Feature Serving endpoints
Databricks Feature Serving makes data in the Databricks platform available to models or applications deployed outside of Databricks. Feature Serving endpoints automatically scale to adjust to real-time traffic and provide a high-availability, low-latency service for serving features. This page describes how to set up and use Feature Serving. For a step-by-step tutorial, see Example: Deploy and query a feature serving endpoint.
When you use Mosaic AI Model Serving to serve a model that was built using features from Databricks, the model automatically looks up and transforms features for inference requests. With Databricks Feature Serving, you can serve structured data for retrieval augmented generation (RAG) applications, as well as features that are required for other applications, such as models served outside of Databricks or any other application that requires features based on data in Unity Catalog.
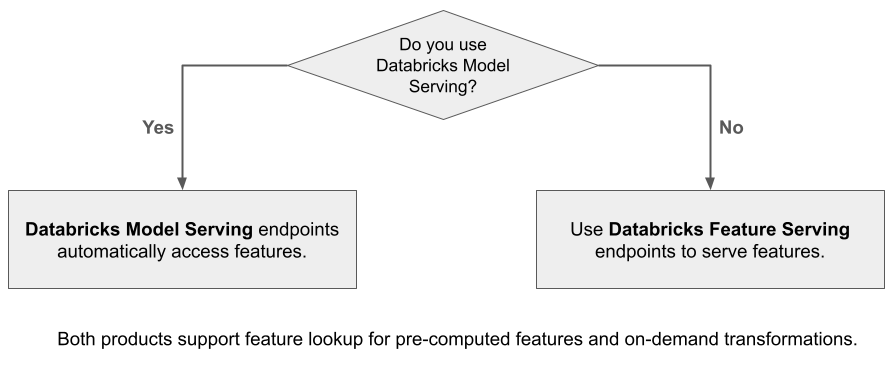
Why use Feature Serving?
Databricks Feature Serving provides a single interface that serves pre-materialized and on-demand features. It also includes the following benefits:
- Simplicity. Databricks handles the infrastructure. With a single API call, Databricks creates a production-ready serving environment.
- High availability and scalability. Feature Serving endpoints automatically scale up and down to adjust to the volume of serving requests.
- Security. Endpoints are deployed in a secure network boundary and use dedicated compute that terminates when the endpoint is deleted or scaled to zero.
Requirements
- Databricks Runtime 14.2 ML or above.
- To use the Python API, Feature Serving requires
databricks-feature-engineeringversion 0.1.2 or above, which is built into Databricks Runtime 14.2 ML. For earlier Databricks Runtime ML versions, manually install the required version using%pip install databricks-feature-engineering>=0.1.2. If you are using a Databricks notebook, you must then restart the Python kernel by running this command in a new cell:dbutils.library.restartPython(). - To use the Databricks SDK, Feature Serving requires
databricks-sdkversion 0.18.0 or above. To manually install the required version, use%pip install databricks-sdk>=0.18.0. If you are using a Databricks notebook, you must then restart the Python kernel by running this command in a new cell:dbutils.library.restartPython().
Databricks Feature Serving provides a UI and several programmatic options for creating, updating, querying, and deleting endpoints. This article includes instructions for each of the following options:
- Databricks UI
- REST API
- Python API
- Databricks SDK
To use the REST API or MLflow Deployments SDK, you must have a Databricks API token.
As a security best practice for production scenarios, Databricks recommends that you use machine-to-machine OAuth tokens for authentication during production.
For testing and development, Databricks recommends using a personal access token belonging to service principals instead of workspace users. To create tokens for service principals, see Manage tokens for a service principal.
Authentication for Feature Serving
For information about authentication, see Authorize access to Databricks resources.
Create a FeatureSpec
A FeatureSpec is a user-defined set of features and functions. You can combine features and functions in a FeatureSpec. FeatureSpecs are stored in and managed by Unity Catalog and appear in Catalog Explorer.
The tables specified in a FeatureSpec must be published to an online feature store or a third-party online store. See Databricks Online Feature Stores.
