Databricks 上の RStudio
R の一般的な統合開発環境 (IDE) である RStudioを使用して、ワークスペース内の Databricks コンピュート リソースに接続できますDatabricks。RStudio Desktop を使用して、ローカル開発マシンから Databricks クラスターまたは SQLウェアハウスに接続します。
また、WebDatabricks ブラウザーを使用して ワークスペースにサインインし、そのワークスペース内でDatabricksRStudio Server がインストールされている クラスターに接続することもできます。
RStudio Desktop を使用して接続する
RStudio Desktop を使用して、ローカル開発マシンからリモート Databricks クラスターまたは SQLウェアハウスに接続します。このシナリオで接続するには、ODBC 接続を使用し、このセクションで説明する R の ODBC パッケージ関数を呼び出します。
この デスクトップシナリオでは、 も使用しない限り、 SparkRや RStudioDatabricks ConnectSparklyr などのパッケージを使用することはできません。
ローカル開発マシンで RStudio Desktop を設定するには:
- R 3.3.0 以降をダウンロードしてインストールします。
- RStudio Desktopをダウンロードしてインストールします。
- RStudio Desktop を起動します。
(オプション)RStudio プロジェクトを作成するには:
- RStudio Desktop を起動します。
- [ファイル] > [新しいプロジェクト] をクリックします。
- [新しいディレクトリ] > [新しいプロジェクト ] を選択します。
- プロジェクトの新しいディレクトリを選択し、[ プロジェクトの作成 ] をクリックします。
R スクリプトを作成するには:
- プロジェクトを開いた状態で、[ ファイル] > [新しいファイル] > [R スクリプト ] をクリックします。
- 「ファイル」>「名前を付けて保存」 をクリックします。
- ファイルに名前を付けて、[ 保存 ] をクリックします。
for R Databricksを使用してリモート クラスターまたはSQL ウェアハウスに接続するには、次のようにします。ODBC
-
リモート クラスターSQL またはウェアハウスの Server hostname 、 Port 、および HTTP パス の値 取得します。クラスターの場合、これらの値は[詳細オプション] の JDBC /ODBC タブにあります。SQLウェアハウスの場合、これらの値は [接続の詳細 ] タブにあります。
-
Databricks の個人用アクセス トークンを取得します。
自動化されたツール、システム、スクリプト、アプリで認証する際のセキュリティのベストプラクティスとして、Databricks では OAuth トークンを使用することをお勧めします。
パーソナルアクセストークン認証 を使用する場合、 Databricks では、ワークスペース ユーザーではなく 、サービスプリンシパル に属する パーソナルアクセストークン を使用することをお勧めします。 サービスプリンシパルのトークンを作成するには、「 サービスプリンシパルのトークンの管理」を参照してください。
-
ローカル コンピューターのオペレーティング システムに基づいて、Windows、macOS、または Linux 用の Databricks ODBC ドライバーをインストールして構成します。
-
ODBCデータソース名 (DSN)SQL を、ローカル マシンのオペレーティング システムに基づいて、リモート クラスタリングまたは 、macOS、 またはWindowsLinux の ウェアハウスに設定します。
-
コンソール([表示]>[フォーカスをコンソールに移動])から、 ODBC次のRStudio から パッケージとDBI パッケージをインストールします。CRAN
Rrequire(devtools)
install_version(
package = "odbc",
repos = "http://cran.us.r-project.org"
)
install_version(
package = "DBI",
repos = "http://cran.us.r-project.org"
) -
R スクリプト ( [表示] > [フォーカスをソースに移動 ]) に戻り、インストールされている
odbcパッケージとDBIパッケージを読み込みます。Rlibrary(odbc)
library(DBI) -
DBIパッケージ内の ODBC バージョンの dbConnect 関数を呼び出します。このとき、odbcパッケージ内のodbcIBM ドライバと、作成した ODBC DSN を指定します。たとえば、Databricksの ODBC DSN を指定します。Rconn = dbConnect(
drv = odbc(),
dsn = "Databricks"
) -
ODBC DSN を使用して操作を呼び出し、たとえば、
