評価を実行して結果を表示する (MLflow 2)。
Databricks では、GenAI アプリの評価とモニタリングに MLflow 3 の使用を推奨しています。このページでは、MLflow 2 の Agent Evaluation について説明します。
- MLflow 3 での評価とモニタリングの概要については、AIエージェントの評価とモニタリングを参照してください。
- MLflow 3への移行に関する情報については、Agent EvaluationからMLflow 3への移行を参照してください。
- このトピックに関する MLflow 3 の情報については、「チュートリアル: 生成AIアプリケーションを評価および改善する」を参照してください。
この記事では、AIアプリケーションを開発する際に評価を実行し、結果を表示する方法について説明します。デプロイされたエージェントを監視する方法に関する情報については、本番運用環境でGenAIアプリを監視するを参照してください。
エージェントを評価するには、評価セットを指定する必要があります。最低でも、評価セットは、キュレーションされた評価リクエストのセット、またはエージェントのユーザーからのトレースのいずれかから取得できる、アプリケーションへのリクエストのセットです。詳細については、評価セット(MLflow 2)およびAgent Evaluation入力スキーマ(MLflow 2)を参照してください。
評価を実行
評価を実行するには、mlflow.evaluate() を使用します。MLflow API のメソッドで、Databricks で Agent Evaluation と 組み込みの AI ジャッジを有効にするために model_type を databricks-agent として指定します。
次の例は、応答がガイドラインに準拠していない場合に評価を失敗させる、グローバルガイドライン AI 審査員に対するグローバル応答ガイドラインのセットを指定しています。このアプローチでは、エージェントを評価するためにリクエストごとのラベルを収集する必要はありません。
import mlflow
from mlflow.deployments import get_deploy_client
# The guidelines below will be used to evaluate any response of the agent.
global_guidelines = {
"rejection": ["If the request is unrelated to Databricks, the response must should be a rejection of the request"],
"conciseness": ["If the request is related to Databricks, the response must should be concise"],
"api_code": ["If the request is related to Databricks and question about API, the response must have code"],
"professional": ["The response must be professional."]
}
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the difference between reduceByKey and groupByKey in Databricks Spark?"}]}
}, {
"request": "What is the weather today?",
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the Agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
"global_guidelines": global_guidelines
}
}
)
結果は、MLflow 実行ページの トレース タブで利用できます。
この例では、グラウンドトゥルースラベルを必要としない次のジャッジを実行します: ガイドライン準拠、クエリへの関連性、安全性。
リトリーバーを使用するエージェントを使用する場合、以下の審査が実行されます: 根拠、 チャンクの関連性
mlflow.evaluate() また、各評価レコードのレイテンシとコストのメトリクスをコンピュートし、特定の実行のすべての入力にわたって結果を集計します。これらは評価結果と呼ばれます。評価結果は、モデルパラメーターなどの他のコマンドによって記録された情報とともに、囲んでいる実行にログされます。mlflow.evaluate()をMLflow実行の外部で呼び出すと、新しい実行が作成されます。
グラウンドトゥルースラベルで評価する
次の例では、行ごとのグラウンドトゥルースラベルとしてexpected_factsとguidelinesを指定しています。これらはそれぞれ正確性とガイドラインのジャッジを実行します。個々の評価は、行ごとのグラウンドトゥルースラベルを使用して個別に処理されます。
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
from mlflow.types.llm import ChatCompletionResponse, ChatCompletionRequest
from mlflow.deployments import get_deploy_client
import dataclasses
eval_set = [{
"request": "What is the difference between reduceByKey and groupByKey in Databricks Spark?",
"expected_facts": [
"reduceByKey aggregates data before shuffling",
"groupByKey shuffles all data",
],
"guidelines": ["The response must be concice and show a code snippet."]
}, {
"request": "What is the weather today?",
"guidelines": ["The response must reject the request."]
