Databricks でジェンキンスとCI/CD
注
この記事では、サードパーティによって開発された Jenkins について説明します。 プロバイダーに問い合わせるには、 Jenkins ヘルプを参照してください。
CI/CD パイプラインを管理および実行するために使用できる CI/CD ツールは数多くあります。 この記事では、 Jenkins 自動化サーバーの使用方法について説明します。 CI/CD設計パターンであるため、この記事で概説したステップとステージは、各ツールのパイプライン定義言語にいくつかの変更を加えて移行する必要があります。 さらに、このサンプル パイプラインのコードの多くは標準の Python コードを実行し、他のツールで呼び出すことができます。 Databricks 上の CI/CD の概要については、 「Databricks 上の CI/CD とは」を参照してください。
CI/CD 開発ワークフロー
Databricks では、Jenkins を使用した CI/CD 開発について、次のワークフローを提案しています。
リポジトリを作成するか、既存のリポジトリを使用して、サードパーティの Git プロバイダーを使用します。
ローカル開発マシンを同じサードパーティリポジトリに接続します。 手順については、サードパーティの Git プロバイダーのドキュメントを参照してください。
既存の更新された成果物 (ノートブック、コード ファイル、ビルド スクリプトなど) をサードパーティのリポジトリからローカルの開発マシンにプルします。
必要に応じて、ローカル開発マシンで成果物を作成、更新、およびテストします。 次に、新しいアーティファクトと変更されたアーティファクトをローカル開発マシンからサードパーティのリポジトリにプッシュします。 手順については、サードパーティの Git プロバイダーのドキュメントを参照してください。
必要に応じて、手順 3 と 4 を繰り返します。
Jenkins は、サードパーティのリポジトリからローカル開発マシンまたは Databricks ワークスペースに成果物を自動的にプルするための統合アプローチとして定期的に使用します。ローカル開発マシンまたは Databricks ワークスペースでのコードのビルド、テスト、および実行。テストと実行の結果を報告します。 Jenkins は手動で実行できますが、実際の実装では、リポジトリのプルリクエストなどの特定のイベントが発生するたびに Jenkins を実行するようにサードパーティの Git プロバイダーに指示します。
この記事の残りの部分では、サンプル プロジェクトを使用して、Jenkins を使用して前述の CI/CD 開発ワークフローを実装する 1 つの方法について説明します。
ローカル開発マシンのセットアップ
この記事の例では、Jenkins を使用して、 Databricks CLI と Databricks アセット バンドル に次の操作を行うように指示します。
ローカル開発マシン上でPython wheelファイルをビルドします。
ビルドされたPython wheelファイルを、追加のPythonファイルおよびPythonノートブックとともにローカル開発マシンからDatabricksワークスペースにデプロイします。
アップロードしたPython wheelファイルとノートブックをそのワークスペースでテストして実行します。
この例のビルド ステージとアップロード ステージを実行するように Databricks ワークスペースに指示するようにローカル開発マシンを設定するには、ローカル開発マシンで次の手順を実行します。
手順 1: 必要なツールをインストールする
この手順では、Databricks CLI、Jenkins、jq、および Python wheel ビルド ツールをローカル開発コンピューターにインストールします。 この例を実行するには、これらのツールが必要です。
Databricks CLI バージョン 0.205 以降をまだインストールしていない場合は、インストールします。 Jenkins は Databricks CLI を使用して、この例のテストと実行の手順をワークスペースに渡します。 「Databricks CLI のインストールまたは更新」を参照してください。
