情報抽出を使用する (レガシー)
ベータ版
この機能はベータ版です。ワークスペース管理者は、 プレビュー ページからこの機能へのアクセスを制御できます。Databricksのプレビューを管理するを参照してください。
このページでは、情報の抽出の旧バージョンについて説明します。Databricksでは、最新バージョンの使用をお勧めします。情報の抽出を参照してください。
このページでは、情報抽出用の生成AIエージェントを作成する方法について説明します。
情報抽出とは何ですか?
情報抽出は、情報の抽出をサポートし、大量のラベル付けされていないテキストドキュメントを、各ドキュメントから抽出された情報を含む構造化されたテーブルに変換するプロセスを簡素化します。
情報抽出の例:
- 契約から価格とリース情報を抽出します。
- 顧客のメモからデータを整理する。
- ニュース記事から重要な詳細を取得する。
情報抽出は、MLflowやAgent Evaluationなどの自動評価機能を活用して、特定の抽出タスクにおけるコストと品質のトレードオフを迅速に評価できます。この評価により、精度とリソース投資のバランスについて、情報に基づいた意思決定を行うことができます。
情報抽出は、各エージェントを動かす一時的なデータ変換、モデルチェックポイント、および内部メタデータを保存するために、デフォルトストレージを使用します。エージェントが削除されると、エージェントに関連付けられているすべてのデータはデフォルトのストレージから削除されます。
要件
-
以下を含むワークスペースです。
- サーバレスコンピュートが利用可能です(Unity Catalogが有効なワークスペースではデフォルトで有効になっています)。
- Unity Catalogが有効です。「Unity Catalog のワークスペースを有効にする」を参照してください。
system.aiスキーマを介した Unity Catalog における基盤モデルへのアクセス- ゼロ以外の予算を持つサーバレス利用ポリシーへのアクセス。
-
サポートされているいずれかのリージョンにあるワークスペース。
-
ai_querySQL関数を使用できます。 -
データを抽出したいファイルです。ファイルはUnity Catalogボリュームまたはテーブルに存在する必要があります。
- PDFを使用する場合は、まずそれらをUnity Catalogテーブルに変換してください。「情報抽出でPDFを使用する」を参照してください。
- エージェントを構築するには、Unity Catalog ボリュームに少なくとも1つのラベルなしドキュメント、またはテーブルに1行が必要です。
情報抽出エージェントを作成
