CI/CD com Jenkins em Databricks
Observação
Este artigo abrange o Jenkins, que é desenvolvido por terceiros. Para entrar em contato com o provedor, consulte a Ajuda do Jenkins.
Existem inúmeras ferramentas CI/CD que o senhor pode usar para gerenciar e executar seu pipeline CI/CD. Este artigo ilustra como usar o servidor de automação Jenkins. CI/CD é um padrão de design, portanto, os passos e etapas descritos neste artigo devem ser transferidos com algumas alterações na linguagem de definição do pipeline em cada ferramenta. Além disso, grande parte do código deste exemplo pipeline executa o código Python padrão, que o senhor pode invocar em outras ferramentas. Para obter uma visão geral da CI/CD na Databricks, consulte O que é CI/CD na Databricks?
Fluxo de trabalho de desenvolvimento de CI/CD
Databricks sugere o seguinte fluxo de trabalho para desenvolvimento de CI/CD com Jenkins:
Crie um repositório ou use um repositório existente com seu provedor Git terceirizado.
Conecte sua máquina de desenvolvimento local ao mesmo repositório de terceiros. Para obter instruções, consulte a documentação do seu provedor Git terceirizado.
Extraia quaisquer artefatos atualizados existentes (como Notebook, arquivos de código e scripts de construção) do repositório de terceiros para sua máquina de desenvolvimento local.
Conforme desejado, crie, atualize e teste artefatos em sua máquina de desenvolvimento local. Em seguida, envie quaisquer artefatos novos e alterados da sua máquina de desenvolvimento local para o repositório de terceiros. Para obter instruções, consulte a documentação do seu provedor Git terceirizado.
Repita os passos 3 e 4 conforme necessário.
Use Jenkins periodicamente como uma abordagem integrada para extrair automaticamente artefatos de seu repositório de terceiros para sua máquina de desenvolvimento local ou workspace do Databricks; construir, testar e executar código em sua máquina de desenvolvimento local ou workspace do Databricks; e relatórios de testes e resultados de execução. Embora você possa executar o Jenkins manualmente, em implementações do mundo real você instruiria seu provedor Git terceirizado para executar o Jenkins sempre que um evento específico acontecesse, como uma solicitação pull de repositório.
O restante deste artigo usa um projeto de exemplo para descrever uma maneira de usar Jenkins para implementar o fluxo de trabalho de desenvolvimento de CI/CD anterior.
Configuração da máquina de desenvolvimento local
O exemplo deste artigo usa Jenkins para instruir a CLI do Databricks e os pacotes ativos do Databricks a fazer o seguinte:
Crie um arquivo Python wheel em seu computador de desenvolvimento local.
Implemente o arquivo Python wheel construído junto com os arquivos Python adicionais e o Notebook Python de sua máquina de desenvolvimento local em um Databricks workspace.
Teste e execute o upload do arquivo Python wheel e o Notebook nesse workspace.
Para configurar a sua máquina de desenvolvimento local para instruir o seu workspace Databricks para executar as fases de construção e upload para este exemplo, faça o seguinte na sua máquina de desenvolvimento local:
o passo 1: Instale as ferramentas necessárias
Nesta etapa, você instala a CLI do Databricks, Jenkins, jq e ferramentas de criação Python wheel em sua máquina de desenvolvimento local. Essas ferramentas são necessárias para executar este exemplo.
Instale a CLI do Databricks versão 0.205 ou acima, caso ainda não tenha feito isso. Jenkins usa a CLI do Databricks para passar as instruções de teste e execução deste exemplo para seu workspace. Consulte Instalar ou atualizar a CLI do Databricks.
Instale e comece o Jenkins, caso ainda não o tenha feito. Consulte Instalando o Jenkins para Linux, macOS ou Windows.
Instale o jq. Este exemplo usa
jqpara analisar alguma saída de comando formatada em JSON.Use
pippara instalar as ferramentas de compilaçãoPython wheel com o comando a seguir (alguns sistemas podem exigir que você usepip3em vez depip):pip install --upgrade wheel
o passo 2: Crie um pipeline Jenkins
Neste passo, você usa Jenkins para criar um Jenkins Pipeline para o exemplo deste artigo. Jenkins fornece alguns tipos de projetos diferentes para criar pipeline de CI/CD. pipeline Jenkins fornece uma interface para definir estágios em um pipeline Jenkins usando código Groovy para chamar e configurar plug-ins Jenkins.
