MLflow のランでトレーニング結果を表示する
この記事では、 MLflow ランを使用してモデル トレーニング エクスペリメントの結果を表示および分析する方法と、ランを管理および整理する方法について説明します。 MLflow エクスペリメントの詳細については、「MLflow エクスペリメントを使用してトレーニング ランを整理する」を参照してください。
MLflow のラン は、モデル コードの 1 回のランに対応します。 各ランには、ランを開始したノートブック、ランによって作成されたモデル、キーと値のペアとして保存されたモデル パラメーターとメトリクス、ランメタデータのタグ、ランによって作成されたアーティファクトまたは出力ファイルなどの情報が記録されます。
すべての MLflow ランは 、アクティブなエクスペリメントに記録されます。 エクスペリメントをアクティブ エクスペリメントとして明示的に設定していない場合、ランはノートブック エクスペリメントに記録されます。
ランの詳細を表示する
ランには、エクスペリメントの詳細ページからアクセスするか、ランを作成したノートブックから直接アクセスできます。
エクスペリメントの詳細ページで、ランテーブルのラン名をクリックします。
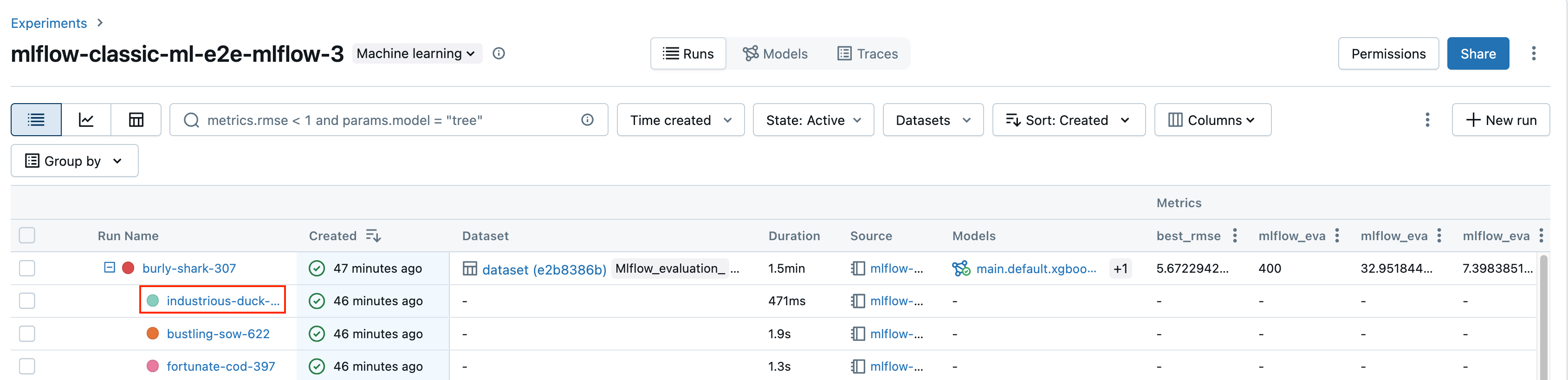
ノートブックから、エクスペリメント ラン サイドバーでラン名をクリックします。
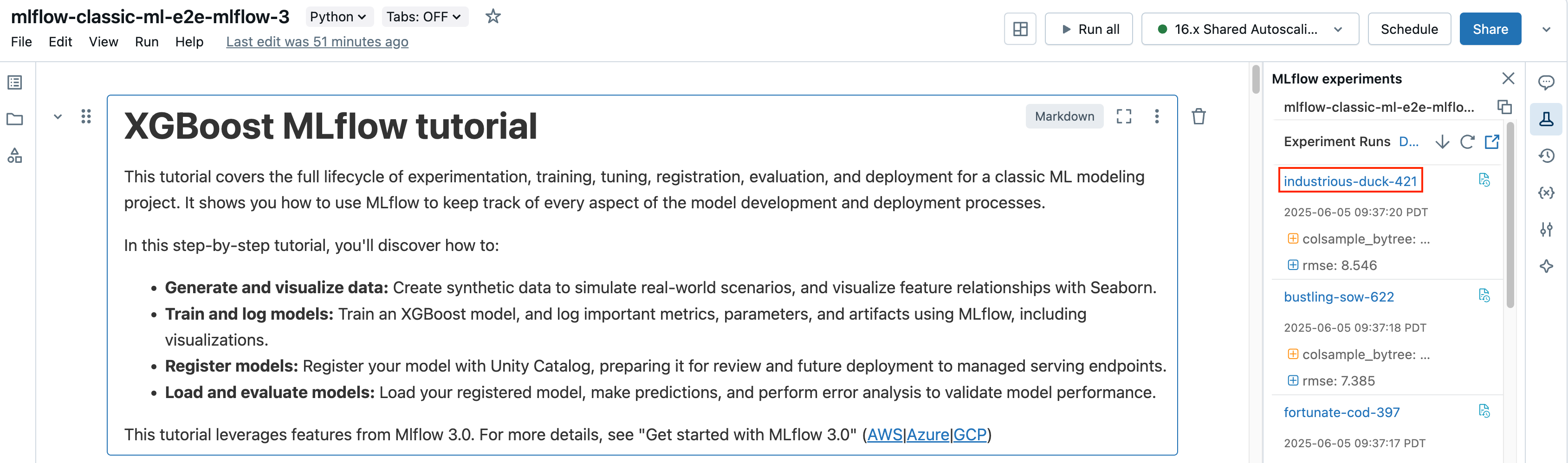
ラン画面には、ラン ID、ランに使用されたパラメーター、ランの結果として得られるメトリクス、およびソース ノートブックへのリンクを含むランの詳細が表示されます。ランから保存されたアーティファクトは、[ アーティファクト ] タブで使用できます。
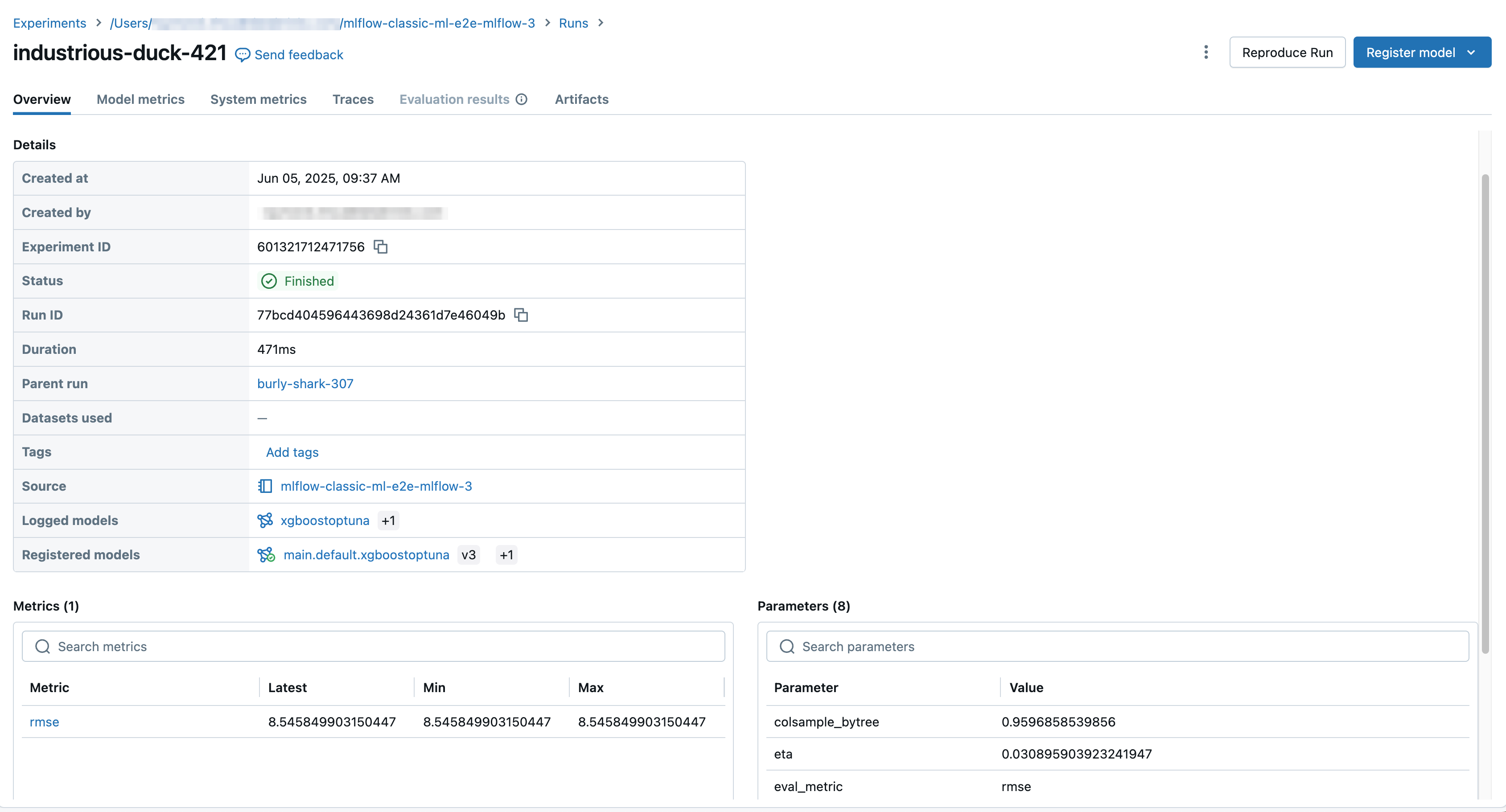
予測用のコードスニペット
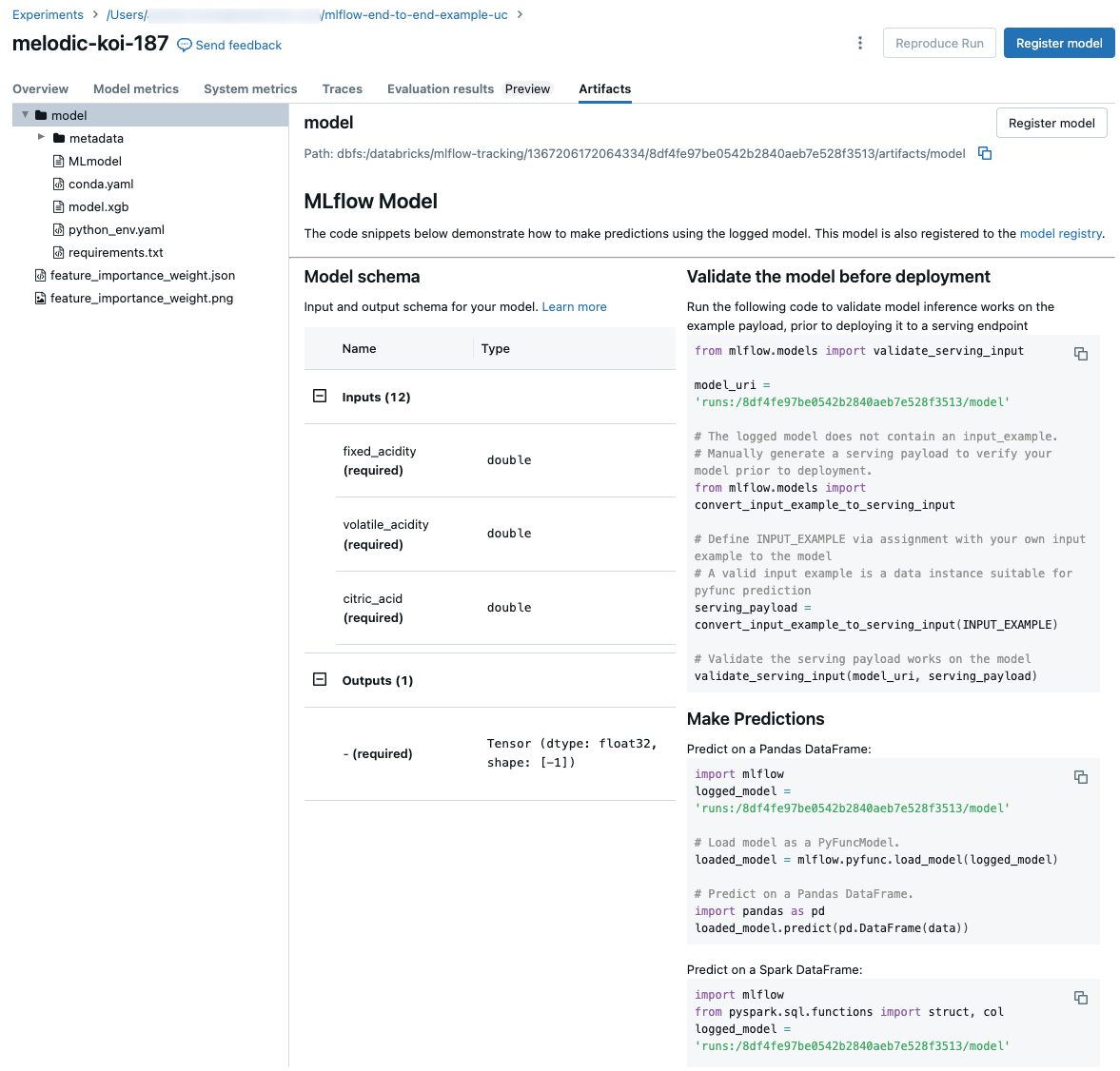
