日付とタイムスタンプ
このドキュメントは廃止されており、更新されない可能性があります。 このコンテンツに記載されている製品、サービス、またはテクノロジはサポートされなくなりました。 「日時パターン」を参照してください。
Databricks Runtime 7.0 では、 Date データ型と Timestamp データ型が大幅に変更されました。 この記事では、次の内容について説明します。
Dateの種類と関連付けられているカレンダー。Timestampの種類と、タイム ゾーンとの関係。また、Databricks Runtime 7.0 で使用される Java 8 の新しい Time API のタイム ゾーン オフセット解像度と微妙な動作変更の詳細についても説明します。- 日付とタイムスタンプの値を作成するAPI。
- Apache Spark ドライバーで日付オブジェクトとタイムスタンプ オブジェクトを収集するための一般的な落とし穴とベスト プラクティス。
日付とカレンダー
Dateは、(year=2012, month=12, day=31) のように、年、月、日フィールドの組み合わせです。ただし、年、月、および日のフィールドの値には、日付値が現実世界で有効な日付であることを保証するための制約があります。 たとえば、month の値は 1 から 12 まで、day の値は 1 から 28、29、30、または 31 (年と月によって異なります) までである必要があります。 Dateタイプでは、タイムゾーンは考慮されません。
カレンダー
Dateフィールドに対する制約は、多くの可能なカレンダーの 1 つによって定義されます。太陰暦のように、特定の地域でのみ使用されるものもあります。ユリウス暦のように、歴史上のみ使用されるものもあります。事実上の国際標準は グレゴリオ暦 で、世界中のほぼどこでも民生目的で使用されています。 1582年に導入され、1582年より前の日付にも拡張されました。 この拡張されたカレンダーは、 プロレプティックグレゴリオ暦と呼ばれます。
Databricks Runtime 7.0 では、 Pandas、R、 Apache Arrow などの他のデータ システムで既に使用されている先発グレゴリオ暦が使用されます。 Databricks Runtime 6.x 以下では、ユリウス暦とグレゴリオ暦の組み合わせが使用されていました: 1582 年より前の日付ではユリウス暦が使用され、1582 年以降の日付ではグレゴリオ暦が使用されました。 これは、Java 8でプロレプティックグレゴリオ暦を使用するjava.time.LocalDateに置き換えられたレガシーjava.sql.DateAPIから継承されます。
タイムスタンプとタイムゾーン
Timestamp タイプは、Date タイプを拡張し、新しいフィールド (時、分数、秒 (小数部を持つことができます)、およびグローバル (セッション スコープ) タイム ゾーン付き) を追加します。これは、具体的な時間的瞬間を定義します。 たとえば、(year=2012, month=12, day=31, hour=23, minute=59, second=59.123456) セッション タイム ゾーン UTC+01:00 を使用します。 Parquet などのテキスト以外のデータソースにタイムスタンプ値を書き込む場合、値はタイムゾーン情報を持たない単なるインスタント (UTC のタイムスタンプなど) です。 異なるセッションタイムゾーンでタイムスタンプ値を書き込んだり読み取ったりすると、時、分、秒の各フィールドに異なる値が表示されることがありますが、それらは同じ具体的な時刻のインスタントです。
時、分、秒の各フィールドには、標準範囲 (時間の場合は 0 から 23、分と秒の場合は 0 から 59) があります。 Spark は、マイクロ秒の精度で小数秒をサポートします。 分数の有効な範囲は 0 から 999,999 マイクロ秒です。
具体的な瞬間には、タイムゾーンに応じて、さまざまなウォールクロックの値を観察できます。
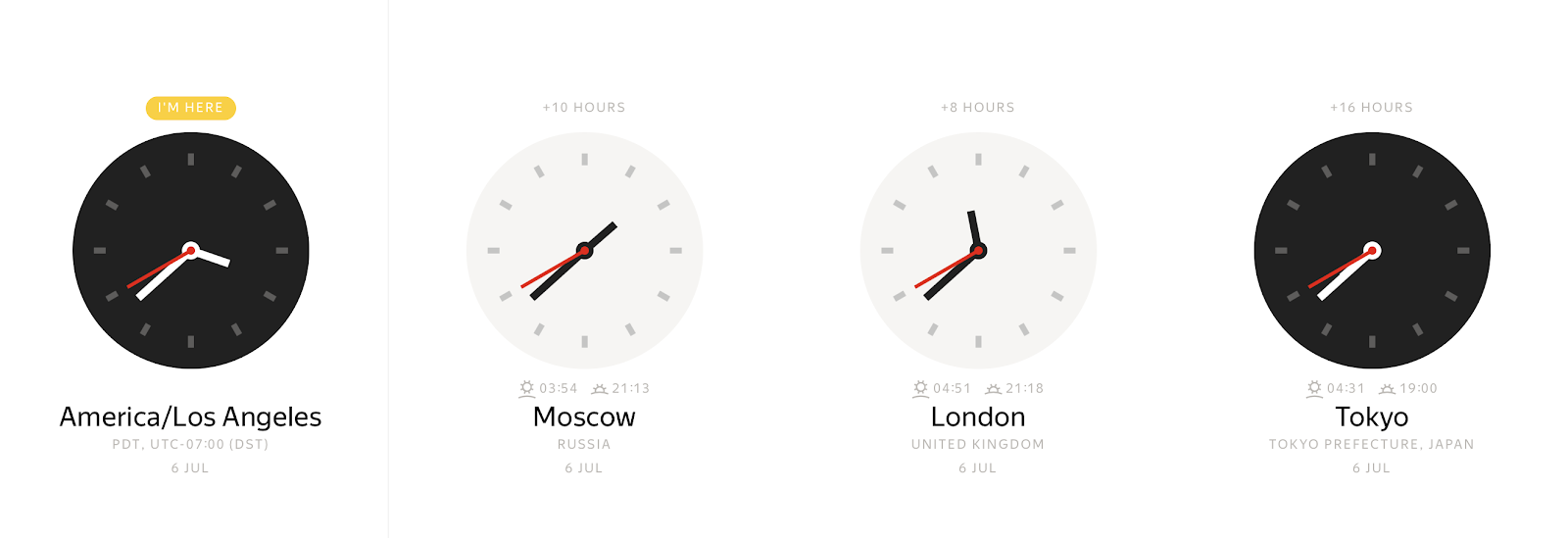