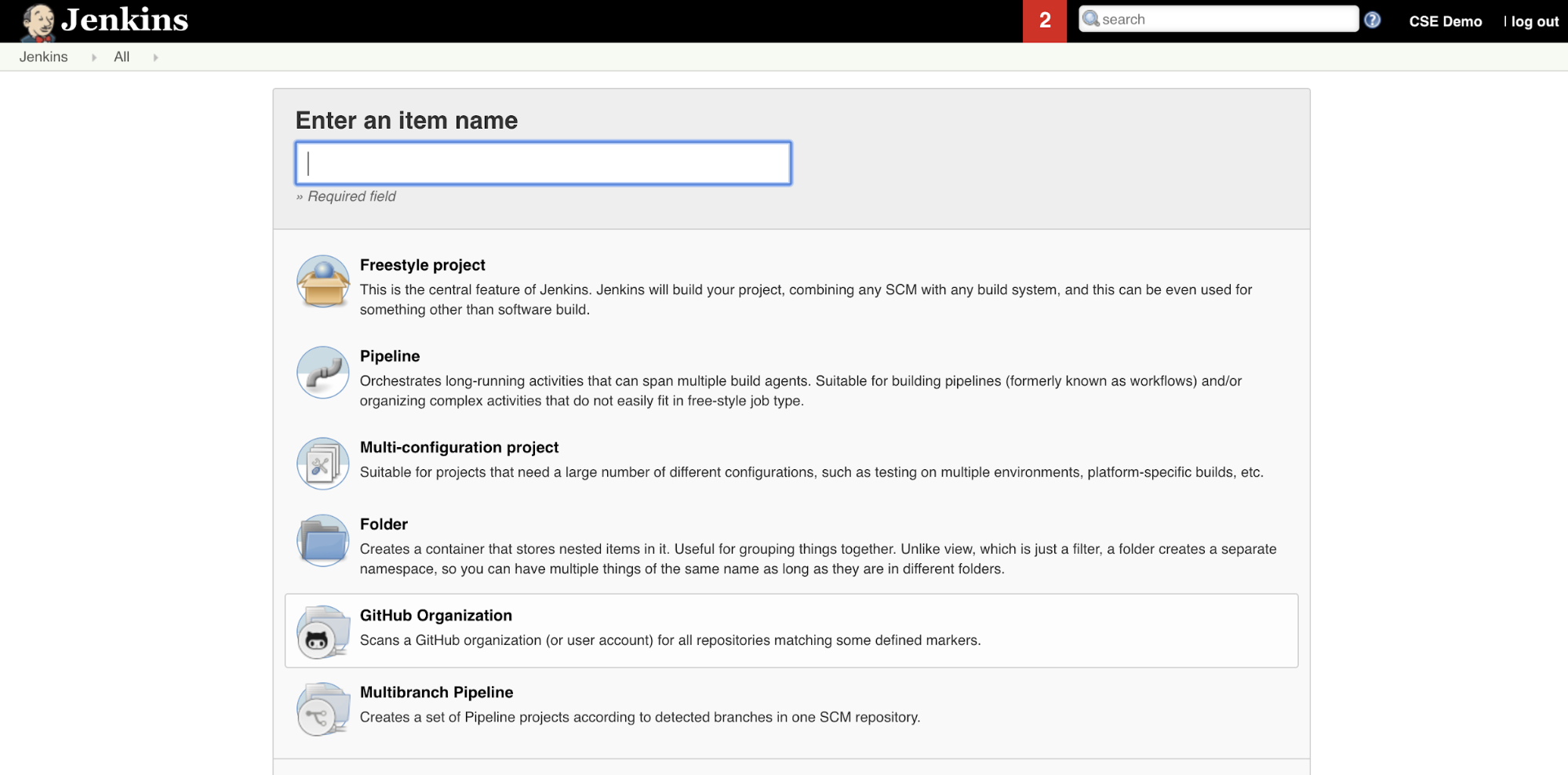
Para criar o pipeline Jenkins no Jenkins:
Depois de começar o Jenkins, no painel do Jenkins, clique em Novo item.