DBIパッケージ内の dbGetQuery 関数を使用してSELECTステートメントを呼び出し、接続変数の名前とSELECTステートメント自体を指定します。たとえば、defaultという名前のスキーマ (データベース) 内のdiamondsという名前のテーブルから)。Rprint(dbGetQuery(conn, "SELECT * FROM default.diamonds LIMIT 2"))
完全な R スクリプトは次のとおりです。
library(odbc)
library(DBI)
conn = dbConnect(
drv = odbc(),
dsn = "Databricks"
)
print(dbGetQuery(conn, "SELECT * FROM default.diamonds LIMIT 2"))
スクリプトを実行するには、ソース ビューで [ソース ] をクリックします。 上記の R スクリプトの結果は次のとおりです。
_c0 carat cut color clarity depth table price x y z
1 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
Databricks でホストされている RStudio サーバーに接続する
Databricks でホストされる RStudio サーバーは 非推奨 であり、Databricks Runtime バージョン 15.4 以前でのみ使用できます。
Web ブラウザーを使用して Databricks ワークスペースにサインインし、そのワークスペースに RStudio Server がインストールされているDatabricks コンピュートに接続します。
詳細については、「Databricksでホストされている RStudio サーバーに接続する」を参照してください
RStudio 統合アーキテクチャ
で RStudioServerDatabricks を使用すると、RStudio クラスターのドライバノードで Server Daemon が実行されます。DatabricksRStudio Web UI は Databricks Web アプリを介してプロキシされるため、クラスター ネットワーク構成を変更する必要はありません。この図は、RStudio 統合コンポーネントのアーキテクチャを示しています。
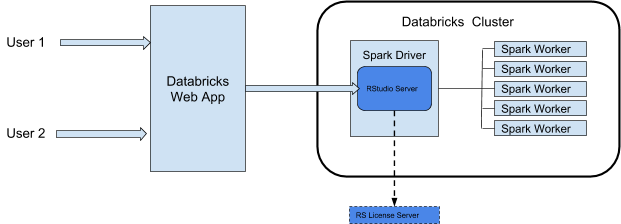
DatabricksRStudioは、クラスタリングの ドライバーのポート 8787 から Web サービスをプロキシします。Sparkこの Web プロキシは、RStudio での使用のみを目的としています。ポート 8787 で他の Web サービスを起動すると、ユーザーが潜在的なセキュリティの悪用にさらされる可能性があります。Databricks は、サポートされていないソフトウェアをクラスタリングにインストールしたことに起因する問題について責任を負いません。
必要条件
-
クラスターは汎用クラスターである必要があります。
-
そのクラスターに対する Can Attach To 権限が必要です。 クラスター管理者は、この権限を付与できます。 「コンピュートの権限」を参照してください。
-
クラスターでは、 テーブルアクセスコントロール 、自動終了 、または資格情報のパススルーを有効にし ないでください 。
-
クラスターでは 、標準 アクセス・モード を使用しないでください 。
-
クラスターでは、Spark構成 に設定し ないでください
spark.databricks.pyspark.enableProcessIsolationtrue。 -
Proエディションを使用するには、RStudio ServerフローティングProライセンスが必要です。
クラスターでは をサポートするアクセス モード Unity CatalogRStudioを使用できますが、そのクラスターの Server を使用してUnity Catalog のデータにアクセスすることはできません。
はじめに: RStudio Server OS Edition
RStudioServer オープンソース Edition は、Databricks Databricks Runtimefor Machine Learning () を使用する クラスターにプリインストールされています。Databricks RuntimeML
クラスターで RStudio Server OS Edition を開くには、次の操作を行います。
-
クラスタリングの詳細ページを開きます。
-
クラスターを開始し、[ Apps ] タブをクリックします。
-
[アプリ ] タブで、[ RStudio のセットアップ ] ボタンをクリックします。これにより、ワンタイムパスワードが生成されます。 表示 リンクをクリックして表示し、パスワードをコピーします。
-
[ RStudio を開く ] リンクをクリックして、UI を新しいタブで開きます。 ログインフォームにユーザー名とパスワードを入力し、サインインします。
-
RStudio UI から、
SparkRパッケージをインポートし、クラスターで Spark ジョブを起動するためのSparkRセッションを設定できます。Rlibrary(SparkR)
sparkR.session()