実行からモデルをログに記録すると、そのモデルが [アーティファクト] タブに表示されます。また、モデルを読み込んで使用し、Spark および Pandas DataFrames で予測を行う方法を示すコード スニペットも表示されます。MLflow 3では、モデルは実行アーティファクトとして記録されるのではなく、独自のファーストクラス オブジェクトになりました。 詳細については、 「モデル用のMLflow 3 の使用を開始する」を参照してください。
ランに使用したノートブックを表示する
ランを作成した ノートブックのバージョン を表示するには、次のようにします。
- エクスペリメントの詳細ページで、[ ソース ] 列のリンクをクリックします。
- ランページで、[ ソース ] の横にあるリンクをクリックします。
- ノートブックの [エクスペリメントのラン] サイドバーで、そのエクスペリメントのランのボックスにある [ノートブック ] アイコン
 をクリックします。
をクリックします。
ランに関連付けられているノートブックのバージョンがメイン ウィンドウに表示され、ランの日時を示す強調表示バーが表示されます。
ランにタグを追加する
タグは、キーと値のペアで、作成して後で ランを検索するために使用できます。
-
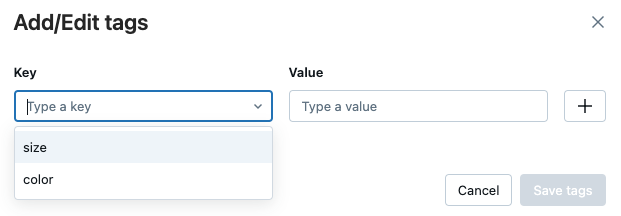
実行ページの[詳細] テーブルで、[ タグ] の横にある[タグの追加] をクリックします。
![[詳細] ページの [タグ] ボタン](/aws/ja/assets/images/tags-open-2b92892f2d6833c4fac51ed029b0ae39.png)
-
タグの追加/編集ダイアログが開きます。 「 キー 」フィールドに、キーの名前を入力し、「 タグを追加 」をクリックします。
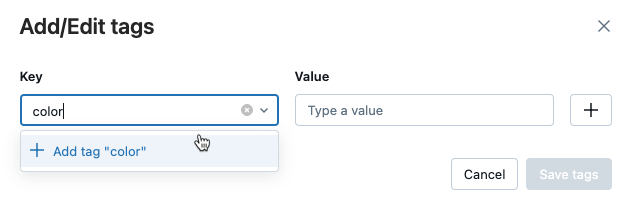
-
[値 ] フィールドに、タグの値を入力します。
-
プラス記号をクリックして、入力したキーと値のペアを保存します。
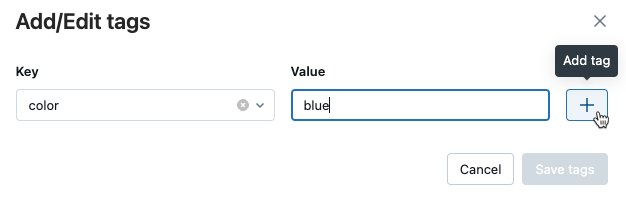
-
タグを追加するには、手順 2 から 4 を繰り返します。
