Tutorial: Build your first machine learning model on Databricks
This tutorial shows you how to build a machine learning classification model using the scikit-learn library on Databricks.
The goal is to create a classification model to predict whether a wine is considered “high-quality”. The dataset consists of 11 features of different wines (for example, alcohol content, acidity, and residual sugar) and a quality ranking between 1 to 10.
This example also illustrates the use of MLflow to track the model development process, and Hyperopt to automate hyperparameter tuning.
The dataset is from the UCI Machine Learning Repository, presented in Modeling wine preferences by data mining from physicochemical properties [Cortez et al., 2009].
Before you begin
- Your workspace must be enabled for Unity Catalog. See Get started with Unity Catalog.
- You must have permission to create a compute resource or access to a compute resource that uses Databricks Runtime for Machine Learning.
- You must have the USE CATALOG privilege on a catalog.
- Within that catalog, you must have the following privileges on a schema: USE SCHEMA, CREATE TABLE, and CREATE MODEL.
All of the code in this article is available in a notebook that you can import directly into your workspace. See Example notebook: Build a classification model.
Step 1: Create a Databricks notebook
To create a notebook in your workspace, click ![]() New in the sidebar, and then click Notebook. A blank notebook opens in the workspace.
New in the sidebar, and then click Notebook. A blank notebook opens in the workspace.
To learn more about creating and managing notebooks, see Manage notebooks.
Step 2: Connect to compute resources
To do exploratory data analysis and data engineering, you must have access to compute. The steps in this article require Databricks Runtime for Machine Learning. For more information and instructions for selecting an ML version of Databricks Runtime, see Databricks Runtime for Machine Learning.
In your notebook, click the Connect drop-down menu in the top right. If you have access to an existing resource that uses Databricks Runtime for Machine Learning, then select that resource from the menu. Otherwise, click Create new resource... to configure a new compute resource.
Step 3: Set up model registry, catalog, and schema
There are two important steps required before you get started. First, you must configure the MLflow client to use Unity Catalog as the model registry. Enter the following code into a new cell in your notebook.
import mlflow
mlflow.set_registry_uri("databricks-uc")
You must also set the catalog and schema where the model will be registered. You must have USE CATALOG privilege on the catalog, and USE SCHEMA, CREATE TABLE, and CREATE MODEL privileges on the schema.
For more information about how to use Unity Catalog, see What is Unity Catalog?.
Enter the following code into a new cell in your notebook.
# If necessary, replace "main" and "default" with a catalog and schema for which you have the required permissions.
CATALOG_NAME = "main"
SCHEMA_NAME = "default"
Step 4: Load data and create Unity Catalog tables
This example uses two CSV files that are available in databricks-datasets. To learn how to ingest your own data, see Standard connectors in Lakeflow Connect.
Enter the following code into a new cell in your notebook. This code does the following:
- Read data from
winequality-white.csvandwinequality-red.csvinto Spark DataFrames. - Clean the data by replacing spaces in column names with underscores.
- Write the DataFrames to
white_wineandred_winetables in Unity Catalog. Saving the data to Unity Catalog both persists the data and lets you control how to share it with others.
white_wine = spark.read.csv("/databricks-datasets/wine-quality/winequality-white.csv", sep=';', header=True)
red_wine = spark.read.csv("/databricks-datasets/wine-quality/winequality-red.csv", sep=';', header=True)
# Remove the spaces from the column names
for c in white_wine.columns:
white_wine = white_wine.withColumnRenamed(c, c.replace(" ", "_"))
for c in red_wine.columns:
red_wine = red_wine.withColumnRenamed(c, c.replace(" ", "_"))
# Define table names
red_wine_table = f"{CATALOG_NAME}.{SCHEMA_NAME}.red_wine"
white_wine_table = f"{CATALOG_NAME}.{SCHEMA_NAME}.white_wine"
# Write to tables in Unity Catalog
spark.sql(f"DROP TABLE IF EXISTS {red_wine_table}")
spark.sql(f"DROP TABLE IF EXISTS {white_wine_table}")
white_wine.write.saveAsTable(f"{CATALOG_NAME}.{SCHEMA_NAME}.white_wine")
red_wine.write.saveAsTable(f"{CATALOG_NAME}.{SCHEMA_NAME}.red_wine")
Step 5. Preprocess and split the data
In this step, you load the data from the Unity Catalog tables you created in Step 4 into Pandas DataFrames and preprocess the data. The code in this section does the following:
- Loads the data as Pandas DataFrames.
- Adds a Boolean column to each DataFrame to distinguish red and white wines, and then combines the DataFrames into a new DataFrame,
data_df. - The dataset includes a
qualitycolumn that rates wines from 1 to 10, with 10 indicating the highest quality. The code transforms this column into two classification values: “True” to indicate a high-quality wine (quality>= 7) and “False” to indicate a wine that is not high-quality (quality< 7). - Splits the DataFrame into separate train and test datasets.
