Unity Catalog でモデルのライフサイクルを管理する
このページでは、モデルの管理と展開のためにDatabricksが推奨するUnity Catalogのモデルについて説明します。 ワークスペースで Unity Catalog が有効になっていない場合、このページの機能は使用できません。代わりに、 「 Workspace Model Registry (レガシ) を使用してモデルのライフサイクルを管理する」を参照してください。 Workspace Model Registry から Unity Catalog にアップグレードする方法については、 「ワークフローとモデルを Unity Catalog に移行する」を参照してください。
この記事では、機械学習ワークフローの一部として Unity Catalog のモデルを使用して、ML モデルのライフサイクル全体を管理する方法について説明します。 Databricksは、MLflow Model Registry でホストされたバージョンのUnity Catalog を提供します。Unity Catalog のモデルは、一元化されたアクセス制御、監査、リネージ、ワークスペース間でのモデル検出など、Unity Catalog の利点を ML モデルに拡張します。 Unity Catalog のモデルは、オープンソースの MLflow Python クライアントと互換性があります。
Model Registryの概念の概要については、MLflow MLモデル ライフサイクルの を参照してください。
MLflow 3では、 Unity CatalogのMLflow Model Registryが大幅に強化されており、モデルで、パラメーターやメトリクスなどのデータを直接キャプチャし、すべてのワークスペースとエクスペリメントで利用できるようになります。 MLflow 3 のデフォルトのレジストリ URI はdatabricks-ucであり、 Unity CatalogのMLflow Model Registryが使用されることを意味します。 詳細については、モデル向けにMLflow 3 の使用を開始するおよびMLflow 3 でのModel Registryの改善を参照してください。
必要条件
-
Unity Catalog は、ワークスペースで有効にする必要があります。 「Unity Catalog の使用を開始する」を参照して、Unity Catalog メタストアを作成し、ワークスペースで有効にして、カタログを作成します。Unity Catalogが有効になっていない場合は、ワークスペース モデルレジストリを使用します。
-
Unity Catalogにアクセスできるコンピュート リソースを使用する必要があります。MLワークロードの場合、これはコンピュートのアクセスモードが 専用 (以前のシングルユーザー)である必要があることを意味します。詳細については、「 アクセス モード」を参照してください。 Databricks Runtime 15.4 LTS ML 以降では、 専用のグループ アクセス モードを使用することもできます。
-
新規登録モデルを作成するには、次の権限が必要です。
USE SCHEMAスキーマとそれを囲むカタログに対するUSE CATALOG権限。CREATE MODELまたはスキーマに対するCREATE FUNCTION権限。権限を付与するには、カタログエクスプローラ UI または SQL GRANT コマンドを使用します。
SQLGRANT CREATE MODEL ON SCHEMA <schema-name> TO <principal> -
Databricks on AWS GovCloudを使用している場合は、環境変数
MLFLOW_USE_DATABRICKS_SDK_MODEL_ARTIFACTS_REPO_FOR_UCをTrueに設定する必要があります。次のコードを使用して、ノートブックにセルを含めます。Pythonimport os
os.environ['MLFLOW_USE_DATABRICKS_SDK_MODEL_ARTIFACTS_REPO_FOR_UC'] = 'True'この設定は、モデルを登録しようとしたときに認証の問題が発生した場合にも役立つことがあります。 このアプローチは、デフォルト ストレージを使用する Delta Sharing と共有されるモデルには使用できません。
ワークスペースは、特権の継承をサポートする Unity Catalog メタストアにアタッチされている必要があります。 これは、2022年8月25日以降に作成されたすべてのメタストアに当てはまります。 古いメタストアで実行している場合は、ドキュメントに従ってアップグレードしてください。
Unity Catalog 用の MLflow クライアントをインストールして構成する
このセクションでは、Unity Catalog の MLflow クライアントをインストールして構成する手順について説明します。
MLflow Python クライアントをインストールする
Databricks Runtime 13.2 ML以降には、Unity Catalogのモデルのサポートが含まれています。
次のコードを使用して、最新バージョンの MLflow Python クライアントをノートブックにインストールすることで、Databricks Runtime 11.3 LTS 以降の Unity Catalog でモデルを使用することもできます。
%pip install --upgrade "mlflow-skinny[databricks]"
dbutils.library.restartPython()
Unity Catalog のモデルにアクセスするように MLflow クライアントを構成する
ワークスペースのデフォルトカタログが(hive_metastoreではなく)Unity Catalogにあり、Databricks Runtime 13.3 LTS以上を使用するか、MLflow 3を使用してクラスタリングを実行している場合、モデルはデフォルトカタログに自動的に作成され、デフォルトカタログからロードされます。この手順を実行する必要はありません。
その他のワークスペースの場合、 MLflow Python クライアントは Databricks ワークスペース モデルレジストリにモデルを作成します。 Unity Catalog のモデルにアップグレードするには、ノートブックで次のコードを使用して MLflow クライアントを構成します。
import mlflow
mlflow.set_registry_uri("databricks-uc")
デフォルト カタログが 2024 年 1 月より前の Unity Catalog カタログに構成され、ワークスペース モデルレジストリが 2024 年 1 月より前に使用された少数のワークスペースでは、上記のコマンドを使用してデフォルト カタログを手動で Unity Catalog に設定する必要があります。
Unity Catalog 互換モデルをトレーニングして登録する
必要な権限 :新しい登録済みモデルを作成するには、それを含むスキーマに対するCREATE MODEL権限とUSE SCHEMA権限、それを含むカタログに対するUSE CATALOG権限が必要です。登録済みモデルの下に新しいモデルバージョンを作成するには、登録済みモデルの所有者である必要があり、モデルを含むスキーマとカタログに対するUSE SCHEMA権限とUSE CATALOG権限が必要です。
モデルを登録しようとしたときに認証の問題が発生する場合は、環境変数 の [ MLFLOW_USE_DATABRICKS_SDK_MODEL_ARTIFACTS_REPO_FOR_UC ] を Trueに設定してみてください。 このアプローチは、デフォルト ストレージを使用する Delta Sharing と共有されるモデルには使用できません。 「要件」を参照してください。
Databricks on AWS GovCloudを使用している場合は、環境変数MLFLOW_USE_DATABRICKS_SDK_MODEL_ARTIFACTS_REPO_FOR_UCを Trueに設定する必要があります。「要件」を参照してください。
UC の新しい ML モデルバージョンには 、モデルシグネチャが必要です。モデル トレーニング ワークロードでシグネチャを使用して MLflow モデルをまだログに記録していない場合は、次のいずれかを行うことができます。
- 多くの一般的なML フレームワークのシグネチャを使用して自動的にモデルを記録するDatabricks Autologgingを使用します。MLflow のドキュメントでサポートされているフレームワークを参照してください。
- MLflow 2.5.0以降では、
mlflow.<flavor>.log_modelコールで入力例を指定でき、モデルのシグネチャが自動的に推論されます。詳細については、 MLflowドキュメントを参照してください。
次に、モデルの 3 レベルの名前を <catalog>.<schema>.<model> の形式で MLflow APIに渡します。
シグニチャーを持たないモデルバージョンには、特定の制限があります。これらの制限事項のリスト、および既存のモデル バージョンのシグネチャを追加または更新するには、「 既存のモデル バージョンのシグニチャを追加または更新する」を参照してください。
このセクションの例では、prodカタログの下のml_teamスキーマでモデルを作成してアクセスします。
このセクションのモデル トレーニングの例では、新しいモデル バージョンを作成し、 prod カタログに登録します。 prodカタログを使用するからといって、必ずしもモデル版が本番運用トラフィックを提供するわけではありません。モデル バージョンを囲むカタログ、スキーマ、および登録済みモデルは、その環境 (prod) と関連するガバナンス ルール (たとえば、管理者のみがカタログから削除できるように特権を設定できるなど) を反映し prod が、デプロイ ステータスは反映されません。デプロイの状態を管理するには、 モデル エイリアスを使用します。
自動ログを使用してモデルを Unity Catalog に登録する
モデルを登録するには、MLflow クライアント API の register_model() メソッドを使用します。 mlflow.register_modelを参照してください。
- MLflow 3
- MLflow 2.x
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
# Train a sklearn model on the iris dataset
X, y = datasets.load_iris(return_X_y=True, as_frame=True)
clf = RandomForestClassifier(max_depth=7)
clf.fit(X, y)