-
完了したら、[ タグの保存 ] をクリックします。
ランのタグを編集または削除する
-
ランページの [詳細] テーブルで既存のタグの横にある
 をクリックします。
をクリックします。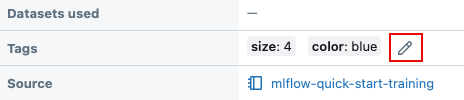
-
[タグの追加/編集] ダイアログが開きます。
-
タグを削除するには、そのタグの [X] をクリックします。
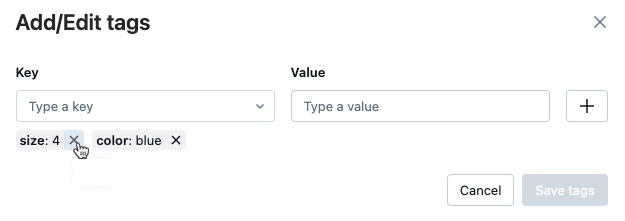
-
タグを編集するには、ドロップダウンメニューからキーを選択し、[ 値 ]フィールドの値を編集します。 プラス記号をクリックして、変更を保存します。
-
-
完了したら、[ タグの保存 ] をクリックします。
ソフトウェア環境のランを再現
ランページの右上にある 「ランの再現 」をクリックすると、ランの正確なソフトウェア環境を再現できます。 次のダイアログが表示されます。
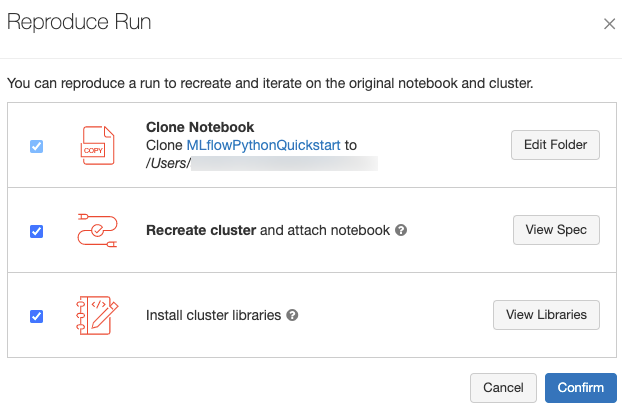
デフォルト設定では、[ 確認] をクリックすると、次のようになります。
- ノートブックは、ダイアログに表示されている場所にクローニングされます。
- 元のクラスターがまだ存在する場合は、クローニングされたノートブックが元のクラスターにアタッチされ、クラスターが開始されます。
- 元のクラスターが存在しなくなった場合は、同じ構成の新しいクラスター (インストールされているライブラリを含む) が作成され、開始されます。 ノートブックが新しいクラスターにアタッチされます。
クローン作成されたノートブックに別の場所を選択し、クラスター構成とインストールされているライブラリを検査できます。
- クローン ノートブックを保存する別のフォルダを選択するには、[ フォルダの編集] をクリックします。
- クラスター スペシフィケーションを表示するには、[ View Spec ] をクリックします。 ノートブックのみをクローンし、クラスターをクローンしない場合は、このオプションのチェックを外します。