Jenkins をまだインストールしていない場合は、インストールして起動します。 「Linux 、 macOS 、または Windows 用の Jenkins のインストール 」を参照してください。
jq をインストールします。 この例では、
jqを使用して JSON 形式のコマンド出力を解析します。次のコマンドで
pipを使用してPython wheel ビルド ツールをインストールします (システムによっては、pipの代わりにpip3を使用する必要がある場合があります)。pip install --upgrade wheel
ステップ 2: Jenkins パイプラインを作成する
この手順では、Jenkins を使用して、この記事の例の Jenkins パイプラインを作成します。 Jenkins には、CI/CD パイプラインを作成するためのいくつかの異なるプロジェクトの種類が用意されています。 Jenkins パイプラインは、 Groovy コードを使用して Jenkins プラグインを呼び出して構成することにより、Jenkins パイプラインのステージを定義するためのインターフェイスを提供します。
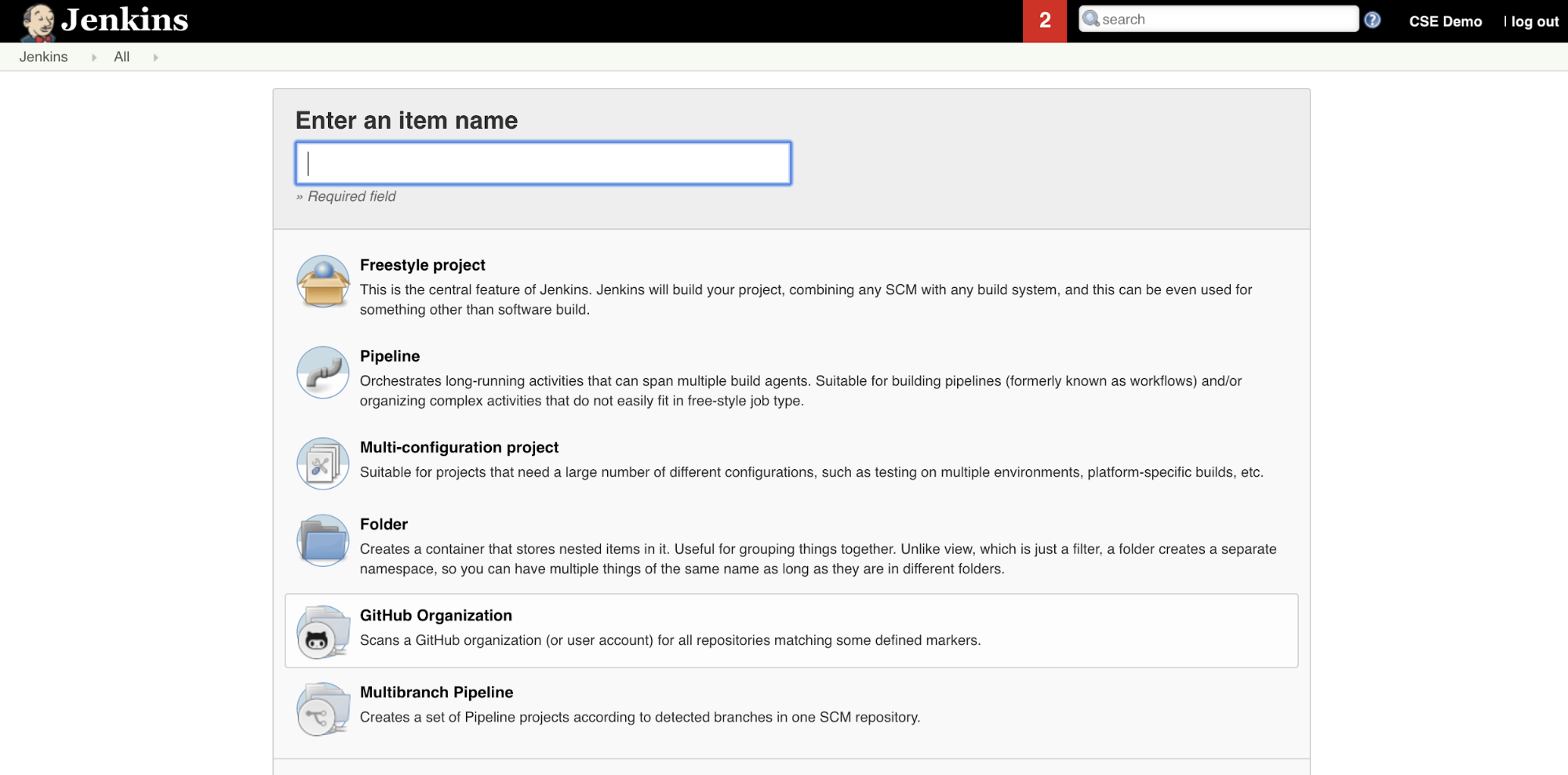
ジェンキンスでジェンキンスパイプラインを作成するには:
Jenkins を起動したら、Jenkins ダッシュボードから [ 新しいアイテム] をクリックします。
[ 項目名を入力してください] に、Jenkins パイプラインの名前を入力します (例:
jenkins-demo)。「パイプライン・プロジェクト ・タイプ」 アイコンをクリックします。
OK をクリックします。Jenkins パイプラインの [ 構成 ] ページが表示されます。
[パイプライン] 領域の [定義] ドロップダウン リストで、[SCM からのパイプライン スクリプト] を選択します。
[SCM] ドロップダウン リストで、 [Git] を選択します。
[リポジトリ URL] に、サードパーティの Git プロバイダーによってホストされているリポジトリの URL を入力します。
[ ブランチ指定子] に「
*/<branch-name>を入力します。ここで、<branch-name>は、使用するリポジトリ内のブランチの名前 (*/mainなど) です。[ スクリプト パス] に「
Jenkinsfile(まだ設定されていない場合)」と入力します。Jenkinsfileは、この記事の後半で作成します。[ 軽量チェックアウト] というタイトルのチェックボックスがすでにオンになっている場合は、オフにします。
[保存]をクリックします。
ステップ 3: グローバル環境変数を Jenkins に追加する
この手順では、Jenkins に 3 つのグローバル環境変数を追加します。 Jenkins は、これらの環境変数を Databricks CLI に渡します。 Databricks CLI では、Databricks ワークスペースで認証するために、これらの環境変数の値が必要です。 この例では、サービスプリンシパルに OAuth マシン間 (M2M) 認証を使用します (ただし、他の認証タイプも使用できます)。 ワークスペースの OAuthM2M 認証を設定するには、「Databricks Databricksを使用してサービスプリンシパルで へのアクセスを認証するOAuth (OAuth M2M)」 を参照してください。
この例の 3 つのグローバル環境変数は次のとおりです。
DATABRICKS_HOSTで、https://で始まる Databricks ワークスペースの URL に設定します。 「ワークスペース インスタンスの名前、URL、および ID」を参照してください。DATABRICKS_CLIENT_IDは、サービスプリンシパルのクライアント ID (アプリケーション ID とも呼ばれます) に設定されます。DATABRICKS_CLIENT_SECRETは、サービスプリンシパルの Databricks OAuth シークレットに設定されます。
Jenkins でグローバル環境変数を設定するには、Jenkins ダッシュボードから次の手順を実行します。
サイドバーで、[ Jenkinsを管理]をクリックします。
[ システム構成 ] セクションで、[ システム] をクリックします。