逆に、ウォールクロックの値は、さまざまな時間的瞬間を表すことができます。
タイム ゾーン オフセット を使用すると、ローカル タイムスタンプを時刻のインスタントに明確にバインドできます。通常、タイム ゾーン オフセットは、グリニッジ標準時 (GMT) または UTC+0 (協定世界時) からの時間単位のオフセットとして定義されます。このタイム ゾーン情報の表現はあいまいさを排除しますが、不便です。ほとんどの人は、 America/Los_Angeles や Europe/Parisなどの場所を指摘することを好みます。このゾーンオフセットからの抽象化レベルが加わることで、生活は楽になりますが、複雑さが伴います。たとえば、タイムゾーン名をオフセットにマップするために、特別なタイムゾーンデータベースを維持する必要があります。Spark は JVM 上で実行されるため、マッピングを Java 標準ライブラリに委任し、Java 標準ライブラリは Internet Assigned Numbers Authority Time Zone Database (IANA TZDB) からデータを読み込みます。さらに、Javaの標準ライブラリのマッピングメカニズムには、Sparkの動作に影響を与えるいくつかのニュアンスがあります。
Java 8 以降、JDK は日時操作とタイム ゾーン オフセット解決のための異なる API を公開し、Databricks Runtime 7.0 はこの API を使用します。 タイムゾーン名とオフセットのマッピングのソースは同じですが、Java 8 以降では Java 7 とは異なる方法で実装されています。
たとえば、 America/Los_Angeles タイム ゾーン ( 1883-11-10 00:00:00) で 1883 年より前のタイムスタンプを見てみましょう。 今年は、1883年11月18日に北米のすべての鉄道が新しい標準時システムに切り替えたため、他の年とは一線を画しています。 Java 7 time API を使用すると、次のようにローカル タイムスタンプでタイム ゾーン オフセットを取得できます -08:00。
java.time.ZoneId.systemDefault
res0:java.time.ZoneId = America/Los_Angeles
java.sql.Timestamp.valueOf("1883-11-10 00:00:00").getTimezoneOffset / 60.0
res1: Double = 8.0
同等のJava 8 APIは、異なる結果を返します。
java.time.ZoneId.of("America/Los_Angeles").getRules.getOffset(java.time.LocalDateTime.parse("1883-11-10T00:00:00"))
res2: java.time.ZoneOffset = -07:52:58
1883年11月18日以前は、北米の時刻は地域的な問題であり、ほとんどの都市や町は、よく知られた時計(教会の尖塔や宝石商の窓など)によって維持される何らかの形の地元の太陽時を使用していました。そのため、このような奇妙なタイムゾーンのオフセットが表示されます。
この例では、 Java 8 つの関数がより正確であり、IANA TZDB からアカウント ヒストリカルデータ を取り込むことを示しています。 Java 8 タイム API に切り替えた後、Databricks Runtime 7.0 は自動的に改善の恩恵を受け、タイム ゾーン オフセットの解決方法がより正確になりました。
Databricks Runtime 7.0 では、 Timestamp の種類も Proleptic グレゴリオ暦に切り替えられました。 ISO SQL:2016 標準では、タイムスタンプの有効な範囲が 0001-01-01 00:00:00 から 9999-12-31 23:59:59.999999であると宣言されています。Databricks Runtime 7.0 は標準に完全に準拠しており、この範囲内のすべてのタイムスタンプをサポートします。 Databricks Runtime 6.x 以下と比較すると、次のサブ範囲に注意してください。