# Note that the UC model name follows the pattern
# <catalog_name>.<schema_name>.<model_name>, corresponding to
# the catalog, schema, and registered model name
# in Unity Catalog under which to create the version
# The registered model will be created if it doesn't already exist,
# and the model version will contain all parameters and metrics
# logged with the corresponding MLflow Logged Model.
logged_model = mlflow.last_logged_model()
mlflow.register_model(logged_model.model_uri, "prod.ml_team.iris_model")
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
# Train a sklearn model on the iris dataset
X, y = datasets.load_iris(return_X_y=True, as_frame=True)
clf = RandomForestClassifier(max_depth=7)
clf.fit(X, y)
# Note that the UC model name follows the pattern
# <catalog_name>.<schema_name>.<model_name>, corresponding to
# the catalog, schema, and registered model name
# in Unity Catalog under which to create the version
# The registered model will be created if it doesn't already exist
autolog_run = mlflow.last_active_run()
model_uri = "runs:/{}/model".format(autolog_run.info.run_id)
mlflow.register_model(model_uri, "prod.ml_team.iris_model")
API を使用してモデルを登録する
- MLflow 3
- MLflow 2.x
mlflow.register_model(
"models:/<model_id>", "prod.ml_team.iris_model"
)
mlflow.register_model(
"runs:/<run_id>/model", "prod.ml_team.iris_model"
)
自動的に推論されたシグネチャを使用してモデルを Unity Catalog に登録する
自動的に推論されたシグネチャのサポートは、MLflowバージョン2.5.0以降で使用でき、 Databricks Runtime 11.3 LTS ML以降でサポートされています。自動的に推論されたシグネチャを使用するには、以下のコードを使用して、最新のMLflow Pythonクライアントをノートブックにインストールします。
%pip install --upgrade "mlflow-skinny[databricks]"
dbutils.library.restartPython()
次のコードは、自動的に推論される署名の例を示しています。log_model() 呼び出しで registered_model_name を使用してモデルを Unity Catalogに登録するため、モデルの 3 レベルの完全な名前を <catalog>.<schema>.<model>の形式で指定する必要があることに注意してください。
- MLflow 3
- MLflow 2.x
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
with mlflow.start_run():
# Train a sklearn model on the iris dataset
X, y = datasets.load_iris(return_X_y=True, as_frame=True)
clf = RandomForestClassifier(max_depth=7)
clf.fit(X, y)
# Take the first row of the training dataset as the model input example.
input_example = X.iloc[[0]]
# Log the model and register it as a new version in UC.
mlflow.sklearn.log_model(
sk_model=clf,
name="model",
# The signature is automatically inferred from the input example and its predicted output.
input_example=input_example,
# Use three-level name to register model in Unity Catalog.
registered_model_name="prod.ml_team.iris_model",
)
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
with mlflow.start_run():
# Train a sklearn model on the iris dataset
X, y = datasets.load_iris(return_X_y=True, as_frame=True)
clf = RandomForestClassifier(max_depth=7)
clf.fit(X, y)
# Take the first row of the training dataset as the model input example.
input_example = X.iloc[[0]]
# Log the model and register it as a new version in UC.
mlflow.sklearn.log_model(
sk_model=clf,
artifact_path="model",
# The signature is automatically inferred from the input example and its predicted output.
input_example=input_example,
# Use three-level name to register model in Unity Catalog.
registered_model_name="prod.ml_team.iris_model",
)
UI を使用してモデルを登録する
以下の手順に従います。
-
エクスペリメント 実行ページで、UI の右上隅にある モデルを登録する をクリックします。
-
ダイアログで Unity Catalog を選択し、ドロップダウン リストから宛先モデルを選択します。
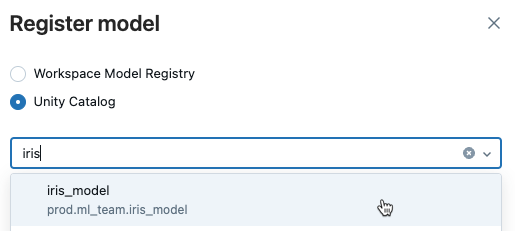
-
登録 をクリックします。
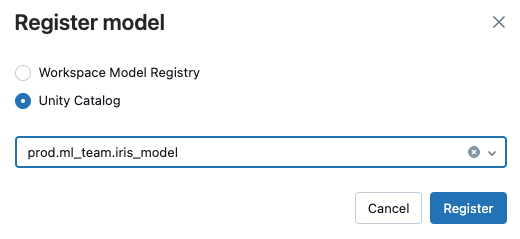
モデルの登録には時間がかかる場合があります。 進行状況を監視するには、Unity Catalog で目的地のモデルに移動し、定期的に更新します。
既存のモデル バージョンの署名を追加または更新する
シグネチャを持たないモデルバージョンには、次の制限があります。
- シグネチャが指定されている場合、モデル入力は推論時にチェックされ、入力がシグネチャと一致しない場合はエラーが報告されます。署名がなければ、自動入力の強制はなく、モデルは予期しない入力を処理できる必要があります。
- AI 関数でモデル バージョンを使用するには、関数呼び出しでスキーマを指定する必要があります。
- モデル サービング でモデルバージョンを使用しても、入力例は自動生成されません。
モデル バージョン シグネチャを追加または更新するには、 MLflow のドキュメントを参照してください。
モデル エイリアスを使用する
モデル エイリアスを使用すると、登録されたモデルの特定のバージョンに変更可能な名前付き参照を割り当てることができます。 エイリアスを使用して、モデルバージョンのデプロイメントステータスを示すことができます。 たとえば、現在本番運用中のモデルバージョンに「Champion」エイリアスを割り当て、本番運用モデルを使用するワークロードでこのエイリアスをターゲットにすることができます。 その後、「Champion」エイリアスを別のモデルバージョンに再割り当てすることで、本番運用モデルを更新できます。
モデルのエイリアスを設定して削除する
必要な権限 :登録されたモデルの所有者である必要があり、そのモデルを含むスキーマとカタログに対するUSE SCHEMA権限とUSE CATALOG権限が必要です。
カタログエクスプローラ を使用して、Unity Catalog のモデルのエイリアスを設定、更新、削除できます。「UI でのモデルの表示と管理」を参照してください。
MLflow クライアント API を使用してエイリアスを設定、更新、削除するには、次の例を参照してください。
from mlflow import MlflowClient
client = MlflowClient()
# create "Champion" alias for version 1 of model "prod.ml_team.iris_model"
client.set_registered_model_alias("prod.ml_team.iris_model", "Champion", 1)
# reassign the "Champion" alias to version 2
client.set_registered_model_alias("prod.ml_team.iris_model", "Champion", 2)
# get a model version by alias
client.get_model_version_by_alias("prod.ml_team.iris_model", "Champion")
# delete the alias
client.delete_registered_model_alias("prod.ml_team.iris_model", "Champion")
エイリアス クライアント APIの詳細については、 MLflow API のドキュメントを参照してください。
推論ワークロードのエイリアスによるモデルバージョンのロード
必要な権限 : 登録されたモデルに対する EXECUTE 権限に加えて、モデルを含むスキーマとカタログに対する USE SCHEMA 権限と USE CATALOG 権限。
バッチ推論ワークロードは、エイリアスでモデル バージョンを参照できます。 以下のスニペットは、バッチ推論の "Champion" モデル バージョンを読み込んで適用します。 "Champion" バージョンが新しいモデル バージョンを参照するように更新された場合、バッチ推論ワークロードは次回の実行時に自動的にそれを取得します。 これにより、モデルのデプロイをバッチ推論ワークロードから切り離すことができます。
import mlflow.pyfunc
model_version_uri = "models:/prod.ml_team.iris_model@Champion"
champion_version = mlflow.pyfunc.load_model(model_version_uri)
champion_version.predict(test_x)
モデルサービングエンドポイントは、エイリアスでモデルバージョンを参照することもできます。 デプロイ ワークフローを記述して、エイリアスごとにモデルバージョンを取得し、モデルサービング エンドポイントを更新してそのバージョンを提供するようにするには、 モデルサービングREST APIを使用します。 例えば:
import mlflow
import requests
client = mlflow.tracking.MlflowClient()
champion_version = client.get_model_version_by_alias("prod.ml_team.iris_model", "Champion")
# Invoke the model serving REST API to update endpoint to serve the current "Champion" version
model_name = champion_version.name
model_version = champion_version.version
requests.request(...)