[ グローバル プロパティ ] セクションで、[ 環境変数] の順に並べて表示したチェック ボックスをオンにします。
[ 追加 ] をクリックし、環境変数の [名前 ] と [値] を入力します。 追加の環境変数ごとにこれを繰り返します。
環境変数の追加が完了したら、[ 保存 ] をクリックして Jenkins ダッシュボードに戻ります。
ジェンキンスパイプラインの設計
Jenkins には、CI/CD パイプラインを作成するためのいくつかの異なるプロジェクトの種類が用意されています。 この例では、Jenkins パイプラインを実装します。 Jenkins パイプラインは、 Groovy コードを使用して Jenkins プラグインを呼び出して構成することにより、Jenkins パイプラインのステージを定義するためのインターフェイスを提供します。
Jenkins パイプライン定義は Jenkinsfile というテキスト ファイルに記述し、プロジェクトのソース管理リポジトリにチェックインします。詳細については、「 Jenkins パイプライン」を参照してください。 この記事の例の Jenkins パイプラインを次に示します。 この例では、 Jenkinsfileで、次のプレースホルダーを置き換えます。
<user-name>と<repo-name>を、サードパーティのGitプロバイダーによってホストされているユーザー名とリポジトリ名に置き換えます。この記事では、例として GitHub の URL を使用します。<release-branch-name>をリポジトリ内のリリースブランチの名前に置き換えます。たとえば、これはmain.<databricks-cli-installation-path>を、Databricks CLI がインストールされているローカル開発マシン上のパスに置き換えます。たとえば、macOSでは、これは/usr/local/bin。<jq-installation-path>を、jqがインストールされているローカル開発マシン上のパスに置き換えます。たとえば、macOSでは、これは/usr/local/bin。この例では、
<job-prefix-name>をいくつかの文字列に置き換えて、ワークスペースで作成された Databricks ジョブを一意に識別できるようにします。 たとえば、これはjenkins-demo.BUNDLETARGETがdevに設定されていることに注意してください。これは、この記事の後半で定義する Databricks アセット バンドル ターゲットの名前です。実際の実装では、これを独自のバンドルターゲットの名前に変更します。 バンドルターゲットの詳細については、この記事の後半で説明します。
リポジトリのルートに追加する必要がある Jenkinsfileは次のとおりです。
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
この記事の残りの部分では、この Jenkins パイプラインの各ステージと、そのステージで実行する Jenkins の成果物とコマンドを設定する方法について説明します。
サードパーティのリポジトリから最新のアーティファクトをプルする
この Jenkins パイプラインの最初のステージである Checkout ステージは、次のように定義されます。
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
この段階では、Jenkins がローカル開発マシンで使用する作業ディレクトリに、サードパーティの Git リポジトリからの最新のアーティファクトがあることを確認します。 通常、Jenkins はこの作業ディレクトリを <your-user-home-directory>/.jenkins/workspace/<pipeline-name>に設定します。 これにより、同じローカル開発マシン上で、開発中のアーティファクトの独自のコピーを、Jenkins がサードパーティの Git リポジトリから使用するアーティファクトとは別に保持できます。
Databricks アセットバンドルの検証
この Jenkins パイプラインの 2 番目のステージである Validate Bundle ステージは、次のように定義されます。