- 元のクラスターが存在しなくなった場合は、[ ライブラリの表示 ] をクリックすると、元のクラスターにインストールされているライブラリを確認できます。 元のクラスターがまだ存在する場合、このセクションはグレー表示されます。
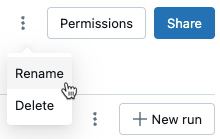
ランの名前変更
ランの名前を変更するには、ランページの右上隅 ([アクセス許可]ボタンの横) にあるケバブ メニュー をクリックし、[![]() 名前の変更] を選択します。
名前の変更] を選択します。
表示する列の選択
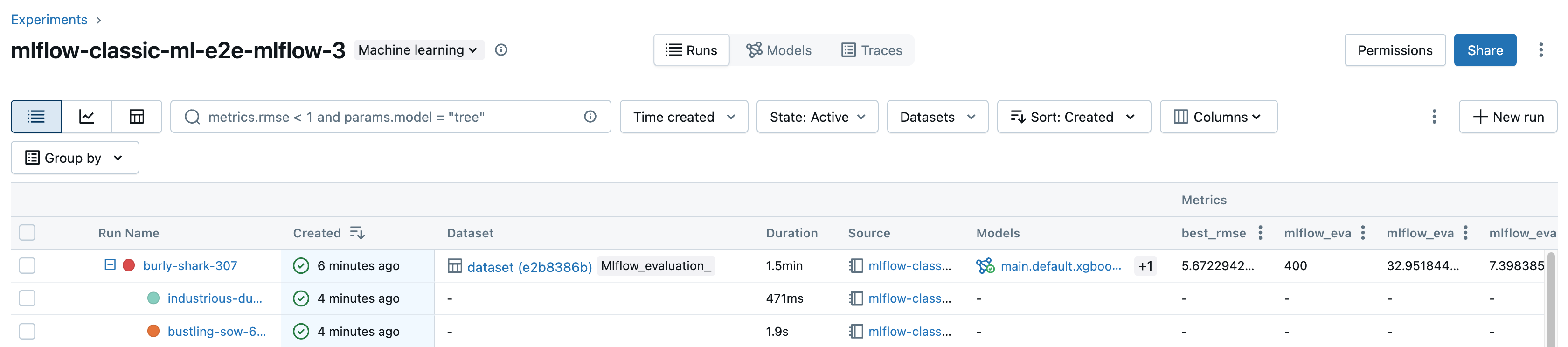
エクスペリメントの詳細ページのランテーブルに表示される列を制御するには、[ 列 ] をクリックし、ドロップダウン メニューから選択します。
ランのフィルター
エクスペリメントの詳細ページのテーブルで、パラメーターまたはメトリクスの値に基づいてランを検索できます。 タグでランを検索することもできます。
-
パラメーター値とメトリクス値を含む式に一致するランを検索するには、検索フィールドにクエリを入力して Enter キーを押します。 クエリ構文の例を次に示します。
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1デフォルトでは、メトリクス値は最後にログされた値に基づいてフィルタリングされます。
MINまたはMAXを使用すると、それぞれメトリクスの最小値または最大値に基づいてランを検索できます。2024 年 8 月以降にログ記録されたランのみ、最小値と最大値があります。 -
タグでランを検索するには、
tags.<key>="<value>"の形式でタグを入力します。 文字列値は、次に示すように引用符で囲む必要があります。tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5キーと値の両方にスペースを含めることができます。 キーにスペースが含まれている場合は、次に示すようにキーをバッククォートで囲む必要があります。