推論ワークロードのバージョン番号によるモデルバージョンの読み込み
バージョン番号を指定してモデルのバージョンを読み込むこともできます。
import mlflow.pyfunc
# Load version 1 of the model "prod.ml_team.iris_model"
model_version_uri = "models:/prod.ml_team.iris_model/1"
first_version = mlflow.pyfunc.load_model(model_version_uri)
first_version.predict(test_x)
ワークスペース間でモデルを共有する
同じ地域のユーザーとモデルを共有する
適切な特権がある限り、モデルを含むメタストアにアタッチされている任意のワークスペースから Unity Catalog のモデルにアクセスできます。 たとえば、開発ワークスペースの prod カタログからモデルにアクセスして、新しく開発されたモデルを本番運用ベースラインと簡単に比較できます。
作成した登録済みモデルで他のユーザーと共同作業する (書き込み権限を共有する) には、自分自身と共同作業するユーザーを含むグループにモデルの所有権を付与する必要があります。コラボレーターは、モデルを含むカタログとスキーマに対する USE CATALOG 権限と USE SCHEMA 権限も持っている必要があります。詳細については、「 Unity Catalog の特権とセキュリティ保護可能なオブジェクト 」を参照してください。
別の地域やアカウントのユーザーとモデルを共有する
他の地域のユーザーやアカウントとモデルを共有するには、Delta Sharing Databricks-to-Databricks共有フローを使用します。「共有にモデルを追加する」 (プロバイダーの場合) および「Databricks-to-Databricksモデルでアクセスを取得する (受信者の場合)」を参照してください。受信者は、共有からカタログを作成した後、その共有カタログ内のモデルに Unity Catalog の他のモデルと同じ方法でアクセスします。
Unity Catalogでモデルのデータリネージを追跡する
Unity Catalogでのテーブルからモデルへのリネージのサポートは、MLflow 2.11.0以降で利用可能です。
Unity Catalogのテーブルでモデルをトレーニングすると、モデルのリネージを、トレーニングおよび評価されたアップストリームデータセットまで追跡できます。これを行うには、 mlflow.log_input を使用します。 これにより、モデルを生成した MLflow の実行と共に入力テーブル情報が保存されます。 データリネージは、Feature Store APIを使用してログに記録されたモデルについても自動的にキャプチャされます。 特徴量のガバナンスとリネージを参照してください。
モデルを Unity Catalogに登録すると、リネージ情報が自動的に保存され、カタログエクスプローラのモデルバージョンページの リネージ タブに表示されます。 モデルバージョン情報の表示およびモデルリネージを参照してください。
次のコードは例を示しています。
- MLflow 3
- MLflow 2.x
import mlflow
import pandas as pd
import pyspark.pandas as ps
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestRegressor
# Write a table to Unity Catalog
iris = load_iris()
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_df.rename(
columns = {
'sepal length (cm)':'sepal_length',
'sepal width (cm)':'sepal_width',
'petal length (cm)':'petal_length',
'petal width (cm)':'petal_width'},
inplace = True
)
iris_df['species'] = iris.target
ps.from_pandas(iris_df).to_table("prod.ml_team.iris", mode="overwrite")
# Load a Unity Catalog table, train a model, and log the input table
dataset = mlflow.data.load_delta(table_name="prod.ml_team.iris", version="0")
pd_df = dataset.df.toPandas()
X = pd_df.drop("species", axis=1)
y = pd_df["species"]
with mlflow.start_run():
clf = RandomForestRegressor(n_estimators=100)
clf.fit(X, y)
mlflow.log_input(dataset, "training")
# Take the first row of the training dataset as the model input example.
input_example = X.iloc[[0]]
