。
組み込みのLLMジャッジを使用する
MLflowには、モニタリングにすぐに使用できる組み込みLLMジャッジがいくつか用意されています。
from mlflow.genai.scorers import Safety, ScorerSamplingConfig
# Register the scorer with a name and start monitoring
safety_judge = Safety().register(name="my_safety_judge") # name must be unique to experiment
safety_judge = safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.7))
デフォルトでは、各ジャッジは GenAI 品質評価を実行するために設計された Databricks ホスト LLM を使用します。スコアラー定義でmodel引数を使用すると、代わりにDatabricksモデルサービング エンドポイントを使用するように判定モデルを変更できます。 モデルはdatabricks:/<databricks-serving-endpoint-name>形式で指定する必要があります。
safety_judge = Safety(model="databricks:/databricks-gpt-oss-20b").register(name="my_custom_safety_judge")
使用ガイドライン LLMジャッジ
ガイドライン LLM 審査員は、合格/不合格の自然言語基準を使用して入力と出力を評価します。
from mlflow.genai.scorers import Guidelines
# Create and register the guidelines scorer
english_judge = Guidelines(
name="english",
guidelines=["The response must be in English"]
).register(name="is_english") # name must be unique to experiment
# Start monitoring with the specified sample rate
english_judge = english_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.7))
組み込みジャッジと同様に、代わりにDatabricksモデルサービング エンドポイントを使用するようにジャッジ モデルを変更できます。
english_judge = Guidelines(
name="english",
guidelines=["The response must be in English"],
model="databricks:/databricks-gpt-oss-20b",
).register(name="custom_is_english")
カスタムプロンプトでLLMジャッジを使用する
ガイドライン審査員よりも柔軟性を高めるには、カスタマイズ可能な選択カテゴリと数値スコアによる複数レベルの品質評価を可能にするカスタム プロンプトを備えた LLM 審査員を使用します。
from mlflow.genai.scorers import scorer, ScorerSamplingConfig
@scorer
def formality(inputs, outputs, trace):
# Must be imported inline within the scorer function body
from mlflow.genai.judges import custom_prompt_judge
from mlflow.entities.assessment import DEFAULT_FEEDBACK_NAME
formality_prompt = """
You will look at the response and determine the formality of the response.
<request>{{request}}</request>
<response>{{response}}</response>
You must choose one of the following categories.
[[formal]]: The response is very formal.
[[semi_formal]]: The response is somewhat formal. The response is somewhat formal if the response mentions friendship, etc.
[[not_formal]]: The response is not formal.
"""
my_prompt_judge = custom_prompt_judge(
name="formality",
prompt_template=formality_prompt,
numeric_values={
"formal": 1,
"semi_formal": 0.5,
"not_formal": 0,
},
model="databricks:/databricks-gpt-oss-20b", # optional
)
result = my_prompt_judge(request=inputs, response=inputs)
if hasattr(result, "name"):
result.name = DEFAULT_FEEDBACK_NAME
return result
# Register the custom judge and start monitoring
formality_judge = formality.register(name="my_formality_judge") # name must be unique to experiment
formality_judge = formality_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.1))
カスタムスコアラー関数を使用する
柔軟性を最大限に高めるには、カスタム スコアラー関数を定義して使用します。
カスタム スコアラーを定義するときは、関数シグネチャにインポートする必要がある型ヒントを使用しないでください。スコアラー関数本体でインポートが必要なパッケージを使用する場合は、適切なシリアル化を確保するために、これらのパッケージを関数内にインラインでインポートします。
一部のパッケージは、インラインインポートを必要とせずにデフォルトで使用できます。これには、 databricks-agents、 mlflow-skinny、 openai、 およびサーバレス環境バージョン 2 に含まれるすべてのパッケージが含まれます。
from mlflow.genai.scorers import scorer, ScorerSamplingConfig
# Custom metric: Check if response mentions Databricks
@scorer
def mentions_databricks(outputs):
"""Check if the response mentions Databricks"""
return "databricks" in str(outputs.get("response", "")).lower()
# Custom metric: Response length check
@scorer(aggregations=["mean", "min", "max"])
def response_length(outputs):
"""Measure response length in characters"""
return len(str(outputs.get("response", "")))
# Custom metric with multiple inputs
@scorer