ワークスペースの左側のナビゲーションペインで、![]() エージェント に移動します。 情報抽出 タイルから、 ビルド をクリックします。
エージェント に移動します。 情報抽出 タイルから、 ビルド をクリックします。
ステップ1:エージェントを構成します
エージェントを設定します:
-
名前 フィールドに、エージェントの名前を入力します。
-
提供するデータのタイプを選択します。「 ラベルなしのデータセット 」または「 ラベル付きデータセット 」のどちらかを選択できます。
-
提供するデータセットを選択してください。
- Unlabeled dataset
- Labeled dataset
**ラベルなしデータセット**を選択した場合:
-
データセットの場所 フィールドで、Unity Catalogボリュームから使用したいフォルダーまたはテーブルを選択します。フォルダーを選択した場合、そのフォルダーにはサポートされているドキュメント形式のドキュメントが含まれている必要があります。
以下はボリュームの例です。
/Volumes/main/info-extraction/bbc_articles/ -
テーブルを提供する場合、ドロップダウンからテキストデータを含む列を選択します。テーブル列には、サポートされているデータ形式のデータを含める必要があります。
PDFを使用する場合は、まずそれらをUnity Catalogテーブルに変換してください。「情報抽出でPDFを使用する」を参照してください。
-
情報抽出は、**サンプル JSON 出力**フィールドに、データセットから抽出されたデータを含むサンプル JSON 出力を自動的に推論し生成します。サンプル出力を受け入れるか、編集するか、または希望するJSON出力の例に置き換えることができます。エージェントは抽出された情報をこの形式を使用して返します。
ラベル付きデータセット を選択した場合は、
- 「 正解データセット 」フィールドで、正解データを含むUnity Catalogテーブルを選択します。
- 入力列 フィールドで、エージェントが処理するテキストを含む列を選択します。この列のデータは
str形式である必要があります。 - **正解応答列**フィールドで、期待される理想的な応答を含む列を選択してください。この列のデータはJSON文字列である必要があります。この列の各行は、同じJSON形式に従う必要があります。追加または欠落したキーを含む行は受け入れられません。
- 「 サンプルJSON出力 」フィールドでは、情報抽出によって、グラウンドトゥルス応答列のデータの最初の行を使用してサンプルJSON出力が自動的に生成されます。このJSON出力が期待される形式と一致することを確認します。