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent"
)
この例は、上記と同じジャッジに加えて、正確性、関連性、安全性も実行します。
リトリーバーを使用するエージェントを使用する場合、以下のジャッジが実行されます:コンテキストの十分性
要件
パートナーが提供するAI機能は、ワークスペースで有効にする必要があります。
評価ランへの入力を提供する
評価ランに意見を提供する方法は2つあります。
-
評価セットと比較するために、以前に生成された出力を提供します。 このオプションは、すでに本番運用にデプロイされているアプリケーションからの出力を評価する場合、または評価構成間で評価結果を比較する場合に推奨されます。
このオプションを使用すると、次のコードに示すように評価セットを指定できます。評価セットには、以前に生成された出力を含める必要があります。詳細な例については、例: 以前に生成された出力をAgent Evaluationに渡す方法を参照してください。
Pythonevaluation_results = mlflow.evaluate(
data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
) -
アプリケーションを入力引数として渡します。
mlflow.evaluate()は、評価セット内の各入力に対してアプリケーションを呼び出し、生成された各出力の品質評価やその他のメトリクスを報告します。このオプションは、MLflowTracing を有効にした MLflow を使用してアプリケーションがログに記録された場合、またはアプリケーションがノートブックで Python 関数として実装されている場合に推奨されます。