Use Agent Bricks: extração de informações
Beta
Este recurso está em versão Beta. Os administradores do espaço de trabalho podem controlar o acesso a este recurso na página de Pré-visualizações . Veja as prévias do Gerenciador Databricks.
Esta página descreve como criar um agente AI generativo para extração de informações usando Agent Bricks: extração de informações.
O Agent Bricks oferece uma abordagem simples para construir sistemas de agentes AI de alta qualidade e específicos para cada domínio, para casos de uso comuns AI .
O que é o Agent Bricks: information Extraction?
O Agent Bricks oferece suporte à extração de informações e simplifica o processo de transformação de um grande volume de documentos de texto não rotulados em uma tabela estruturada com informações extraídas para cada documento.
Exemplos de extração de informações incluem:
- Extração de preços e informações de arrendamento de contratos.
- Organizar dados a partir de notas de clientes.
- Obter detalhes importantes de artigos de notícias.
O Agent Bricks: information Extraction aproveita os recursos de avaliação automatizada, incluindo MLflow e Agent Evaluation, para permitir uma avaliação rápida da relação custo-qualidade para sua tarefa de extração específica. Essa avaliação permite que o senhor tome decisões informadas sobre o equilíbrio entre precisão e investimento em recursos.
O Agent Bricks utiliza o armazenamentodefault para guardar transformações de dados temporárias, pontos de verificação do modelo e metadados internos que alimentam cada agente. Ao excluir um agente, todos os dados associados a ele são removidos do armazenamento default .
Requisitos
-
Um workspace que inclui o seguinte:
- Prévia (Beta) dos blocos do agente Mosaic AI ativada. Veja as prévias do gerenciar Databricks.
- sem servidor compute ativado. Consulte os requisitos do compute sem servidor.
- Unity Catalog habilitado. Consulte Ativar um workspace para Unity Catalog.
- Acesso a modelos básicos no Unity Catalog por meio do esquema
system.ai. - Acesso a uma política orçamentáriaserverless com um orçamento diferente de zero.
-
Um workspace em uma das regiões compatíveis:
us-east-1ouus-west-2. -
Capacidade de usar a função
ai_querySQL. -
Arquivos dos quais o senhor deseja extrair dados. Os arquivos devem estar em um volume ou tabela do Unity Catalog.
- Se o senhor quiser usar PDFs, primeiro converta-os em uma tabela do Unity Catalog. Consulte Usar PDFs no Agent Bricks.
- Para criar seu agente, o senhor precisa de pelo menos 1 documento não rotulado no volume do Unity Catalog ou 1 linha na tabela.
Criar um agente de extração de informações
Vá para ![]() Agentes no painel de navegação esquerdo do seu workspace. No bloco Extração de informações , clique em Construir .
Agentes no painel de navegação esquerdo do seu workspace. No bloco Extração de informações , clique em Construir .
o passo 1: Configure seu agente
Configure seu agente:
-
No campo Nome , insira um nome para seu agente.
-
Selecione o tipo de dados que você deseja fornecer. O senhor pode escolher entre Unlabeled dataset (conjunto de dados sem rótulo ) ou Labeled dataset (conjunto de dados com rótulo ).
-
Selecione o endereço dataset para fornecer.
- Unlabeled dataset
- Labeled dataset
Se você selecionar Sem rótulo dataset :
-
No campo de localização do conjunto de dados , selecione a pasta ou tabela que deseja usar no volume Unity Catalog. Se você selecionar uma pasta, ela deverá conter documentos em um formato de documento compatível.
Veja a seguir um exemplo de volume:
/Volumes/main/info-extraction/bbc_articles/ -
Se o senhor estiver fornecendo uma tabela, selecione a coluna que contém os dados de texto no site dropdown. A coluna da tabela deve conter dados em um formato de dados compatível.
Se o senhor quiser usar PDFs, primeiro converta-os em uma tabela do Unity Catalog. Consulte Usar PDFs no Agent Bricks.
-
O Agent Bricks infere e gera automaticamente um exemplo de saída JSON contendo dados extraídos do seu dataset no campo "Saída JSON de exemplo" . Você pode aceitar a saída de exemplo, editá-la ou substituí-la por um exemplo da saída JSON desejada. O agente retorna as informações extraídas usando este formato.