0001-01-01 00:00:00..1582-10-03 23:59:59.999999.Databricks Runtime 6.x 以下ではユリウス暦が使用されており、標準に準拠していません。Databricks Runtime 7.0 では、この問題が修正され、年、月、日などの取得などのタイムスタンプに対する内部操作で Proleptic グレゴリオ暦が適用されます。カレンダーが異なるため、Databricks Runtime 6.x 以前に存在する一部の日付は、Databricks Runtime 7.0 には存在しません。たとえば、1000 はグレゴリオ暦のうるう年ではないため、1000-02-29 は有効な日付ではありません。また、Databricks Runtime 6.x 以下では、このタイムスタンプ範囲のタイム ゾーン名からゾーン オフセットへのオフセットが正しく解決されません。1582-10-04 00:00:00..1582-10-14 23:59:59.999999.これは、Databricks Runtime 7.0 のローカル タイムスタンプの有効な範囲であり、Databricks Runtime 6.x 以下ではそのようなタイムスタンプが存在しなかったのとは対照的です。1582-10-15 00:00:00..1899-12-31 23:59:59.999999. Databricks Runtime 7.0 では、IANA TZDB のヒストリカルデータを使用して、タイムゾーンオフセットを正しく解決します。 Databricks Runtime 7.0 と比較すると、Databricks Runtime 6.x 以下では、前の例に示すように、タイム ゾーン名からのゾーン オフセットが正しく解決されない場合があります。1900-01-01 00:00:00..2036-12-31 23:59:59.999999.Databricks Runtime 7.0 と Databricks Runtime 6.x 以下の両方が ANSI SQL 標準に準拠しており、月の日の取得などの日時操作でグレゴリオ暦を使用します。2037-01-01 00:00:00..9999-12-31 23:59:59.999999.Databricks Runtime 6.x 以下では、タイム ゾーン オフセットと夏時間オフセットが正しく解決されない可能性があります。 Databricks Runtime 7.0 ではそうではありません。
タイムゾーン名をオフセットにマッピングするもう 1 つの側面は、夏時間 (DST) や別の標準タイム ゾーン オフセットへの切り替えによって発生する可能性のあるローカル タイムスタンプの重複です。たとえば、2019 年 11 月 3 日 02:00:00 に、米国のほとんどの州で時計が 1 時間戻されて 01:00:00 になったとします。ローカル タイムスタンプ 2019-11-03 01:30:00 America/Los_Angeles は、 2019-11-03 01:30:00 UTC-08:00 または 2019-11-03 01:30:00 UTC-07:00にマッピングできます。オフセットを指定せず、タイム ゾーン名 ( 2019-11-03 01:30:00 America/Los_Angelesなど) を設定するだけの場合、Databricks Runtime 7.0 は以前のオフセット (通常は "summer" に対応します) を受け取ります。この動作は、"winter" オフセットを取る Databricks Runtime 6.x 以前とは異なります。クロックが前方にジャンプするギャップの場合、有効なオフセットはありません。一般的な 1 時間の夏時間の変更の場合、Spark はそのようなタイムスタンプを「夏」時間に対応する次の有効なタイムスタンプに移動します。
前の例からわかるように、タイム ゾーン名とオフセットのマッピングはあいまいで、1 対 1 ではありません。 可能な場合は、タイムスタンプを作成するときに、正確なタイムゾーンオフセット( 2019-11-03 01:30:00 UTC-07:00など)を指定することをお勧めします。