-
サンプルJSON出力 フィールドが、希望する応答形式と一致することを確認してください。必要に応じて編集します。
たとえば、一連のニュース記事から情報を抽出するために、次のサンプルJSON出力が使用できます。
JSON{
"title": "Economy Slides to Recession",
"category": "Politics",
"paragraphs": [
{
"summary": "GDP fell by 0.1% in the last three months of 2004.",
"word_count": 38
},
{
"summary": "Consumer spending had been depressed by one-off factors such as the unseasonably mild winter.",
"word_count": 42
}
],
"tags": ["Recession", "Economy", "Consumer Spending"],
"estimate_time_to_read_min": 1,
"published_date": "2005-01-15",
"needs_review": false
} -
**モデル選択**で、情報抽出エージェントに最適なモデルを選択してください。
- 「**スケールに合わせて最適化**」(デフォルト):大量のデータを処理している場合、または費用対効果の高いエージェントを希望する場合は、このオプションを選択します。このモデルは、高スループットと迅速なターンアラウンドタイムを実現するように設計されており、ほとんどの情報抽出タスクに適しています。
- 複雑性の最適化 :複雑な推論が必要で、速度やコストよりも精度を優先する場合は、このオプションを選択してください。このモデルは、長いドキュメント(財務書類など)に対してより高度な推論機能を提供し、より複雑な抽出(40以上のスキーマフィールドの抽出など)を処理できます。
-
エージェントの作成 をクリックします。
サポートされているドキュメント形式
次の表は、Unity Catalogボリュームを指定する場合のソースドキュメントにサポートされているドキュメントファイルタイプを示します。
コードファイル | ドキュメントファイル | ログファイル。 |
|---|---|---|
|
|
|
サポートされているデータ形式
Unity Catalog テーブルを提供する場合、情報抽出はソースドキュメントに対して次のデータ型とスキーマをサポートしています。情報抽出は、これらのデータ型を各ドキュメントから抽出することもできます。