Se você selecionar rótulo dataset :
- No campo datasetde verdades fundamentais , selecione a tabela Unity Catalog que contém seus dados de verdades fundamentais.
- No campo Coluna de entrada , selecione a coluna que contém o texto que você deseja que o agente processe. Os dados nessa coluna devem estar no formato
str. - No campo da coluna "Resposta verdadeira" , selecione a coluna que contém as respostas ideais esperadas. Os dados nesta coluna devem ser strings JSON . Cada linha nesta coluna deve seguir o mesmo formato JSON. Linhas contendo chaves adicionais ou ausentes não são aceitáveis.
- No campo de saída JSON de exemplo , o Agent Bricks gera automaticamente um exemplo de saída JSON usando a primeira linha de dados da coluna de resposta de referência. Verifique se a saída JSON corresponde ao formato esperado.
-
Verifique se o campo de saída JSON de exemplo corresponde ao formato de resposta desejado. Edite conforme necessário.
Por exemplo, o seguinte exemplo de saída JSON pode ser usado para extrair informações de um conjunto de artigos de notícias:
JSON{
"title": "Economy Slides to Recession",
"category": "Politics",
"paragraphs": [
{
"summary": "GDP fell by 0.1% in the last three months of 2004.",
"word_count": 38
},
{
"summary": "Consumer spending had been depressed by one-off factors such as the unseasonably mild winter.",
"word_count": 42
}
],
"tags": ["Recession", "Economy", "Consumer Spending"],
"estimate_time_to_read_min": 1,
"published_date": "2005-01-15",
"needs_review": false
} -
Em Escolha do modelo , selecione o modelo mais adequado para o seu agente de extração de informações:
- Otimizar para escalabilidade (default): Escolha esta opção se estiver processando grandes volumes de dados ou se preferir um agente com boa relação custo-benefício. Este modelo foi projetado para altas taxas de transferência e tempos de resposta mais rápidos e é adequado para a maioria das tarefas de extração de informação.
- Otimizar para Complexidade : Escolha esta opção se precisar de raciocínio complexo e priorizar a precisão em detrimento da velocidade e do custo. Este modelo oferece maior capacidade de raciocínio para documentos mais longos (como demonstrações financeiras) e pode lidar com extrações mais complexas (como extrair mais de 40 campos de esquema).
-
Clique em Criar agente .
Formatos de documentos suportados
A tabela a seguir mostra os tipos de arquivos de documentos suportados para seus documentos de origem se o senhor fornecer um volume do Unity Catalog.
Arquivos de código | Arquivos de documentos | arquivos de registro |
|---|---|---|
|
|
|
Formatos de dados suportados
Agent Bricks: a extração de informações é compatível com os seguintes tipos de dados e esquemas para os documentos de origem se o senhor fornecer uma tabela Unity Catalog. O Agent Bricks também pode extrair esses tipos de dados de cada documento.
strintfloatbooleanenum(usado para tarefas de classificação onde o agente deve selecionar apenas categorias predefinidas)- Objeto
- Matrizes
enum (adequado para tarefas de classificação onde queremos que o agente produza apenas um conjunto de categorias predefinidas) objeto (no lugar de "campos aninhados personalizados") variedade
o passo 2: Melhore seu agente
Na tab "Construir" , revise os exemplos de saída para ajudá-lo a refinar a definição do seu esquema e adicionar instruções para obter melhores resultados.
-
À esquerda, revise exemplos de respostas e forneça feedback para ajustar seu agente. Esses exemplos são baseados na sua configuração atual do agente.
- Clique em uma linha para visualizar a entrada e a resposta completas.
- Na parte inferior, ao lado de "Esta resposta está correta?" , forneça feedback selecionando uma das opções.
 Sim ou
Sim ou  Corrija isso . Para enviar feedback sobre a correção , forneça detalhes adicionais sobre como o agente deve alterar sua resposta e clique em
Corrija isso . Para enviar feedback sobre a correção , forneça detalhes adicionais sobre como o agente deve alterar sua resposta e clique em  Salvar .
Salvar . - Após concluir a revisão de todas as respostas, clique em Sim, atualize o agente . Ou você pode clicar em Salvar feedback e atualizar após analisar pelo menos três respostas.