def response_relevance_score(inputs, outputs):
"""Score relevance based on keyword matching"""
query = str(inputs.get("query", "")).lower()
response = str(outputs.get("response", "")).lower()
# Simple keyword matching (replace with your logic)
query_words = set(query.split())
response_words = set(response.split())
if not query_words:
return 0.0
overlap = len(query_words & response_words)
return overlap / len(query_words)
# Register and start monitoring custom scorers
databricks_scorer = mentions_databricks.register(name="databricks_mentions")
databricks_scorer = databricks_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
length_scorer = response_length.register(name="response_length")
length_scorer = length_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=1.0))
relevance_scorer = response_relevance_score.register(name="response_relevance_score") # name must be unique to experiment
relevance_scorer = relevance_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=1.0))
複数のスコアラー構成
包括的なモニタリング設定を行うには、複数のスコアラーを個別に登録して起動します。
from mlflow.genai.scorers import Safety, Guidelines, ScorerSamplingConfig, list_scorers
# # Register multiple scorers for comprehensive monitoring
safety_judge = Safety().register(name="safety") # name must be unique within an MLflow experiment
safety_judge = safety_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0), # Check all traces
)
guidelines_judge = Guidelines(
name="english",
guidelines=["Response must be in English"]
).register(name="english_check")
guidelines_judge = guidelines_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=0.5), # Sample 50%
)
# List and manage all scorers
all_scorers = list_scorers()
for scorer in all_scorers:
if scorer.sample_rate > 0:
print(f"{scorer.name} is active")
else:
print(f"{scorer.name} is stopped")
スコアラーのライフサイクル
スコアラーのライフサイクルはMLflowエクスペリメントを中心としています。 次の表は、スコアラーのライフサイクル状態を示しています。
スコアラーは 不変で あるため、ライフサイクル操作によって元のスコアラーが変更されることはありません。代わりに、新しいスコアラー インスタンスを返します。
状態 | 説明 | API |
|---|---|---|
未登録 | スコアラー関数は定義されていますが、サーバーに認識されていません。 | |
登録済み | スコアラーはアクティブなMLflowエクスペリメントに登録されます。 | |
アクティブ | スコアラーはサンプル レート > 0 で実行されています。 | |
停止 | スコアラーは登録されていますが、実行されていません (サンプル レート = 0)。 | |
削除済み | スコアラーはサーバーから削除され、 MLflowエクスペリメントとの関連がなくなりました。 |
基本的なスコアラーライフサイクル
from mlflow.genai.scorers import Safety, scorer, ScorerSamplingConfig
# Built-in scorer lifecycle
safety_judge = Safety().register(name="safety_check")
safety_judge = safety_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0),
)
safety_judge = safety_judge.update(
sampling_config=ScorerSamplingConfig(sample_rate=0.8),
)
safety_judge = safety_judge.stop()
delete_scorer(name="safety_check")
# Custom scorer lifecycle
@scorer
def response_length(outputs):
return len(str(outputs.get("response", "")))
length_scorer = response_length.register(name="length_check")
length_scorer = length_scorer.start(
sampling_config=ScorerSamplingConfig(sample_rate=0.5),
)
得点者を管理する
スコアラーの管理には次のAPIsが利用できます。
API | 説明 | 例 |
|---|---|---|
現在のエクスペリメントに登録されているすべてのスコアラーをリストします。 | ||
登録されたスコアラーを名前で検索します。 | ||
アクティブ スコアラーのサンプリング構成を変更します。これは不変の操作です。 | ||
新しいメトリクスまたは更新されたメトリクスを履歴トレースに遡って適用します。 | ||
登録されたスコアラーを名前で削除します。 |
現在の得点者一覧
エクスペリメントに登録されているすべてのスコアラーを表示するには:
from mlflow.genai.scorers import list_scorers
# List all registered scorers
scorers = list_scorers()
for scorer in scorers:
print(f"Name: {scorer._server_name}")
print(f"Sample rate: {scorer.sample_rate}")
print(f"Filter: {scorer.filter_string}")
print("---")
スコアラーを取得して更新する
既存のスコアラー構成を変更するには:
from mlflow.genai.scorers import get_scorer
# Get existing scorer and update its configuration (immutable operation)
safety_judge = get_scorer(name="safety_monitor")