ANSI SQL と Spark SQL のタイムスタンプ
ANSI SQL 標準では、次の 2 種類のタイムスタンプが定義されています。
TIMESTAMP WITHOUT TIME ZONEまたはTIMESTAMP: ローカルタイムスタンプ (YEAR,MONTH,DAY,HOUR,MINUTE,SECOND) これらのタイムスタンプは、どのタイム ゾーンにもバインドされておらず、ウォール クロック タイムスタンプです。TIMESTAMP WITH TIME ZONE: (YEAR、MONTH、DAY、HOUR、MINUTE、SECOND、TIMEZONE_HOUR、TIMEZONE_MINUTE) としてゾーニングされたタイムスタンプ 。 これらのタイムスタンプは、UTC タイム ゾーンのインスタント + 各値に関連付けられたタイム ゾーン オフセット (時間と分単位) を表します。
TIMESTAMP WITH TIME ZONEのタイム ゾーン オフセットは、タイムスタンプが表す物理的な時点に影響を与えません。これは、他のタイムスタンプ コンポーネントによって指定される UTC 時刻のインスタントによって完全に表されます。代わりに、タイムゾーンオフセットは、表示、日付/時刻コンポーネントの抽出( EXTRACTなど)、およびタイムスタンプに月を追加するなど、タイムゾーンを知る必要があるその他の操作のタイムスタンプ値のデフォルト動作にのみ影響します。
Spark SQL では、タイムスタンプのタイプを TIMESTAMP WITH SESSION TIME ZONEとして定義し、フィールド (YEAR、 MONTH、 DAY、 HOUR、 MINUTE、 SECOND、 SESSION TZ) の組み合わせで、 YEAR から SECOND フィールドが UTC タイムゾーンのタイムインスタントを識別します。 ここで、SESSION TZはSQL構成spark.sql.session.timeZoneから取得されます。 セッションのタイム ゾーンは、次のように設定できます。
- ゾーンオフセット
(+|-)HH:mm. このフォームを使用すると、物理的な時点を明確に定義できます。 - リージョン ID
area/cityの形式のタイム ゾーン名 (America/Los_Angelesなど)。 この形式のタイムゾーン情報は、ローカルタイムスタンプの重複など、前に説明したいくつかの問題に悩まされています。 ただし、各 UTC タイム インスタントは、任意のリージョン ID の 1 つのタイム ゾーン オフセットに明確に関連付けられるため、リージョン ID ベースのタイム ゾーンを持つ各タイムスタンプは、ゾーン オフセットを持つタイムスタンプに明確に変換できます。 デフォルトでは、セッション・タイム・ゾーンは Java 仮想マシンのデフォルト・タイム・ゾーンに設定されます。
Spark TIMESTAMP WITH SESSION TIME ZONE は、次のものとは異なります。
TIMESTAMP WITHOUT TIME ZONEこれは、この種類の値は複数の物理時間インスタントにマップできますが、TIMESTAMP WITH SESSION TIME ZONEの値は具体的な物理時間インスタントであるためです。 SQL 型は、すべてのセッションで 1 つの固定タイム ゾーン オフセット (UTC+0 など) を使用してエミュレートできます。 その場合、UTC のタイムスタンプをローカル タイムスタンプと見なすことができます。TIMESTAMP WITH TIME ZONEこれは、SQL 標準に従って、型の列値に異なるタイム ゾーン オフセットを含めることができるためです。 これは Spark SQL ではサポートされていません。
グローバル (セッション スコープ) タイム ゾーンに関連付けられているタイムスタンプは、Spark SQL によって新しく考案されたものではないことに注意してください。 Oracle などの RDBMS は、タイムスタンプに対して同様のタイプ ( TIMESTAMP WITH LOCAL TIME ZONE.