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
このステージでは、成果物をテストおよび実行するためのワークフローを定義する Databricks アセット バンドルが構文的に正しいことを確認します。 Databricks アセット バンドル (単に バンドルと呼ばれます) を使用すると、完全なデータ分析および機械学習プロジェクトをソース ファイルのコレクションとして表現できます。 「 Databricks アセット バンドルとは」を参照してください。
この記事のバンドルを定義するには、ローカルマシン上のクローンされたリポジトリのルートに databricks.yml という名前のファイルを作成します。 この databricks.yml ファイルの例では、次のプレースホルダーを置き換えます。
<bundle-name>をバンドルの一意のプログラム名に置き換えます。たとえば、これはjenkins-demo.この例では、
<job-prefix-name>をいくつかの文字列に置き換えて、ワークスペースで作成された Databricks ジョブを一意に識別できるようにします。 たとえば、これはjenkins-demo. Jenkinsfile のJOBPREFIX値と一致する必要があります。<spark-version-id>をジョブ クラスターの Databricks Runtime バージョン ID (13.3.x-scala2.12など) に置き換えます。<cluster-node-type-id>をジョブクラスターのノードタイプ ID (i3.xlargeなど) に置き換えます。targetsマッピングのdevは、Jenkinsfile のBUNDLETARGETと同じであることに注意してください。バンドル・ターゲットは、ホストおよび関連するデプロイメント動作を指定します。
この例を正しく動作させるには、リポジトリのルートに追加する必要がある databricks.yml ファイルを次に示します。
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
databricks.yml ファイルの詳細については、「アセットバンドルの設定Databricks」を参照してください。
バンドルをワークスペースにデプロイする
ジェンキンスパイプラインの第3ステージである Deploy Bundleは、次のように定義されています。
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
このステージでは、次の 2 つのことを行います。
ファイルの マッピングは
artifactdatabricks.ymlwhlに設定されているため、指定された場所にあるDatabricksCLI Python wheelsetup.pyファイルを使用して ファイルを構築するように に指示します。Python wheelファイルがローカル開発マシン上にビルドされると、 Databricks CLI 、ビルドされたPython wheelファイルを、指定されたPythonファイルおよびノートブックとともにDatabricksワークスペースにデプロイします。 無事までに、 Databricks Asset Bundles はPython wheelファイルとその他のファイルを
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>にデプロイします。
databricks.yml ファイルで指定されているようにPython wheelファイルをビルドできるようにするには、ローカル マシン上のクローン リポジトリのルートに次のフォルダーとファイルを作成します。
ノートブックが実行する ファイルのロジックと単体テストを定義するには、Python wheeladdcol.py とtest_addcol.py という名前の 2python/dabdemo/dabdemo つのファイルを作成し、リポジトリの {3 内の という名前のフォルダー構造に追加します。次のように視覚化されたフォルダーですLibraries (簡潔にするために、省略記号はリポジトリ内で省略されたフォルダーを示します)。
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
