Veja os resultados do treinamento com MLflow execução
Este artigo descreve como usar o MLflow execução para view e analisar os resultados de um experimento de treinamento de modelo e como gerenciar e organizar a execução. Para obter mais informações sobre os experimentos do MLflow, consulte Organizar treinamento execução com os experimentos do MLflow.
Uma execução do MLflow corresponde a uma única execução do código do modelo. Cada execução registra informações como o Notebook que iniciou a execução, quaisquer modelos criados pela execução, parâmetros e métricas do modelo salvos como par key-value, tags para metadados da execução e quaisquer artefatos ou arquivos de saída criados pela execução.
Todas as execuções do MLflow são registros para o experimento ativo. Se o senhor não tiver definido explicitamente um experimento como o experimento ativo, as execuções serão registradas no experimento do Notebook.
ver detalhes da execução
O senhor pode acessar uma execução na página de detalhes do experimento ou diretamente no Notebook que criou a execução.
Na página de detalhes do experimento, clique no nome da execução na tabela de execução.
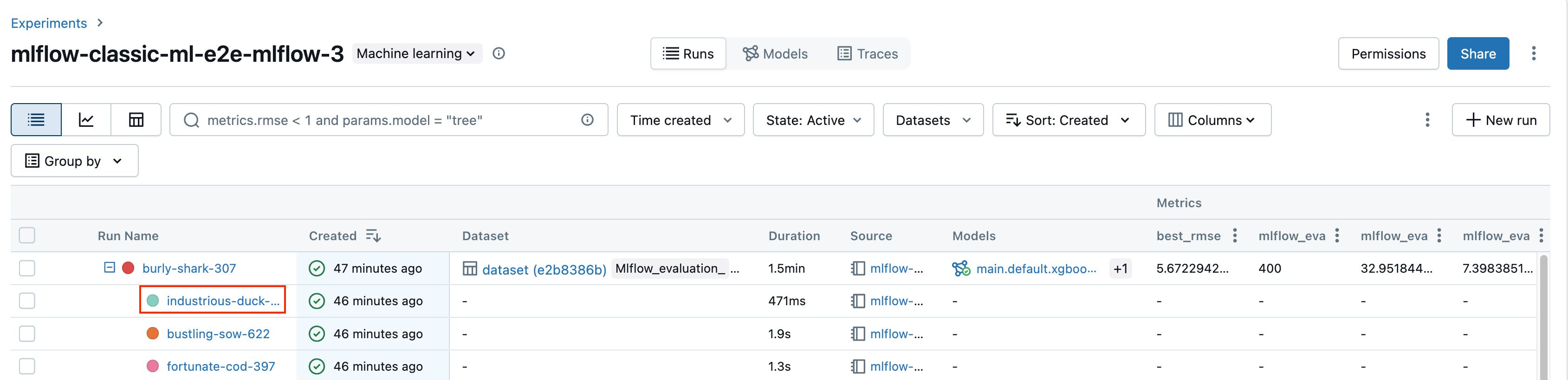
No Notebook, clique no nome da execução na barra lateral Experiment Execution.
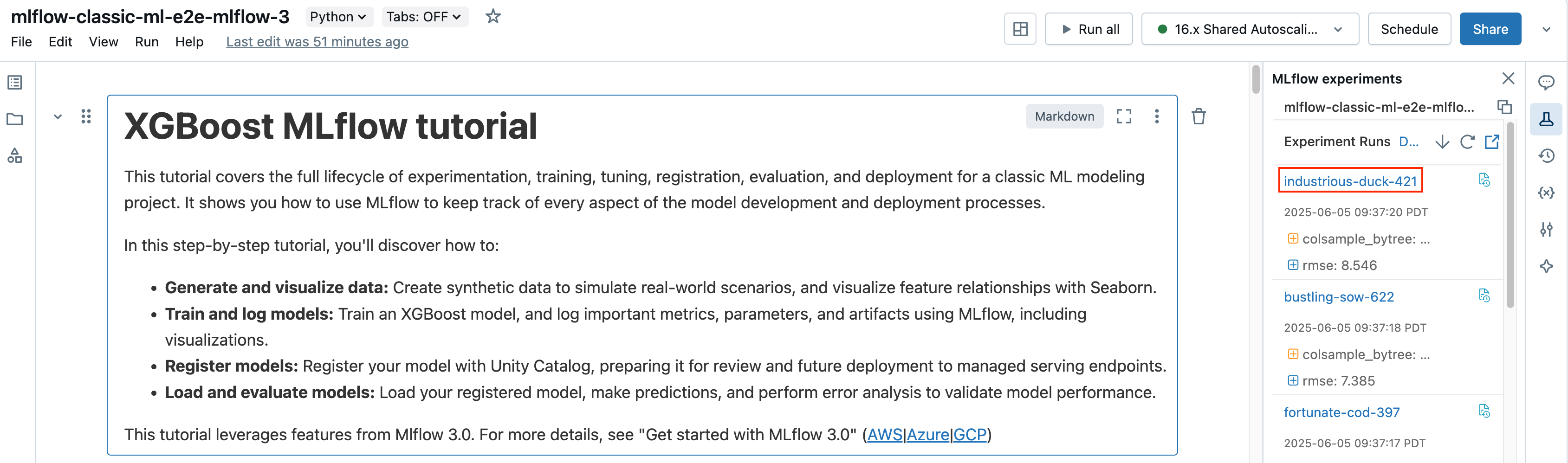
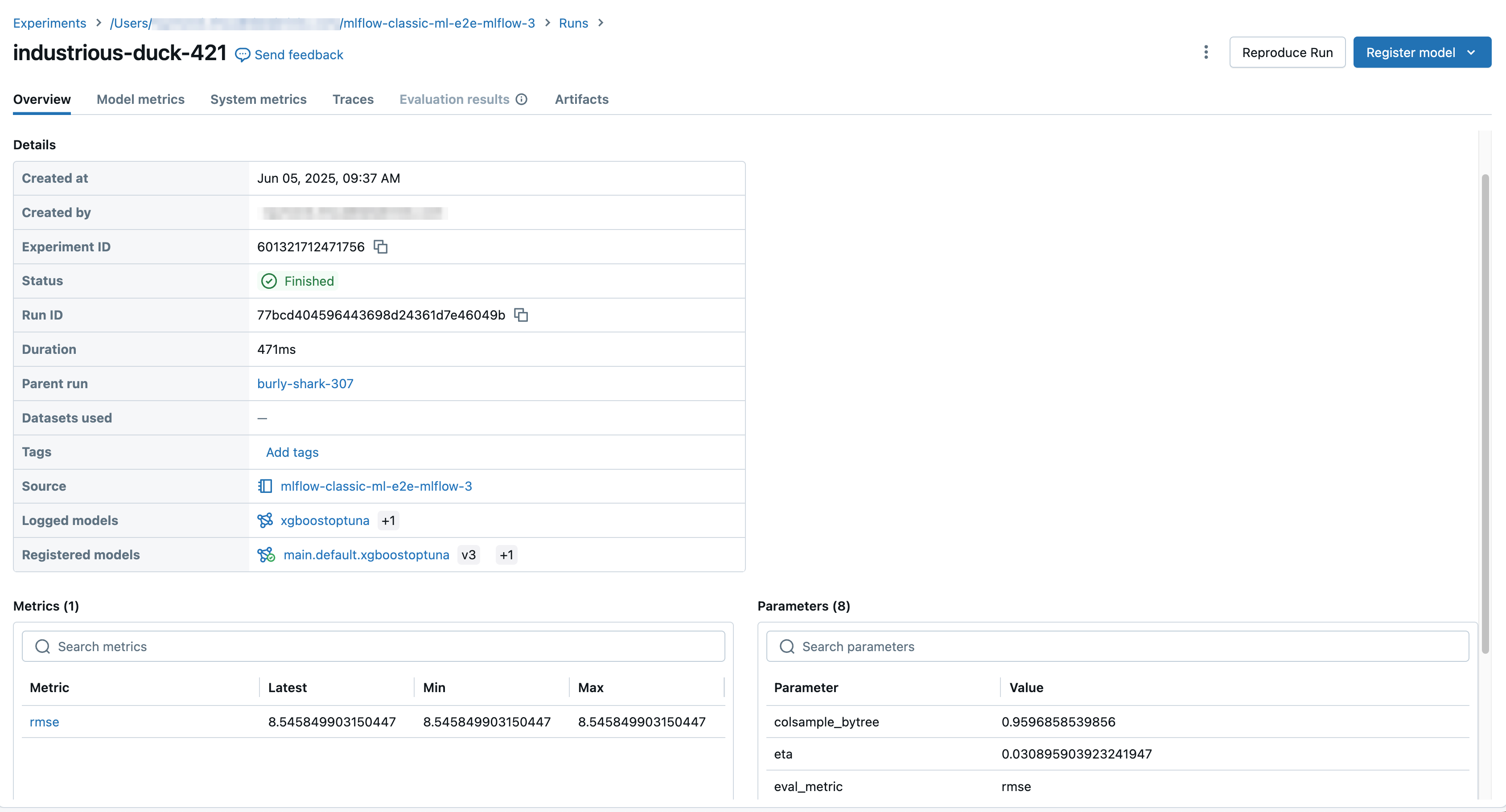
A tela de execução mostra o ID da execução, os parâmetros usados para a execução, as métricas resultantes da execução e detalhes sobre a execução, incluindo um link para o Notebook de origem. Os artefatos salvos da execução estão disponíveis em Artifacts tab.