strintfloatbooleanenum(エージェントが事前に定義されたカテゴリからのみ選択する必要がある分類タスクに使用されます)- オブジェクト
- 配列
enum (事前定義されたカテゴリのセットからのみエージェントに出力させたい分類タスクに適しています) object (「カスタムネストされたフィールド」の代わりとして) array
ステップ2: エージェントを改善する
ビルド タブでサンプル出力を確認し、スキーマ定義の調整と、より良い結果を得るための指示の追加に役立ててください。
-
左側でサンプル応答を確認し、エージェントを調整するためのフィードバックを提供してください。これらのサンプルは、現在のエージェント構成に基づいています。
- 完全な入力と応答を確認するには、行をクリックします。
- 下部にある[**この応答は正しいですか?**]の横で、[**

 はい**] または [** 修正**] を選択してフィードバックを提供します。 [**修正**] フィードバックについては、エージェントが応答をどのように変更すべきかについて詳細を提供し、[**
はい**] または [** 修正**] を選択してフィードバックを提供します。 [**修正**] フィードバックについては、エージェントが応答をどのように変更すべきかについて詳細を提供し、[**  保存**] をクリックします。
保存**] をクリックします。 - すべての応答のレビューが完了したら、「** はい、エージェントを更新**」をクリックします。または、3つ以上の応答をレビューした後、「**フィードバックを保存して更新**」をクリックします。
-
右側の**出力フィールド**の下で、抽出スキーマフィールドの説明を絞り込んでください。これらの説明は、エージェントが抽出したい内容を理解するために依存するものです。左側のサンプル応答を参考にして、スキーマ定義を絞り込んでください。
- 各フィールドについて、必要に応じてスキーマ定義を確認および編集します。左側のサンプル応答を使用して、これらの説明を調整してください。
- フィールド名とタイプを編集するには、
 フィールドを編集 をクリックします。
フィールドを編集 をクリックします。 - 新しいフィールドを追加するには、
 [新しいフィールドを追加] をクリックします。名前、タイプ、説明を入力し、 [確認] をクリックしてください。
[新しいフィールドを追加] をクリックします。名前、タイプ、説明を入力し、 [確認] をクリックしてください。 - フィールドを削除するには、
 フィールドを削除 をクリックします。
フィールドを削除 をクリックします。 - エージェント設定を更新するには、 保存して更新 をクリックしてください。