updated_judge = safety_judge.update(sampling_config=ScorerSamplingConfig(sample_rate=0.8)) # Increased from 0.5
# Note: The original scorer remains unchanged; update() returns a new scorer instance
print(f"Original sample rate: {safety_judge.sample_rate}") # Original rate
print(f"Updated sample rate: {updated_judge.sample_rate}") # New rate
得点者を停止して削除する
監視を停止するか、スコアラーを完全に削除するには:
from mlflow.genai.scorers import get_scorer, delete_scorer
# Get existing scorer
databricks_scorer = get_scorer(name="databricks_mentions")
# Stop monitoring (sets sample_rate to 0, keeps scorer registered)
stopped_scorer = databricks_scorer.stop()
print(f"Sample rate after stop: {stopped_scorer.sample_rate}") # 0
# Remove scorer entirely from the server
delete_scorer(name=databricks_scorer.name)
# Or restart monitoring from a stopped scorer
restarted_scorer = stopped_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
不変の更新
LLM 審査員を含む採点者は不変のオブジェクトです。スコアラーを更新しても、元のスコアラーは変更されません。代わりに、スコアラーの更新されたコピーが作成されます。この不変性は、本番運用用のスコアラーが誤って変更されないようにするのに役立ちます。 次のコード スニペットは、不変の更新がどのように機能するかを示しています。
# Demonstrate immutability
original_judge = Safety().register(name="safety")
original_judge = original_judge.start(
sampling_config=ScorerSamplingConfig(sample_rate=0.3),
)
# Update returns new instance
updated_judge = original_judge.update(
sampling_config=ScorerSamplingConfig(sample_rate=0.8),
)
# Original remains unchanged
print(f"Original: {original_judge.sample_rate}") # 0.3
print(f"Updated: {updated_judge.sample_rate}") # 0.8
履歴トレースの評価 (メトリクス バックフィル)
新しいメトリクスまたは更新されたメトリクスを履歴トレースに遡及的に適用できます。
現在のサンプルレートを使用した基本的なメトリクスのバックフィル
from databricks.agents.scorers import backfill_scorers
safety_judge = Safety()
safety_judge.register(name="safety_check")
safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
#custom scorer
@scorer(aggregations=["mean", "min", "max"])
def response_length(outputs):
"""Measure response length in characters"""
return len(outputs)
response_length.register(name="response_length")
response_length.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
# Use existing sample rates for specified scorers
job_id = backfill_scorers(
scorers=["safety_check", "response_length"]
)
カスタムサンプルレートと時間範囲を使用したメトリクスバックフィル
from databricks.agents.scorers import backfill_scorers, BackfillScorerConfig
from datetime import datetime
from mlflow.genai.scorers import Safety, Correctness
safety_judge = Safety()
safety_judge.register(name="safety_check")
safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
#custom scorer
@scorer(aggregations=["mean", "min", "max"])
def response_length(outputs):
"""Measure response length in characters"""
return len(outputs)
response_length.register(name="response_length")
response_length.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
# Define custom sample rates for backfill
custom_scorers = [
BackfillScorerConfig(scorer=safety_judge, sample_rate=0.8),
BackfillScorerConfig(scorer=response_length, sample_rate=0.9)
]
job_id = backfill_scorers(
experiment_id=YOUR_EXPERIMENT_ID,
scorers=custom_scorers,
start_time=datetime(2024, 6, 1),
end_time=datetime(2024, 6, 30)
)
最近のデータのバックフィル
from datetime import datetime, timedelta
# Backfill last week's data with higher sample rates
one_week_ago = datetime.now() - timedelta(days=7)
job_id = backfill_scorers(
scorers=[
BackfillScorerConfig(scorer=safety_judge, sample_rate=0.8),
BackfillScorerConfig(scorer=response_length, sample_rate=0.9)
],
start_time=one_week_ago
)
結果を見る
スコアラーをスケジュールした後、初期処理に15〜20分かかります。そうしたら:
- MLflowエクスペリメントに移動します。
- トレース タブを開いて、トレースに添付された評価を確認します。
- モニタリングダッシュボードを使用して、品質の傾向を追跡します。