tags.`my custom tag` = "my value"
また、状態 (アクティブまたは削除済み)、ランが作成された日時、使用されたデータセットに基づいてランをフィルタリングすることもできます。 これを行うには、 作成された時間 、 状態 、または データセット のドロップダウンメニューからそれぞれ選択します。
ランのダウンロード
エクスペリメントの詳細ページから、以下の手順でランをダウンロードできます。
-
 クリックしてケバブメニューを開きます。
クリックしてケバブメニューを開きます。
-
表示されているすべてのラン (最大 100 個) を含む CSV 形式でファイルをダウンロードするには、[
<n>ランのダウンロード] を選択します。MLflow では、1 行に 1 回のランを含むファイルが作成され、ダウンロードされます。これには、ランごとに次のフィールドが含まれます。Start Time, Duration, Run ID, Name, Source Type, Source Name, User, Status, <parameter1>, <parameter2>, ..., <metric1>, <metric2>, ... -
100 を超えるランをダウンロードする場合、またはプログラムによってランをダウンロードする場合は、[ すべてのランをダウンロード] を選択します。 ダイアログが開き、コピーしたりノートブックで開いたりできるコード スニペットが表示されます。 ノートブックのセルでこのコードをランした後、セル出力から [Download all rows from the cell output] を選択します。
ランの削除
エクスペリメントの詳細ページからランを削除するには、次の手順に従います。
- エクスペリメントで、ランの左側にあるチェックボックスをクリックして、1 つ以上のランを選択します。
- 削除 をクリックします。
- ランが親ランの場合は、子孫ランも削除するかどうかを決定します。 このオプションはデフォルトで選択されています。