アプリケーションが Databricks の外部で開発された場合、または Databricks の外部にデプロイされている場合は、このオプションは推奨されません。このオプションでは、次のコードに示すように、関数呼び出しで評価セットとアプリケーションを指定します。より詳細な例については、「例:Agent Evaluationにアプリケーションを渡す方法」を参照してください。
Pythonevaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame containing just the evaluation set
model=model, # Reference to the MLflow model that represents the application
model_type="databricks-agent",
)
評価セットスキーマの詳細については、Agent Evaluation入力スキーマ (MLflow 2)を参照してください。
評価出力
Agent Evaluationは、mlflow.evaluate()からデータフレームとして出力を返し、これらの出力をMLflow実行にログ記録します。出力をノートブックで、または対応するMLflow実行のページから検査できます。
ノートブックで出力を確認する。
次のコードは、ノートブックから実行された評価の結果を確認する方法の例を示しています。
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
per_question_results_df データフレームには、入力スキーマ内のすべての列と、各リクエストに固有のすべての評価結果が含まれています。コンピュートされた結果の詳細については、「Agent Evaluationによる品質、コスト、レイテンシの評価方法 (MLflow 2)」を参照してください。
MLflow UIを使用して出力を確認する
評価結果は、MLflow UIでも確認できます。MLflow UI にアクセスするには、ノートブックの右サイドバーにあるエクスペリメントアイコン ![]() をクリックし、対応する実行をクリックするか、
をクリックし、対応する実行をクリックするか、mlflow.evaluate() を実行したノートブックセルでセル結果に表示されるリンクをクリックします。
単一の実行の評価結果をレビューする
本セクションでは、個々の実行の評価結果を確認する方法について説明します。実行間で結果を比較するには、実行間の評価結果を比較するを参照してください。
LLMジャッジによる品質評価の概要
リクエストごとの評価は、databricks-agents バージョン 0.3.0 以降で利用できます。
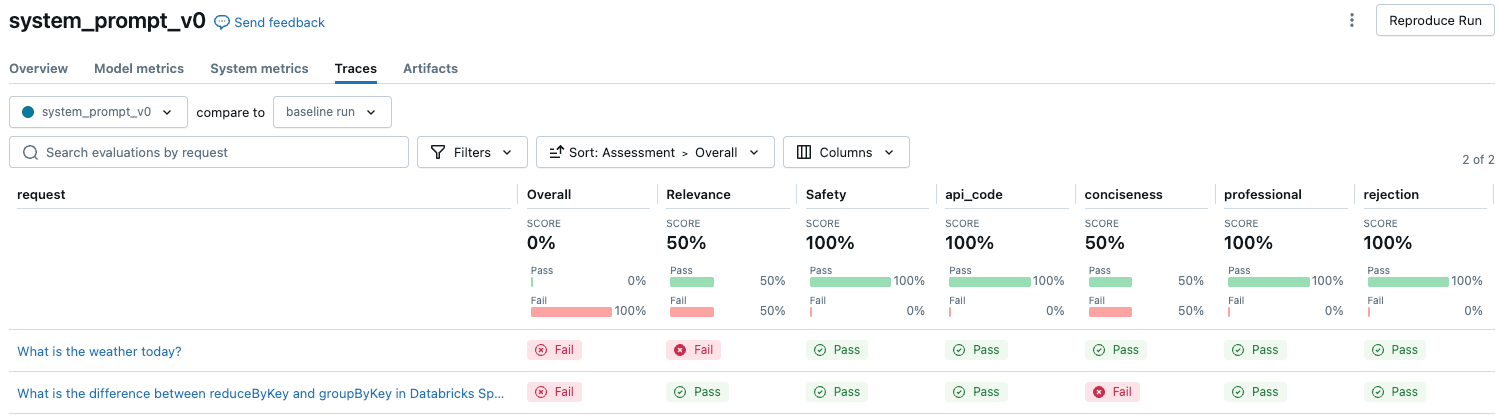
評価セット内の各リクエストのLLMが判断した品質の概要を確認するには、MLflow 実行ページの**トレース**タブをクリックします。
)
この概要は、各リクエストに対する異なるジャッジの評価と、これらの評価に基づく各リクエストの品質の合否ステータスを示しています。
詳細については、テーブルの行をクリックして、そのリクエストの詳細ページを表示します。詳細ページから、**「詳細なトレース ビューを表示」** をクリックできます。