日付とタイムスタンプの構築
Spark SQL には、日付とタイムスタンプの値を作成するためのメソッドがいくつか用意されています。
- デフォルト コンストラクター (パラメーターなし):
CURRENT_TIMESTAMP()とCURRENT_DATE(). - 他のプリミティブ Spark SQL 型 (
INT、LONG、STRING - Python の datetime や Java クラスなどの外部型から
java.time.LocalDate/Instant. - CSV、JSON、Avro、Parquet、ORCなどのデータソースからの逆シリアル化。
Databricks Runtime 7.0 で導入された関数 MAKE_DATE 、YEAR、 MONTH、 DAYの 3 つのパラメーターを受け取り、 DATE 値を構築します。 すべての入力パラメーターは、可能な限り暗黙的に INT 型に変換されます。 この関数は、結果の日付がプロレプティック グレゴリオ暦の有効な日付であるかどうかをチェックし、そうでない場合は NULLを返します。 例えば:
spark.createDataFrame([(2020, 6, 26), (1000, 2, 29), (-44, 1, 1)],['Y', 'M', 'D']).createTempView('YMD')
df = sql('select make_date(Y, M, D) as date from YMD')
df.printSchema()
root
|-- date: date (nullable = true)
データフレームコンテンツを出力するには、エグゼキューターで日付を文字列に変換し、その文字列をドライバーに転送してコンソールに出力するshow()アクションを呼び出します。
df.show()
+-----------+
| date|
+-----------+
| 2020-06-26|
| null|
|-0044-01-01|
+-----------+
同様に、 MAKE_TIMESTAMP 関数を使用してタイムスタンプ値を作成できます。 MAKE_DATEと同様に、日付フィールドに対して同じ検証を実行し、さらに時間フィールド HOUR (0-23)、MINUTE (0-59)、および SECOND (0-60) を受け入れます。SECOND は Decimal(precision = 8, scale = 6) 型です。これは、秒を小数部からマイクロ秒の精度まで渡すことができるためです。 例えば:
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30.123456), \
(1582, 10, 10, 0, 1, 2.0001), (2019, 2, 29, 9, 29, 1.0)],['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND'])
df.show()
+----+-----+---+----+------+---------+
|YEAR|MONTH|DAY|HOUR|MINUTE| SECOND|
+----+-----+---+----+------+---------+
|2020| 6| 28| 10| 31|30.123456|
|1582| 10| 10| 0| 1| 2.0001|
|2019| 2| 29| 9| 29| 1.0|
+----+-----+---+----+------+---------+
df.selectExpr("make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND) as MAKE_TIMESTAMP")
ts.printSchema()
root
|-- MAKE_TIMESTAMP: timestamp (nullable = true)
日付については、show() アクションを使用して ts データフレーム の内容を出力します。 同様に、show() はタイムスタンプを文字列に変換しますが、今では SQL config spark.sql.session.timeZone で定義されたセッションのタイムゾーンをアカウントに取り込みます。
ts.show(truncate=False)
+--------------------------+
|MAKE_TIMESTAMP |
+--------------------------+
|2020-06-28 10:31:30.123456|
|1582-10-10 00:01:02.0001 |
|null |
+--------------------------+
2019 年はうるう年ではないためこの日付は無効ということになり、Spark は最後のタイムスタンプを作成できません。
前の例では、タイム ゾーン情報がないことに気付くかもしれません。 その場合、Spark は SQL 構成 spark.sql.session.timeZone からタイム ゾーンを取得し、それを関数の呼び出しに適用します。 また、 MAKE_TIMESTAMPの最後のパラメーターとして渡すことで、別のタイムゾーンを選択することもできます。 次に例を示します。
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30, 'UTC'),(1582, 10, 10, 0, 1, 2, 'America/Los_Angeles'), \
(2019, 2, 28, 9, 29, 1, 'Europe/Moscow')], ['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND', 'TZ'])