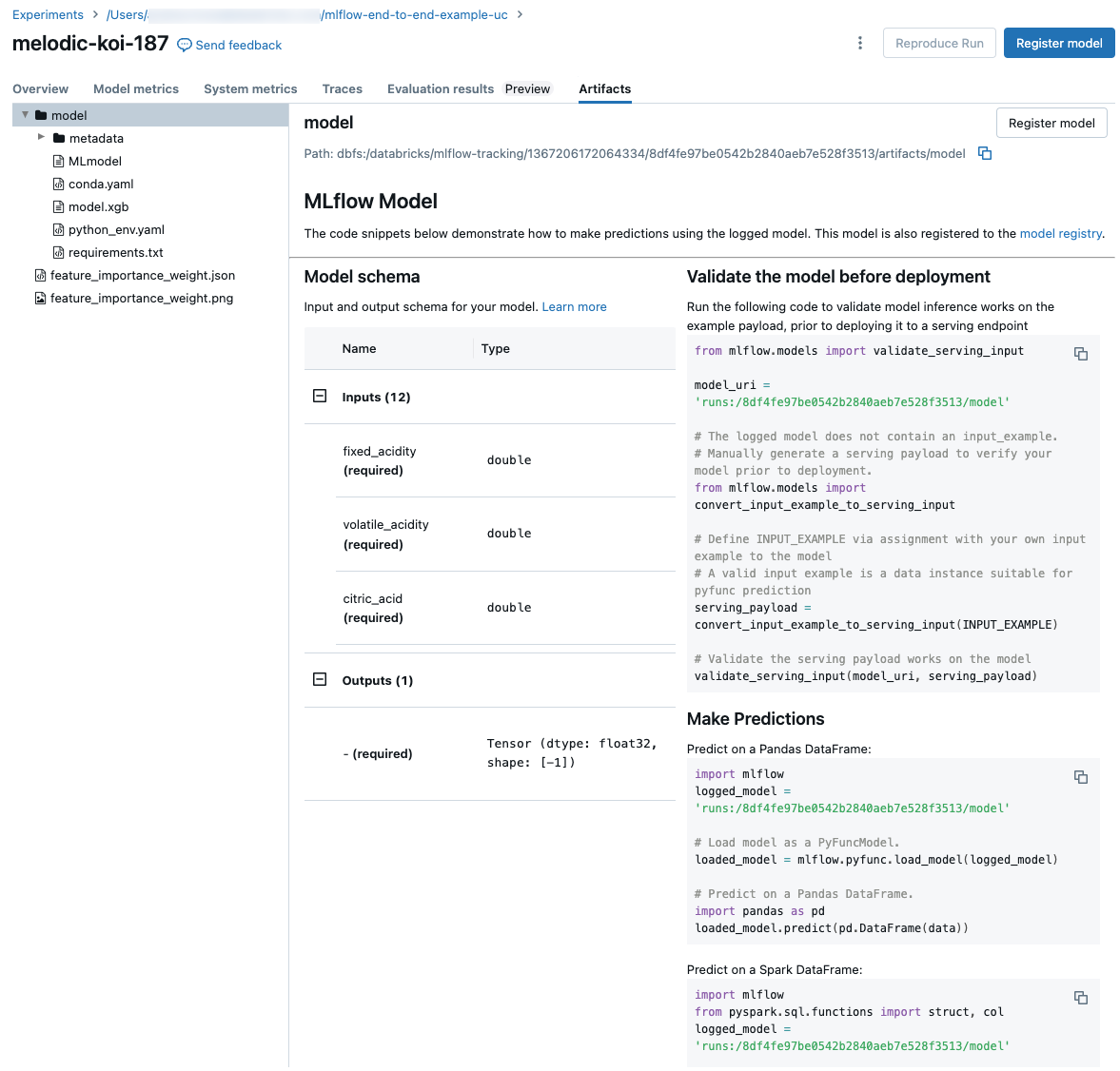
Trechos de código para previsão
Se você log um modelo de uma execução, o modelo aparecerá na tab Artefatos , junto com trechos de código ilustrando como carregar e usar o modelo para fazer previsões no Spark e Pandas DataFrames. No MLflow 3, os modelos agora são seus objetos de primeira classe distintos, em vez de serem logs como artefatos de execução. Para obter mais informações, consulte Começar com MLflow 3 para modelos.
visualizar o Notebook usado para uma execução
Para view a versão do Notebook que criou uma execução:
- Na página de detalhes do experimento, clique no link na coluna Fonte .
- Na página de execução, clique no link ao lado de Source .
- No Notebook, na barra lateral da execução do experimento, clique no ícone Notebook
 na caixa da execução do experimento.
na caixa da execução do experimento.
A versão do Notebook associada à execução aparece na janela principal com uma barra de destaque mostrando a data e a hora da execução.
Adicionar uma tag a uma execução
As tags são par key-value que o senhor pode criar e usar posteriormente para pesquisar a execução.