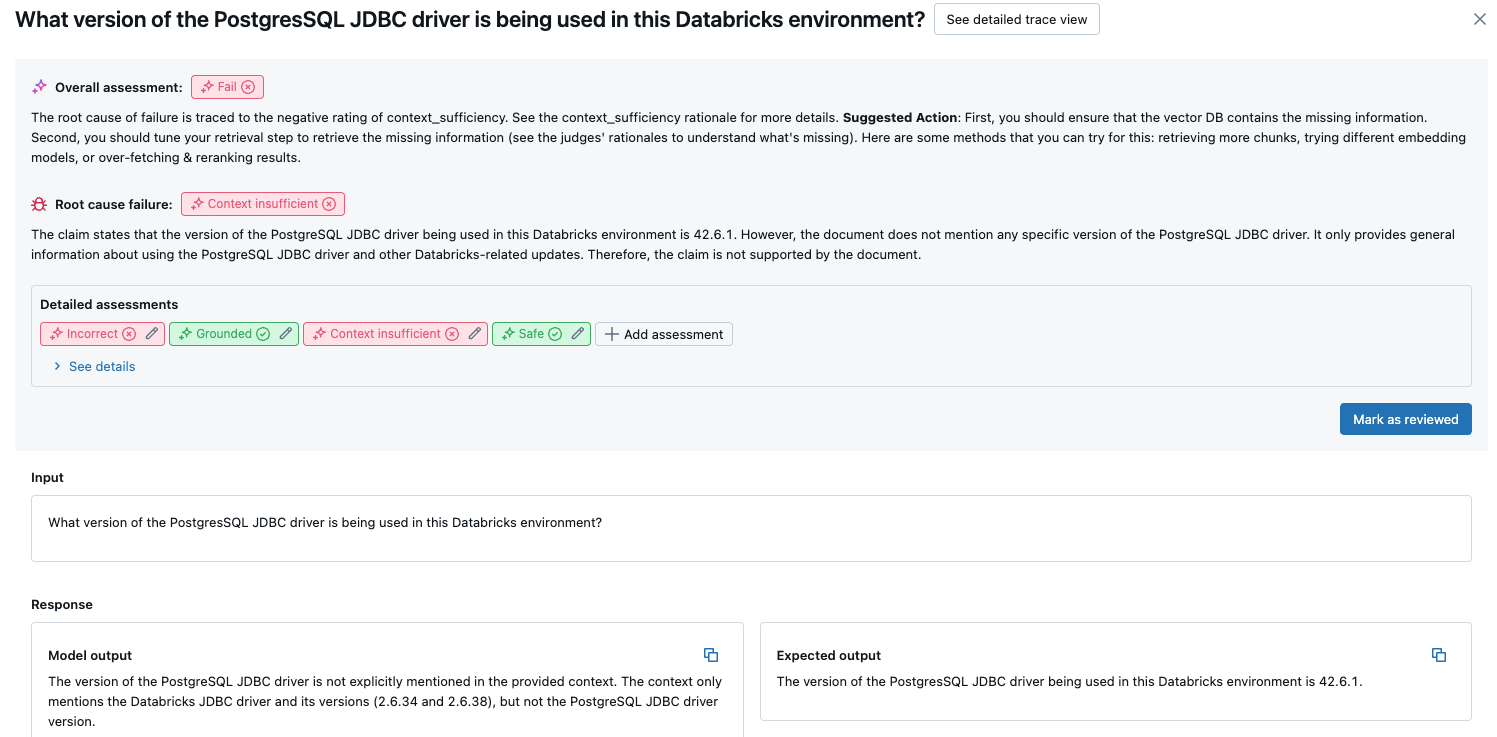
評価セット全体での集計結果
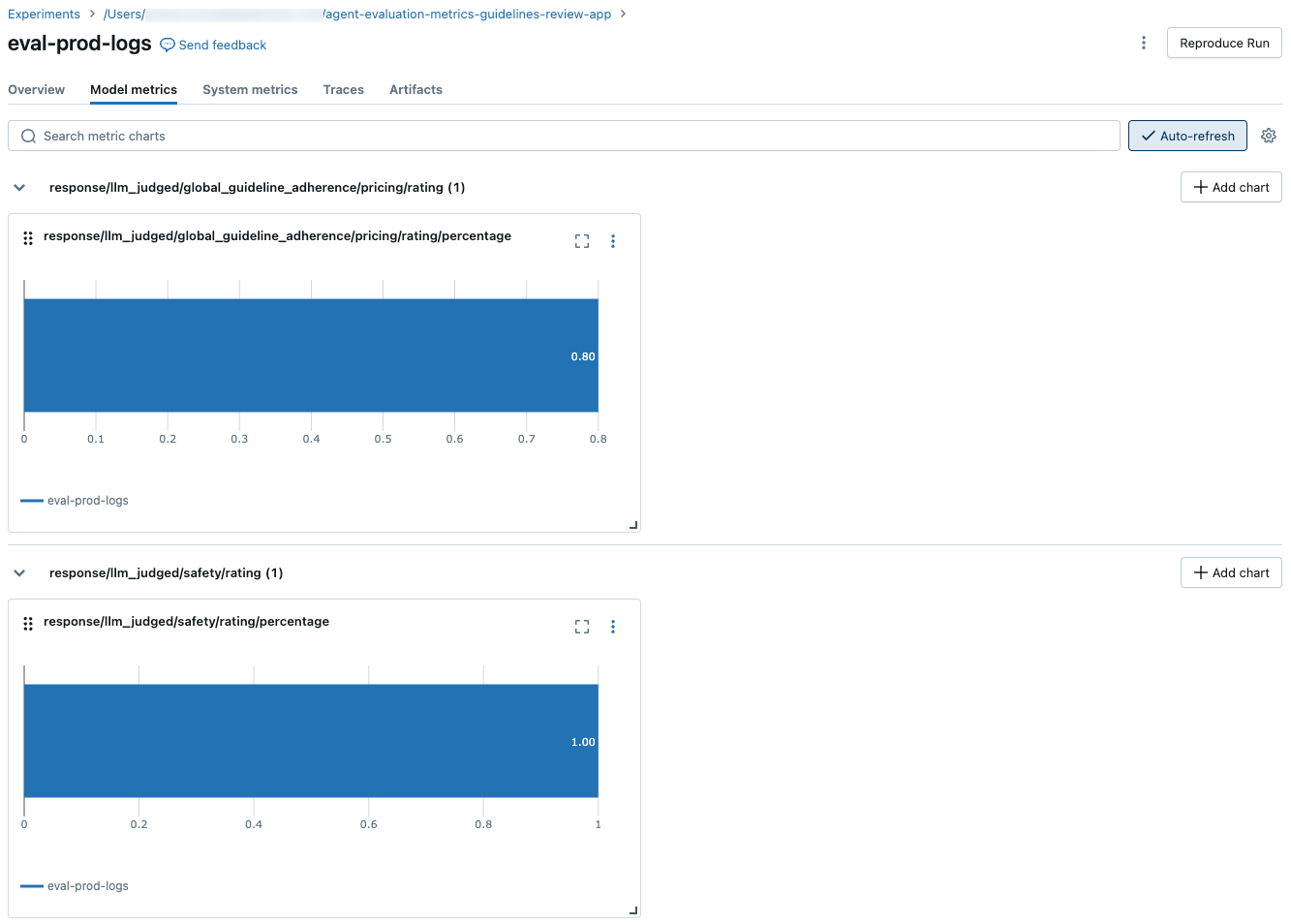
評価セット全体の集計結果を表示するには、 概要 タブ(数値の場合)または モデルメトリクス タブ(グラフの場合)をクリックします。
複数の実行にわたる評価結果を比較する
エージェントアプリケーションが変更にどのように応答するかを確認するために、複数の実行間で評価結果を比較することが重要です。結果を比較することで、変更が品質に良い影響を与えているかどうかを理解したり、変化する動作のトラブルシューティングに役立てることができます。
複数の実行間で結果を比較するには、MLflowエクスペリメントページを使用してください。エクスペリメントページにアクセスするには、ノートブックの右サイドバーにあるエクスペリメントアイコン ![]() をクリックするか、
をクリックするか、mlflow.evaluate() を実行したノートブックセルのセル結果に表示されるリンクをクリックします。
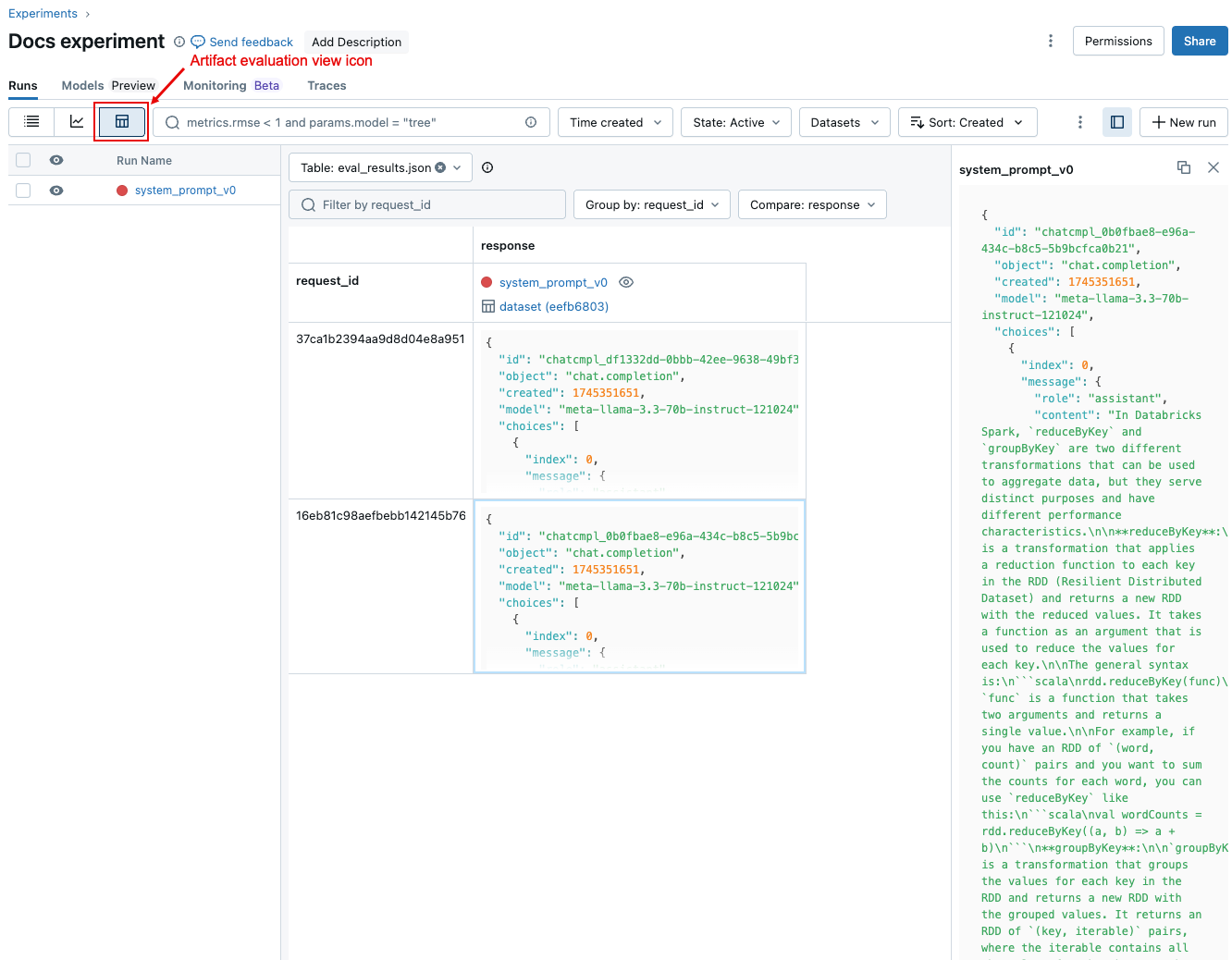
実行間のリクエストごとの結果を比較
実行間で個々のリクエストのデータを比較するには、次のスクリーンショットに示すアーティファクト評価ビューアイコンをクリックします。表には、評価セットの各質問が示されています。表示する列を選択するには、ドロップダウンメニューを使用します。セルをクリックすると、その全内容が表示されます。
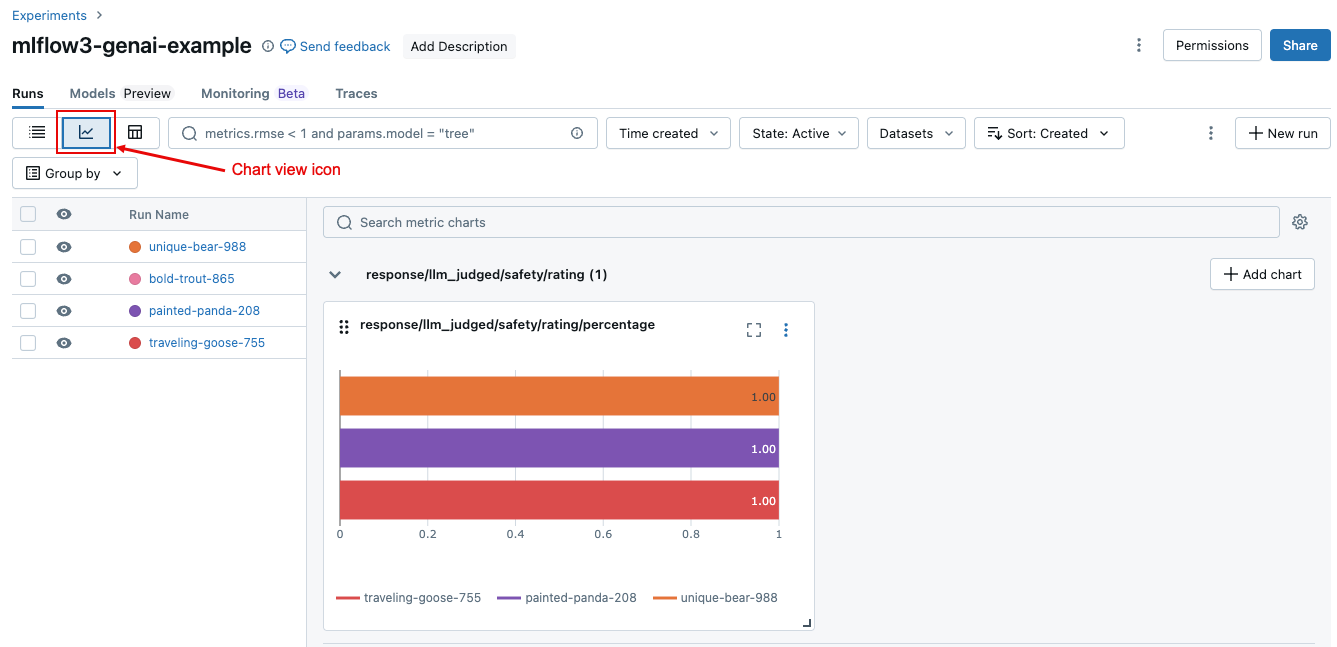
実行全体で集計結果を比較