# Log the model and register it as a new version in UC.
mlflow.sklearn.log_model(
sk_model=clf,
name="model",
# The signature is automatically inferred from the input example and its predicted output.
input_example=input_example,
# Use three-level name to register model in Unity Catalog.
registered_model_name="prod.ml_team.iris_classifier",
)
import mlflow
import pandas as pd
import pyspark.pandas as ps
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestRegressor
# Write a table to Unity Catalog
iris = load_iris()
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_df.rename(
columns = {
'sepal length (cm)':'sepal_length',
'sepal width (cm)':'sepal_width',
'petal length (cm)':'petal_length',
'petal width (cm)':'petal_width'},
inplace = True
)
iris_df['species'] = iris.target
ps.from_pandas(iris_df).to_table("prod.ml_team.iris", mode="overwrite")
# Load a Unity Catalog table, train a model, and log the input table
dataset = mlflow.data.load_delta(table_name="prod.ml_team.iris", version="0")
pd_df = dataset.df.toPandas()
X = pd_df.drop("species", axis=1)
y = pd_df["species"]
with mlflow.start_run():
clf = RandomForestRegressor(n_estimators=100)
clf.fit(X, y)
mlflow.log_input(dataset, "training")
# Take the first row of the training dataset as the model input example.
input_example = X.iloc[[0]]
# Log the model and register it as a new version in UC.
mlflow.sklearn.log_model(
sk_model=clf,
artifact_path="model",
# The signature is automatically inferred from the input example and its predicted output.
input_example=input_example,
# Use three-level name to register model in Unity Catalog.
registered_model_name="prod.ml_team.iris_classifier",
)
モデルへのアクセスの制御
Unity Catalog では、登録されたモデルはセキュリティ保護可能な FUNCTION オブジェクトのサブタイプです。Unity Catalog に登録されているモデルへのアクセスを許可するには、 GRANT ON FUNCTION.カタログ エクスプローラを使用して、モデルの所有権と権限を設定することもできます。詳細については、「 Unity Catalog での特権の管理 」および 「Unity Catalog オブジェクト モデル」を参照してください。
モデルの権限は、 Grants REST API を使用してプログラムで構成できます。 モデルのアクセス許可を構成するときは、REST API 要求で securable_type を "FUNCTION" に設定します。 たとえば、 PATCH /api/2.1/unity-catalog/permissions/function/{full_name} を使用して、登録済みモデルのアクセス許可を更新します。
UIでのモデルの表示と管理
必要な権限 :登録されたモデルとそのモデルのバージョンをUIで表示するには、登録されたモデルに対するEXECUTE権限と、そのモデルを含むスキーマとカタログに対するUSE SCHEMA権限とUSE CATALOG権限が必要です。
カタログエクスプローラ を使用して、Unity Catalog で登録済みのモデルとモデルバージョンを表示および管理できます。
モデル情報の表示
カタログエクスプローラでモデルを表示するには:
-
サイドバー
 カタログ をクリックします。
カタログ をクリックします。 -
右上のドロップダウンリストからコンピュートリソースを選択します。