おすすめの方法
スコアラーの状態管理
sample_rateを使用して操作する前にスコアラーの状態を確認します。- 不変パターンを使用します。
.start()、.update()、.stop()の結果を変数に割り当てます。 - スコアラーのライフサイクルを理解します。
.stop()登録を保持し、delete_scorer()スコアラーを完全に削除します。
メトリクス バックフィル
- 小さく始めましょう。ジョブの期間とリソースの使用量を見積もるには、まず短い時間範囲から始めます。
- 適切なサンプル レートを使用します。高いサンプル レートを使用する場合のコストと時間の影響を考慮してください。
サンプリング戦略
-
安全性やセキュリティのチェックなどの重要なスコアラーには、
sample_rate=1.0使用します。 -
複雑な LLM ジャッジなどの高価なスコアラーの場合は、より低いサンプル レート (0.05 ~ 0.2) を使用します。
-
開発中の反復的な改善には、中程度のレート (0.3 ~ 0.5) を使用します。
-
次の例に示すように、カバレッジとコストのバランスをとってください。
Python# High-priority scorers: higher sampling
safety_judge = Safety().register(name="safety")
safety_judge = safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=1.0)) # 100% coverage for critical safety
# Expensive scorers: lower sampling
complex_scorer = ComplexCustomScorer().register(name="complex_analysis")
complex_scorer = complex_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=0.05)) # 5% for expensive operations
カスタムスコアラーのデザイン
次の例に示すように、カスタムスコアラーを自己完結型のままにします。
@scorer
def well_designed_scorer(inputs, outputs):
# All imports inside the function
import re
import json
# Handle missing data gracefully
response = outputs.get("response", "")
if not response:
return 0.0
# Return consistent types
return float(len(response) > 100)
トラブルシューティング
スコアラーが実行されない
スコアラーが実行されていない場合は、次の点を確認してください。
- エクスペリメントのチェック : トレースが個々の実行ではなくエクスペリメントに記録されていることを確認します。
- サンプリング レート : サンプリング レートが低い場合、結果が表示されるまでに時間がかかることがあります。
- フィルター文字列を確認してください :
filter_stringが実際のトレースと一致していることを確認してください。
シリアル化の問題
カスタムスコアラーを作成するときは、関数定義にインポートを含めます。
# ❌ Avoid external dependencies
import external_library # Outside function
@scorer
def bad_scorer(outputs):
return external_library.process(outputs)
# ✅ Include imports in the function definition
@scorer
def good_scorer(outputs):
import json # Inside function
return len(json.dumps(outputs))
# ❌ Avoid using type hints in scorer function signature that requires imports
from typing import List
@scorer
def scorer_with_bad_types(outputs: List[str]):
return False
メトリクスのバックフィルの問題
「エクスペリメントに予定されたスコアラー 'X' が見つかりません」
- スコアラーの名前がエクスペリメントに登録されているスコアラーと一致していることを確認してください。
list_scorersメソッドを使用して利用可能なスコアラーを確認します。
トレースのアーカイブ
トレースとそれに関連する評価を Unity CatalogのDelta テーブルに保存して、長期保存と高度な分析を行うことができます。 これは、カスタムダッシュボードの構築やトレースデータに対する詳細な実行、アプリケーションの動作の永続的な記録の維持の役に立ちます。
指定した Unity CatalogのDelta テーブルに書き込むために必要なアクセス許可が必要です。ターゲットテーブルがまだ存在しない場合は、作成されます。
テーブルが既に存在する場合は、トレースが追加されます。
アーカイブトレースの有効化
- MLflow API
- Databricks UI
エクスペリメントのトレースのアーカイブを開始するには、 enable_databricks_trace_archival 関数を使用します。 ターゲット Delta テーブルのフルネーム (カタログやスキーマなど) を指定する必要があります。experiment_idを指定しない場合、現在アクティブなエクスペリメントに対してトレースのアーカイブが有効になります。
from mlflow.tracing.archival import enable_databricks_trace_archival
# Archive traces from a specific experiment to a Unity Catalog Delta table
enable_databricks_trace_archival(
delta_table_fullname="my_catalog.my_schema.archived_traces",
experiment_id="YOUR_EXPERIMENT_ID",
)
disable_databricks_trace_archival関数を使用すると、いつでもエクスペリメントのトレースのアーカイブを停止できます。
from mlflow.tracing.archival import disable_databricks_trace_archival
# Stop archiving traces for the specified experiment
disable_databricks_trace_archival(experiment_id="YOUR_EXPERIMENT_ID")
UI でエクスペリメントのトレースをアーカイブするには:
- Databrick ワークスペースの体験ページに移動します。
- 「Delta sync: Not enabled」 をクリックします。
- カタログとスキーマを含む、ターゲット Delta テーブルの完全な名前を指定します。
トレースアーカイブを無効にするには:
- Databrick ワークスペースの体験ページに移動します。
- Delta同期: 有効 > 同期を無効にするを クリックします。
次のステップ
- カスタムスコアラーの作成 - ニーズに合わせたスコアラーを構築します。
- 評価データセットの構築 - モニタリング結果を使用して品質を向上させます。
リファレンスガイド
- スコアラーのライフサイクル管理APIリファレンス- モニタリング用のスコアラーを管理するためのAPIと例。
- スコアラー - モニタリングを強化するメトリクスを理解します。
- 評価ハーネス - オフライン評価と本番運用の関連。