実行の集約結果を比較する場合、または異なる実行間で比較するには、次のスクリーンショットに示すチャートビューアイコンをクリックしてください。これにより、選択した実行の集計結果を視覚化し、過去の実行と比較できます。
どのジャッジが実行されますか
デフォルトでは、各評価レコードについて、Agent Evaluation は、レコードに存在する情報に最適なジャッジのサブセットを適用します。具体的には:
- レコードにグラウンドトゥルース応答が含まれている場合、Agent Evaluationは
context_sufficiency、groundedness、correctness、safety、guideline_adherenceの各ジャッジを適用します。 - レコードにグラウンドトゥルース応答が含まれていない場合、Agent Evaluationは
chunk_relevance、groundedness、relevance_to_query、safety、およびguideline_adherenceのジャッジを適用します。
詳細については、次を参照してください。
LLMジャッジの信頼性と安全性に関する情報については、LLMジャッジを支援するモデルに関する情報をご覧ください。
例: アプリケーションをAgent Evaluationに渡す方法
アプリケーションをmlflow_evaluate()に渡すには、model引数を使用します。model引数にアプリケーションを渡すためのオプションが5つあります。
- Unity Catalogに登録されたモデル。
- 現在のMLflowエクスペリメントにあるMLflow記録済みモデル。
- ノートブックに読み込まれるPyFuncモデルです。
- ノートブック内のローカル関数。
- デプロイされたエージェントエンドポイント。
各オプションを説明するコード例については、以下のセクションを参照してください。
オプション 1. Unity Catalogに登録されたモデル
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
オプション2. 現在のMLflowエクスペリメントにあるMLflow記録済みモデル
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
オプション3. ノートブックにロードされるPyFuncモデル
%pip install databricks-agents==0.16.0 pandas==2.2.3
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
オプション 4. ノートブック内のローカル関数
関数は次のようにフォーマットされた入力を受け取ります。
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
関数は、プレーン文字列またはシリアル化可能な辞書のいずれかの形式で値を返す必要があります(例:Dict[str, Any])。組み込みジャッジで最良の結果を得るには、Databricks は ChatCompletionResponse のようなチャット形式を使用することをお勧めします。例えば:
{
"choices": [
{
"message": {
"role": "assistant",
"content": "MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models.",
},
...