- [ 削除 ] をクリックして確定します。 削除されたランは30日間保存されます。 削除されたランを表示するには、[状態] フィールドで [ 削除済み ] を選択します。
作成時刻に基づくランの一括削除
Pythonを使用して、UNIX タイムスタンプより前または UNIX タイムスタンプで作成された実験のランを一括削除できます。
Databricks Runtime 14.1 以降を使用すると、 mlflow.delete_runs API を呼び出してランを削除し、削除されたランの数を返すことができます。
mlflow.delete_runs パラメーターを次に示します。
experiment_id: 削除するランを含むエクスペリメントの ID。max_timestamp_millis: 削除ランの UNIX エポック以降の最大作成タイムスタンプ (ミリ秒単位)。 このタイムスタンプより前またはその時点で作成されたランのみが削除されます。max_runs:随意。 削除するランの最大数を示す正の整数。 max_runs の最大許容値は 10000 です。 指定しない場合、max_runsデフォルトは 10000 です。
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
Databricks Runtime 13.3 LTS 以前を使用すると、Databricks ノートブックで次のクライアント コードをランできます。
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
作成時刻に基づいてランを削除するためのパラメーターと戻り値の指定については、Databricks エクスペリメント API ドキュメントを参照してください。
ランの復元
以前に削除したランは、次のように UI から復元できます。
- エクスペリメント ページの 状態 フィールドで、 削除 済み を選択して、削除されたランを表示します。
- ランの左側にあるチェックボックスをクリックして、1 つ以上のランを選択します。
- 「リストア」 をクリックします。