df = df.selectExpr('make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, TZ) as MAKE_TIMESTAMP')
df = df.selectExpr("date_format(MAKE_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss VV') AS TIMESTAMP_STRING")
df.show(truncate=False)
+---------------------------------+
|TIMESTAMP_STRING |
+---------------------------------+
|2020-06-28 13:31:00 Europe/Moscow|
|1582-10-10 10:24:00 Europe/Moscow|
|2019-02-28 09:29:00 Europe/Moscow|
+---------------------------------+
例に示すように、 Spark は指定されたタイム ゾーンをアカウントに取り込みますが、すべてのローカル タイムスタンプをセッション タイム ゾーンに調整します。 MAKE_TIMESTAMP 関数に渡された元のタイムゾーンは、TIMESTAMP WITH SESSION TIME ZONE 型がすべての値が 1 つのタイムゾーンに属していると想定し、すべての値ごとにタイムゾーンを格納しないため、失われます。TIMESTAMP WITH SESSION TIME ZONEの定義に従って、SparkはローカルタイムスタンプをUTCタイムゾーンで保存し、日時フィールドの抽出やタイムスタンプの文字列への変換時にはセッションタイムゾーンを使用します。
また、タイムスタンプは、キャストを使用して LONG 型から構築できます。 LONG 列にエポック 1970-01-01 00:00:00Z からの秒数が含まれている場合は、Spark SQL TIMESTAMPにキャストできます。
select CAST(-123456789 AS TIMESTAMP);
1966-02-02 05:26:51
残念ながら、この方法では秒の小数部を指定することはできません。
別の方法は、 STRING 型の値から日付とタイムスタンプを作成することです。 特別なキーワードを使用してリテラルを作成できます。
select timestamp '2020-06-28 22:17:33.123456 Europe/Amsterdam', date '2020-07-01';
2020-06-28 23:17:33.123456 2020-07-01
または、列内のすべての値に適用できるキャストを使用することもできます。
select cast('2020-06-28 22:17:33.123456 Europe/Amsterdam' as timestamp), cast('2020-07-01' as date);
2020-06-28 23:17:33.123456 2020-07-01
入力タイムスタンプ文字列は、指定されたタイムゾーンのローカルタイムスタンプとして解釈されるか、入力文字列でタイムゾーンが省略されている場合はセッションタイムゾーンのタイムスタンプとして解釈されます。 通常とは異なるパターンの文字列は、 to_timestamp() 関数を使用してタイムスタンプに変換できます。 サポートされているパターンについては、「 書式設定と解析の日時パターン」で説明されています。
select to_timestamp('28/6/2020 22.17.33', 'dd/M/yyyy HH.mm.ss');
2020-06-28 22:17:33
パターンを指定しない場合、関数は CASTと同様に動作します。
使いやすさのために、Spark SQL は、文字列を受け入れ、タイムスタンプまたは日付を返すすべてのメソッドで特別な文字列値を認識します。
epochは、日付1970-01-01またはタイムスタンプ1970-01-01 00:00:00Zのエイリアスです。nowは、セッション・タイム・ゾーンにおける現在のタイム・スタンプまたは日付です。 1 つのクエリ内では、常に同じ結果が生成されます。todayは、TIMESTAMPタイプの現在の日付の始まり、またはDATEタイプの現在の日付です。tomorrowは、タイムスタンプの場合は翌日の始まり、DATEタイプの場合は翌日です。yesterdayは、現在の 1 日の前日、またはTIMESTAMPタイプの開始日です。
例えば:
select timestamp 'yesterday', timestamp 'today', timestamp 'now', timestamp 'tomorrow';
2020-06-27 00:00:00 2020-06-28 00:00:00 2020-06-28 23:07:07.18 2020-06-29 00:00:00
select date 'yesterday', date 'today', date 'now', date 'tomorrow';
2020-06-27 2020-06-28 2020-06-28 2020-06-29
Spark を使用すると、ドライバー側の既存の外部オブジェクトのコレクションから Datasets を作成し、対応する型の列を作成できます。 Spark は、外部型のインスタンスを意味的に同等の内部表現に変換します。 たとえば、Python コレクションから DATE 列と TIMESTAMP 列を含むDatasetを作成するには、次を使用できます。
import datetime
df = spark.createDataFrame([(datetime.datetime(2020, 7, 1, 0, 0, 0), datetime.date(2020, 7, 1))], ['timestamp', 'date'])
