O senhor pode começar com AI agentes
Crie e implante seu primeiro agente AI usando Databricks Apps padrão. Neste tutorial você vai:
- Crie e implante o agente a partir da interface de usuário Databricks Apps .
- Converse com o agente usando uma interface de chat pré-configurada.
Pré-requisitos
Habilite Databricks Apps em seu workspace. Consulte Configurar seu workspace e ambiente de desenvolvimento Databricks Apps.
implantar o agente padrão
Comece usando um agente pré-construído padrão do aplicativoDatabricks repositório padrão.
Este tutorial utiliza o padrão agent-openai-agents-sdk , que inclui:
- Um agente criado usando o SDK de Agentes da OpenAI
- Código inicial para um aplicativo de agente com uma API REST conversacional e uma interface de chat interativa.
- Código para avaliar o agente usando MLflow
Instale o aplicativo padrão usando a interface do usuário do espaço de trabalho. Isso instala o aplicativo e o implanta em um recurso compute em seu workspace.
-
No seu workspace Databricks , clique em + Novo > Aplicativo .
-
Clique em Agentes > Agente - SDK de Agentes da OpenAI .
-
Crie um novo experimento MLflow com o nome
openai-agents-templatee conclua o restante da configuração para instalar o padrão. -
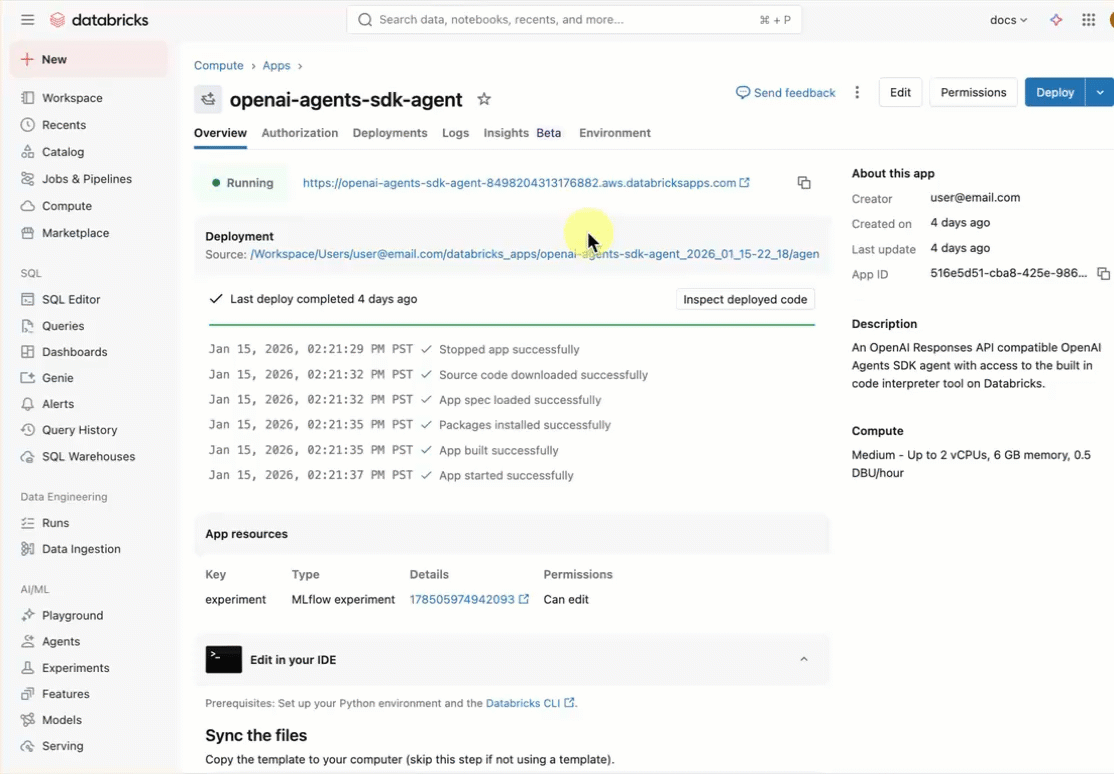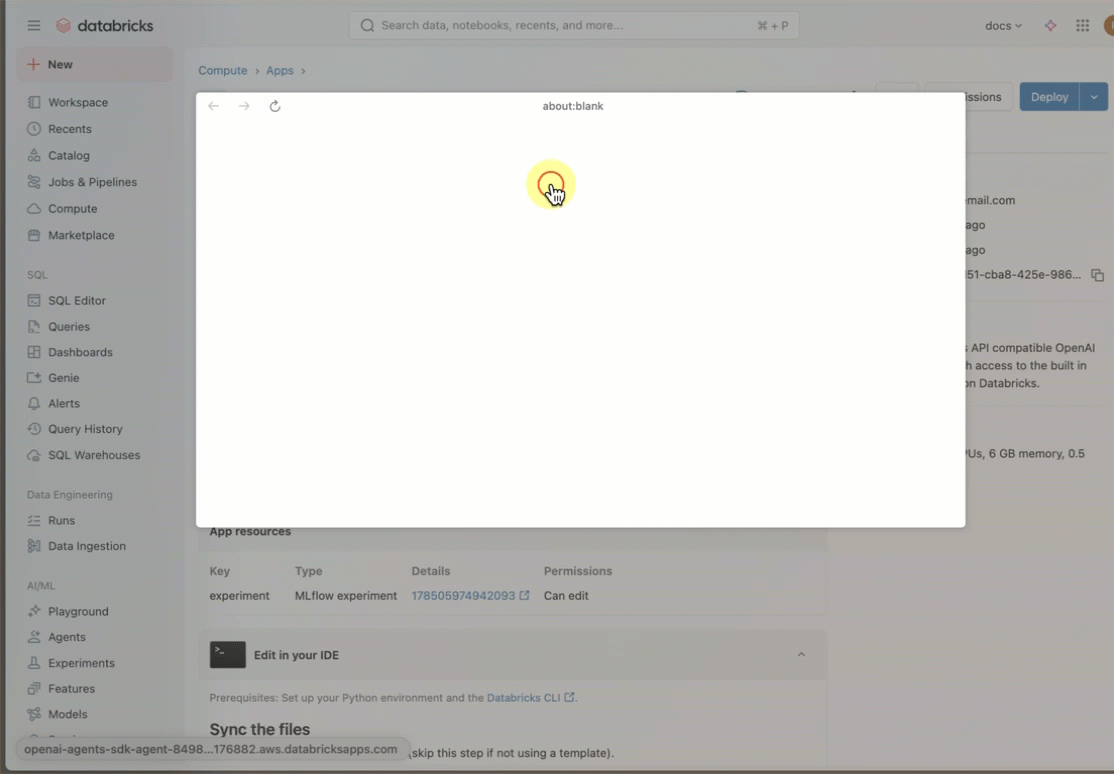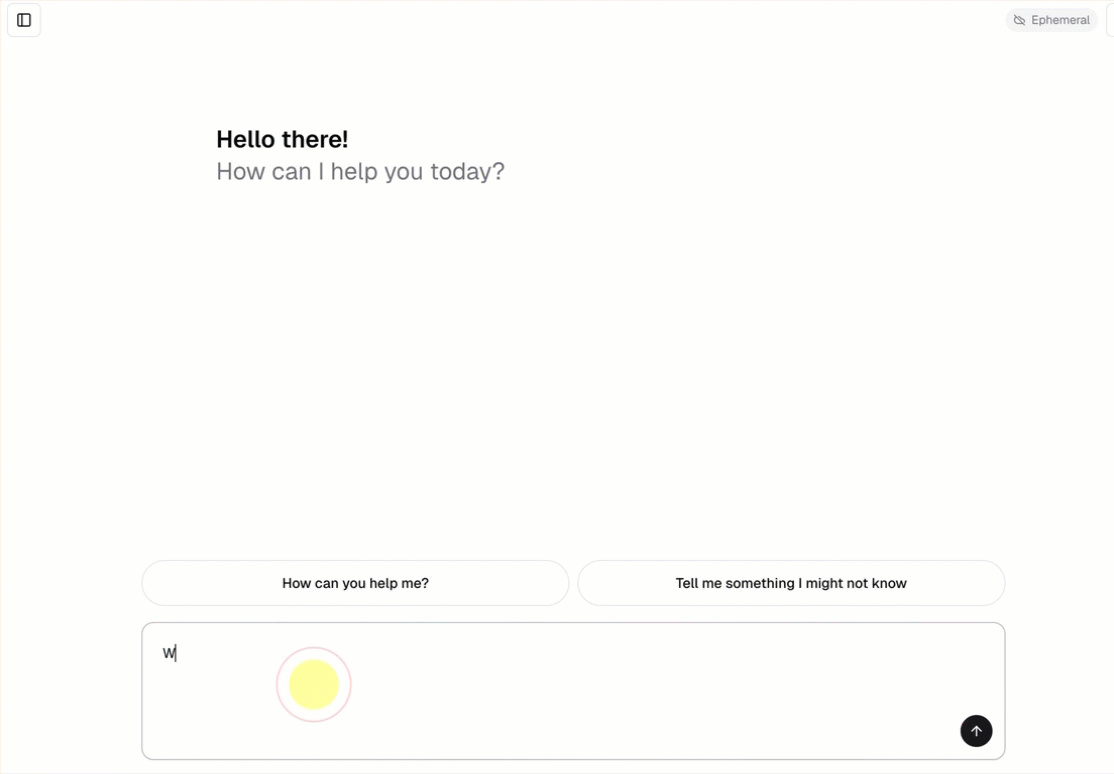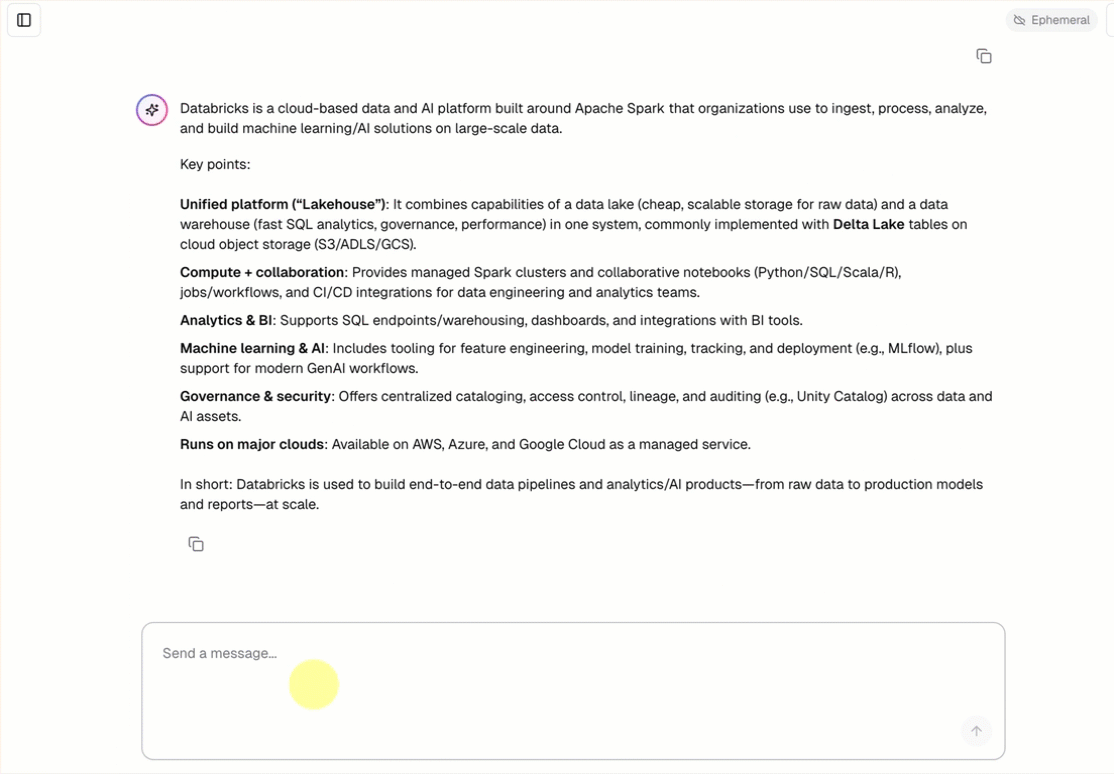
Após criar o aplicativo, clique no URL do aplicativo para abrir a interface de bate-papo.
Compreenda a aplicação do agente
O agente padrão demonstra uma arquitetura pronta para produção com estes componentes key :
MLflow AgentServer : Um servidor FastAPI assíncrono que lida com solicitações de agentes com rastreamento e observabilidade integrados. O AgentServer fornece o endpoint /invocations para consultar seu agente e gerencia automaticamente o roteamento de solicitações, registro e tratamento de erros.
OpenAI Agents SDK : O padrão utiliza o OpenAI Agents SDK como framework de agentes para gerenciamento de conversas e orquestração de ferramentas. Você pode criar agentes usando qualquer framework. A key é envolver seu agente com a interface MLflow ResponsesAgent .
InterfaceResponsesAgent : Esta interface garante que seu agente funcione em diferentes estruturas e se integre com as ferramentas do Databricks. Crie seu agente usando SDK OpenAI , LangGraph, LangChain ou Python puro e, em seguida, envolva-o com ResponsesAgent para obter compatibilidade automática com AI Playground, a avaliação de agentes e a implantação Databricks Apps .
Servidores MCP (Model Context Protocol) : O padrão se conecta aos servidores MCP Databricks para acessar agentes, ferramentas e fonte de dados. Consulte o Protocolo de Contexto do Modelo (MCP) no Databricks.

Próximas etapas
Aprenda como criar um agente personalizado :Crie um agente AI e implante-o no Databricks Apps