-
À direita, em Campos de saída , refine as descrições dos campos do seu esquema de extração. Essas descrições são o que o agente utiliza para entender o que você deseja extrair. Utilize as respostas de exemplo à esquerda para ajudá-lo a refinar a definição do esquema.
- Para cada campo, revise e edite a definição do esquema conforme necessário. Utilize as respostas de exemplo à esquerda para ajudá-lo(a) a refinar essas descrições.
- Para editar o nome e o tipo do campo, clique em
 Editar campo .
Editar campo . - Para adicionar um novo campo, clique
 Adicionar novo campo . Insira o nome, o tipo e a descrição e clique em Confirmar .
Adicionar novo campo . Insira o nome, o tipo e a descrição e clique em Confirmar . - Para remover um campo, clique
 Remover campo .
Remover campo . - Clique em Salvar e atualizar para atualizar a configuração do seu agente.
-
(Opcional) À direita, em Instruções , insira quaisquer instruções globais para o seu agente. Estas instruções aplicam-se a todos os elementos extraídos. Clique em Salvar e atualizar para aplicar as instruções.
-
Novas respostas de amostra são geradas no lado esquerdo. Revise essas respostas atualizadas e continue a refinar a configuração do seu agente até que as respostas sejam satisfatórias.
o passo 3: Use seu agente
O senhor pode usar seu agente em fluxo de trabalho em Databricks.
Para começar a usar seu agente, clique em Usar . Você pode escolher usar seu agente de várias maneiras:
- extração de dados para todos os documentos : Clique em iniciar extração para abrir o editor SQL e use
ai_querypara enviar solicitações ao seu novo agente de extração de informações. - Criar pipeline ETL : Clique em Criar pipeline para implantar um pipeline que será executado em intervalos agendados para usar seu agente em novos dados. Consulte o pipeline declarativoLakeFlow Spark para obter mais informações sobre o pipeline.
- Teste seu agente : clique em Abrir no Playground para testar seu agente em um ambiente de teste e ver como ele funciona. Veja Bate-papo com LLMs e protótipos de aplicativos AI generativa usando AI Playground para saber mais sobre AI Playground.
(Opcional) o passo 4: Avalie seu agente
Para garantir que você criou um agente de alta qualidade, execute uma avaliação e revise o relatório de qualidade resultante.
-
Mude para a tab Qualidade .
-
Clique
avaliação de execução . -
No painel Nova Avaliação que desliza para fora, configure a avaliação:
- Selecione o nome da execução de avaliação. Você pode escolher usar um nome gerado ou fornecer um nome personalizado.
- Selecione o dataset de avaliação. Você pode escolher usar o mesmo dataset de origem usado para criar seu agente ou fornecer um dataset de avaliação personalizado usando dados rotulados ou não rotulados.
-
Clique para iniciar a avaliação .
-
Após a conclusão da execução da sua avaliação, revise o relatório de qualidade:
-
Por default é exibida uma view de resumo . Revisar a qualidade geral, o custo, a Taxa de transferência e o relatório resumido das métricas de avaliação. Clique
 Ao lado do campo de esquema, você pode ver como esse campo é avaliado.