-
左側のカタログエクスプローラーツリーで、カタログを開き、スキーマを選択します。
-
スキーマにモデルが含まれている場合は、次に示すように、ツリーの [モデル ] の下に表示されます。
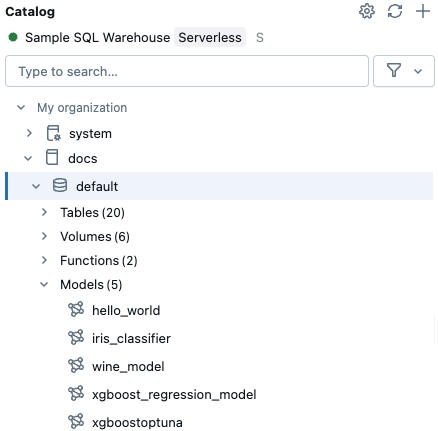
-
モデルをクリックすると、詳細情報が表示されます。モデルの詳細ページには、モデル バージョンの一覧と追加情報が表示されます。
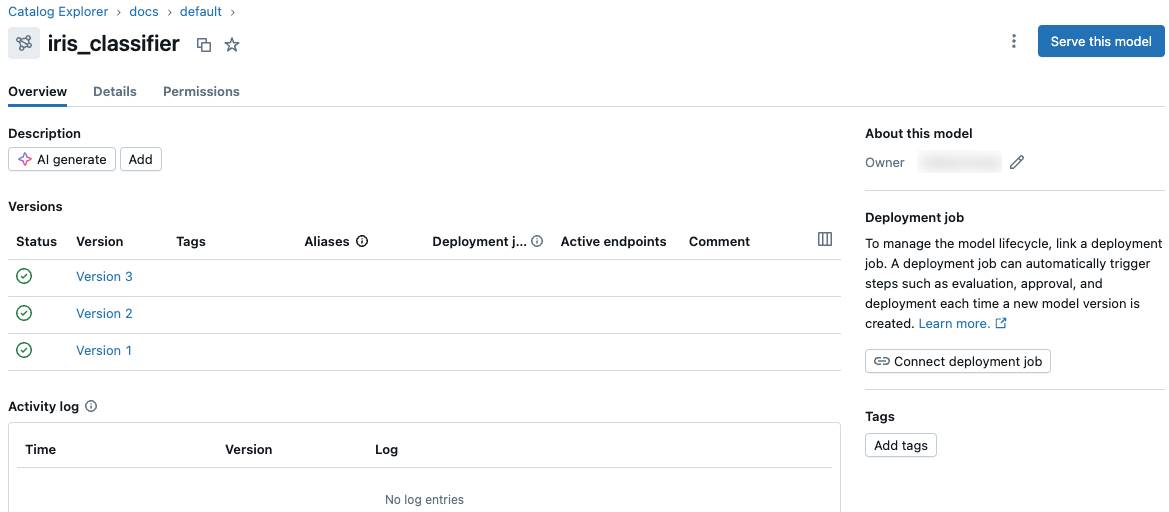
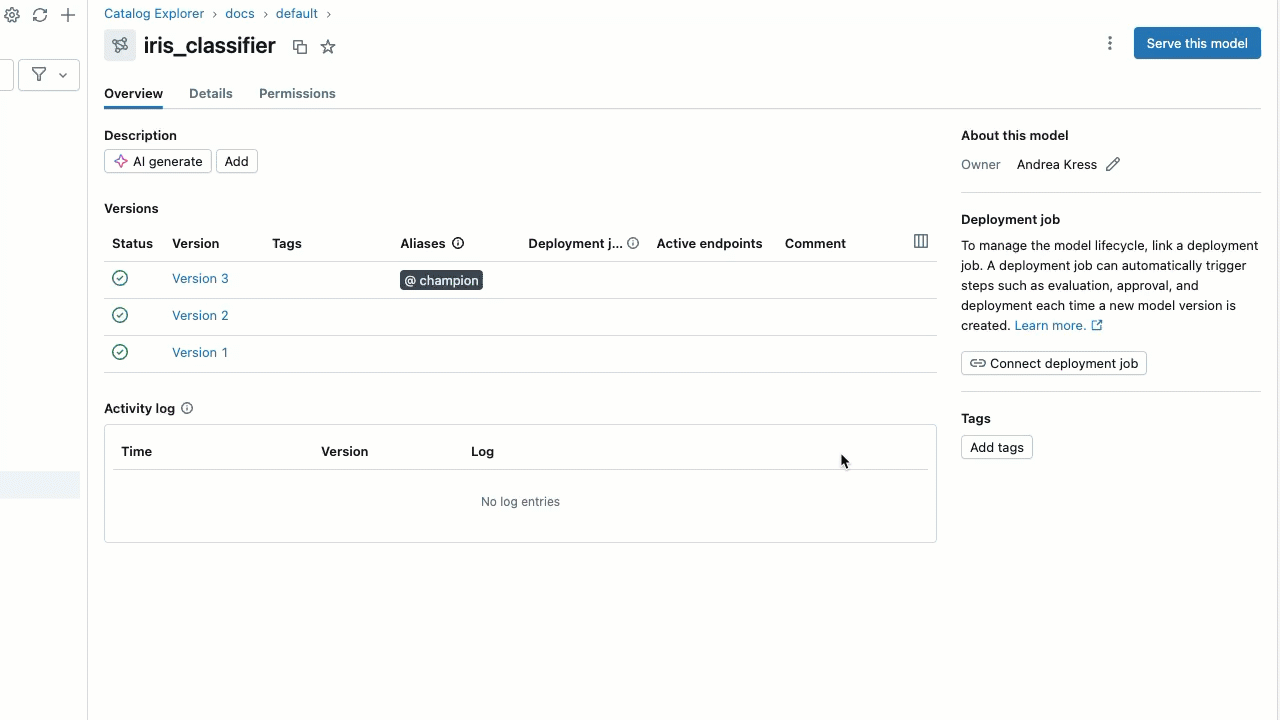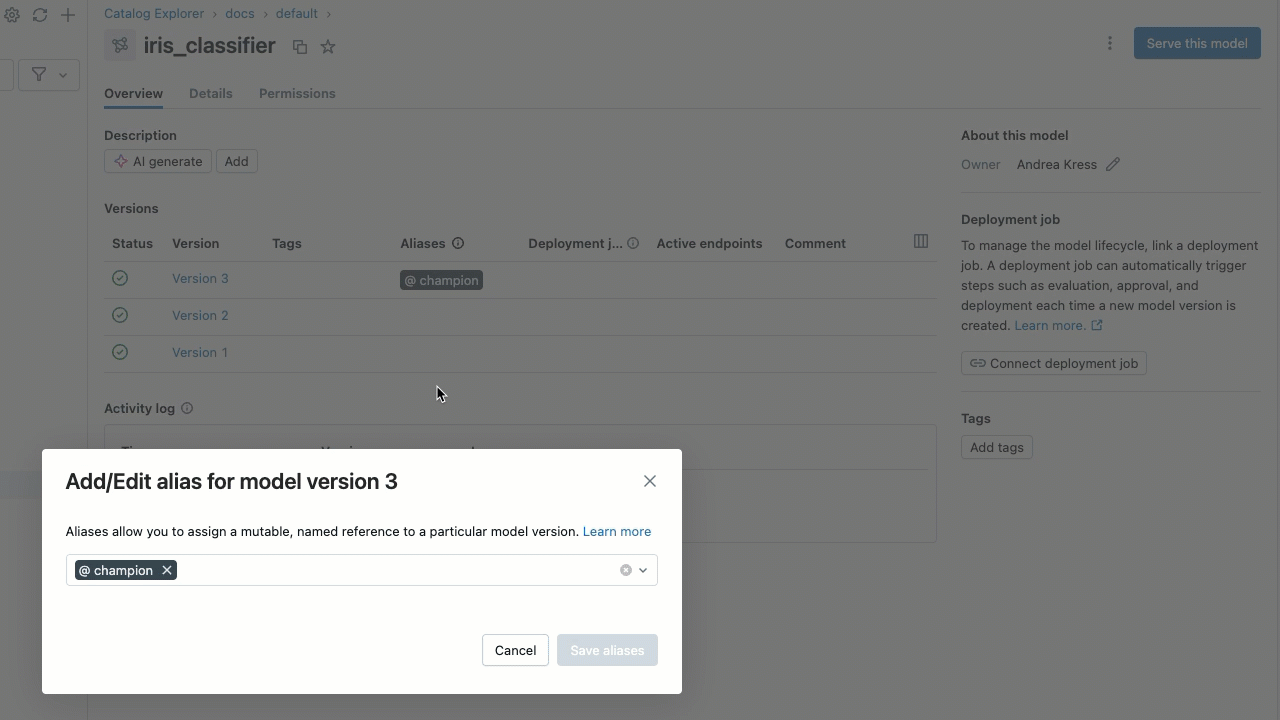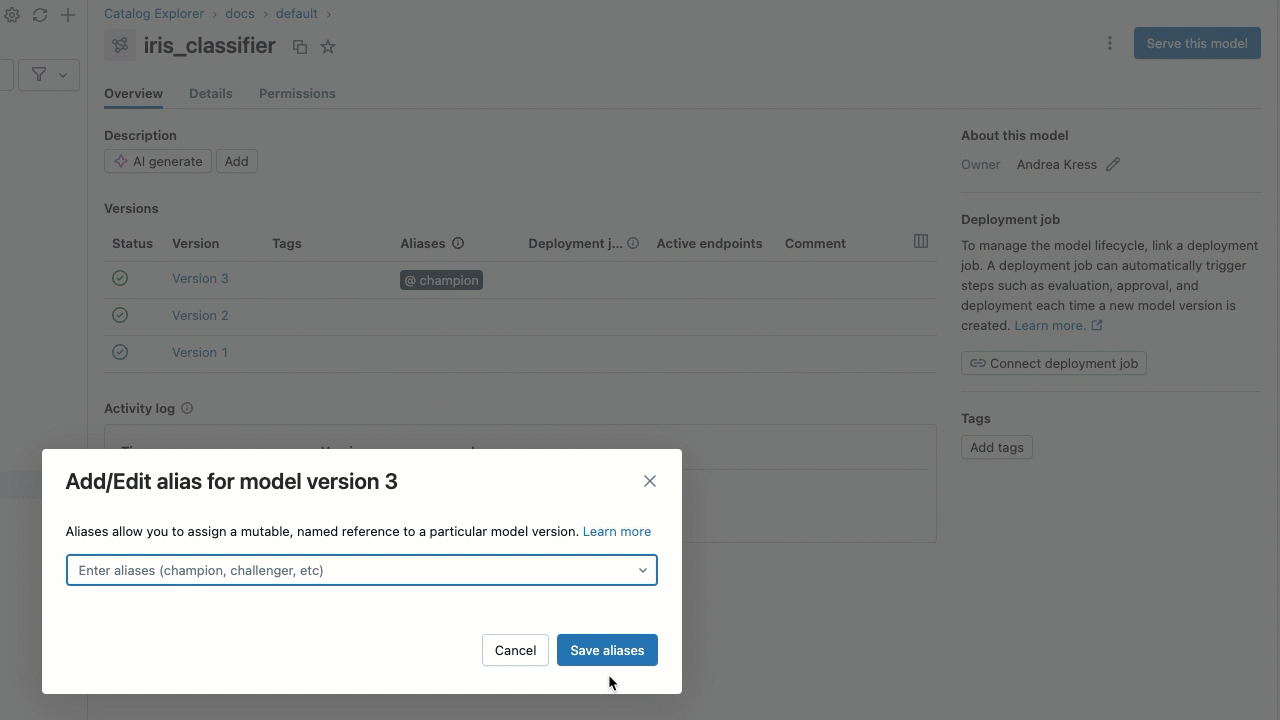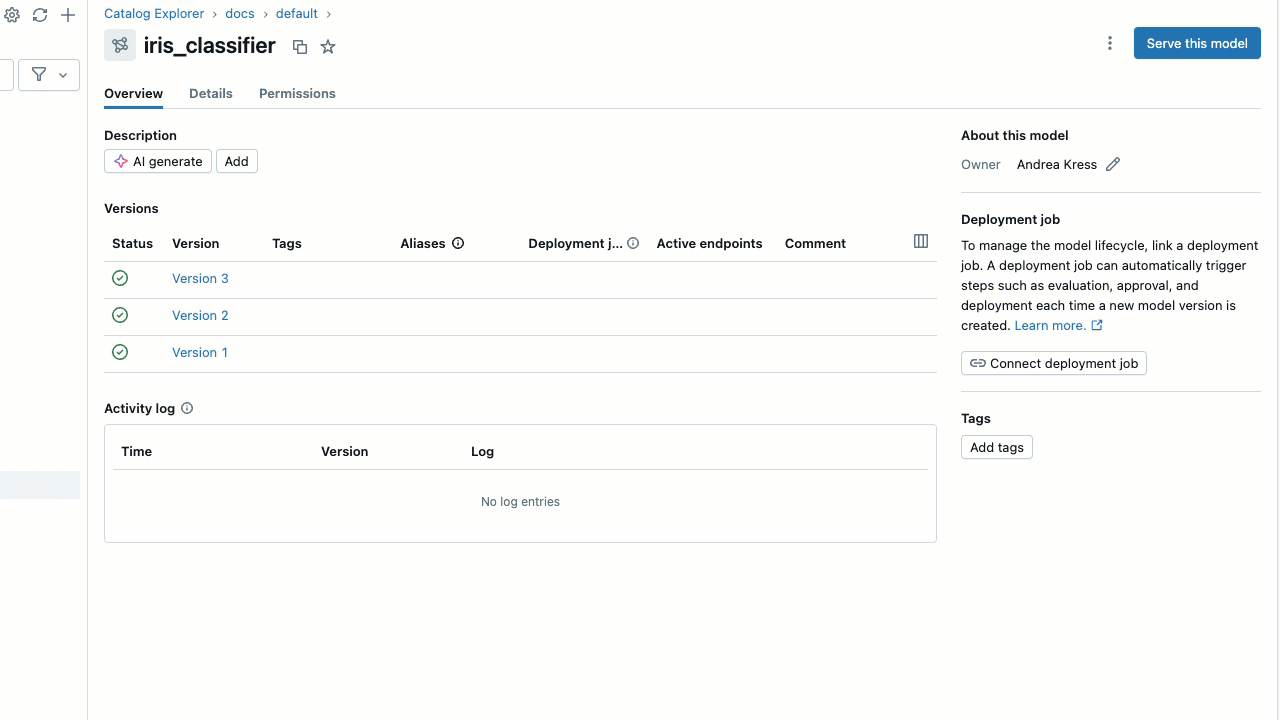
モデル エイリアスの設定
UI を使用してモデル エイリアスを設定するには:
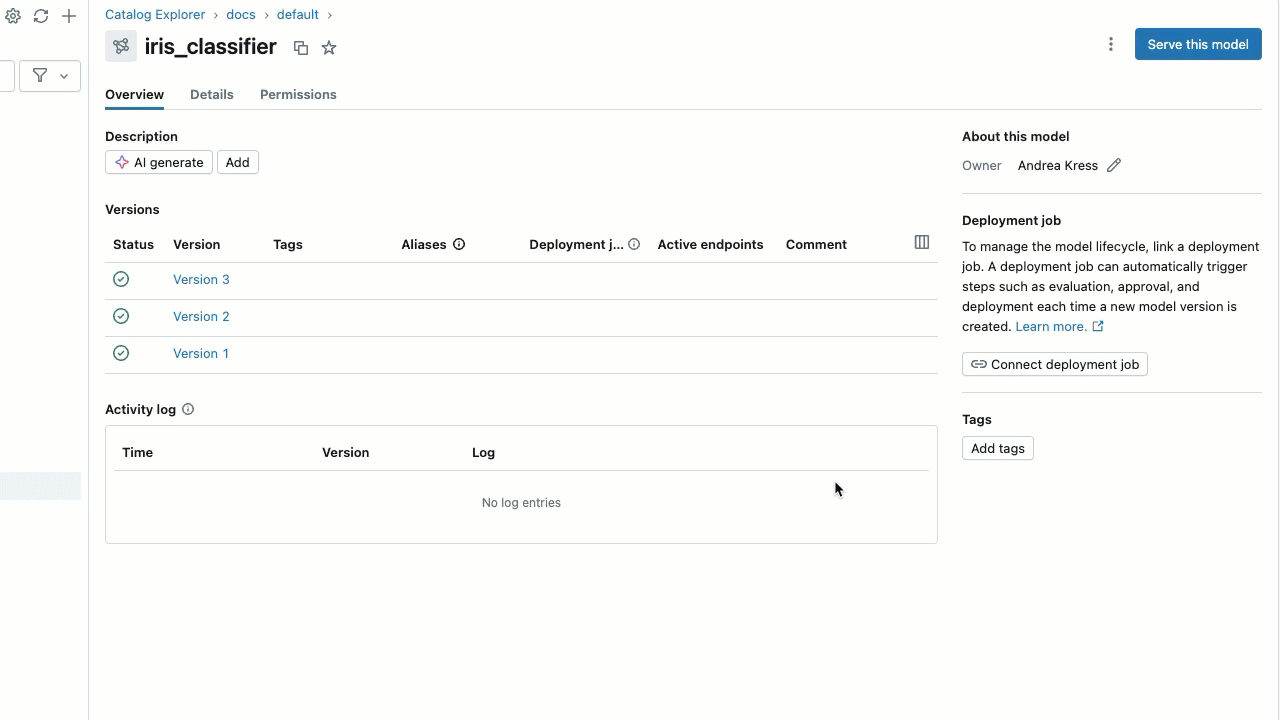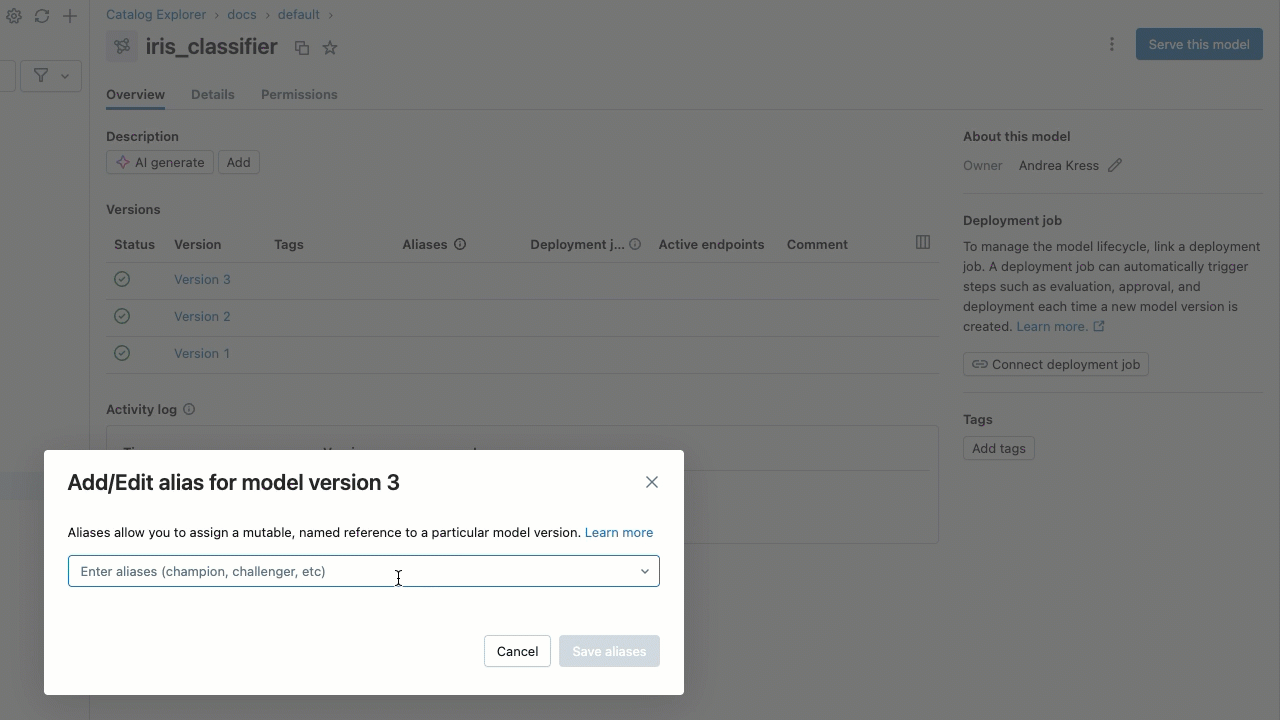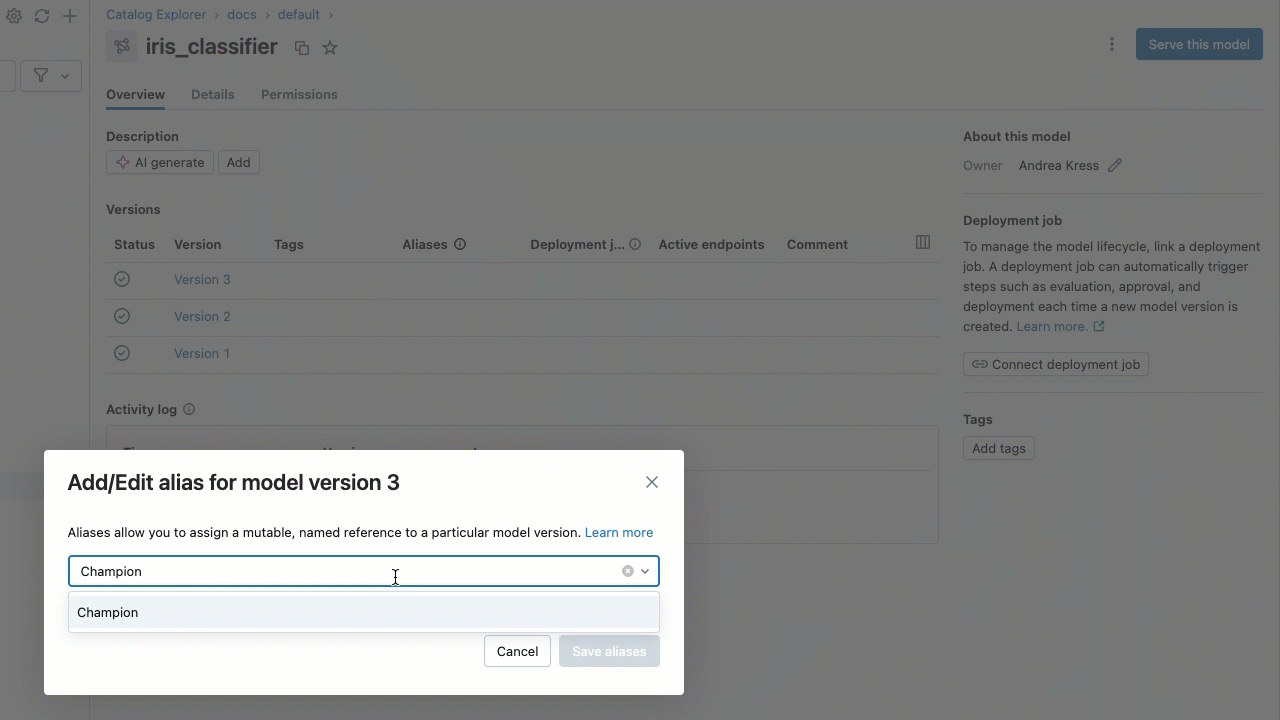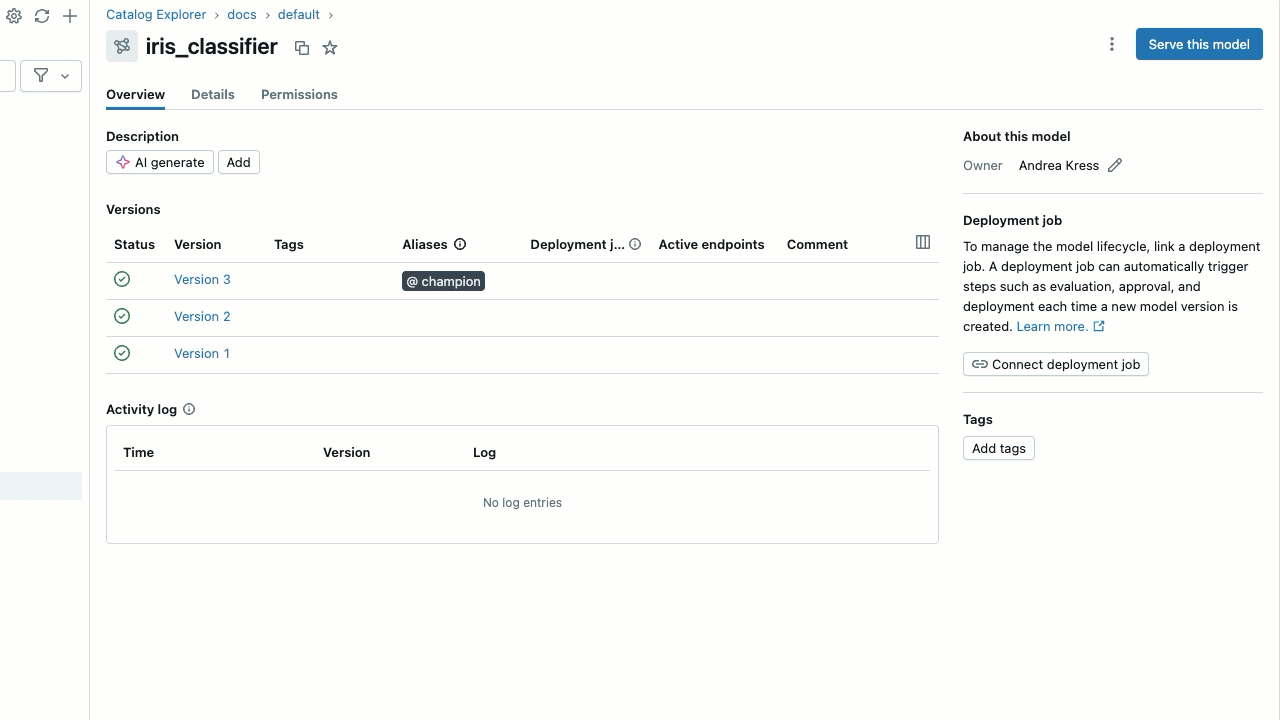
- モデルの詳細ページで、エイリアスを追加するモデル バージョンの行にカーソルを合わせます。 [エイリアスの追加 ] ボタンが表示されます。
- [ エイリアスを追加 ] をクリックします。
- エイリアスを入力するか、ドロップダウンメニューからエイリアスを選択します。ダイアログには複数のエイリアスを追加できます。
- [ エイリアスの保存 ] をクリックします。
エイリアスを削除するには:
- モデル バージョンの行にカーソルを合わせ、エイリアスの横にある鉛筆アイコンをクリックします。
- ダイアログで、削除するエイリアスの横にある
Xをクリックします。 - [ エイリアスの保存 ] をクリックします。
モデルバージョン情報とモデルリネージの参照
モデルバージョンに関する詳細情報を表示するには、モデルのリストでその名前をクリックします。 モデルバージョンページが表示されます。このページには、バージョンを作成した MLflow ソース実行へのリンクが含まれています。MLflow 3 では、対応する MLflow 記録済みモデルで記録されたすべてのパラメーターとメトリクスを表示することもできます。
- MLflow 3
- MLflow 2.x
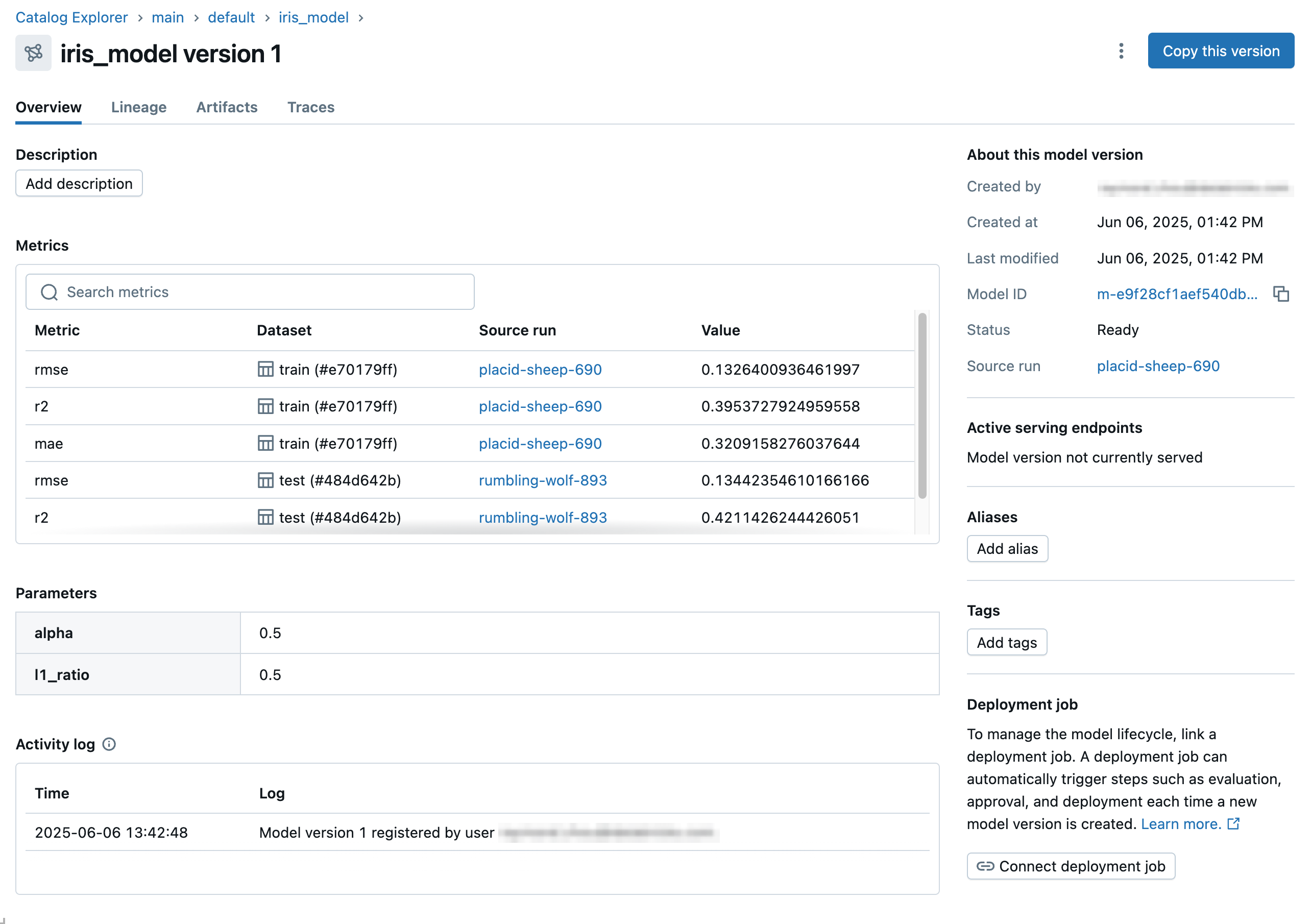
このページから、モデルのリネージを次のように表示できます。
-
依存関係 タブを選択します。左側のサイドバーには、モデルとともにログに記録されたコンポーネントが表示されます。
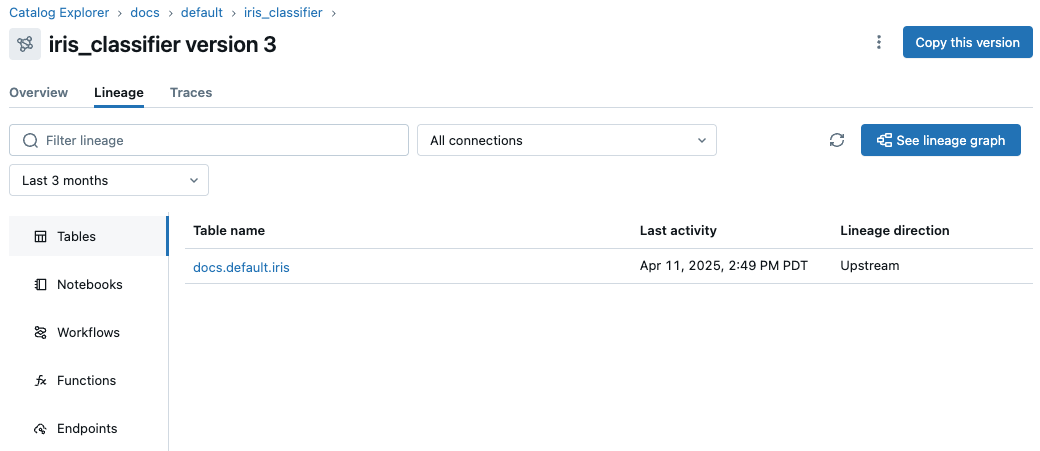
-
リネージグラフを見る をクリックします。リネージグラフが表示されます。 リネージグラフの探索の詳細については、 リネージのキャプチャと探索を参照してください。

-
リネージグラフを閉じるには、右上隅の
 をクリックします。
をクリックします。
モデルの名前を変更する
権限が必要 :登録されたモデルの所有者である必要があり、登録されたモデルを含むスキーマのCREATE MODEL権限、モデルを含むスキーマとカタログのUSE SCHEMA権限とUSE CATALOG権限が必要です。
登録済みモデルの名前を変更するには、MLflow クライアント API rename_registered_model() メソッドを使用します ( <full-model-name> はモデルの完全な 3 レベル名、 <new-model-name> はカタログまたはスキーマを含まないモデル名です)。
client=MlflowClient()
client.rename_registered_model("<full-model-name>", "<new-model-name>")
たとえば、次のコードでは、モデル hello_world の名前を helloに変更します。
client=MlflowClient()
client.rename_registered_model("docs.models.hello_world", "hello")
モデル バージョンのコピー
Unity Catalog では、モデルバージョンを 1 つのモデルから別のモデルにコピーできます。
UI を使用したモデルバージョンのコピー
以下の手順に従います。
-
モデルのバージョンページで、UI の右上隅にある このバージョンをコピー をクリックします。
-
ドロップダウンリストから目的のモデルを選択し、 コピーをクリックします 。
![[モデルバージョンのコピー]ダイアログ](/aws/ja/assets/images/uc-copy-model-dialog-6ae0befbf4db7d7802b214a9a68fbd8f.png)
モデルのコピーには時間がかかる場合があります。 進行状況を監視するには、Unity Catalog で目的地のモデルに移動し、定期的に更新します。
API を使用したモデルバージョンのコピー
モデル バージョンをコピーするには、MLflow の copy_model_version() Python API を使用します。
client = MlflowClient()