-
(オプション)右側の**[指示]**の下で、エージェントへのグローバル指示を入力します。これらの指示は、抽出されたすべての要素に適用されます。「**保存して更新**」をクリックして、指示を適用します。
-
新しいサンプル応答が左側に生成されます。これらの更新された応答を確認し、応答が満足できるものになるまでエージェント構成を引き続き調整してください。
ステップ 3: エージェントを使用する
Databricksのワークフロー全体でエージェントを使用できます。
エージェントの使用を開始するには、 「使用」 をクリックします。エージェントはいくつかの方法で使用できます。
- すべてのドキュメントのデータを抽出 : 抽出を開始 をクリックしてSQLエディターを開き、
ai_queryを使用して新しい情報抽出エージェントにリクエストを送信してください。 - ETLパイプラインの作成 : 「パイプラインの作成」 をクリックして、スケジュールされた間隔で実行されるパイプラインをデプロイし、新しいデータでエージェントを使用します。パイプラインの詳細については、「Spark宣言型パイプライン」を参照してください。
- エージェントのテスト : [Playground で開く] をクリックして、テスト環境でエージェントを試し、その動作を確認してください。AI Playground の詳細については、AI Playgroundを使用したLLM とのチャットおよび生成AI アプリのプロトタイピングを参照してください。
(オプション) ステップ 4: エージェントを評価
高品質のエージェントを構築したことを確認するには、評価を実行し、結果の品質レポートを確認してください。
-
品質 タブに切り替えてください。
-
**
評価を実行**をクリックします。 -
スライドアウトする「 新しい評価 」ペインで、評価を構成します。
- 評価実行名を選択してください。生成された名前を使用するか、カスタム名を提供するかを選択できます。
- 評価データセットを選択します。エージェントの構築に使用されたのと同じソースデータセットを使用するか、ラベル付きまたはラベルなしのデータを使用してカスタム評価データセットを提供するかを選択できます。
-
評価を開始 をクリックします。
-
評価の実行が完了した後、品質レポートを確認します:
-
サマリー ビューがデフォルトで表示されます。評価メトリクスの全体的な品質、コスト、スループット、およびサマリーレポートを確認してください。スキーマフィールドの横にある
 をクリックして、そのフィールドがどのように評価されるかを確認してください。