You must use the databricks-feature-engineering package to create a FeatureSpec.
First, define the function:
from unitycatalog.ai.core.databricks import DatabricksFunctionClient
client = DatabricksFunctionClient()
CATALOG = "main"
SCHEMA = "default"
def difference(num_1: float, num_2: float) -> float:
"""
A function that accepts two floating point numbers, subtracts the second one
from the first, and returns the result as a float.
Args:
num_1 (float): The first number.
num_2 (float): The second number.
Returns:
float: The resulting difference of the two input numbers.
"""
return num_1 - num_2
client.create_python_function(
func=difference,
catalog=CATALOG,
schema=SCHEMA,
replace=True
)
Then you can use the function in a FeatureSpec:
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates num_1 - num_2.
input_bindings={"num_1": "ytd_spend", "num_2": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
Specify default values
To specify default values for features, use the default_values parameter in the FeatureLookup. See the following example:
feature_lookups = [
FeatureLookup(
table_name="ml.recommender_system.customer_features",
feature_names=[
"membership_tier",
"age",
"page_views_count_30days",
],
lookup_key="customer_id",
default_values={
"age": 18,
"membership_tier": "bronze"
},
),
]
If the feature columns are renamed using the rename_outputs parameter, default_values must use the renamed feature names.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
rename_outputs={"materialized_feature_value": "feature_value"},
default_values={
"feature_value": 0
}
)
Create an endpoint
The FeatureSpec defines the endpoint. For more information, see Create custom model serving endpoints, the Python API documentation, or the Databricks SDK documentation for details.
For workloads that are latency sensitive or require high queries per second, Model Serving offers route optimization on custom model serving endpoints, see Route optimization on serving endpoints.
- Databricks SDK - Python
- Python API
- REST API
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
To see the endpoint, click Serving in the left sidebar of the Databricks UI. When the state is Ready, the endpoint is ready to respond to queries. To learn more about Mosaic AI Model Serving, see Mosaic AI Model Serving.
Save the augmented DataFrame in the inference table
For endpoints created starting February 2025, you can configure the model serving endpoint to log the augmented DataFrame that contains the looked-up feature values and function return values. The DataFrame is saved to the inference table for the served model.
For instructions on setting this configuration, see Log feature lookup DataFrames to inference tables.
For information about inference tables, see Inference tables for monitoring and debugging models.
Get an endpoint
You can use the Databricks SDK or the Python API to get the metadata and status of an endpoint.
- Databricks SDK - Python
- Python API
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
Get the schema of an endpoint
You can use the Databricks SDK or the REST API to get the schema of an endpoint. For more information about the endpoint schema, see Get a model serving endpoint schema.
- Databricks SDK - Python
- REST API
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
# Create endpoint
endpoint = workspace.serving_endpoints.get_open_api(name="customer-features")
ACCESS_TOKEN=<token>
ENDPOINT_NAME=<endpoint name>
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
Query an endpoint
You can use the REST API, the MLflow Deployments SDK, or the Serving UI to query an endpoint.
The following code shows how to set up credentials and create the client when using the MLflow Deployments SDK.
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
As a security best practice when you authenticate with automated tools, systems, scripts, and apps, Databricks recommends that you use OAuth tokens.
If you use personal access token authentication, Databricks recommends using personal access tokens belonging to service principals instead of workspace users. To create tokens for service principals, see Manage tokens for a service principal.
Query an endpoint using APIs
This section includes examples of querying an endpoint using the REST API or the MLflow Deployments SDK.
- MLflow Deployments SDK
- REST API
The following example uses the predict() API from the MLflow Deployments SDK. This API is Experimental and the API definition might change.
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
Query an endpoint using the UI
You can query a serving endpoint directly from the Serving UI. The UI includes generated code examples that you can use to query the endpoint.
-
In the left sidebar of the Databricks workspace, click Serving.
-
Click the endpoint you want to query.
-
In the upper-right of the screen, click Query endpoint.