client.copy_model_version(
"models:/<source-model-name>/<source-model-version>",
"<destination-model-name>",
)
モデルまたはモデルバージョンを削除する
必要な権限 :登録されたモデルの所有者である必要があり、そのモデルを含むスキーマとカタログに対するUSE SCHEMA権限とUSE CATALOG権限が必要です。
UI または API を使用して、登録済みモデルまたは登録済みモデル内のモデル バージョンを削除できます。
この操作は元に戻せません。モデルを削除すると、Unity Catalogによって保存されたすべてのモデルアーティファクトと、登録されたモデルに関連付けられているすべてのメタデータが削除されます。
UI を使用したモデルのバージョンまたはモデルの削除
Unity Catalog でモデルまたはモデル バージョンを削除するには、次の手順に従います。
-
カタログ エクスプローラーのモデル ページまたはモデル バージョン ページで、右上隅にあるケバブ メニュー
 をクリックします。
をクリックします。モデルページから:
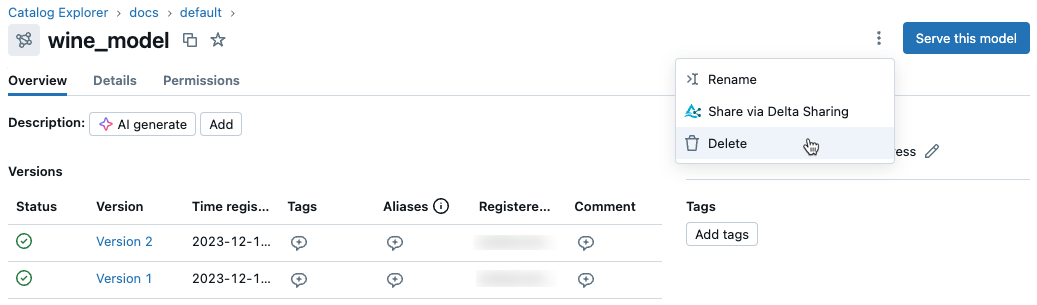
モデルバージョンページから:
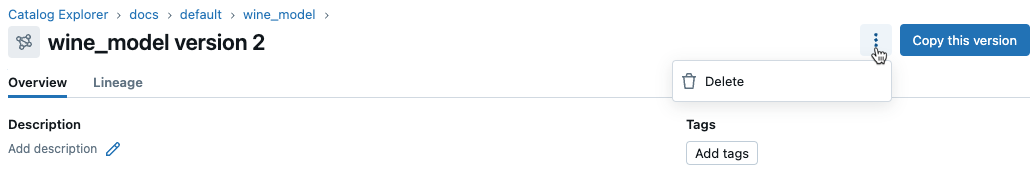
-
削除 を選択します。
-
確認ダイアログが表示されます。 削除 をクリックして確定します。
API を使用してモデルのバージョンまたはモデルを削除する
モデルバージョンを削除するには、MLflowクライアントAPIのdelete_model_version()メソッドを使用します。
# Delete versions 1,2, and 3 of the model
client = MlflowClient()
versions=[1, 2, 3]
for version in versions:
client.delete_model_version(name="<model-name>", version=version)
モデルを削除するには、MLflowクライアントAPIのdelete_registered_model()メソッドを使用します。
client = MlflowClient()
client.delete_registered_model(name="<model-name>")
モデルでのタグの使用
タグ は、登録済みモデルとモデルバージョンに関連付けるキーと値のペアであり、機能やステータスごとにラベルを付けて分類できます。 たとえば、質問応答タスク用の登録済みモデルに、キー "task" と値 "question-answering" (UI では task:question-answeringと表示) のタグを適用できます。 モデルバージョンレベルでは、デプロイ前の検証を受けているバージョンに validation_status:pending タグを付け、デプロイがクリアされたバージョンには validation_status:approvedタグを付けることができます。
必要な権限 : 登録されたモデルの所有者または APPLY TAG 権限に加えて、モデルを含むスキーマとカタログに対する USE SCHEMA 権限と USE CATALOG 権限があります。
UI を使用してタグを設定および削除する方法については、「Unity Catalog のセキュリティ保護可能なオブジェクトにタグを適用する」を参照してください。
MLflow クライアント API を使用してタグを設定および削除するには、次の例を参照してください。
from mlflow import MlflowClient
client = MlflowClient()
# Set registered model tag
client.set_registered_model_tag("prod.ml_team.iris_model", "task", "classification")
# Delete registered model tag
client.delete_registered_model_tag("prod.ml_team.iris_model", "task")
# Set model version tag
client.set_model_version_tag("prod.ml_team.iris_model", "1", "validation_status", "approved")
# Delete model version tag
client.delete_model_version_tag("prod.ml_team.iris_model", "1", "validation_status")
登録済みのモデルとモデルバージョンタグの両方が 、プラットフォーム全体の制約を満たす必要があります。
タグクライアント APIについて詳しくは、 MLflow API のドキュメントを参照してください。
モデルまたはモデル バージョンに説明(コメント)を追加する
必要な権限 :登録されたモデルの所有者である必要があり、そのモデルを含むスキーマとカタログに対するUSE SCHEMA権限とUSE CATALOG権限が必要です。
Unity Catalog には、任意のモデルまたはモデル バージョンのテキスト説明を含めることができます。 たとえば、問題の概要や、使用された方法論やアルゴリズムに関する情報を提供できます。