First, import the required libraries:
import numpy as np
import pandas as pd
import sklearn.datasets
import sklearn.metrics
import sklearn.model_selection
import sklearn.ensemble
import matplotlib.pyplot as plt
from hyperopt import fmin, tpe, hp, SparkTrials, Trials, STATUS_OK
from hyperopt.pyll import scope
Now load and preprocess the data:
# Load data from Unity Catalog as Pandas dataframes
white_wine = spark.read.table(f"{CATALOG_NAME}.{SCHEMA_NAME}.white_wine").toPandas()
red_wine = spark.read.table(f"{CATALOG_NAME}.{SCHEMA_NAME}.red_wine").toPandas()
# Add Boolean fields for red and white wine
white_wine['is_red'] = 0.0
red_wine['is_red'] = 1.0
data_df = pd.concat([white_wine, red_wine], axis=0)
# Define classification labels based on the wine quality
data_labels = data_df['quality'].astype('int') >= 7
data_df = data_df.drop(['quality'], axis=1)
# Split 80/20 train-test
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
data_df,
data_labels,
test_size=0.2,
random_state=1
)
Step 6. Train the classification model
This step trains a gradient boosting classifier using the default algorithm settings. It then applies the resulting model to the test dataset and calculates, logs, and displays the area under the receiver operating curve to evaluate the model's performance.
First, enable MLflow autologging:
mlflow.autolog()
Now start the model training run:
with mlflow.start_run(run_name='gradient_boost') as run:
model = sklearn.ensemble.GradientBoostingClassifier(random_state=0)
# Models, parameters, and training metrics are tracked automatically
model.fit(X_train, y_train)
predicted_probs = model.predict_proba(X_test)
roc_auc = sklearn.metrics.roc_auc_score(y_test, predicted_probs[:,1])
roc_curve = sklearn.metrics.RocCurveDisplay.from_estimator(model, X_test, y_test)
# Save the ROC curve plot to a file
roc_curve.figure_.savefig("roc_curve.png")
# The AUC score on test data is not automatically logged, so log it manually
mlflow.log_metric("test_auc", roc_auc)
# Log the ROC curve image file as an artifact
mlflow.log_artifact("roc_curve.png")
print("Test AUC of: {}".format(roc_auc))
The cell results show the calculated area under the curve and a plot of the ROC curve:
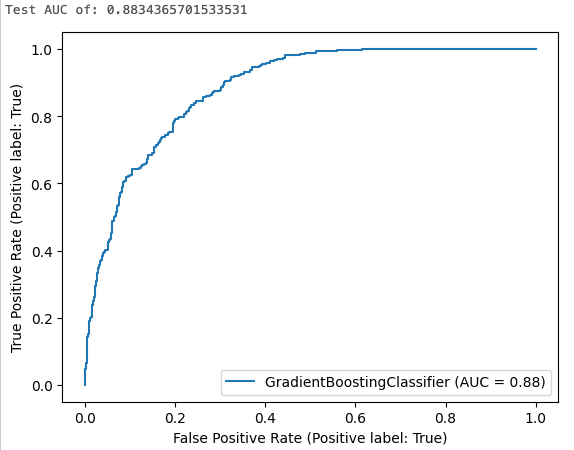
Step 7. View experiment runs in MLflow
MLflow experiment tracking helps you keep track of model development by logging code and results as you iteratively develop models.
To view the logged results from the training run you just executed, click the link in the cell output, as shown in the following image.
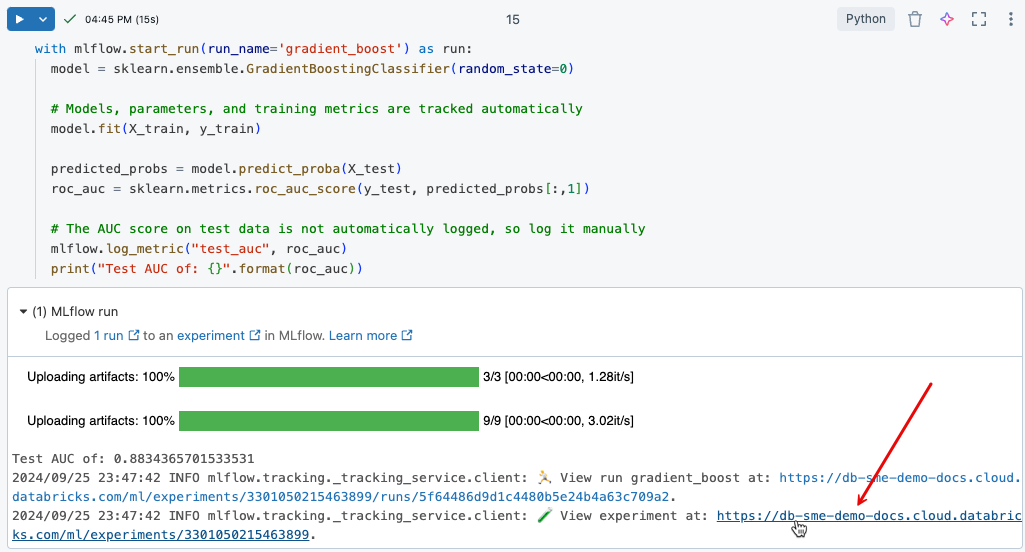
The experiment page allows you to compare runs and view details for specific runs. Click the name of a run to see details such as parameter and metric values for that run. See MLflow experiment tracking.