# Query the first two rows of a table named "diamonds" in a
# schema (database) named "default" and display the query result.
df <- SparkR::sql("SELECT * FROM default.diamonds LIMIT 2")
showDF(df)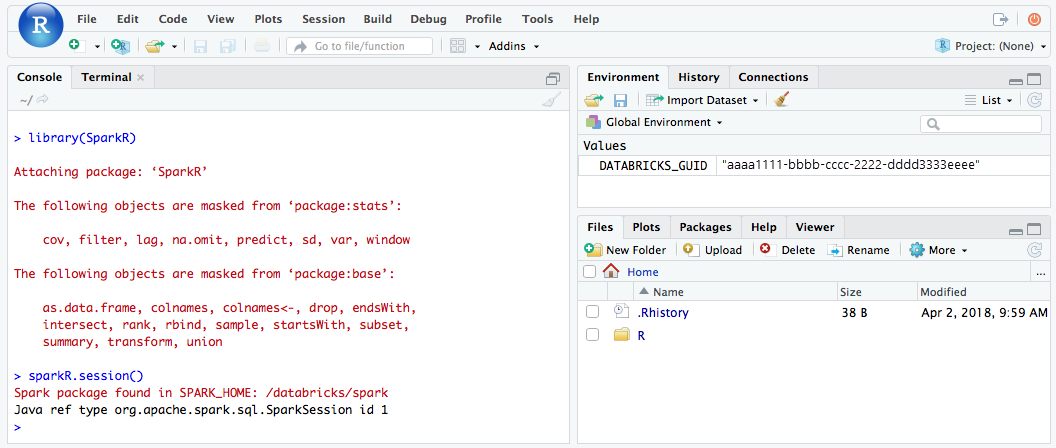
-
Sparklyr パッケージをアタッチして、Spark接続を設定することもできます。
Rlibrary(sparklyr)
sc <- spark_connect(method = "databricks")
# Query a table named "diamonds" and display the first two rows.
df <- spark_read_table(sc = sc, name = "diamonds")
print(x = df, n = 2)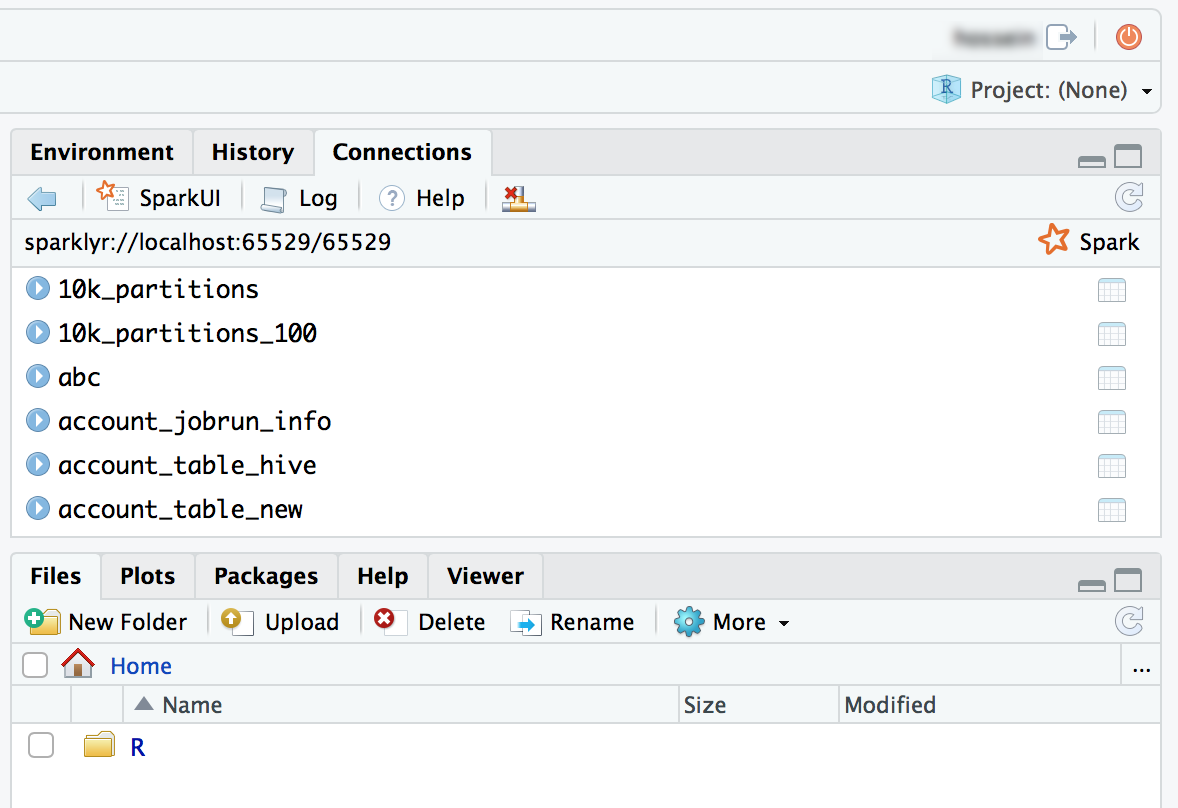
はじめに: RStudio Workbench
このセクションでは、RStudio RStudioDatabricksクラスターで Workbench (旧称 Server Pro) を設定して使用を開始する方法について説明します。ライセンスによっては、RStudio Workbench に RStudio Server Pro が含まれている場合があります。
RStudio ライセンス サーバーのセットアップ
Databricks で RStudio Workbench を使用するには、Pro ライセンスをフローティング ライセンスに変換する必要があります。サポートが必要な場合は、 help@rstudio.comまでお問い合わせください。ライセンスを変換する場合は、RStudio Workbench のライセンス サーバーを設定する必要があります。
ライセンスサーバーを設定するには:
- クラウドプロバイダーネットワーク上で小さなインスタンスを起動します。ライセンスサーバーデーモンは非常に軽量です。