df.show()
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
PySpark は、Python の日時オブジェクトを、Spark のセッション タイム ゾーン設定とは異なるシステム タイム ゾーンを使用して、ドライバー側で内部 Spark SQL 表現に変換します spark.sql.session.timeZone。内部値には、元のタイム ゾーンに関する情報は含まれていません。並列化された日付とタイムスタンプの値に対する今後の操作は、TIMESTAMP WITH SESSION TIME ZONEタイプの定義に従って、セッションのタイムゾーンSpark SQLのみアカウントに取り込まれます。
同様に、 Spark では、 Java と Scala APIで次のタイプを外部日付/時間タイプとして認識します。
java.sql.DateDATE型の外部型としてjava.time.LocalDatejava.sql.TimestampTIMESTAMPタイプはjava.time.Instantです。
java.sql.*タイプとjava.time.*タイプには違いがあります。java.time.LocalDate と java.time.Instant は Java 8 で追加され、型は Databricks Runtime 7.0 以降で使用されているのと同じ暦である先発グレゴリオ暦に基づいています。 java.sql.Date と java.sql.Timestamp の下には、ハイブリッド カレンダー (1582-10-15 以降のユリウス暦 + グレゴリオ暦) という別のカレンダーがあり、これは Databricks Runtime 6.x 以前で使用されるレガシ カレンダーと同じです。 暦体系が異なるため、Spark は内部 Spark SQL 表現への変換中に追加の操作を実行し、入力日付/タイムスタンプを 1 つの暦から別の暦にリベースする必要があります。 リベース操作は、1900 年以降の最新のタイムスタンプでは少しオーバーヘッドがあり、古いタイムスタンプではより大きくなる可能性があります。
次の例は、Scala コレクションからタイムスタンプを作成する方法を示しています。最初の例では、文字列から java.sql.Timestamp オブジェクトを構築します。valueOfメソッドは、入力文字列をデフォルトのJVMタイムゾーンのローカルタイムスタンプとして解釈します。これは、Sparkのセッションタイムゾーンとは異なる場合があります。特定のタイムゾーンで java.sql.Timestamp または java.sql.Date のインスタンスを構築する必要がある場合は、 java.text.SimpleDateFormat (およびそのメソッド setTimeZone) または java.util.Calendar を参照してください。
Seq(java.sql.Timestamp.valueOf("2020-06-29 22:41:30"), new java.sql.Timestamp(0)).toDF("ts").show(false)
+-------------------+
|ts |
+-------------------+
|2020-06-29 22:41:30|
|1970-01-01 03:00:00|
+-------------------+
Seq(java.time.Instant.ofEpochSecond(-12219261484L), java.time.Instant.EPOCH).toDF("ts").show
+-------------------+
| ts|
+-------------------+
|1582-10-15 11:12:13|
|1970-01-01 03:00:00|
+-------------------+
同様に、java.sql.Dateまたはjava.sql.LocalDateのコレクションからDATE列を作成できます。java.sql.LocalDateインスタンスの並列化は、Spark のセッションまたは JVM のデフォルトのタイムゾーンに完全に依存しませんが、java.sql.Dateインスタンスの並列化には当てはまりません。ニュアンスがあります。
java.sql.Dateインスタンスは、ドライバーのデフォルトの JVM タイムゾーンでのローカル日付を表します。- Spark SQL 値への正しい変換を行うには、ドライバとエグゼキュータにおける既定の JVM タイムゾーンが同じである必要があります。
Seq(java.time.LocalDate.of(2020, 2, 29), java.time.LocalDate.now).toDF("date").show
+----------+
| date|
+----------+
|2020-02-29|
|2020-06-29|
+----------+
カレンダーとタイムゾーンに関連する問題を回避するために、タイムスタンプまたは日付のJava / Scalaコレクションの並列化では、Java 8 java.sql.LocalDate/Instant を外部タイプとして使用することをお勧めします。
日付とタイムスタンプの収集
並列化の逆の操作では、エグゼキューターからドライバーに日付とタイムスタンプを収集し、外部型のコレクションを返します。 たとえば、上記のcollect()アクションを使用して、DataFrameをドライバーに戻すことができます。
df.collect()
[Row(timestamp=datetime.datetime(2020, 7, 1, 0, 0), date=datetime.date(2020, 7, 1))]