- 復元 をクリックして確定します。復元されたランは、[状態] フィールドで アクティブ を選択すると表示されます。
ランの一括復元は削除時間に基づいて行われます
Pythonを使用して、UNIX タイムスタンプ以降に削除されたエクスペリメントのランを一括復元することもできます。
Databricks Runtime 14.1 以降を使用すると、 mlflow.restore_runs API を呼び出してランを復元し、復元されたランの数を返すことができます。
mlflow.restore_runs パラメーターを次に示します。
experiment_id: 復元するランを含むエクスペリメントの ID。min_timestamp_millis: 復元ランの UNIX エポックからの最小削除タイムスタンプ (ミリ秒単位)。 このタイムスタンプ以降に削除されたランのみが復元されます。max_runs:随意。 復元するランの最大数を示す正の整数。 max_runs の最大許容値は 10000 です。 指定しない場合、max_runs のデフォルトは 10000 です。
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
Databricks Runtime 13.3 LTS 以前を使用すると、Databricks ノートブックで次のクライアント コードをランできます。
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
削除時間に基づいてランを復元するためのパラメーターと戻り値の仕様については、Databricks エクスペリメント API のドキュメントを参照してください。
ランの比較
単一のエクスペリメントまたは複数のエクスペリメントからの実行を比較できます。 [実行の比較 ] ページには、選択した実行に関する情報が表形式で表示されます。また、実行結果の視覚化と、実行情報、実行パラメーター、およびメトリクスのテーブルを作成することもできます。 「グラフとグラフを使用して MLflow の実行とモデルを比較する」を参照してください。