をクリックして、そのフィールドがどのように評価されるかを確認してください。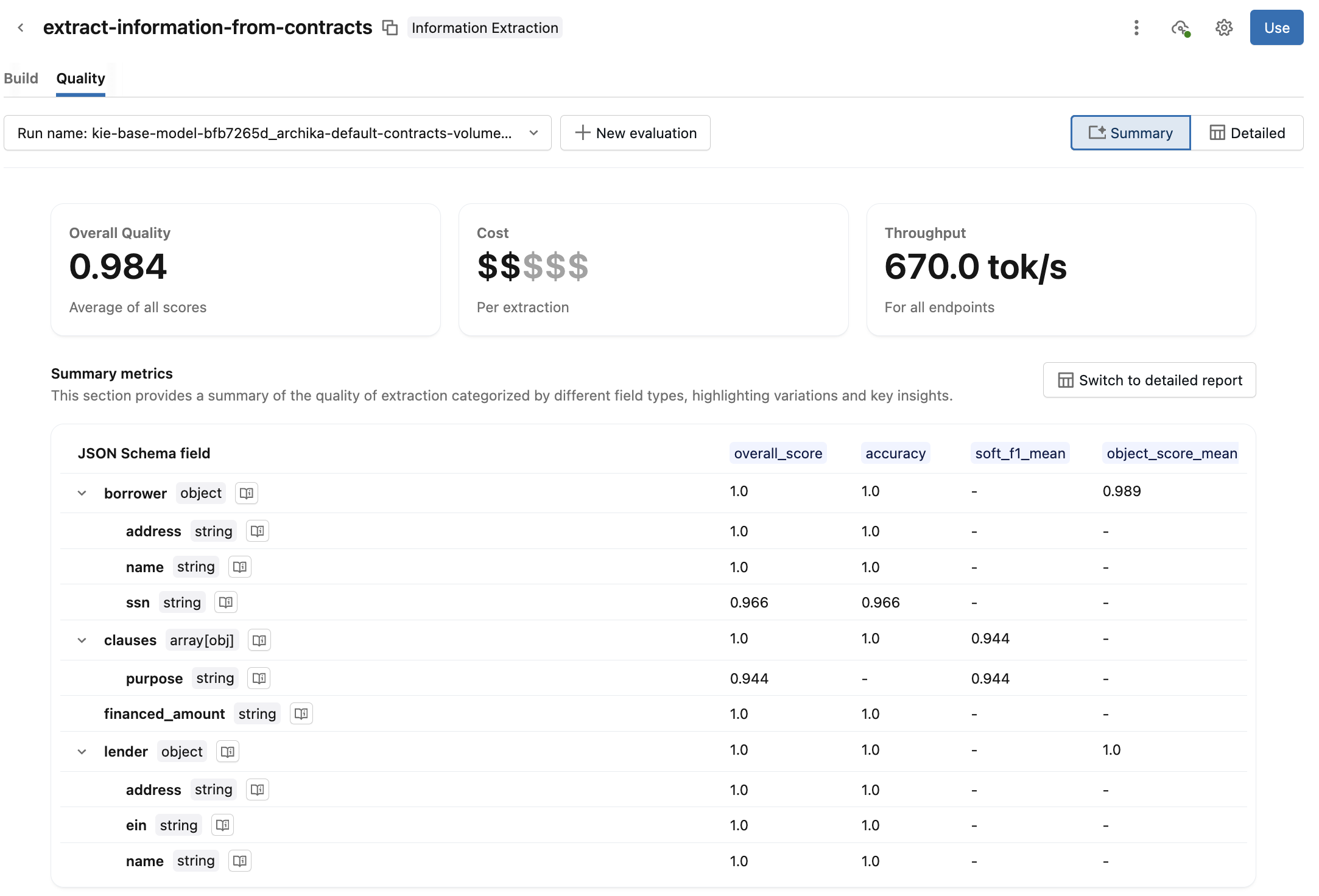
-
詳細については、 詳細 ビューに切り替えてください。このビューには、各リクエストと各メトリクスの評価スコアが表示されます。リクエストをクリックすると、入力、出力、評価、トレース、リンクされたプロンプトなどの詳細情報を確認できます。リクエストの評価を編集したり、追加のフィードバックを提供することもできます。
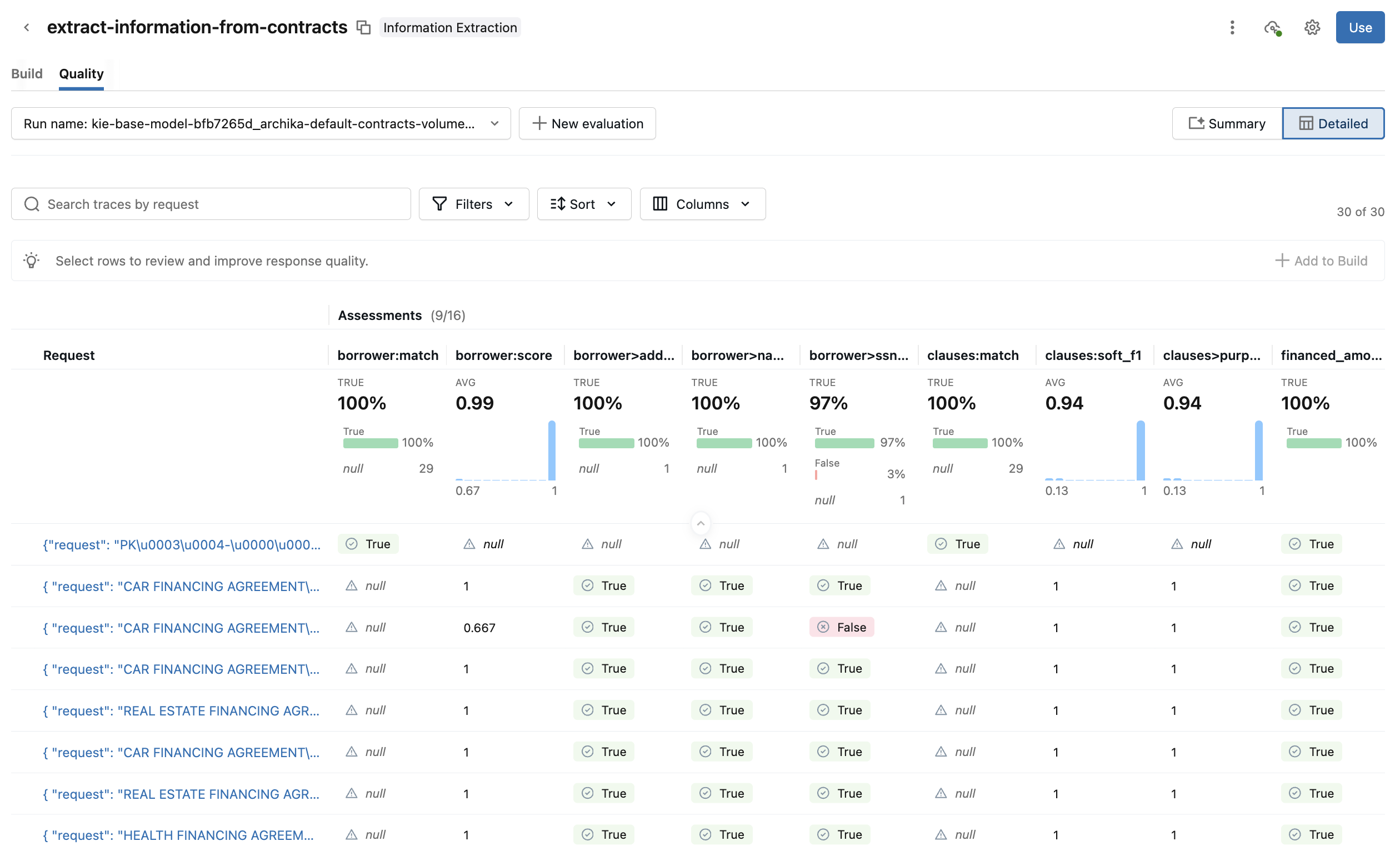
-
エージェントエンドポイントをクエリする
エージェントページで、右上の ![]() エージェント ステータス を参照して、デプロイされたエージェント エンドポイントを取得し、エンドポイントの詳細を確認します。
エージェント ステータス を参照して、デプロイされたエージェント エンドポイントを取得し、エンドポイントの詳細を確認します。
作成されたエージェントエンドポイントをクエリする方法は複数あります。AI Playground で提供されているコード例を開始点として使用してください。
- エージェントページで、 使用 をクリックします。
- **Playgroundで開く**をクリックします。
- Playground から コードを取得 をクリックします。
- エンドポイントの使用方法を選択してください:
- データに適用 を選択して、エージェントを特定のテーブル列に適用する SQL クエリを作成します。
- curl を使用してエンドポイントをクエリするコード例として、 Curl API を選択します。
- Pythonを使用してエンドポイントを操作するコード例については、 Python API を選択してください。
権限を管理します。
デフォルトでは、エージェントの作成者とワークスペースの管理者のみがエージェントに対する権限を持っています。他のユーザーがエージェントを編集またはクエリできるようにするには、明示的に権限を付与する必要があります。
エージェントの権限を管理するには:
-
[**エージェント**] ページで、エージェントを開きます。
-
上部の
 ケバブメニューをクリックします。
ケバブメニューをクリックします。 -
[アクセス許可を管理] をクリックします。
-
**権限設定** ウィンドウで、ユーザー、グループ、またはサービスプリンシパルを選択します。
-
付与する権限を選択してください:
- 管理可能 : 権限の設定、エージェント構成の編集、品質の向上など、エージェントの管理が可能です。