-
Na tabela Details (Detalhes ) da página de execução, clique em Add tags (Adicionar tags ) ao lado de Tags .
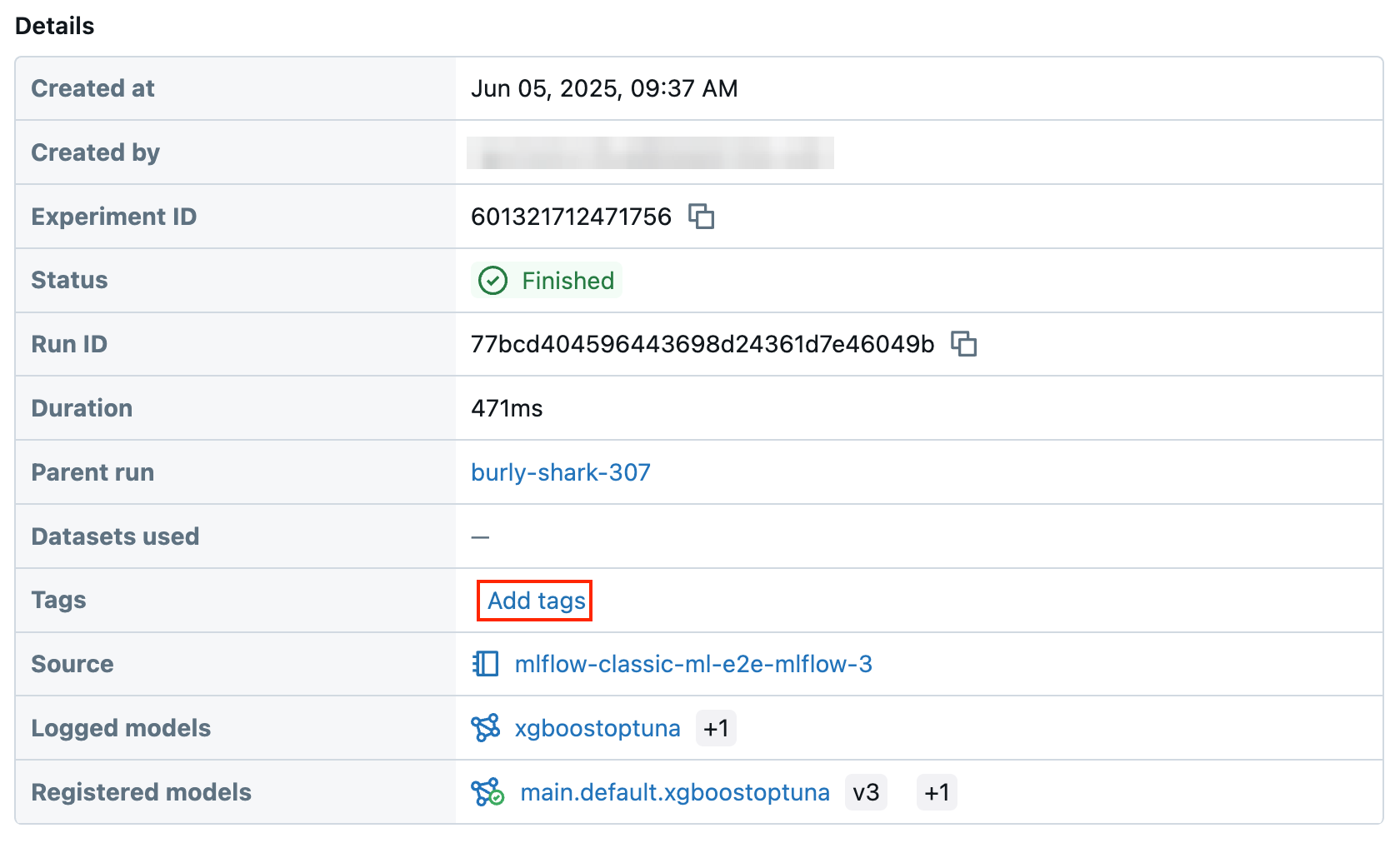
-
A caixa de diálogo Adicionar/Editar tags é aberta. No campo key (chave ), digite um nome para a tag key e clique em Add tag (adicionar tag) .
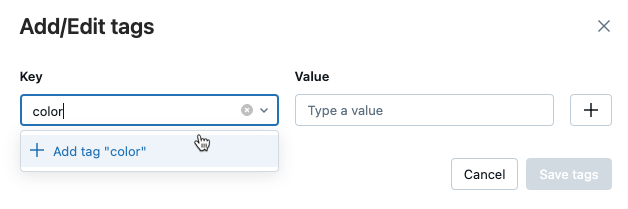
-
No campo Valor , insira o valor da tag.
-
Clique no sinal de mais para salvar o valor do par keyque o senhor acabou de inserir.