Ao lado do campo de esquema, você pode ver como esse campo é avaliado.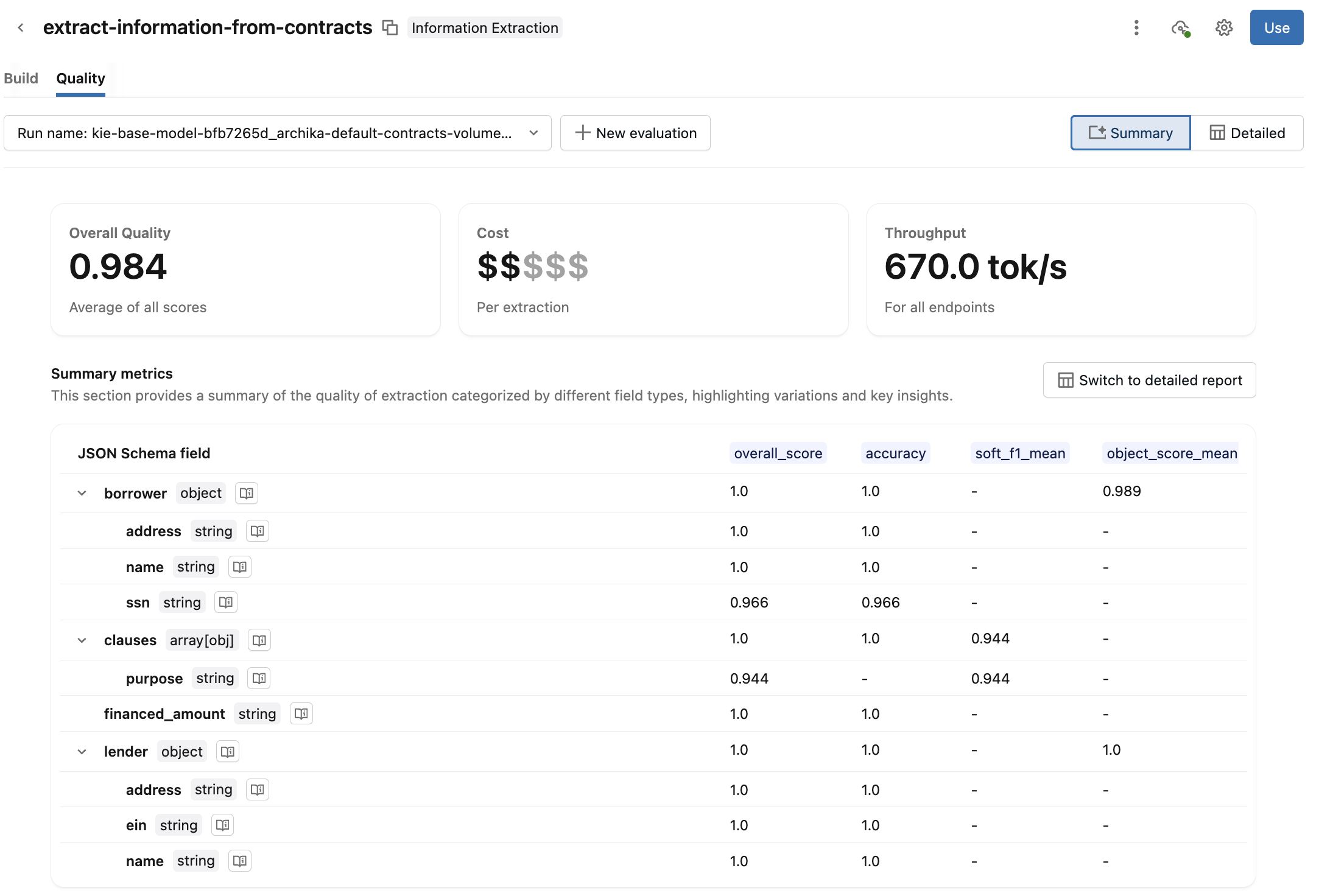
-
Mude para a view Detalhada para obter mais detalhes. Esta view mostra cada solicitação e a pontuação de avaliação para cada uma delas. Clique em uma solicitação para ver detalhes adicionais, como entrada, saída, avaliações, rastreamentos e prompts relacionados. Você também pode editar as avaliações da solicitação e fornecer feedback adicional.