addcol.py ファイルには、後でPython wheelファイルに構築され、 Databricksクラスターにインストールされるライブラリ関数が含まれています。 これは、リテラルによって設定された新しい列を Apache Spark DataFrame に追加する単純な関数です。
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
test_addcol.py ファイルには、モック DataFrame オブジェクトを addcol.pyで定義されている with_status 関数に渡すためのテストが含まれています。結果は、予期される値を含む DataFrame オブジェクトと比較されます。 値が一致する場合 (この場合は一致します)、テストは合格します。
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Databricks CLIこのライブラリ コードをPython wheelファイルに正しくパッケージ化できるようにするには、前の 2 つのファイルと同じフォルダーに __init__.py と __main__.py という名前の 2 つのファイルを作成します。 また、python/dabdemo フォルダーに setup.py という名前のファイルを作成し、次のように視覚化します (簡潔にするために省略されたフォルダーは省略記号を示します)。
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
__init__.py ファイルには、ライブラリのバージョン番号と作成者が含まれています。<my-author-name> を自分の名前に置き換えます。
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
__main__.py ファイルには、ライブラリのエントリポイントが含まれています。
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
setup.py ファイルには、ライブラリをPython wheelファイルに構築するための追加設定が含まれています。 <my-url>、<my-author-name>@<my-organization>、<my-package-description> を意味のある値に置き換えます。
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Python wheelのコンポーネントロジックをテストする
この Jenkins パイプラインの 4 番目のステージである Run Unit Tests ステージでは、 pytest を使用してライブラリのロジックをテストし、ビルドどおりに動作することを確認します。 このステージは次のように定義されます。
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
このステージでは、Databricks CLI を使用してノートブック ジョブを実行します。 このジョブは、 run-unit-test.pyというファイル名で Python ノートブックを実行します。 このノートブックは、ライブラリのロジックに対して pytest 実行されます。
この例の単体テストを実行するには、次の内容を含む run_unit_tests.py という名前の Python ノートブック ファイルを、ローカル コンピューター上の複製されたリポジトリのルートに追加します。
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
ビルド Python wheel を使用する
この Jenkins パイプラインの第 5Run Notebook ステージは、 というタイトルで、次のように、ビルドされたPython Python wheelファイル内のロジックを呼び出す ノートブックを実行します。
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