Spark は、日付列とタイムスタンプ列の内部値をエグゼキューターからドライバーに UTC タイム ゾーンの時刻として転送し、セッション タイム ゾーンを使用せずに、ドライバーでシステム タイム ゾーンの Python datetime オブジェクトへの変換 Spark SQL 実行します。 collect() は、前のセクションで説明した show() アクションとは異なります。 show() は、タイムスタンプを文字列に変換するときにセッションのタイム ゾーンを使用し、ドライバーで結果の文字列を収集します。
Java および Scala API では、Spark は初期設定で次の変換を実行します。
- Spark SQL
DATEの値は、java.sql.Dateのインスタンスに変換されます。 - Spark SQL
TIMESTAMPの値は、java.sql.Timestampのインスタンスに変換されます。
どちらの変換も、ドライバーのデフォルトの JVM タイム・ゾーンで実行されます。 このように、Date.getDay()、 Spark SQL getHour()などを使用して取得できる日付/時刻フィールドと同じ日付/時刻フィールドを持つには、DAY、HOUR、ドライバーのデフォルトの JVM タイム ゾーンとエグゼキューターのセッション タイム ゾーンを同じにする必要があります。
java.sql.Date/Timestampから日付/タイムスタンプを作成するのと同様に、Databricks Runtime 7.0 は、先頭のグレゴリオ暦からハイブリッド カレンダー (ユリウス暦 + グレゴリオ暦) へのリベースを実行します。この操作は、現代の日付 (1582 年以降) とタイムスタンプ (1900 年以降) ではほぼ無料ですが、古い日付とタイムスタンプではオーバーヘッドが発生する可能性があります。
このようなカレンダー関連の問題を回避し、Java 8 以降に追加された java.time 型を返すように Spark に依頼できます。 SQL 構成 spark.sql.datetime.java8API.enabled を true に設定すると、 Dataset.collect() アクションは以下を返します。
java.time.LocalDateSpark SQLDATEタイプの場合java.time.InstantSpark SQLTIMESTAMPタイプの場合
Java 8 型と Databricks Runtime 7.0 以降はどちらも Proleptic グレゴリオ暦に基づいているため、変換はカレンダー関連の問題に悩まされることはなくなりました。collect() アクションは、デフォルトの JVM タイム・ゾーンに依存しません。タイムスタンプの変換は、タイムゾーンにまったく依存しません。日付変換では、SQL 構成 spark.sql.session.timeZoneのセッション タイム ゾーンが使用されます。たとえば、DATE列とTIMESTAMP列があり、デフォルトのJVMタイムゾーンをEurope/Moscowに設定し、セッションタイムゾーンをAmerica/Los_Angelesに設定しているDatasetがあるとします。
java.util.TimeZone.getDefault
res1: java.util.TimeZone = sun.util.calendar.ZoneInfo[id="Europe/Moscow",...]
spark.conf.get("spark.sql.session.timeZone")
res2: String = America/Los_Angeles
df.show
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
show() アクションはセッション時間 America/Los_Angelesのタイムスタンプを出力しますが、Datasetを収集すると java.sql.Timestamp に変換され、toString メソッドは次のようにEurope/Moscowを出力します。
df.collect()
res16: Array[org.apache.spark.sql.Row] = Array([2020-07-01 10:00:00.0,2020-07-01])
df.collect()(0).getAs[java.sql.Timestamp](0).toString
res18: java.sql.Timestamp = 2020-07-01 10:00:00.0
実際には、ローカルタイムスタンプ 2020-07-01 00:00:00 は UTC の 2020-07-01T07:00:00Z です。 Java 8 API を有効にしてデータセットを収集すると、次のことがわかります。
df.collect()
res27: Array[org.apache.spark.sql.Row] = Array([2020-07-01T07:00:00Z,2020-07-01])
java.time.Instant オブジェクトは、グローバル JVM タイム・ゾーンとは無関係に、任意のローカル・タイム・スタンプに変換できます。これは、java.sql.Timestampに対するjava.time.Instantの利点の1つです。前者では、グローバル JVM 設定を変更する必要があり、同じ JVM 上の他のタイムスタンプに影響します。 したがって、アプリケーションが異なるタイム ゾーンで日付またはタイムスタンプを処理し、Java または Scala Dataset.collect() API を使用してドライバーにデータを収集する際にアプリケーションが互いに競合しないようにする場合は、SQL 構成 spark.sql.datetime.java8API.enabledを使用して Java 8 API に切り替えることをお勧めします。