モデルの場合、AI が生成したコメントを使用するオプションもあります。 AI で生成されたコメントを Unity Catalog オブジェクトに追加するを参照してください。
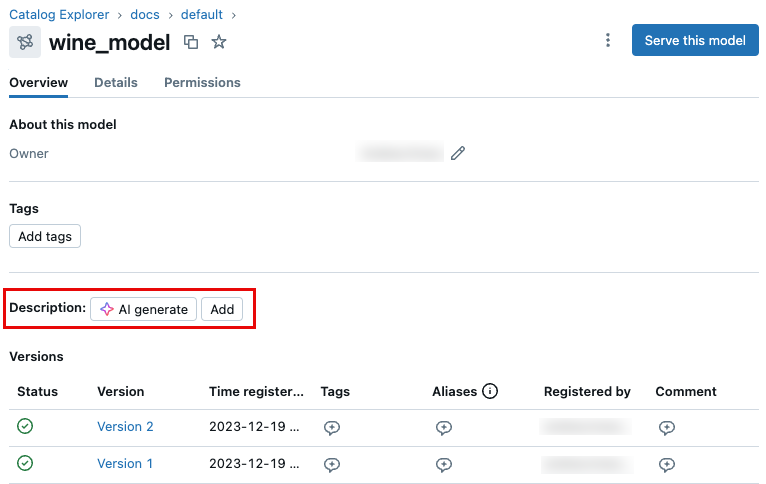
UI を使用してモデルに説明を追加する
モデルの説明を追加するには、AI が生成したコメントを使用するか、独自のコメントを入力できます。 必要に応じて、AIが生成したコメントを編集できます。
- 自動生成されたコメントを追加するには、 AI生成 ボタンをクリックします。
- 独自のコメントを追加するには、 追加 をクリックします。 ダイアログにコメントを入力し、 保存 をクリックします。
UI を使用したモデルバージョンへの説明の追加
Unity Catalog のモデル バージョンに説明を追加するには、次の手順に従います。
-
モデル バージョン ページで、 説明 の下にある鉛筆アイコンをクリックします。
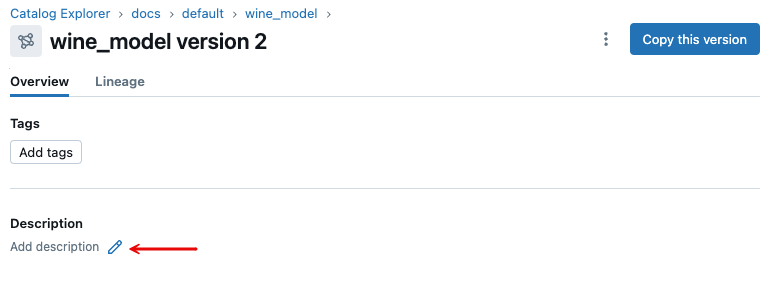
-
ダイアログにコメントを入力し、 保存 をクリックします。
API を使用してモデルまたはモデル バージョンに説明を追加する
登録されたモデルの説明を更新するには、MLflowクライアントAPIのupdate_registered_model()メソッドを使用します。
client = MlflowClient()
client.update_registered_model(
name="<model-name>",
description="<description>"
)
モデルバージョンの説明を更新するには、MLflowクライアントAPIのupdate_model_version()メソッドを使用します。
client = MlflowClient()
client.update_model_version(
name="<model-name>",
version=<model-version>,
description="<description>"
)
検索モデルの一覧と検索
Unity Catalog に登録されているモデルの一覧を取得するには、MLflow の search_registered_models() Python API を使用します。
mlflow.search_registered_models()
特定のモデル名を検索し、そのモデルのバージョンに関する情報を取得するには、次の search_model_versions()を使用します。
from pprint import pprint
[pprint(mv) for mv in mlflow.search_model_versions("name='<model-name>'")]
Unity Catalog のモデルでは、すべての検索 API フィールドと演算子がサポートされているわけではありません。 詳細については、 制限事項 を参照してください。
モデルファイルのダウンロード(高度なユースケース)
ほとんどの場合、モデルを読み込むには、mlflow.pyfunc.load_model や mlflow.<flavor>.load_model などの MLflow API使用する必要があります (たとえば、HuggingFace モデルの場合は mlflow.transformers.load_model)。
場合によっては、モデルの動作やモデルの読み込みの問題をデバッグするために、モデルファイルをダウンロードする必要があります。 モデルファイルは、次のように mlflow.artifacts.download_artifactsを使用してダウンロードできます。
import mlflow
mlflow.set_registry_uri("databricks-uc")
model_uri = f"models:/{model_name}/{version}" # reference model by version or alias
destination_path = "/local_disk0/model"
mlflow.artifacts.download_artifacts(artifact_uri=model_uri, dst_path=destination_path)
環境間でモデルを昇格させる
Databricks では、ML パイプラインをコードとしてデプロイすることをお勧めします。 これにより、すべての本番運用モデルは、本番運用環境内の自動トレーニング ワークフローを通じて作成できるため、環境間でモデルを昇格する必要がなくなります。
ただし、場合によっては、環境間でモデルを再トレーニングするにはコストがかかりすぎることがあります。 代わりに、Unity Catalog に登録されているモデル間でモデルバージョンをコピーして、環境間でモデルバージョンを昇格させることができます。
以下のサンプルコードを実行するには、次の権限が必要です。
USE CATALOGstagingカタログとprodカタログに掲載されています。USE SCHEMAstaging.ml_teamとprod.ml_teamのスキーマで。EXECUTEstaging.ml_team.fraud_detectionに。
また、登録したモデル prod.ml_team.fraud_detectionの所有者である必要があります。
次のコード スニペットでは、MLflow バージョン 2.8.0 以降で使用できる copy_model_version MLflow クライアント API を使用しています。