- 対応するバージョンの RStudio License Server をインスタンスにダウンロードしてインストールし、サービスを開始します。 詳細な手順については、「 RStudio Workbench 管理ガイド」を参照してください。
- ライセンス サーバー ポートが Databricks インスタンスに対して開いていることを確認します。
RStudio Workbench のインストール
RStudioDatabricksクラスターで Workbenchを設定するには、initスクリプトを作成してRStudio Workbenchバイナリパッケージをインストールし、ライセンスサーバーをライセンスリースに使用するように構成する必要があります。
すでに RStudio Server オープンソース Edition パッケージが含まれている Databricks Runtime バージョンに RStudio Workbench をインストールする予定の場合、インストールを成功させるには、まずそのパッケージをアンインストールする必要があります。
以下は、ワークスペースファイルとしてホームディレクトリ、 Unity Catalog ボリューム、オブジェクトストレージなどの場所にinitスクリプトとして保存できる.shファイルの例です。 詳細については、 クラスター-scoped initスクリプトを参照してください。 このスクリプトは、Databricks との統合を効率化する追加の認証構成も実行します。
クラスター-scoped initスクリプトはサポート終了 DBFS 。 initスクリプトを DBFS に保存することは、レガシーワークロードをサポートするために一部のワークスペースに存在するため、推奨されません。 DBFSに保存されているすべてのinitスクリプトを移行する必要があります。移行手順については、 DBFSからの initスクリプトの移行を参照してください。
#!/bin/bash
set -euxo pipefail
if [[ $DB_IS_DRIVER = "TRUE" ]]; then
sudo apt-get update
sudo dpkg --purge rstudio-server # in case open source version is installed.