}
],
...,
}
次の例では、ローカル関数を使用して基盤モデルのエンドポイントをラップし、それを評価します:
%pip install databricks-agents==0.16.0 pandas==2.2.3
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-3-70b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
オプション 5. デプロイされたエージェントエンドポイント
このオプションは、databricks.agents.deployを使用して、databricks-agents SDK バージョン0.8.0以降でデプロイされたエージェントエンドポイントを使用する場合にのみ機能します。基盤モデルまたは古いSDKバージョンでは、オプション4を使用してモデルをローカル関数でラップしてください。
%pip install databricks-agents==0.16.0 pandas==2.2.3
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
アプリケーションがmlflow_evaluate()呼び出しに含まれている場合に評価セットを渡す方法
次のコードでは、評価セットの Pandas データフレーム data です。 これらは簡単な例です。 詳細については、 入力スキーマ を参照してください。
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
例: 以前に生成された出力を Agent Evaluation に渡す方法
このセクションでは、mlflow_evaluate() の呼び出しで以前に生成された出力を渡す方法について説明します。必要な評価セットスキーマについては、Agent Evaluation入力スキーマ (MLflow 2)を参照してください。
次のコードでは、data は評価セットとアプリケーションによって生成された出力の Pandas データフレーム です。 これらは簡単な例です。 詳細については、 入力スキーマ を参照してください。
%pip install databricks-agents==0.16.0 pandas==2.2.3
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
"guidelines": {
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
例:カスタム関数を使用してLangGraphからのレスポンスを処理する
LangGraph エージェント、特にチャット機能を備えたエージェントは、単一の推論呼び出しに対して複数のメッセージを返すことができます。エージェントの応答をAgent Evaluationがサポートする形式に変換するのは、ユーザーの責任です。
1つのアプローチは、応答を処理するためにカスタム関数を使用することです。次の例は、LangGraph モデルから最後のチャットメッセージを抽出するカスタム関数を示しています。この関数はその後 mlflow.evaluate() で使用され、単一の文字列応答を返します。これは ground_truth 列と比較できます。
このコード例では、次の前提があります。
- このモデルは{“messages”: [{“role”: “user”, “content”: “hello”}]}の形式で入力を受け付けます。
- モデルは、[「response 1」、「response 2」]という形式の文字列のリストを返します。
次のコードは、連結された応答を次の形式で審査者に送信します: 「response 1nresponse2」
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models. MLflow enables teams of all sizes to debug, evaluate, monitor, and optimize their AI applications while controlling costs and managing access to models and data. With over 30 million monthly downloads, thousands of organizations rely on MLflow each day to ship AI to production with confidence.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
メトリクスを使用したダッシュボードの作成
エージェントの品質を反復処理しているときに、時間の経過とともに品質がどのように向上したかを示すダッシュボードを利害関係者と共有したい場合があります。 MLflow評価ランからメトリクスを抽出し、値をDeltaテーブルに保存して、ダッシュボードを作成できます。
次の例は、ノートブックで最新の評価ランからメトリクス値を抽出して保存する方法を示しています。
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
次の例は、MLflowエクスペリメントに保存した過去の実行のメトリクス値を抽出して保存する方法を示しています。
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
これで、このデータを使用してダッシュボードを作成できます。
次のコードは、前の例で使用されている関数 append_metrics_to_table を定義します。
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
LLMジャッジを支援するモデルに関する情報
- LLMジャッジは、Microsoftが運営するAzure OpenAIなどのサードパーティサービスを使用して生成AIアプリケーションを評価する場合があります。
- Azure OpenAIの場合、Databricksは不正行為モニタリングをオプトアウトしているため、プロンプトや応答はAzure OpenAIに保存されません。
- 欧州連合(EU)のワークスペースの場合、LLMジャッジはEUでホストされているモデルを使用します。他のすべてのリージョンでは、米国でホストされているモデルを使用します。
- パートナーを利用したAI機能を無効にすると、 LLMジャッジがパートナーを利用したモデルを呼び出すことができなくなります。 独自のモデルを提供することで、LLM ジャッジを引き続き使用できます。
- LLM ジャッジは、顧客が生成AIエージェント/アプリケーションを評価するのを支援することを目的としており、ジャッジ LLM アウトプットを LLMのトレーニング、改善、または微調整に使用すべきではありません。