Para Insira um nome de item, digite um nome para o pipeline do Jenkins , por exemplo
jenkins-demo.Clique no ícone do tipo de projeto pipeline .
Clique em OK. A página Configurar do Jenkins pipelineé exibida.
Na área Pipeline , na lista suspensa Definição , selecione Script de pipeline do SCM.
Na lista suspensa SCM , selecione Git.
Para URL do repositório, digite a URL do repositório hospedado pelo seu provedor Git de terceiros.
Para Branch Specifier, digite
*/<branch-name>, onde<branch-name>é o nome da ramificação em seu repositório que você deseja usar, por exemplo*/main.Para Caminho do script, digite
Jenkinsfile, se ainda não estiver definido. Você cria oJenkinsfileposteriormente neste artigo.Desmarque a caixa intitulada Lightweight checkout, se já estiver marcada.
Clique em Salvar.
o passo 3: Adicionar variável global de ambiente ao Jenkins
Neste passo, o senhor adiciona três variáveis globais de ambiente ao Jenkins. Jenkins passa essas variáveis de ambiente para o site Databricks CLI. O Databricks CLI precisa dos valores para essas variáveis de ambiente para se autenticar com o seu Databricks workspace. Este exemplo usa a autenticação OAuth máquina a máquina (M2M) para uma entidade de serviço (embora outros tipos de autenticação também estejam disponíveis). Para configurar a autenticação OAuth M2M para sua Databricks workspace, consulte Autenticar o acesso a Databricks com uma entidade de serviço usando OAuth (OAuth M2M).
As três variáveis globais de ambiente para este exemplo são:
DATABRICKS_HOST, defina como a URL workspace do Databricks, começando comhttps://. Consulte Nomes, URLs e IDs de instâncias do Workspace.DATABRICKS_CLIENT_ID, definido como o ID do cliente da entidade de serviço, que também é conhecido como ID do aplicativo.DATABRICKS_CLIENT_SECRET, definido como o segredo do Databricks OAuth da entidade de serviço.
Para definir a variável global de ambiente no Jenkins, no seu painel Jenkins:
Na barra lateral, clique em Gerenciar Jenkins.
Na seção Configuração do sistema , clique em Sistema.
Na seção Propriedades globais , marque a caixa variável de ambiente lado a lado .
Clique em Adicionar e insira o Nome e o Valor da variável de ambiente. Repita isso para cada variável de ambiente adicional.
Quando terminar de adicionar variável de ambiente, clique em Salvar para retornar ao seu painel Jenkins.
Projete o pipeline Jenkins
Jenkins fornece alguns tipos de projetos diferentes para criar pipeline de CI/CD. Este exemplo implementa um pipeline Jenkins. pipeline Jenkins fornece uma interface para definir estágios em um pipeline Jenkins usando código Groovy para chamar e configurar plug-ins Jenkins.
Você escreve uma definição pipeline do Jenkins em um arquivo de texto chamado Jenkinsfile, que por sua vez é verificado no repositório de controle de origem de um projeto. Para obter mais informações, consulte Pipeline Jenkins. Aqui está o pipeline Jenkins para o exemplo deste artigo. Neste exemplo Jenkinsfile, substitua os seguintes espaços reservados:
Substitua
<user-name>e<repo-name>pelo nome de usuário e nome do repositório hospedado por seu provedor Git terceirizado. Este artigo usa uma URL do GitHub como exemplo.Substitua
<release-branch-name>pelo nome da ramificação de lançamento no seu repositório. Por exemplo, poderia sermain.Substitua
<databricks-cli-installation-path>pelo caminho na sua máquina de desenvolvimento local onde a CLI do Databricks está instalada. Por exemplo, no macOS, poderia ser/usr/local/bin.Substitua
<jq-installation-path>pelo caminho na sua máquina de desenvolvimento local ondejqestá instalado. Por exemplo, no macOS, poderia ser/usr/local/bin.Substitua
<job-prefix-name>por algumas strings para ajudar a identificar exclusivamente o Job do Databricks criado em seu workspace para este exemplo. Por exemplo, poderia serjenkins-demo.Observe que
BUNDLETARGETestá definido comodev, que é o nome do destino do Databricks ativo Bundle definido posteriormente neste artigo. Em implementações do mundo real, você mudaria isso para o nome do seu próprio destino de pacote. Mais detalhes sobre os destinos do pacote serão fornecidos posteriormente neste artigo.