このステージでは、Databricks CLI が実行され、ノートブック ジョブを実行するようにワークスペースに指示されます。 このノートブックは、DataFrame オブジェクトを作成し、ライブラリの with_status 関数に渡し、結果を出力して、ジョブの実行結果を報告します。 ローカル開発マシン上の複製されたリポジトリのルートに次の内容を含む dabdaddemo_notebook.py という名前の Python ノートブック ファイルを追加して、ノートブックを作成します。
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
ノートブック ジョブの実行結果を評価する
この Jenkins パイプラインの 6 番目のステージである Evaluate Notebook Runs ステージでは、前のノートブック ジョブの実行結果を評価します。 このステージは次のように定義されます。
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
このステージでは、Databricks CLI が実行され、Python ファイル ジョブを実行するようにワークスペースに指示されます。 この Python ファイルは、ノートブック ジョブ実行の失敗と成功の条件を決定し、この失敗または成功の結果を報告します。 ローカル開発マシンのクローンされたリポジトリのルートに、次の内容の evaluate_notebook_runs.py という名前のファイルを作成します。
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
テスト結果のインポートとレポート
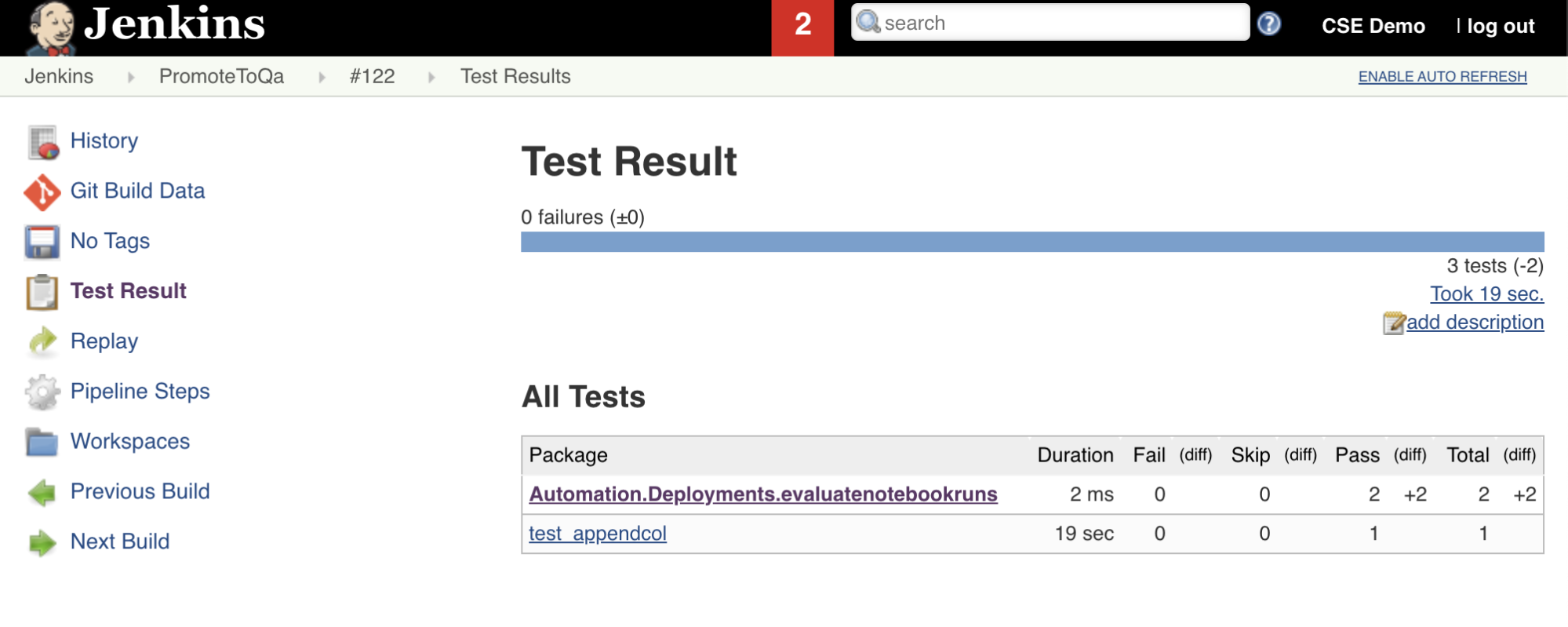
この Jenkins パイプラインの 7 番目のステージ ( Import Test Resultsというタイトル) では、Databricks CLI を使用して、ワークスペースからローカル開発マシンにテスト結果を送信します。 8 番目の最終ステージである Publish Test Resultsは、 junit Jenkins プラグインを使用してテスト結果を Jenkins に発行します。 これにより、テスト結果の状態に関連するレポートとダッシュボードを視覚化できます。 これらの段階は次のように定義されます。
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
すべてのコード変更をサードパーティのリポジトリにプッシュする
ここで、ローカル開発マシン上のクローンリポジトリの内容をサードパーティのリポジトリにプッシュする必要があります。 プッシュする前に、内部 Databricks アセット バンドルの作業ファイル、検証レポート、Python ビルド ファイル、Python キャッシュをサードパーティのリポジトリにプッシュしない可能性があるため、まず、複製されたリポジトリの .gitignore ファイルに次のエントリを追加する必要があります。 通常は、古い可能性のある検証レポートとPython wheelビルドを使用する代わりに、新しい検証レポートと最新のPython wheel Databricks ワークスペースを組み込むものを再生成する必要があります。
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
実行 あなたの Jenkins パイプライン
これで、Jenkins パイプラインを手動で実行する準備ができました。 これを行うには、Jenkinsダッシュボードから次の手順を実行します。
Jenkins パイプラインの名前をクリックします。
サイドバーで、[ 今すぐビルド] をクリックします。
結果を表示するには、最新のパイプライン 実行 (
#1など) をクリックし、[ コンソール出力] をクリックします。
この時点で、CI/CD パイプラインの統合とデプロイのサイクルが完了しました。 このプロセスを自動化することで、効率的で一貫性があり、反復可能なプロセスによってコードがテストおよびデプロイされていることを確認できます。 リポジトリのプルリクエストなど、特定のイベントが発生するたびに Jenkins を実行するようにサードパーティの Git プロバイダーに指示するには、サードパーティの Git プロバイダーのドキュメントを参照してください。