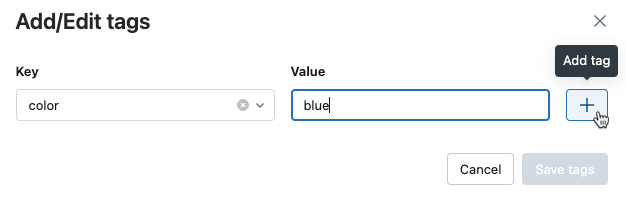
-
Para adicionar tags adicionais, repita as etapas 2 a 4.
-
Quando terminar, clique em Salvar tags .
Editar ou excluir uma tag para uma execução
-
Na tabela Details (Detalhes ) da página de execução, clique em
 ao lado das tags existentes.
ao lado das tags existentes.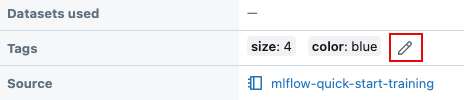
-
A caixa de diálogo Adicionar/Editar tags é aberta.
-
Para excluir uma tag, clique no X dessa tag.
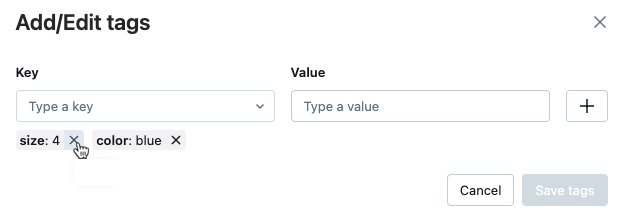
-
Para editar uma tag, selecione key no menu suspenso e edite o valor no campo Value (Valor) . Clique no sinal de mais para salvar sua alteração.
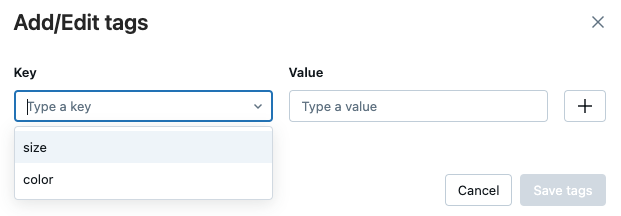
-
-
Quando terminar, clique em Salvar tags .
Reproduzir o ambiente de software de uma execução
O senhor pode reproduzir o ambiente exato do software para a execução clicando em Reproduce execution (Reproduzir execução ) no canto superior direito da página de execução. A caixa de diálogo a seguir é exibida:
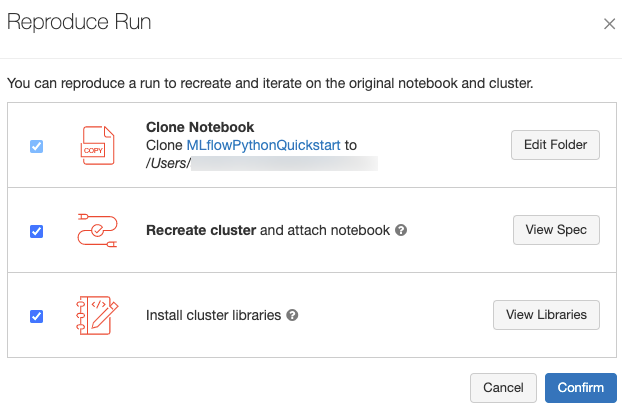
Com as configurações do site default, quando o senhor clicar em Confirm (Confirmar ):
- O Notebook é clonado no local mostrado na caixa de diálogo.
- Se o clustering original ainda existir, o Notebook clonado será anexado ao clustering original e o clustering será iniciado.
- Se o clustering original não existir mais, um novo clustering com a mesma configuração, incluindo qualquer biblioteca instalada, será criado e começará. O Notebook é anexado ao novo clustering.
O senhor pode selecionar um local diferente para o Notebook clonado e inspecionar a configuração de clustering e a biblioteca instalada:
- Para selecionar uma pasta diferente para salvar o Notebook clonado, clique em Edit Folder (Editar pasta) .
- Para ver a especificação de clustering, clique em view Spec . Para clonar apenas o Notebook e não o clustering, desmarque essa opção.
- Se o clustering original não existir mais, o senhor poderá ver a biblioteca instalada no clustering original clicando em view biblioteca . Se o clustering original ainda existir, essa seção ficará em cinza.
Renomear a execução
Para renomear uma execução, clique no menu kebab ![]() no canto superior direito da página de execução (ao lado do botão Permissions ) e selecione Rename (Renomear ).
no canto superior direito da página de execução (ao lado do botão Permissions ) e selecione Rename (Renomear ).
Selecione as colunas a serem exibidas
Para controlar as colunas exibidas na tabela de execução na página de detalhes do experimento, clique em Columns (Colunas ) e selecione no menu suspenso.