- クエリ可能 : AI Playgroundで、およびAPIを介してエージェントエンドポイントをクエリできます。このアクセス許可を持つユーザーのみが、エージェントページでエージェントを表示または編集できません。
-
[ 追加 ] をクリックします。
-
保存 をクリックします。
2025年9月16日より前に作成されたエージェントエンドポイントの場合、**サービングエンドポイント**ページからエンドポイントに**クエリ可能**のアクセス許可を付与できます。
情報抽出でPDFを使用します。
情報抽出とカスタムLLMでは、PDFはまだネイティブにサポートされていません。ただし、UIワークフローを使用してPDFファイルのフォルダをマークダウンに変換し、エージェントを構築する際に結果のUnity Catalogテーブルを入力として使用できます。このワークフローは、変換にai_parse_documentを使用します。以下のステップに従ってください:
-
左側のナビゲーションペインで エージェント をクリックします。
-
情報抽出またはカスタム LLM ユースケースで、 [PDF の使用] をクリックします。
-
開いたサイドパネルで、PDFを変換する新しいワークフローを作成するために、以下のフィールドを入力してください:
- PDF または画像を含むフォルダーを選択 :使用する PDF を含む Unity Catalog フォルダーを選択します。
- 宛先テーブルを選択 :変換されたマークダウンテーブルの宛先スキーマを選択し、必要に応じて下のフィールドでテーブル名を調整します。
- SQLウェアハウスの選択 : ワークフローを実行するSQLウェアハウスを選択します。
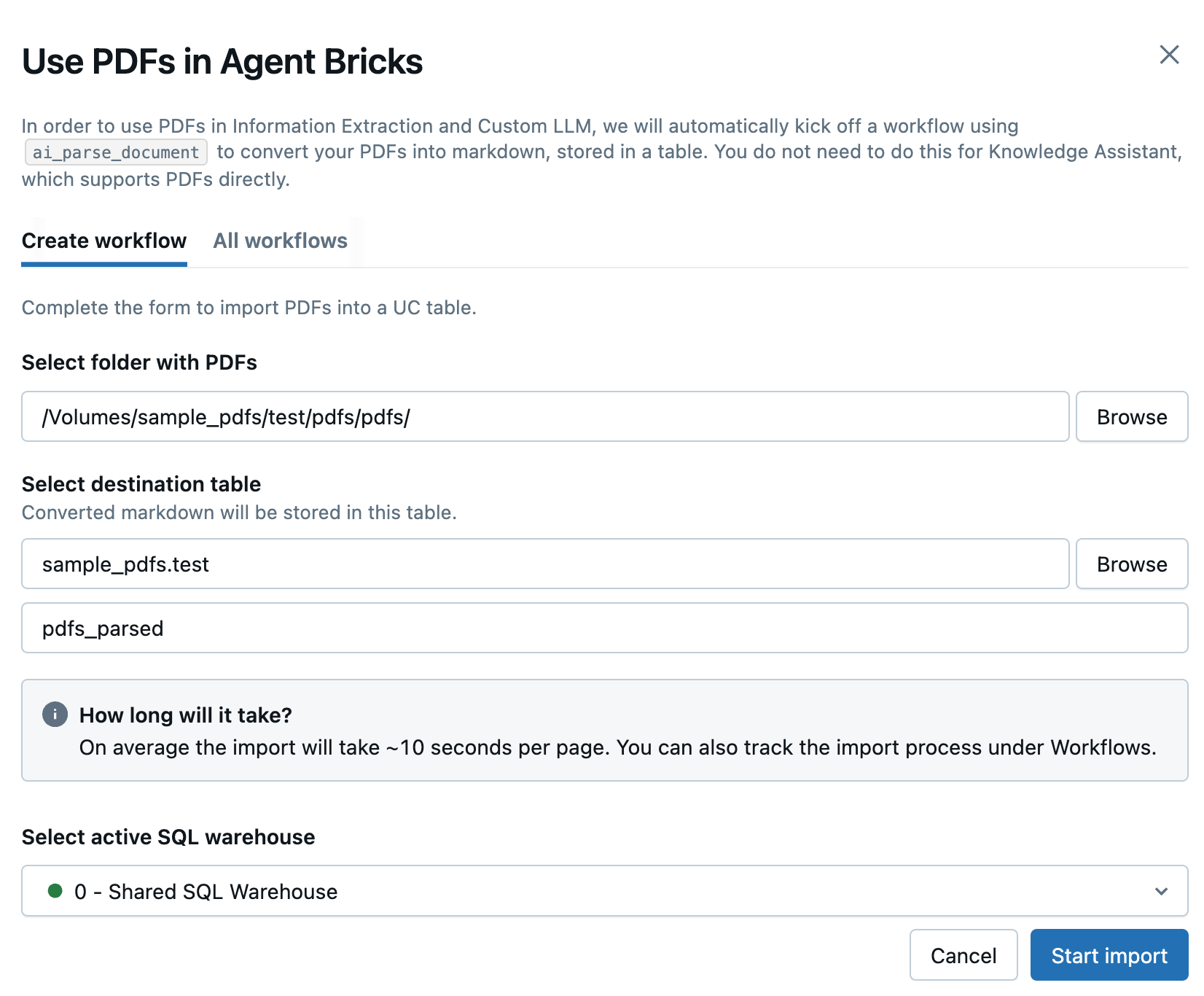
-
インポートの開始 をクリックします。
-
「 すべてのワークフロー 」タブにリダイレクトされ、すべてのPDFワークフローが表示されます。このタブを使用して、ジョブのステータスをモニタリングします。
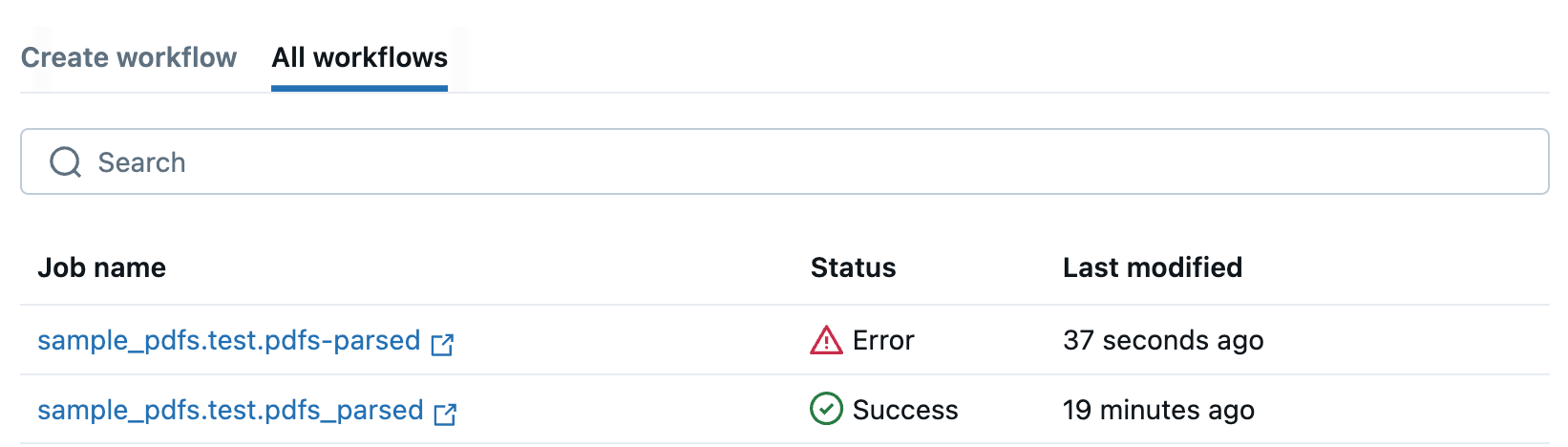
ワークフローが失敗した場合は、ジョブ名をクリックして開き、デバッグに役立つエラーメッセージを確認します。
-
ワークフローが正常に完了したら、ジョブ名をクリックしてカタログエクスプローラでテーブルを開き、列を調査し、理解します。
-
エージェントを構成する際は、Unity Catalogテーブルを入力データとして使用してください。
制限事項
- 情報抽出エージェントの最大コンテキスト長は128kトークンです。
- 拡張セキュリティとコンプライアンスが有効になっているワークスペースはサポートされていません。
- 共用スキーマタイプはサポートされていません。