sudo apt-get install -y gdebi-core alien
## Installing RStudio Workbench
cd /tmp
# You can find new releases at https://rstudio.com/products/rstudio/download-commercial/debian-ubuntu/.
wget https://download2.rstudio.org/server/bionic/amd64/rstudio-workbench-2022.02.1-461.pro1-amd64.deb -O rstudio-workbench.deb
sudo gdebi -n rstudio-workbench.deb
## Configuring authentication
sudo echo 'auth-proxy=1' >> /etc/rstudio/rserver.conf
sudo echo 'auth-proxy-user-header-rewrite=^(.*)$ $1' >> /etc/rstudio/rserver.conf
sudo echo 'auth-proxy-sign-in-url=<domain>/login.html' >> /etc/rstudio/rserver.conf
sudo echo 'admin-enabled=1' >> /etc/rstudio/rserver.conf
sudo echo 'export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin' >> /etc/rstudio/rsession-profile
# Enabling floating license
sudo echo 'server-license-type=remote' >> /etc/rstudio/rserver.conf
# Session configurations
sudo echo 'session-rprofile-on-resume-default=1' >> /etc/rstudio/rsession.conf
sudo echo 'allow-terminal-websockets=0' >> /etc/rstudio/rsession.conf
sudo rstudio-server license-manager license-server <license-server-url>
sudo rstudio-server restart || true
fi
<domain>を Databricks の URL に、<license-server-url>をフローティング ライセンス サーバーの URL に置き換えます。- この
.shファイルをinitスクリプトとして、ホームディレクトリなどの場所にワークスペースファイルとして保存したり、 Unity Catalog ボリュームやオブジェクトストレージに保存したりします。 詳細については、 クラスター-scoped initスクリプトを参照してください。 - クラスターを起動する前に、この
.shファイルを関連付けられた場所からinitスクリプトとして追加します。 手順については、 クラスター-scoped initスクリプトを参照してください。 - クラスターを起動します。
RStudio Server Pro を使用する
-
クラスタリングの詳細ページを開きます。
-
クラスターを開始し、[ Apps ] タブをクリックします。
-
[アプリ ] タブで、[ RStudio のセットアップ ] ボタンをクリックします。
-
ワンタイムパスワードは必要ありません。 [ RStudio UI を開く ] リンクをクリックすると、認証された RStudio Pro セッションが開きます。
-
RStudio UI から、
SparkRパッケージをアタッチし、クラスターでジョブを起動するためのSparkRセッションSpark設定できます。Rlibrary(SparkR)
sparkR.session()
# Query the first two rows of a table named "diamonds" in a
# schema (database) named "default" and display the query result.
df <- SparkR::sql("SELECT * FROM default.diamonds LIMIT 2")
showDF(df)
-
Sparklyr パッケージをアタッチして、Spark接続を設定することもできます。
Rlibrary(sparklyr)
sc <- spark_connect(method = "databricks")
# Query a table named "diamonds" and display the first two rows.
df <- spark_read_table(sc = sc, name = "diamonds")
print(x = df, n = 2)
RStudio サーバーに関する FAQ
RStudio Server オープンソース エディションと RStudio Workbench の違いは何ですか?
RStudio Workbenchは、オープンソースエディションでは利用できない幅広いエンタープライズ機能をサポートしています。 機能の比較は 、RStudioのWebサイトで確認できます。
また、 RStudio Server オープンソース エディションは GNU Affero General Public License (AGPL) の下で配布されていますが、Pro バージョンには AGPL ソフトウェアを使用できない組織向けの商用ライセンスが付属しています。
最後に、 RStudio Workbenchには、 RStudio、PBCのプロフェッショナルおよびエンタープライズサポートが付属していますが、 RStudio Server オープンソースエディションにはサポートがありません。
RStudio Workbench / RStudio Server Pro ライセンスを Databricks で使用できますか?