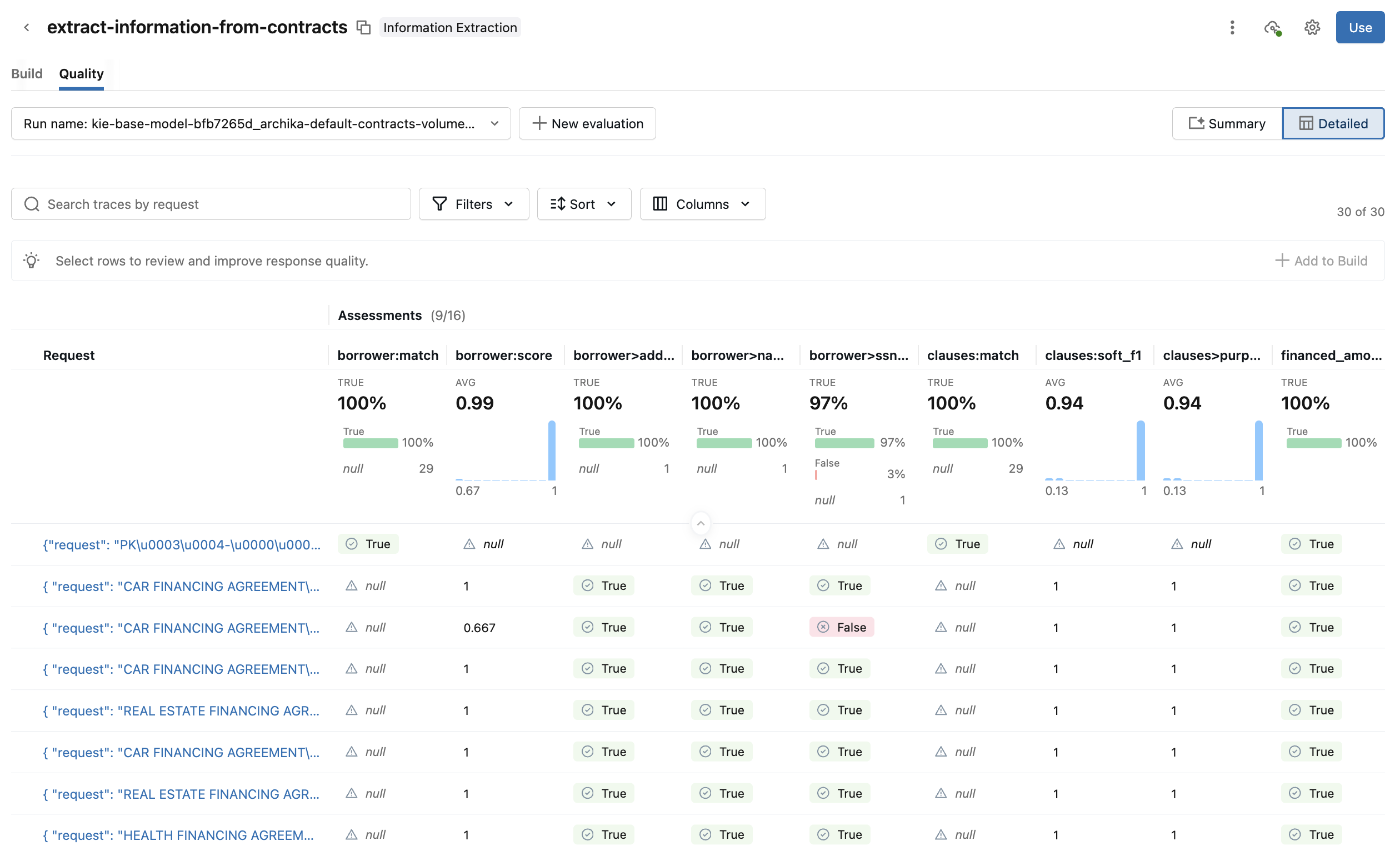
-
Consultar o agente endpoint
Na página do agente, clique ![]() Consulte o status do agente no canto superior direito para obter o endpoint do agente implantado e visualizar os detalhes do endpoint.
Consulte o status do agente no canto superior direito para obter o endpoint do agente implantado e visualizar os detalhes do endpoint.
Existem várias maneiras de consultar o endpoint do agente criado. Utilize os exemplos de código fornecidos no AI Playground como ponto de partida:
- Na página do agente, clique em Usar .
- Clique em Abrir no playground .
- No Playground, clique em Obter código .
- Escolha como o senhor deseja usar o endpoint:
- Selecione Aplicar nos dados para criar uma consulta SQL que aplique o agente a uma coluna específica da tabela.
- Selecione Curl API para obter um exemplo de código para consultar o endpoint usando curl.
- Selecione Python API para obter um exemplo de código para interagir com o endpoint usando Python.
gerenciar permissões
Por default, somente os autores do Agent Bricks e os administradores workspace têm permissões para acessar o agente. Para permitir que outros usuários editem ou consultem seu agente, você precisa conceder-lhes permissão explicitamente.
Para gerenciar as permissões do seu agente:
-
Abra sua agência no Agent Bricks.
-
Na parte superior, clique em
 Cardápio de kebabs.
Cardápio de kebabs. -
Clique em gerenciar permissões .
-
Na janela Configurações de Permissão , selecione o usuário, grupo ou entidade de serviço.
-
Selecione a permissão que deseja conceder:
- Gerenciar : Permite gerenciar os Agent Bricks, incluindo definir permissões, editar a configuração do agente e melhorar sua qualidade.