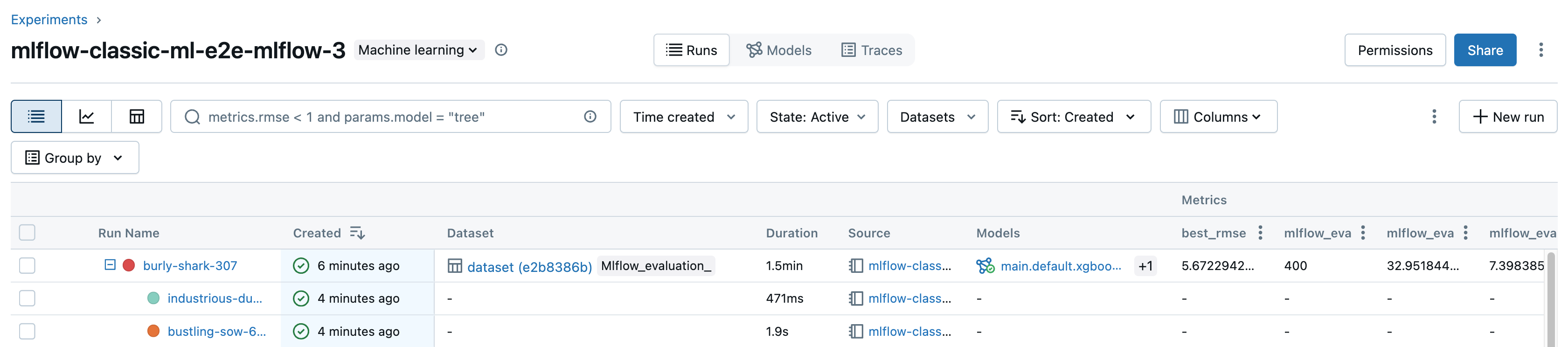
Execução do filtro
O senhor pode pesquisar a execução na tabela da página de detalhes do experimento com base em valores de parâmetros ou métricas. O senhor também pode pesquisar execução por tag.
-
Para pesquisar execuções que correspondam a uma expressão contendo valores de parâmetros e métricas, insira uma consulta no campo de pesquisa e pressione Enter. Alguns exemplos de sintaxe de consulta são:
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1Em default, os valores métricos são filtrados com base no último valor de registros. Usando
MINouMAX, o senhor pode pesquisar a execução com base nos valores métricos mínimos ou máximos, respectivamente. Somente os registros de execução após agosto de 2024 têm valores mínimos e máximos de métricas. -
Para pesquisar a execução por tag, insira as tags no formato:
tags.<key>="<value>". Os valores das cadeias de caracteres devem ser colocados entre aspas, conforme mostrado.tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5Tanto a chave quanto os valores podem conter espaços. Se o endereço key incluir espaços, o senhor deverá colocá-lo entre aspas, conforme mostrado.
tags.`my custom tag` = "my value"
O senhor também pode filtrar a execução com base em seu estado (Ativo ou Excluído), quando a execução foi criada e qual conjunto de dados foi usado. Para fazer isso, faça suas seleções nos menus suspensos Time created (Tempo criado) , State (Estado ) ou dataset (Conjunto de dados) , respectivamente.
download execução
O senhor pode acessar download execução na página de detalhes do experimento da seguinte forma:
-
Clique
 para abrir o menu de kebab.
para abrir o menu de kebab.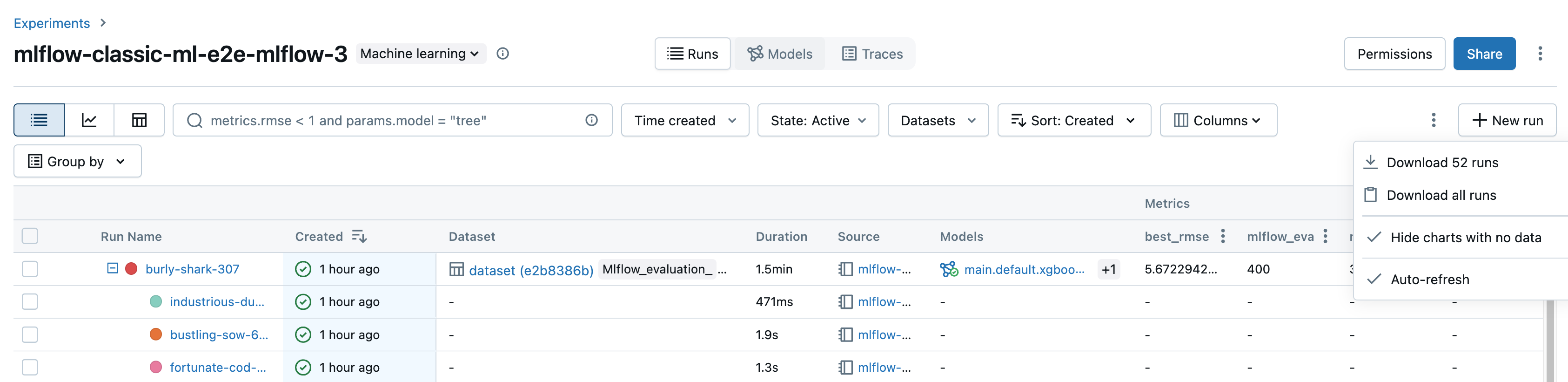
-
Para download um arquivo no formato CSV contendo todas as execuções mostradas (até um máximo de 100), selecione download
<n>execução . MLflow cria e downloads um arquivo com uma execução por linha, contendo os seguintes campos para cada execução:Start Time, Duration, Run ID, Name, Source Type, Source Name, User, Status, <parameter1>, <parameter2>, ..., <metric1>, <metric2>, ... -
Se o senhor quiser download mais de 100 execuções ou quiser download execuções de forma programática, selecione baixar todas as execuções . Uma caixa de diálogo é aberta mostrando um trecho de código que o senhor pode copiar ou abrir em um Notebook. Depois de executar esse código em uma célula do Notebook, selecione baixar todas as linhas da saída da célula.