import mlflow
mlflow.set_registry_uri("databricks-uc")
client = mlflow.tracking.MlflowClient()
src_model_name = "staging.ml_team.fraud_detection"
src_model_version = "1"
src_model_uri = f"models:/{src_model_name}/{src_model_version}"
dst_model_name = "prod.ml_team.fraud_detection"
copied_model_version = client.copy_model_version(src_model_uri, dst_model_name)
モデル・バージョンが本番運用環境に入ったら、必要なデプロイメント前の検証を実行できます。 その後、 エイリアスを使用してデプロイ用のモデルバージョンをマークできます。
client = mlflow.tracking.MlflowClient()
client.set_registered_model_alias(name="prod.ml_team.fraud_detection", alias="Champion", version=copied_model_version.version)
上記の例では、 staging.ml_team.fraud_detection 登録済みモデルから読み取り、 prod.ml_team.fraud_detection 登録済みモデルに書き込みができるユーザーのみが、ステージングモデルを本番運用環境に昇格できます。 同じユーザーがエイリアスを使用して、本番運用環境内にデプロイされるモデルバージョンを管理することもできます。 モデルの昇格とデプロイを制御するために、他のルールやポリシーを構成する必要はありません。
このフローをカスタマイズして、セットアップに一致する複数の環境( 、 dev、 qa、 prodなど)にモデルバージョンを昇格させることができます。 アクセス制御は、各環境の設定に従って適用されます。
ノートブックの例
このノートブックの例は、 Unity Catalog APIの Models を使用して Unity Catalogのモデルを管理する方法を示しています (登録する モデルとモデル バージョン、説明の追加、モデルの読み込みとデプロイ、モデル エイリアスの使用、モデルとモデル バージョンの削除など)。
- MLflow 3
- MLflow 2.x
MLflow 3 の Unity Catalog サンプル ノートブックのモデル
Unity Catalog サンプルノートブックのモデル
制限
-
ステージは、Unity Catalog のモデルではサポートされていません。 Databricks では、Unity Catalog の 3 レベルの名前空間を使用してモデルが存在する環境を表現し、エイリアスを使用してモデルをデプロイに昇格させることをお勧めします。 詳細については、 環境間でのモデルの昇格 を参照してください。
-
Webhook は、Unity Catalog のモデルではサポートされていません。 アップグレードガイドで推奨される代替案を参照してください。
-
Unity Catalog のモデルでは、一部の検索 API フィールドと演算子がサポートされていません。これは、サポートされているフィルタを使用して検索 API を呼び出し、結果をスキャンすることで軽減できます。以下にいくつかの例を示します。
- search_model_versions または search_registered_models クライアント API では、
order_byパラメーターがサポートされていません。 search_model_versionsまたはsearch_registered_modelsでは、タグベースのフィルター(tags.mykey = 'myvalue')がサポートされていません。search_model_versionsまたはsearch_registered_modelsでは、完全等価以外の演算子(例:LIKE、ILIKE、!=)がサポートされていません。- 名前による登録済みモデルの検索(例:
search_registered_models(filter_string="name='main.default.mymodel'"))はサポートされていません。特定の登録済みモデルを名前で取得するには、get_registered_model を使用します。
- search_model_versions または search_registered_models クライアント API では、
-
Unity Catalog では、登録されているモデルおよびモデルバージョンに関する E メール通知とコメントディスカッションスレッドがサポートされていません。
-
アクティビティ ログは、Unity Catalog のモデルではサポートされていません。 Unity Catalog でモデルのアクティビティを追跡するには、 監査ログを使用します。
-
search_registered_modelsDelta Sharing を通じて共有されたモデルの古い結果が返される可能性があります。 最新の結果を得るには、Databricks CLI または SDK を使用して、スキーマ内のモデルを一覧表示します。