- Permissão para consulta : Permite consultar o endpoint do Agent Bricks no AI Playground e por meio da API. Usuários com apenas essa permissão não podem view ou editar o agente no Agent Bricks.
-
Clique em Adicionar .
-
Clique em Salvar .
Para endpoints de agente criados antes de 16 de setembro de 2025 , você pode conceder permissões de "Pode consultar" ao endpoint na página "Endpoint de serviço" .
Use PDFs no Agent Bricks
Os PDFs ainda não são suportados nativamente no Agent Bricks: information Extraction e Custom LLM. No entanto, o senhor pode usar o fluxo de trabalho da interface do usuário do Agent Brick para converter uma pasta de arquivos PDF em markdown e, em seguida, usar a tabela resultante do Unity Catalog como entrada ao criar seu agente. Esse fluxo de trabalho usa ai_parse_document para a conversão. Siga estas etapas:
-
Clique em Agents no painel de navegação esquerdo para abrir o Agent Bricks no Databricks.
-
Nos casos de uso de Extração de informações ou LLM personalizado, clique em Usar PDFs .
-
No painel lateral que se abre, preencha os seguintes campos para criar um novo fluxo de trabalho para converter seus PDFs:
- Selecione a pasta com PDFs ou imagens : selecione a pasta Unity Catalog que contém os PDFs que você deseja usar.
- Selecione a tabela de destino : Selecione o esquema de destino para a tabela de remarcação para baixo convertida e, opcionalmente, ajuste o nome da tabela no campo abaixo.
- Select active SQL warehouse : Selecione o site SQL warehouse para executar o fluxo de trabalho.
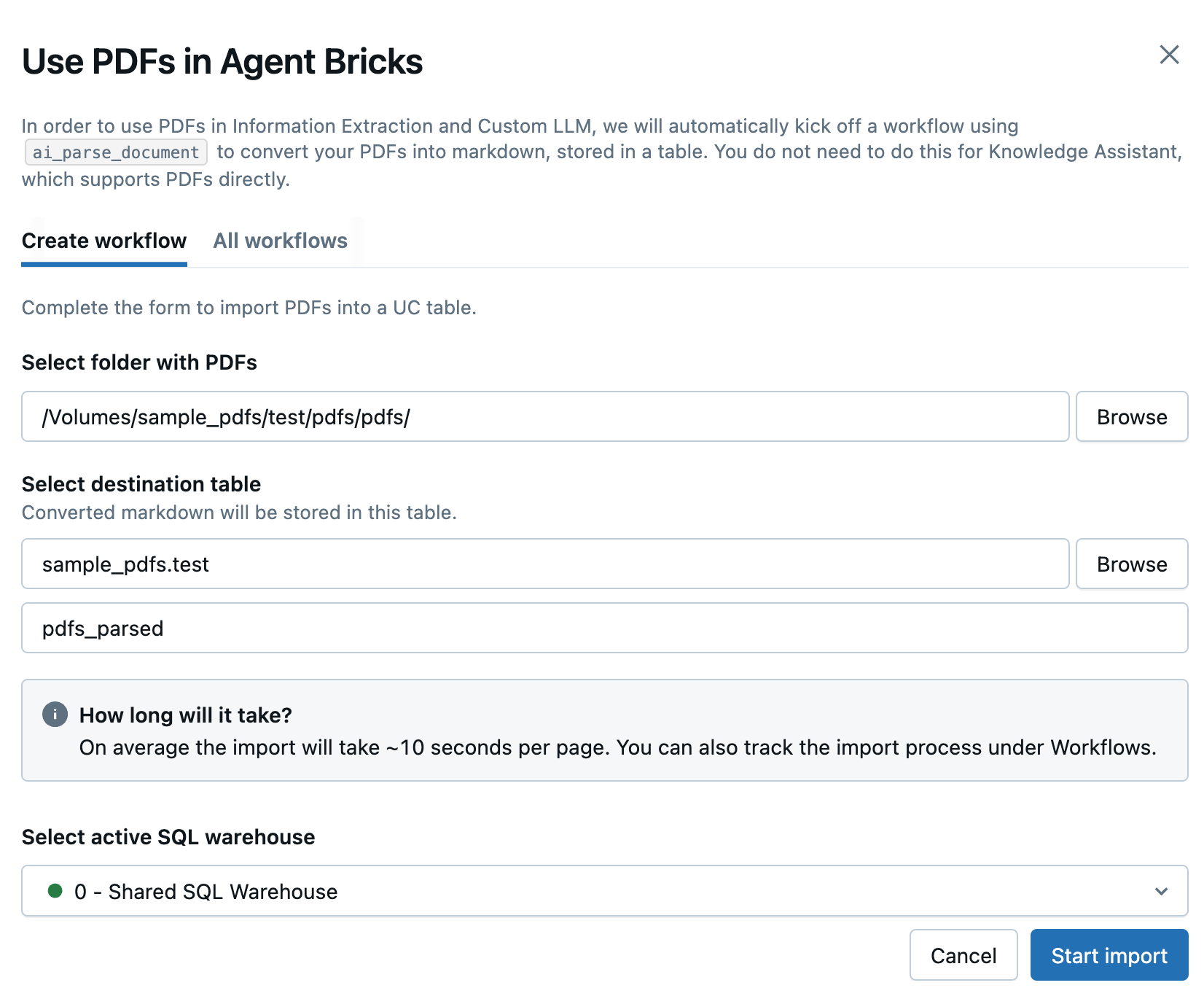
-
Clique em começar a importar .