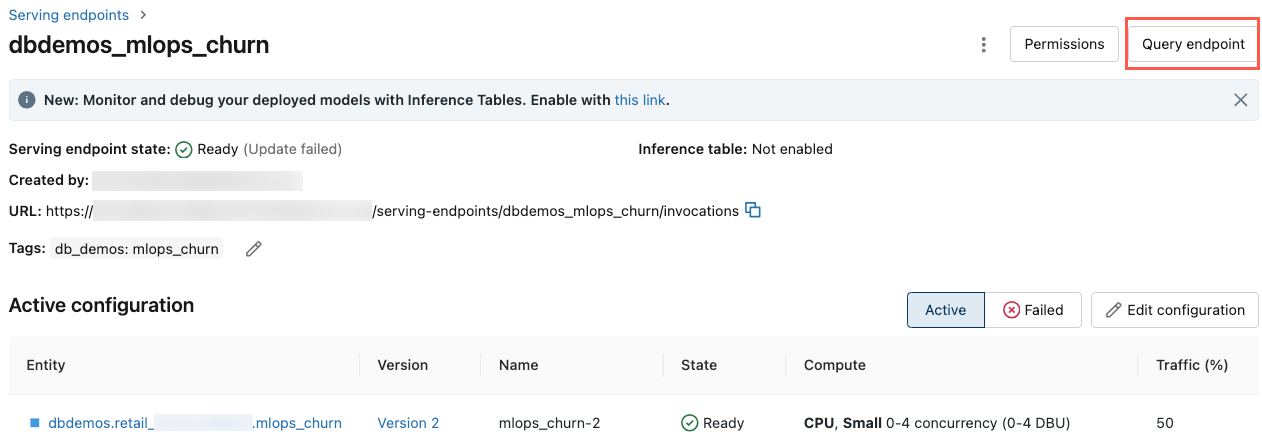
-
In the Request box, type the request body in JSON format.
-
Click Send request.
// Example of a request body.
{
"dataframe_records": [
{ "user_id": 1, "ytd_spend": 598 },
{ "user_id": 2, "ytd_spend": 280 }
]
}
The Query endpoint dialog includes generated example code in curl, Python, and SQL. Click the tabs to view and copy the example code.
To copy the code, click the copy icon in the upper-right of the text box.
Update an endpoint
You can update an endpoint using the REST API, the Databricks SDK, or the Serving UI.
Update an endpoint using APIs
- Databricks SDK - Python
- REST API
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
Update an endpoint using the UI
Follow these steps to use the Serving UI:
- In the left sidebar of the Databricks workspace, click Serving.
- In the table, click the name of the endpoint you want to update. The endpoint screen appears.
- In the upper-right of the screen, click Edit endpoint.
- In the Edit serving endpoint dialog, edit the endpoint settings as needed.
- Click Update to save your changes.

Delete an endpoint
This action is irreversible.
You can delete an endpoint using the REST API, the Databricks SDK, the Python API, or the Serving UI.
Delete an endpoint using APIs
- Databricks SDK - Python
- Python API
- REST API
from databricks.sdk import WorkspaceClient
workspace = WorkspaceClient()
workspace.serving_endpoints.delete(name="customer-features")
fe.delete_feature_serving_endpoint(name="customer-features")
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
Delete an endpoint using the UI
Follow these steps to delete an endpoint using the Serving UI:
- In the left sidebar of the Databricks workspace, click Serving.
- In the table, click the name of the endpoint you want to delete. The endpoint screen appears.
- In the upper-right of the screen, click the kebab menu
 and select Delete.
and select Delete.

Monitor the health of an endpoint
For information about the logs and metrics available for Feature Serving endpoints, see Monitor model quality and endpoint health.
Access control
For information about permissions on Feature Serving endpoints, see Manage permissions on a model serving endpoint.
Example notebook
This notebook illustrates how to use the Databricks SDK to create a Feature Serving endpoint using Databricks Online Feature Store.