Aqui está o Jenkinsfile, que deve ser adicionado à raiz do seu repositório:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
O restante deste artigo descreve cada estágio deste Pipeline Jenkins e como configurar os artefatos e comandos para o Jenkins executar nesse estágio.
Extraia os artefatos mais recentes do repositório de terceiros
O primeiro estágio neste pipeline Jenkins, o estágio Checkout , é definido da seguinte forma:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
Este estágio garante que o diretório de trabalho que Jenkins usa em sua máquina de desenvolvimento local tenha os artefatos mais recentes de seu repositório Git de terceiros. Normalmente, Jenkins define esse diretório de trabalho como <your-user-home-directory>/.jenkins/workspace/<pipeline-name>. Isso permite que você, na mesma máquina de desenvolvimento local, mantenha sua própria cópia dos artefatos em desenvolvimento separada dos artefatos que Jenkins usa do seu repositório Git de terceiros.
Validar o pacote Databricks ativo
O segundo estágio neste pipeline Jenkins, o estágio Validate Bundle , é definido da seguinte forma:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
Esta etapa garante que o pacote Databricks ativo, que define o fluxo de trabalho para testar e executar seus artefatos, esteja sintaticamente correto. Databricks ativos Bundles, conhecidos simplesmente como bundles, possibilitam expressar análises completas de dados e projetos de ML como uma coleção de arquivos fonte. Consulte O que são pacotes Databricks ativos?.
Para definir o pacote para estes artigos, crie um arquivo chamado databricks.yml na raiz do repositório clonado em sua máquina local. Neste arquivo databricks.yml de exemplo, substitua os seguintes espaços reservados:
Substitua
<bundle-name>por um nome programático exclusivo para o pacote. Por exemplo, poderia serjenkins-demo.Substitua
<job-prefix-name>por algumas strings para ajudar a identificar exclusivamente o Job do Databricks criado em seu workspace para este exemplo. Por exemplo, poderia serjenkins-demo. Deve corresponder ao valorJOBPREFIXno seu Jenkinsfile.Substitua
<spark-version-id>pelo ID da versão do Databricks Runtime para seus clusters Job , por exemplo13.3.x-scala2.12.Substitua
<cluster-node-type-id>pelo ID do tipo de nó dos clusters Job , por exemploi3.xlarge.Observe que
devno mapeamentotargetsé igual aBUNDLETARGETem seu Jenkinsfile. Um destino de pacote especifica o host e os comportamentos de implantação relacionados.
Aqui está o arquivo databricks.yml , que deve ser adicionado à raiz do seu repositório para que este exemplo funcione corretamente:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
Para obter mais informações sobre o arquivo databricks.yml, consulte Databricks ativo Bundle configuration.
implantar o pacote em seu espaço de trabalho
O terceiro estágio do pipelineJenkins, intitulado Deploy Bundle, é definido da seguinte forma:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
Este estágio faz duas coisas:
Como o mapeamento
artifactno arquivodatabricks.ymlestá definido comowhl, isso instrui o Databricks CLI a criar o arquivo Python wheel usando o arquivosetup.pyno local especificado.Depois que o arquivo Python wheel é criado em sua máquina de desenvolvimento local, o Databricks CLI implanta o arquivo Python wheel criado junto com os arquivos Python especificados e o Notebook em seu Databricks workspace. Por default, Databricks ativo Bundles implantado o arquivo Python wheel e outros arquivos para
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>.
Para permitir que o arquivo Python wheel seja criado conforme especificado no arquivo databricks.yml, crie as seguintes pastas e arquivos na raiz do repositório clonado em seu computador local.