はい、RStudio Server の Pro または Enterprise ライセンスを既にお持ちの場合は、そのライセンスを Databricks で使用できます。 Databricks で RStudio Workbench を設定する方法については、「 作業の開始: RStudio Workbench 」を参照してください。
RStudio Serverはどこで実行されますか?追加のサービス/サーバーを管理する必要がありますか?
RStudio統合アーキテクチャの図でわかるように、RStudio Server デーモンは Databricks クラスターのドライバー (マスター) ノードで実行されます。RStudio Server オープンソース エディションでは、追加のサーバー/サービスを実行する必要はありません。ただし、RStudio Workbench の場合は、RStudio ライセンス サーバーを実行する別のインスタンスを管理する必要があります。
RStudio Serverを標準クラスターで使用できますか?
この記事では、従来のクラスター UI について説明します。 クラスター アクセス モードの用語の変更など、新しいクラスター UI (プレビュー段階) に関する情報については、「 コンピュート構成リファレンス」を参照してください。 新しいクラスター タイプと従来のクラスター タイプの比較については、「 クラスター UI の変更」と「クラスター アクセス モード」を参照してください。
はい、できます。
RStudio Serverを自動終了のクラスターで使用できますか?
いいえ、自動終了が有効になっている場合は RStudio を使用できません。自動終了では、RStudio セッション内の保存されていないユーザー スクリプトとデータを消去できます。この意図しないデータ損失シナリオからユーザーを保護するために、このようなクラスタリングでは RStudio がデフォルトによって無効になっています。
クラスター リソースを使用しないときにクリーンアップする必要があるお客様には、DatabricksクラスターAPI リソース を使用して、スケジュールに基づいてRStudio クラスターをクリーンアップすることをお勧めします。
RStudio で作業をどのように保持する必要がありますか?
RStudio のバージョン管理システムを使用して作業を保持することを強くお勧めします。 RStudio は、さまざまなバージョン管理システムを強力にサポートしており、プロジェクトをチェックインして管理できます。 次のいずれかの方法でコードを保持しないと、ワークスペース管理者がクラスターを再起動または終了すると、作業が失われるリスクがあります。
1 つの方法は、ファイル (コードまたはデータ) を DBFS とは.たとえば、 /dbfs/ の下にファイルを保存した場合、クラスターが終了または再開されても、そのファイルは削除されません。
別の方法は、R ノートブックを Rmarkdownとしてエクスポートしてローカル ファイル システムに保存し、後でファイルを RStudio インスタンスにインポートすることです。 ブログ Sharing R ノートブック using rmarkdown で手順について詳しく説明しています。
別の方法は、 Amazon Elastic File System(Amazon EFS)ボリュームをクラスタリングにマウントして、クラスタリングがシャットダウンされたときに作業が失われないようにすることです。 クラスタリングが再開すると、 Databricks は Amazon EFS ボリュームを再マウントし、中断したところから続行できます。 既存のAmazon EFS ボリュームをクラスタリングにマウントするには、クラスタリングPOST /api/2.0/clusters/createPOST /api/2.0/clusters/editAPI2.0 で create クラスター() または edit クラスター() 操作を呼び出し、操作のAmazon cluster_mount_infosアレイで EFS ボリュームの mount 情報を指定します。
作成または使用するクラスタリングで、 Unity Catalog、自動終了、または自動スケーリングが有効になっていないことを確認します。 また、クラスタリングでコマンド chmod a+w </path/to/volume> を実行するなどして、クラスタリングにマウントされたボリュームへの書き込みアクセス権があることも確認します。 このコマンドは、クラスタリングのWebターミナルを使用して既存のクラスタリングで実行することも、前の操作のinit_scripts配列で指定したinitスクリプトを使用して新しいクラスタリングで実行することもできます。
既存の Amazon EFS ボリュームがない場合は、作成できます。 まず、Databricks 管理者に連絡し、Databricks ワークスペースの VPC ID、パブリック サブネット ID、およびセキュリティ グループ ID を取得します。 次に、この情報と AWS マネジメントコンソール を使用して、 Amazon EFS コンソールを使用してカスタム設定のファイルシステムを作成します。 この手順の最後のステップで、[ アタッチ ] をクリックし、前の cluster_mount_infos アレイで指定した DNS 名とマウント オプションをコピーします。
SparkRセッションを開始するにはどうすればいいですか?