-
O senhor será redirecionado para o All fluxo de trabalho tab, que lista todos os seus fluxos de trabalho em PDF. Use o site tab para monitorar o status do seu trabalho.
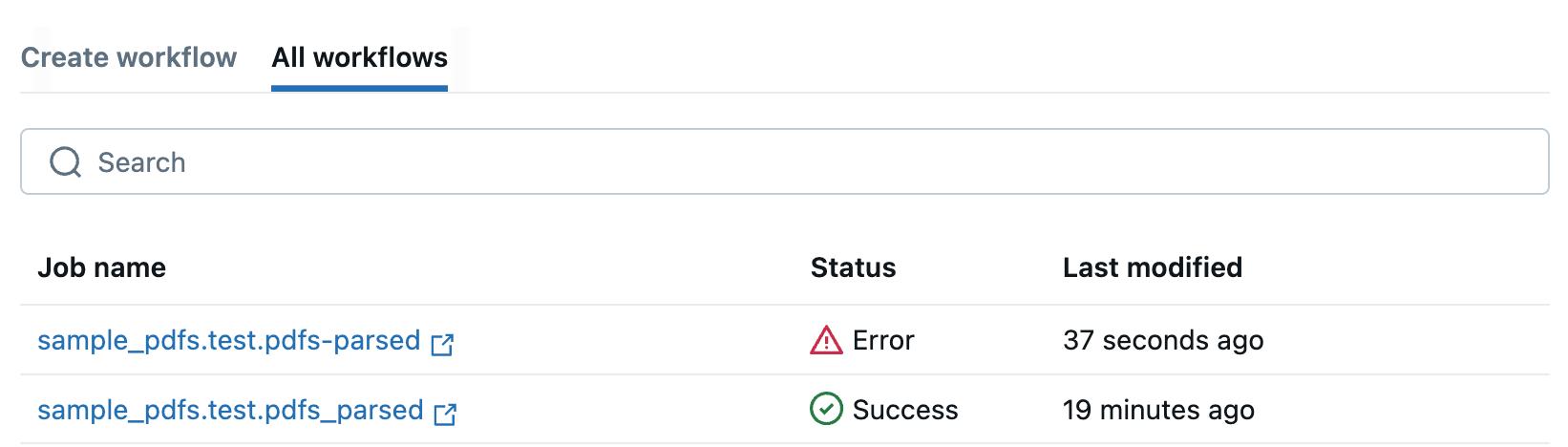
Se o fluxo de trabalho falhar, clique no nome do trabalho para abri-lo e view mensagens de erro para ajudá-lo a depurar.
-
Quando o fluxo de trabalho for concluído com êxito, clique no nome do trabalho para abrir a tabela no Catalog Explorer e explorar e entender as colunas.
-
Use a tabela do Unity Catalog como dados de entrada no Agent Bricks ao configurar seu agente.
Limitações
- informação Os agentes de extração possuem um comprimento máximo de contexto de 128k tokens.
- Os espaços de trabalho que possuem Segurança Avançada e conformidade ativadas não são suportados.
- Não há suporte para tipos de esquema de união.