Para definir a lógica e os testes de unidade para o arquivo Python wheel contra o qual o Notebook será executado, crie dois arquivos denominados addcol.py e test_addcol.py e adicione-os a uma estrutura de pastas denominada python/dabdemo/dabdemo dentro da pasta Libraries do seu repositório, visualizada da seguinte forma (as elipses indicam pastas omitidas no repo, para fins de brevidade):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
O arquivo addcol.py contém uma função de biblioteca que é incorporada posteriormente em um arquivo Python wheel e, em seguida, instalada em um arquivo Databricks cluster. É uma função simples que adiciona uma nova coluna, preenchida por um literal, a um Apache Spark DataFrame:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
O arquivo test_addcol.py contém testes para passar um objeto DataFrame simulado para a função with_status , definida em addcol.py. O resultado é então comparado a um objeto DataFrame contendo os valores esperados. Se os valores corresponderem, o que acontece neste caso, o teste será aprovado:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Para que o Databricks CLI possa empacotar corretamente esse código de biblioteca em um arquivo Python wheel, crie dois arquivos denominados __init__.py e __main__.py na mesma pasta dos dois arquivos anteriores. Além disso, crie um arquivo chamado setup.py na pasta python/dabdemo, visualizado da seguinte forma (as elipses indicam pastas omitidas, para fins de brevidade):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
O arquivo __init__.py contém o número de versão e o autor da biblioteca. Substitua <my-author-name> pelo seu nome:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
O arquivo __main__.py contém o ponto de entrada da biblioteca:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
O arquivo setup.py contém configurações adicionais para criar a biblioteca em um arquivo Python wheel. Substitua <my-url>, <my-author-name>@<my-organization> e <my-package-description> por valores significativos:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Teste a lógica do componente da Python wheel
O estágio Run Unit Tests , o quarto estágio deste pipeline Jenkins, usa pytest para testar a lógica de uma biblioteca para garantir que ela funcione conforme criada. Esta etapa é definida da seguinte forma:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
Este estágio usa a CLI do Databricks para executar um Notebook Job. Este Job executa o Python Notebook com o nome de arquivo run-unit-test.py. Esta execução Notebook pytest contra a lógica da biblioteca.
Para executar os testes de unidade deste exemplo, adicione um arquivo Python Notebook chamado run_unit_tests.py com o seguinte conteúdo à raiz do seu repositório clonado na sua máquina local:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Use a Python wheelconstruída
O quinto estágio desse Jenkins pipeline, intitulado Run Notebook, executa um Python Notebook que chama a lógica no arquivo construído Python wheel, como segue:
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