You can also view your notebook's experiment runs by clicking the Experiment icon ![]() in the upper right of the notebook. This opens the experiment sidebar, which shows a summary of each run associated with the notebook eperiment, including run parameters and metrics. If necessary, click the refresh icon to fetch and monitor the latest runs.
in the upper right of the notebook. This opens the experiment sidebar, which shows a summary of each run associated with the notebook eperiment, including run parameters and metrics. If necessary, click the refresh icon to fetch and monitor the latest runs.
![]()
Step 8. Use Hyperopt for hyperparameter tuning
An important step in developing an ML model is optimizing the model's accuracy by tuning the parameters that control the algorithm, called hyperparameters.
Databricks Runtime ML includes Hyperopt, a Python library for hyperparameter tuning. You can use Hyperopt to run hyperparameter sweeps and train multiple models in parallel, reducing the time required to optimize model performance. MLflow tracking is integrated with Hyperopt to automatically log models and parameters. For more information about using Hyperopt in Databricks, see Hyperparameter tuning.
The following code shows an example of using Hyperopt.
# Define the search space to explore
search_space = {
'n_estimators': scope.int(hp.quniform('n_estimators', 20, 1000, 1)),
'learning_rate': hp.loguniform('learning_rate', -3, 0),
'max_depth': scope.int(hp.quniform('max_depth', 2, 5, 1)),
}
def train_model(params):
# Enable autologging on each worker
mlflow.autolog()
with mlflow.start_run(nested=True):
model_hp = sklearn.ensemble.GradientBoostingClassifier(
random_state=0,
**params
)
model_hp.fit(X_train, y_train)
predicted_probs = model_hp.predict_proba(X_test)
# Tune based on the test AUC
# In production, you could use a separate validation set instead
roc_auc = sklearn.metrics.roc_auc_score(y_test, predicted_probs[:,1])
mlflow.log_metric('test_auc', roc_auc)
# Set the loss to -1*auc_score so fmin maximizes the auc_score
return {'status': STATUS_OK, 'loss': -1*roc_auc}
# SparkTrials distributes the tuning using Spark workers
# Greater parallelism speeds processing, but each hyperparameter trial has less information from other trials
# On smaller clusters try setting parallelism=2
spark_trials = SparkTrials(
parallelism=1
)
with mlflow.start_run(run_name='gb_hyperopt') as run:
# Use hyperopt to find the parameters yielding the highest AUC
best_params = fmin(
fn=train_model,
space=search_space,
algo=tpe.suggest,
max_evals=32,
trials=spark_trials)
Step 9. Find the best model and register it to Unity Catalog
The following code identifies the run that produced the best results, as measured by the area under the ROC curve:
# Sort runs by their test auc. In case of ties, use the most recent run.
best_run = mlflow.search_runs(
order_by=['metrics.test_auc DESC', 'start_time DESC'],
max_results=10,
).iloc[0]
print('Best Run')
print('AUC: {}'.format(best_run["metrics.test_auc"]))
print('Num Estimators: {}'.format(best_run["params.n_estimators"]))
print('Max Depth: {}'.format(best_run["params.max_depth"]))
print('Learning Rate: {}'.format(best_run["params.learning_rate"]))
Using the run_id that you identified for the best model, the following code registers that model to Unity Catalog.
model_uri = 'runs:/{run_id}/model'.format(
run_id=best_run.run_id
)
mlflow.register_model(model_uri, f"{CATALOG_NAME}.{SCHEMA_NAME}.wine_quality_model")
Step 10. Deploy the model to production
When you are ready to serve and deploy your models, you can do so using the Serving UI in your Databricks workspace.
Example notebook: Build a classification model
Use the following notebook to perform the steps in this article. For instructions on importing a notebook to a Databricks workspace, see Import a notebook.
Build your first machine learning model with Databricks
Learn more
Databricks provides a single platform that serves every step of ML development and deployment, from raw data to inference tables that save every request and response for a served model. Data scientists, data engineers, ML engineers, and DevOps can do their jobs using the same set of tools and a single source of truth for the data.
To learn more, see the following:
- Machine learning and AI tutorials
- Overview of machine learning and AI on Databricks
- Overview of training machine learning and AI models on Databricks
- MLflow for ML model lifecycle