Excluir execução
O senhor pode excluir a execução da página de detalhes do experimento seguindo estas etapas:
- No experimento, selecione uma ou mais execuções clicando na caixa de seleção à esquerda da execução.
- Clique em Excluir .
- Se a execução for uma execução pai, decida se o senhor também deseja excluir a execução descendente. Essa opção é selecionada em default.
- Clique em Excluir para confirmar. As execuções excluídas são salvas por 30 dias. Para exibir a execução excluída, selecione Deleted no campo State (Estado).
Execução de exclusão em massa com base na hora de criação
O senhor pode usar o site Python para excluir em massa as execuções de um experimento que foram criadas antes ou em um carimbo de data/hora do UNIX.
Usando o site Databricks Runtime 14.1 ou posterior, o senhor pode chamar o mlflow.delete_runs API para excluir a execução e retornar o número de execuções excluídas.
A seguir estão os parâmetros mlflow.delete_runs:
experiment_id: O ID do experimento que contém a execução a ser excluída.max_timestamp_millis: O registro de data e hora máximo de criação em milissegundos desde a época do UNIX para a exclusão da execução. Somente as execuções criadas antes ou nesse registro de data e hora são excluídas.max_runs: Opcional. Um número inteiro positivo que indica o número máximo de execuções a serem excluídas. O valor máximo permitido para max_runs é 10000. Se não for especificado,max_runstem como padrão 10000.
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
Usando o Databricks Runtime 13.3 LTS ou anterior, o senhor pode executar o seguinte código de cliente em um Databricks Notebook.
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
Consulte a documentação do site Databricks Experiments API para obter os parâmetros e as especificações do valor de retorno para excluir a execução com base no tempo de criação.
Restaurar a execução
O senhor pode restaurar a execução excluída anteriormente na interface do usuário da seguinte forma:
- Na página Experiment , no campo State (Estado ), selecione Deleted (Excluído ) para exibir a execução excluída.
- Selecione uma ou mais execuções clicando na caixa de seleção à esquerda da execução.
- Clique em Restaurar .
- Clique em Restaurar para confirmar. A execução restaurada agora aparece quando o senhor seleciona Active (Ativo ) no campo State (Estado).
Execução de restauração em massa com base na hora da exclusão
O senhor também pode usar o site Python para restaurar em massa a execução de um experimento que foi excluído em ou após um carimbo de data/hora do UNIX.
Usando o site Databricks Runtime 14.1 ou posterior, o senhor pode chamar o mlflow.restore_runs API para restaurar a execução e retornar o número da execução restaurada.
A seguir estão os parâmetros mlflow.restore_runs:
experiment_id: O ID do experimento que contém a execução a ser restaurada.min_timestamp_millis: O registro de data e hora mínimo de exclusão em milissegundos desde a época do UNIX para restaurar a execução. Somente as execuções excluídas nesse momento ou após esse registro de data e hora são restauradas.max_runs: Opcional. Um número inteiro positivo que indica o número máximo de execuções a serem restauradas. O valor máximo permitido para max_runs é 10000. Se não for especificado, o padrão de max_runs é 10000.
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
Usando o Databricks Runtime 13.3 LTS ou anterior, o senhor pode executar o seguinte código de cliente em um Databricks Notebook.
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
Consulte a documentação do site Databricks Experiments API para obter parâmetros e especificações de valores de retorno para restaurar a execução com base no tempo de exclusão.
Comparar execução
O senhor pode comparar a execução de um único experimento ou de vários experimentos. A página Comparação de execução apresenta informações sobre a execução selecionada em formato de tabela. O senhor também pode criar visualizações de resultados de execução e tabelas de informações de execução, parâmetros de execução e métricas. Veja Compare MLflow execução e modelos usando gráficos e tabelas.