Este estágio executa a CLI do Databricks, que por sua vez instrui seu workspace a executar um Notebook Job. Este Notebook cria um objeto DataFrame, passa-o para a função with_status da biblioteca, imprime o resultado e relata os resultados da execução do Job . Crie o Notebook adicionando um arquivo Python Notebook chamado dabdaddemo_notebook.py com o seguinte conteúdo na raiz do seu repositório clonado na sua máquina de desenvolvimento local:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Avalie Notebook Job os resultados da execução
O Evaluate Notebook Runs estágio , o sexto deste pipeline do Jenkins, avalia os resultados da execução Notebook Job anterior . Esta etapa é definida da seguinte forma:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
Este estágio executa a CLI do Databricks, que por sua vez instrui seu workspace a executar um arquivo Python Job. Este arquivo Python determina os critérios de falha e sucesso para a execução Notebook Job e relata essa falha ou resultado de sucesso. Crie um arquivo chamado evaluate_notebook_runs.py com o seguinte conteúdo na raiz do seu repositório clonado na sua máquina de desenvolvimento local:
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Importe e relate resultados de testes
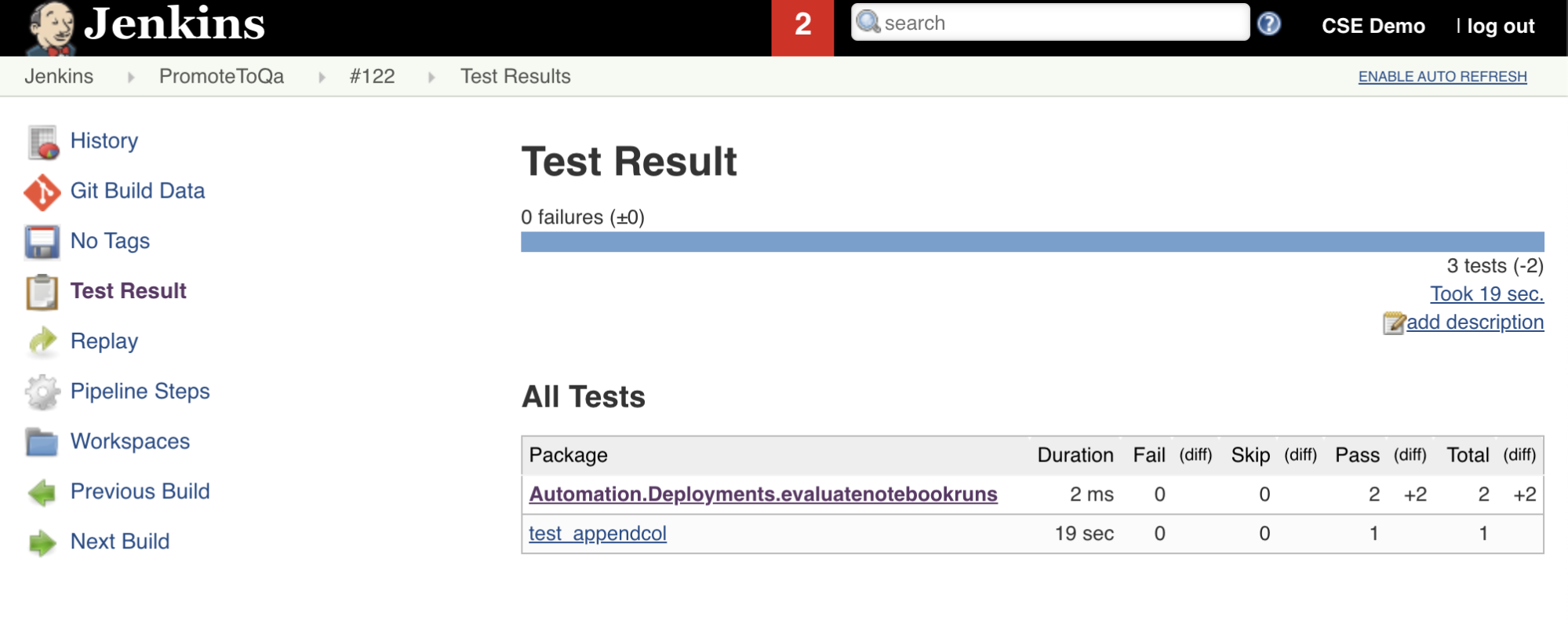
A sétima etapa deste pipeline do Jenkins, intitulada Import Test Results, usa a CLI do Databricks para enviar os resultados do teste do seu workspace para a sua máquina de desenvolvimento local. A oitava e última etapa, intitulada Publish Test Results, publica os resultados do teste no Jenkins usando o plug-in junit Jenkins. Isso permite visualizar relatórios e painéis relacionados ao status dos resultados do teste. Essas etapas são definidas da seguinte forma:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
Envie todas as alterações de código para seu repositório de terceiros
Agora você deve enviar o conteúdo do seu repositório clonado na sua máquina de desenvolvimento local para o seu repositório de terceiros. Antes de enviar, você deve primeiro adicionar as seguintes entradas ao arquivo .gitignore em seu repositório clonado, pois provavelmente não deve enviar arquivos de trabalho internos do Databricks ativo Bundle, relatórios de validação, arquivos de compilação Python e caches Python para seu terceiro repositório. Normalmente, você desejará regenerar novos relatórios de validação e a Python wheel mais recente integrada em seu espaço de trabalho do Databricks, em vez de usar relatórios de validação potencialmente desatualizados e construções Python wheel :
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
executando seu pipeline Jenkins
Agora você está pronto para executar seu pipeline Jenkins manualmente. Para fazer isso, no seu painel Jenkins:
Clique no nome do seu pipeline Jenkins.
Na barra lateral, clique em Construir agora.
Para ver os resultados, clique na execução mais recente do pipeline (por exemplo,
#1) e clique em Saída do console.
Neste ponto, o pipeline de CI/CD concluiu um ciclo de integração e implantação. Ao automatizar esse processo, você pode garantir que seu código foi testado e implantado por um processo eficiente, consistente e repetível. Para instruir seu provedor Git terceirizado a executar o Jenkins sempre que um evento específico acontecer, como uma solicitação pull de repositório, consulte a documentação do seu provedor Git terceirizado.