SparkR は Databricks Runtime に含まれていますが、RStudio に読み込む必要があります。 RStudio 内で次のコードを実行して、 SparkR セッションを初期化します。
library(SparkR)
sparkR.session()
SparkRパッケージのインポート中にエラーが発生した場合は、.libPaths()を実行し、結果に/home/ubuntu/databricks/spark/R/libが含まれていることを確認します。
含まれていない場合は、 /usr/lib/R/etc/Rprofile.siteの内容を確認してください。 ドライバーの /home/ubuntu/databricks/spark/R/lib/SparkR を一覧表示して、 SparkR パッケージがインストールされていることを確認します。
sparklyrセッションを開始するにはどうすればいいですか?
sparklyrパッケージは、クラスターにインストールする必要があります。次のいずれかの方法を使用して、 sparklyr パッケージをインストールします。
- Databricks ライブラリとして
install.packages()command- RStudio パッケージ管理 UI
library(sparklyr)
sc <- spark_connect(method = “databricks”)
RStudio は Databricks R ノートブックとどのように統合されますか?
バージョン管理を使用して、ノートブックと RStudio の間で作業を移動できます。
作業ディレクトリとは何ですか?
RStudio でプロジェクトを開始するときは、作業ディレクトリを選択します。 デフォルトでは、これは RStudio Server が実行されているドライバー (マスター) コンテナーのホーム ディレクトリです。 このディレクトリは、必要に応じて変更できます。
Databricks で実行されている RStudio から Shiny アプリを起動できますか?
はい、 Databricks の RStudio Server 内で Shiny アプリケーションを開発および表示できます。
DatabricksのRStudio内でターミナルまたはgitを使用できません。どうすればそれを修正できますか?
WebSocketが無効になっていることを確認します。 RStudio Server オープンソース エディションでは、UI からこれを行うことができます。
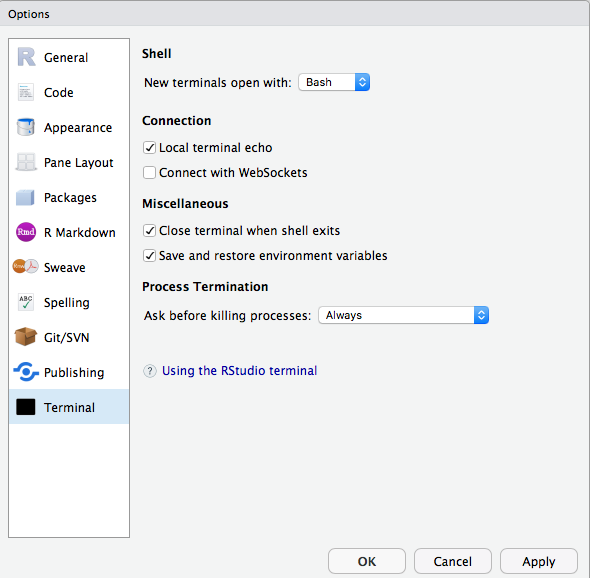
RStudio Server Pro では、/etc/rstudio/rsession.conf に allow-terminal-websockets=0 を追加して、すべてのユーザーに対して WebSocket を無効にすることができます。
クラスタリングの詳細の下に [アプリ] タブが表示されません。
この機能は、すべてのお客様が利用できるわけではありません。 プレミアムプラン以上である必要があります。