As tabelas Parameters e métricas exibem os parâmetros de execução e as métricas de todas as execuções selecionadas. As colunas nessas tabelas são identificadas pela tabela de detalhes da execução imediatamente acima. Para simplificar, o senhor pode ocultar parâmetros e métricas que são idênticos em todas as execuções selecionadas, alternando ![]() .
.
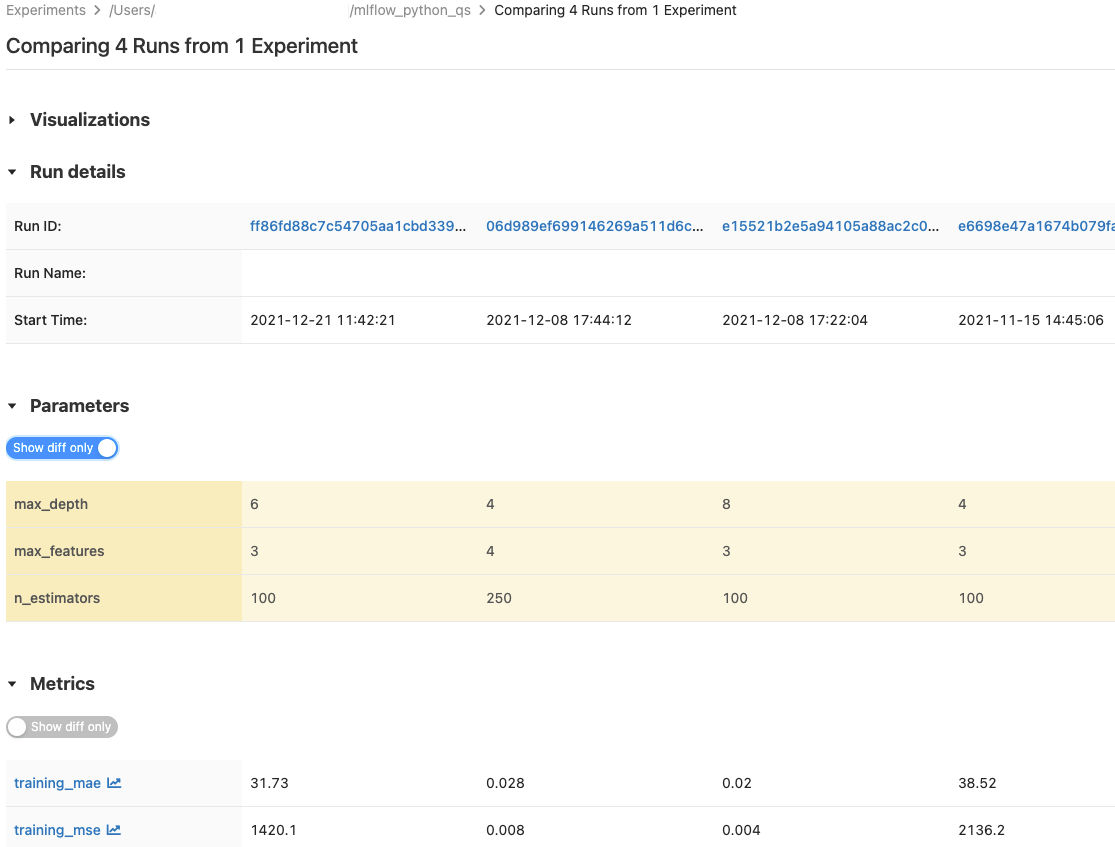
Comparar a execução de um único experimento
- Na página de detalhes do experimento, selecione duas ou mais execuções clicando na caixa de seleção à esquerda da execução ou selecione todas as execuções marcando a caixa na parte superior da coluna.
- Clique em Comparar . A tela Comparando
<N>execução é exibida.
Comparar a execução de vários experimentos
- Na página de experimentos, selecione os experimentos que você deseja comparar clicando na caixa à esquerda do nome do experimento.
- Clique em Comparar (n) ( n é o número de experimentos que você selecionou). É exibida uma tela com todas as execuções dos experimentos que o senhor selecionou.
- Selecione duas ou mais execuções clicando na caixa de seleção à esquerda da execução ou selecione todas as execuções marcando a caixa na parte superior da coluna.
- Clique em Comparar . A tela Comparando
<N>execução é exibida.
Comparar a execução usando tabelas do sistema
MLflow Os metadados dos experimentos e da execução também estão disponíveis nas tabelas do sistema, onde o senhor pode aproveitar Databricks SQL e todas as ferramentas do lakehouse que o Databricks oferece para analisar os dados de seus experimentos. Para obter mais detalhes, consulte Referência das tabelas do sistema MLflow.
Copiar execução entre espaços de trabalho
Para importar ou exportar MLflow execução para ou de seu Databricks workspace, o senhor pode usar o projeto de código aberto orientado pela comunidade MLflow Export-Import.