パラメーター ・テーブルと メトリクス ・テーブルには、選択したすべてのランのラン パラメーターとメトリクスが表示されます。これらのテーブルの列は、すぐ上の [ランの詳細 ] テーブルで識別されます。 簡単にするために、選択したすべてのランで同一のパラメーターとメトリクスを非表示にするには、 ![]() を切り替えます。
を切り替えます。
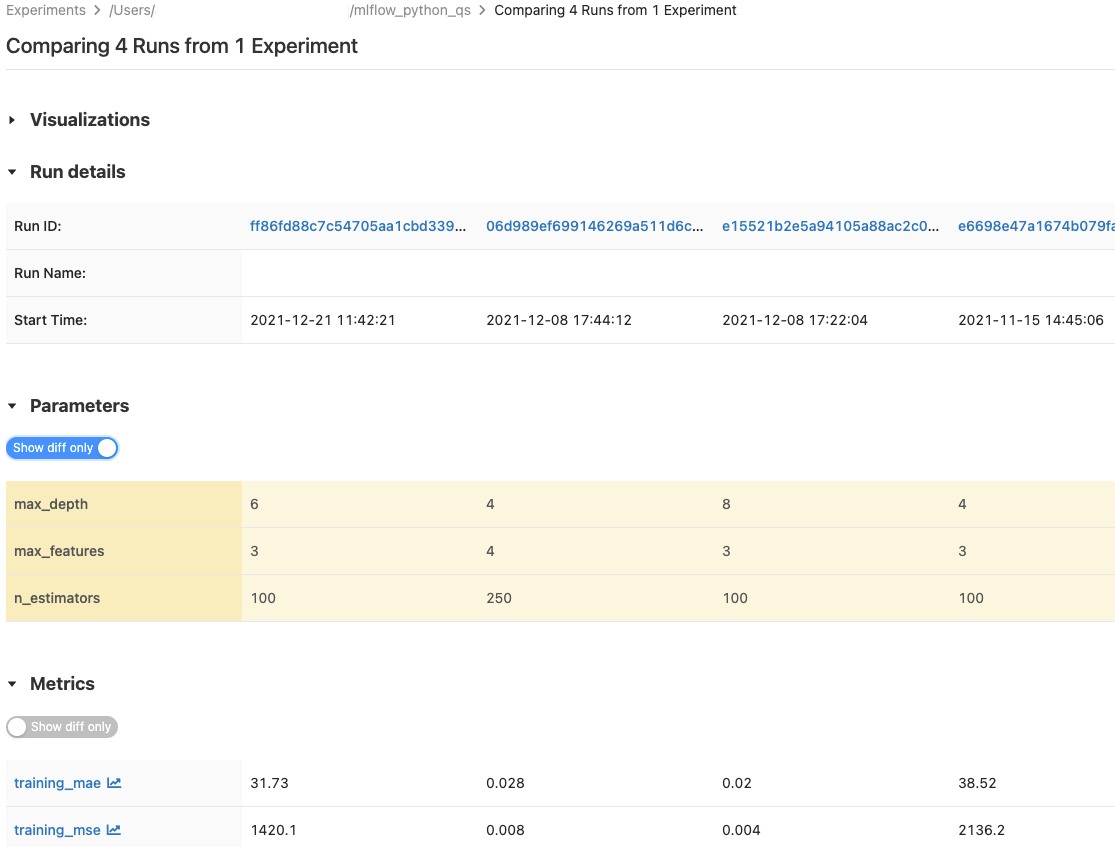
1 つのエクスペリメントからのランの比較
- エクスペリメントの詳細ページで、ランの左側にあるチェックボックスをクリックして 2 つ以上のランを選択するか、列の上部にあるチェックボックスをオンにしてすべてのランを選択します。
- [ 比較] をクリックします。 [ラン
<N>の比較]画面が表示されます。
複数のエクスペリメントからランを比較する
- エクスペリメントページで、エクスペリメント名の左側にあるボックスをクリックして、比較するエクスペリメントを選択します。
- [ 比較] (n) をクリックします ( n は選択したエクスペリメントの数です)。 選択したエクスペリメントのすべてのランを示す画面が表示されます。
- ランの左側にあるチェックボックスをオンにして 2 つ以上のランを選択するか、列の上部にあるチェックボックスをオンにしてすべてのランを選択します。
- [ 比較] をクリックします。 [ラン
<N>の比較]画面が表示されます。
システムテーブルを使用した実行の比較
エクスペリメントと実行のMLflowメタデータは、システムテーブルでも利用でき、Databricks SQLとすべてのレイクハウスツールを活用して、エクスペリメントデータを分析Databricksできます。詳細については、「システムテーブルMLflowリファレンス」を参照してください。
ワークスペース間でのランのコピー
Databricks ワークスペースとの間で MLflow のランをインポートまたはエクスポートするには、コミュニティ主導の オープンソース プロジェクト MLflow エクスポート/インポートを使用できます。